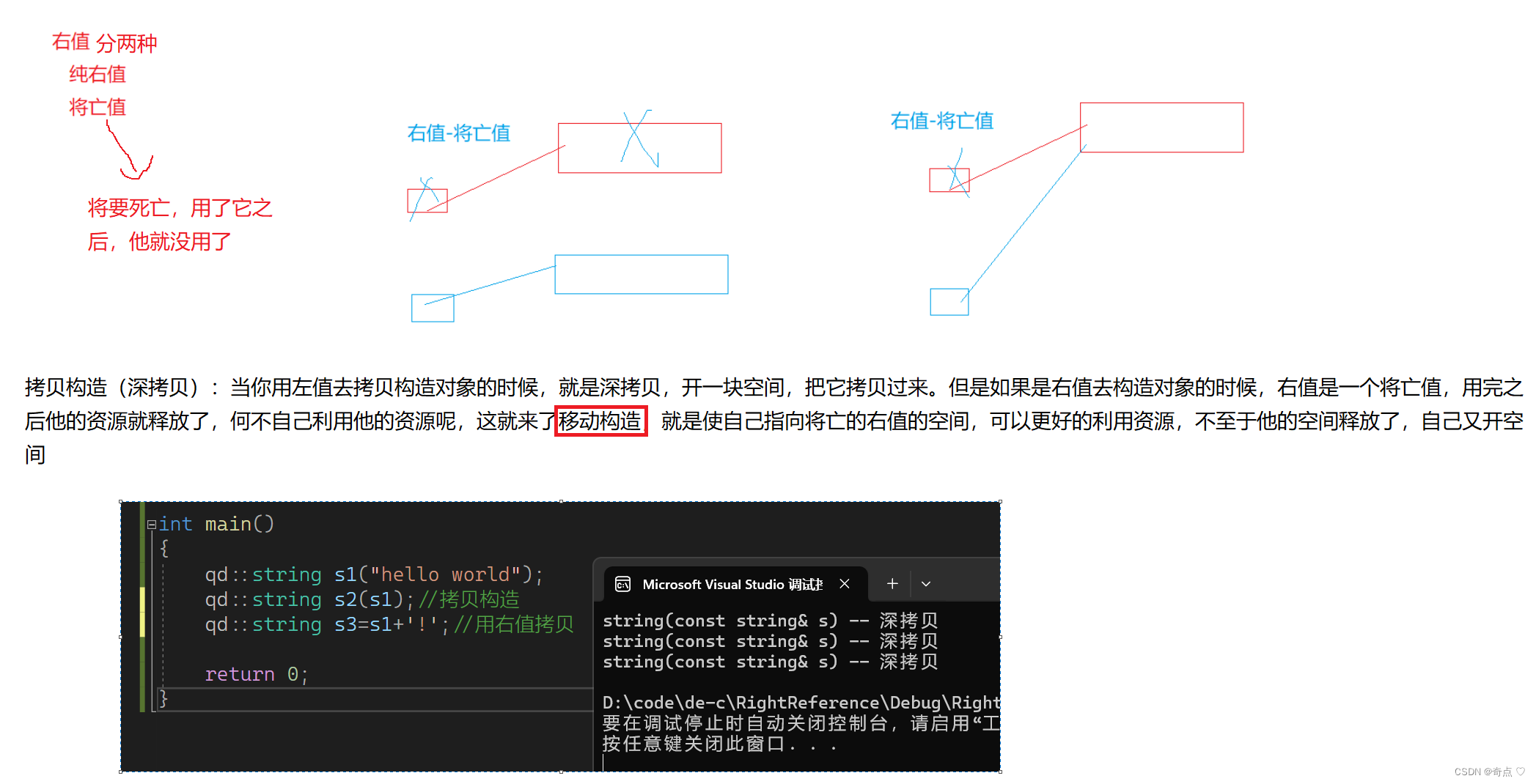
左值与右值
左值的最大特征在于:我们可以获取左值的地址,如变量、解引用的指针
右值的最大特征在于:我们不可以获取右值的地址,如字面常量、表达式返回值、函数返回值(这里的表达式和函数的返回值,都是指的那个临时对象,那个临时对象是右值)
此外,还有一个界定左右值的点:
- 右值不能被修改
- 左值是可以修改的,除非被const修饰。但被const修饰的左值也是左值,它仍然可以取地址
左值可以出现在赋值符号的左右两侧;右值只能出现在赋值符号的右边
//常见左值
//以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
"xxxx"; //字符串常量是左值
//常见右值
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
对于自定义类型的右值,将其称为将亡值
左值引用与右值引用
左值引用:给左值取别名
右值引用:给右值取别名
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
左值引用也可以给右值取别名:
const int& r=10;
const 类型& 变量这一常出现在函数的形参,特别是我们不希望实参被改变时,就会加上const。其实这里还有另一层就是,能够让一些右值能被引用
右值引用也可以给左值取别名:
int&& r=move(a);
move是库里实现的函数,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值,然后实现移动语义
右值引用的意义
左值引用的意义与弊端
左值引用通常用于两种场景:
- 做函数形参
- 做函数返回值
左值引用的价值在于:减少拷贝
但是左值引用最大的弊端在于:做不到对于局部对象的返回。比如:
string& func()
{
string str="xxxx";
//……
return str;
}
上述代码中:str是函数中的局部对象,出了函数就会销毁,所以返回值中的左值引用返回的是一个野指针。对于这种情况,在C++11之前我们只能进行传值返回,而传值返回势必就需要进行拷贝,尤其是涉及深拷贝的自定义类型,深拷贝的消耗是很大的
比如我们看下面的场景:
namespace xy
{
class string
{
public:
string(const char* str = "")
:_size(strlen(str)), _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 赋值(深拷贝)" << endl;
//现代写法,利用拷贝构造实现
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
private:
char* _str;
size_t _size;
size_t _capacity; //不包含最后做标识的\0
};
}
string func()
{
string str="xxxx";
//……
return str;
}
int main()
{
//场景1
string ret1=func();
//场景2
string ret2;
ret2=func();
return 0;
}
场景1:在编译器不做优化之前,str先深拷贝给一个临时对象,然后临时对象再深拷贝给ret1。涉及两次深拷贝。由于两次深拷贝是连续的,编译器会将其优化为一次深拷贝
场景2:str先深拷贝给一个临时对象,然后临时对象再赋值给ret2。涉及一次深拷贝和一次赋值
上述代码运行结果如下:

