目录
一、什么是DMA?为什么需要DMA?
DMA 技术是Direct Memory Access的缩写,其意思是“存储器直接访问”。它是指一种高速的数据传输操作,允许在外部设备和存储器之间直接读写数据,既不通过CPU,也不需要CPU干预。DMA 是所有现代计算机的重要特色,它允许不同速度的硬件设备进行沟通,而不需要依于中央处理器的大量中断负载。否则,中央处理器需要从来源把每一片段的数据复制到寄存器,然后把它们再次写回到新的地方。在这个时间里,中央处理器就无法执行其它的任务。
DMA 是用硬件实现存储器与存储器之间或存储器与 I/O 设备之间直接进行高速数据传输。使用 DMA 时,CPU 向 DMA 控制器发出一个存储传输请求,这样当 DMA 控制器在传输的时候,CPU 执行其它操作,DMA完成后必须以合理的方式通知CPU,那么现有的方式主要依赖中断和轮询两种模式。在高性能下更倾向于使用轮询或者半轮询机制。
为了发起传输事务,DMA 控制器必须得到以下数据(DMA三要素):
源地址:数据被读出的地址
目的地址:数据被写入的地址
传输长度:应被传输的字节数

DMA 存储传输的过程如下:
- 为了配置用 DMA 传输数据到存储器,处理器发出一条 DMA 命令
- DMA 控制器把数据从外设传输到存储器或从存储器到存储器,而让 CPU 腾出手来做其它操作。
- 数据传输完成后,向 CPU 发出一个中断来通知它 DMA 传输可以关闭了。
二、DMA分类
一般情况下,大家都只需要从使用层面来理解如何使用DMA,但是在本文中,我们希望从底层原理的角度,来详细理解DMA的设计和原理。目前常见的几种DMA设计大致可以分成:(1)Block DMA(2)Scatter-Gather DMA(3)Ring buffer DMA
2.1 Block DMA
Block DMA 也被称为阻塞式DMA。Block DMA在一次DMA操作中仅能操作一块物理地址连续的数据块。Block DMA 的驱动程序和硬件交互时具有阻塞式的特点:驱动程序在启动一次 DMA 操作后,直到本次操作完成前,不能下发下一次的操作请求。这样一来,当驱动程序准备数据时,DMA 处于空闲状态;当 DMA 处于操作转态时,驱动程序处于空闲状态,因此其性能较低。
工作原理
初始化:CPU设置DMA控制器的源地址(数据来源)、目的地址(数据去向)、以及要传输的数据块大小。
传输启动:DMA控制器接管控制权,开始数据传输过程。在这个过程中,CPU不需要进行数据移动的操作。
连续传输:DMA控制器连续地从源地址读取数据,并将其写入目标地址,直到整个数据块被传输完成。
传输结束:一旦数据块传输完成,DMA控制器会通过中断信号通知CPU传输已经结束,CPU可以处理其他任务或对传输的数据进行后续处理。

2.2 Scatter-Gather DMA
Scatter-Gather DMA 是一种高级的直接存储器访问(DMA)技术,它允许从非连续的内存区域(scatter)读取数据并将其写入到一个连续的内存区域,或者从一个连续的内存区域读取数据并分散(gather)到多个非连续的内存位置。这种技术在处理多任务和高数据量的系统中非常有用,尤其是在内存布局不是连续分配的情况下。
Scatter-Gather DMA,也称分散聚集式 DMA,分散聚集指的是它在一次 DMA 传输中将分散在主存中的多块内存空间通过链表的方式聚集在一起,从而实现在一次 DMA 传输中进行多次 DMA 操作。
与 Block DMA 相比,SG DMA 在一次 DMA 传输中的操作流程更加复杂,SG DMA 首先发起一次 DMA 操作读取内存中的链表结构, 而后依次处理链表中指向的内存空间数据。可以看到,在小数据量的单次内存访问中, SG DMA 反而会带来额外的开销。但是在数据量较大时,Scatter-Gather DMA 可以提高主机中内存的利用率以及 DMA 传输的效率,因为 SG DMA 将多次 Block DMA 中 的软件硬件交互合并为一次,大大降低了由于多次中断带来的延迟和处理器消耗。
工作原理
描述符表:CPU或DMA控制器构建一个描述符表,这个表包含了多个内存块的地址和大小,这些内存块可能分布在物理内存的不同位置。
DMA读写:DMA控制器根据描述符表中的信息,从多个源内存地址读取数据并将其合并写入单一目标地址,或者将数据从单一源地址读取后分散写入多个目标内存地址。
中断处理:数据传输完成后,DMA控制器通常会发出中断信号通知CPU,CPU随后进行后续处理。

2.3 Ring buffer DMA
Ring buffer DMA(环形缓冲区直接存储器访问)是一种常用于流数据处理的DMA技术,特别适用于那些数据持续生成并需要周期性处理的场景,如音视频流处理、网络数据包处理等。环形缓冲区是一个逻辑上首尾相连的循环数据结构,这种结构使得DMA可以持续、高效地管理和传输数据,而不需要频繁的中断或复杂的内存管理操作。
Ring Buffer DMA 也被称为队列式 DMA。RB DMA 引擎中的各个队列是独立的,并且绑定特定的 CPU 核心,以发挥多核心处理器的体系结构优势。此外,RB DMA 引擎还优化了主机和 DMA 之间的交互流程,RB DMA 使用描述符队列来完成主机与 DMA 之间的命令发布和事件通知。
| 特性/模式 | Block DMA | Scatter-Gather DMA | Ring Buffer DMA |
| 描述 | 一次性传输整个数据块 | 从非连续的内存区域收集数据到连续区域,反之亦然。 | 使用环形缓冲区循环传输数据,适用于流数据处理。 |
| 数据连续性 | 需要数据在内存中连续。 | 适用于非连续内存区域的数据。 | 数据循环在固定大小的缓冲区内,不需连续性。 |
| 效率 | 高,因为是连续快速传输。 | 高,特别是在内存碎片化时。 | 高,通过减少中断提升处理速度。 |
| CPU负担 | 低,在DMA传输期间CPU可以执行其他任务。 | 低,DMA控制器管理所有内存访问。 | 低,自动处理数据流动,减少CPU干预。 |
| 应用场景 | 大文件传输、大数据块处理。 | 数据库系统、文件系统、网络通信。 | 音视频流处理、网络数据包处理、实时系统。 |
| 内存管理 | 简单,因为操作连续内存。 | 复杂,需要高级的内存管理技术。 | 中等,固定大小的缓冲区需事先配置。 |
| 同步机制 | 通常不需要复杂同步,DMA结束后中断CPU。 | 需要精确控制数据源和目标内存区域的同步。 | 需要同步机制防止写入读取操作冲突。 |
三、实际案例
3.1 STM32微处理器
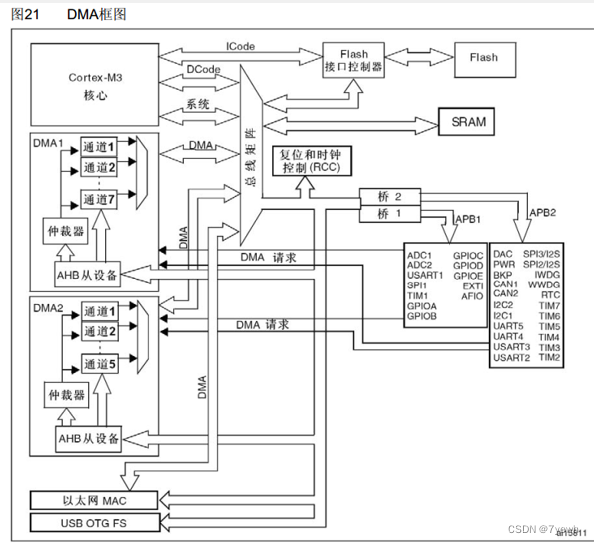
在STM32微控制器中,通常使用的DMA模式包括Block DMA和Scatter-Gather DMA。这些模式被广泛应用于多种外设与内存间的数据传输任务,例如ADC(模拟数字转换器)、USART(通用同步异步接收发射器)、SPI(串行外设接口)等。
3.1.1 Block DMA
Block DMA在STM32中非常常见,用于处理如SPI或USART等接口的大块数据传输。当数据需要在内存与外设间快速移动时,Block DMA可以一次性传输整个数据块,提高传输效率且减少CPU的负担。例如,从USART接收大量数据并存储到RAM的场景中,Block DMA可以连续传输所有数据而无需CPU介入。
3.1.2 Scatter-Gather DMA
Scatter-Gather DMA在STM32中主要用于更复杂的数据管理任务,特别是当数据源分布在内存的不同区域时。这种模式允许DMA控制器从多个内存位置收集数据并发送到单一或多个目标,或者相反。STM32的DMA控制器支持多个通道和流,这使得Scatter-Gather操作更为高效,特别是在处理如网络数据包或多路ADC数据时。
3.1.3 使用场景举例:
- Block DMA:在需要从内存缓冲区向外设如LCD或音频接口连续发送大量数据时使用。
- Scatter-Gather DMA:在收集来自不同传感器的多个ADC通道数据到单一缓冲区,或者从一个缓冲区将数据分发到多个外设时使用。
3.1.4 配置与实现
STM32通过其硬件库HAL或底层库LL提供对DMA的支持,使得开发者可以根据需求配置DMA传输类型。配置通常涉及设定源地址、目标地址、传输方向、传输大小、优先级等参数。这些配置可以通过STM32CubeIDE工具链或直接通过编程实现,具体取决于应用的复杂度和性能要求。总结来说,STM32中的DMA使用情况较为灵活,可以根据外设类型和具体应用需求选择合适的DMA模式。
3.2 FPGA
在FPGA(现场可编程门阵列)中,DMA(Direct Memory Access)的使用是一种高效的数据管理技术,尤其在处理高速数据流和大量数据传输时。FPGA通过DMA可以直接从内存读取或写入数据,而无需CPU干预,这样大大提高了数据处理的速度和系统的总体性能。
3.2.1 FPGA中DMA的实现方式
3.2.1.1 IP核集成
FPGA通常使用现成的DMA IP核来实现高效的数据传输。这些IP核可以通过FPGA开发工具,如Xilinx的Vivado或Intel的Quartus,进行配置和集成。IP核可以配置为支持多种DMA模式,如简单的单次传输、突发传输或更复杂的Scatter-Gather DMA。
3.2.2.2 自定义DMA控制器
对于特殊的应用需求,开发者可能会使用Verilog或VHDL来自定义DMA控制器逻辑。自定义DMA控制器允许精细控制数据的流动、优先级管理和错误处理。
以下举两个典型的例子来进一步介绍FPGA中DMA的使用。
3.2.2 AXI DMA IP
AXI DMA (Direct Memory Access) IP是专为Xilinx FPGA设计的一种高性能、高通量数据传输接口,基于AXI (Advanced eXtensible Interface) 总线标准。这种IP核广泛用于需要高速数据传输的FPGA应用中,如数据采集、图像处理、网络通信等。AXI DMA IP支持高效的内存到内存、外设到内存以及内存到外设的数据传输。
AXI DMA 用到了三种总线,AXI4-Lite 用于对寄存器进行配置,AXI4 Memory Map 用于与内存交互,又分为 AXI4 Memory Map Read 和 AXI4 Memory Map Write 两个接口,一个是读一个是写。AXI4 Stream 接口用于对外设的读写,其中 AXI4 Stream Master(MM2S,Memory Map to Stream)用于对外设写,AXI4-Stream Slave(S2MM,Stream to Memory Map)用于对外设读。总之,在以后的使用中需要知道 AXI_MM2S 和 AXI_S2MM 是存储器端映射的 AXI4 总线,提供对存储器(DDR3)的访问。AXIS_MM2S 和 AXIS_S2MM 是 AXI4-streaming 总线,可以发送和接收连续的数据流,无需地址。

AXI DMA IP核特性
高吞吐量和低延迟:AXI DMA利用AXI总线的高带宽和低延迟特性,实现快速数据传输。支持高速数据流和大批量数据处理。
支持Scatter-Gather模式:通过Scatter-Gather列表,AXI DMA可以管理非连续的内存数据块,提高内存使用效率。这种模式使得DMA能够从多个内存区域收集数据并传输到单一或多个目的地,或反之。
可配置性和灵活性:AXI DMA IP核可在Xilinx的Vivado设计套件中配置,允许用户根据具体应用需求调整数据宽度、传输模式等参数。支持多种传输模式,包括单次传输、连续传输等。
中断和事件管理:支持生成中断,以便在传输完成或发生错误时通知CPU或处理器,实现有效的事件管理。这有助于提高应用的响应能力和可靠性。
3.2.3 XDMA
XDMA是Xilinx公司提供的高性能可配置的SG DMA硬核,具备AXI Stream接口、AXI Lite接口和AXI4接口三种用户接口。XDMA IP核是对FPGA集成的PCIe硬核进行二次封装,开发效率更高。

XDMA的关键特性
- 高速PCI Express接口支持:XDMA支持多种PCIe配置,包括1x, 2x, 4x, 8x, 16x等通道,兼容PCIe 1.x, 2.x, 3.x, 4.x标准,可实现高达16 GT/s的数据传输速率。
- 灵活的数据传输模式:支持Memory-Mapped I/O (MMIO) 和 Direct Memory Access (DMA) 操作模式,可以根据需要灵活配置和使用。
- 支持多个DMA通道:XDMA可以配置多个独立的DMA通道,每个通道可以独立进行数据传输,增加了数据处理的灵活性和系统的扩展性。
- 高级特性:支持中断和信号机制,确保数据传输的可靠性和及时响应。支持Scatter-Gather DMA,允许从非连续的内存区域收集数据,有效管理内存碎片,优化内存使用。