这里场景1中的优化和C++没有关系,是编译器做的优化
右值引用的出现
右值引用一部分就是为了优化:传值返回自定义类型数据时多次深拷贝影响效率
有了右值引用后,就可以实现:移动拷贝和移动赋值
当函数传值返回时,且返回值是自定义类型的,编译器会将返回值识别为将亡值
- 面对深拷贝,将用移动拷贝替换
- 面对赋值,将用移动赋值替换
移动拷贝/移动赋值的好处:
深拷贝和赋值需要给新对象开辟空间,并把数据移动过去,这两步是需要耗费资源的。
移动拷贝/移动赋值是本来你需求一个对象,而我现在已经有一个临时对象了。本来我是用这个临时对象去拷贝构造出你所需的对象,然后我临时变量就销毁, 但是既然我要销毁,你也需要这个对象。那我不如直接把我这个临时对象直接交给你去管理。从而省去了开辟新空间和移动数据的步骤,从而优化效率。
从代码上可以看出,移动拷贝/移动赋值,是浅拷贝
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
string(string&& s)
:_str(nullptr)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 赋值(深拷贝)" << endl;
string tmp(s);
swap(tmp);
return *this;
}
string& operator=(string&& s)
{
cout << "string& operator=(string && s) -- 移动赋值" << endl;
swap(s);
return *this;
}
这里的函数会构成重载
有了移动拷贝和移动赋值,那么重新运行如下代码:
string func()
{
string str="xxxx";
//……
return str;
}
int main()
{
//场景1
string ret1=func();
//场景2
string ret2;
ret2=func();
return 0;
}
结果是:

针对场景1:

编译器验证:

针对场景2:

编译器验证:

右值引用的使用场景
场景一:即上面所讲,自定义类型中需要深拷贝的类,必须传值返回的场景
为什么这里要强调深拷贝?
因为右值引用对于内置类型和成员变量都是内置类型的自定义类来说是没有意义的。因为它们的拷贝一下开销并不大
换句话说,日期类的移动构造和拷贝构造没有什么区别啊,不都是
_year=year吗?所以浅拷贝的类的移动拷贝和移动赋值不需要实现,因为没有需要转移的资源,全都是直接拷贝但是像
map<string,string>这样的自定义类型,拷贝的代价是很大的,所以需要右值引用因此自定义类型没有涉及深拷贝,如Date类,那么右值引用不会发挥作用
场景二:容器的插入接口(如insert、push_back等),如果插入对象是将亡值,可以利用移动构造转移资源给数据结构中的对象
这里对于场景二我们详细说明一下:
我们看如下代码:
list<xy::string> It;
It.push_back("222");
上述代码中存在着一个移动拷贝
首先我们需要搞清楚这个拷贝构造发生在哪

其实上图是有问题的,但这里先知道这个例子就行。具体问题会在完美转发中详细说明
由于“222”是右值,因此可以移动拷贝
因为“222”会先构造一个临时对象,这个临时对象是右值(相当于是隐式类型的转换)
也就是现在比以前少拷贝一次。以前是构造+深拷贝,现在是构造+移动构造
右值引用的特性
右值不可以修改,但右值引用是可以修改的。编译器会将右值引用默认识别为左值
int&& r=10;
r++;
cout<<&r; //是可以打印出r的地址的
比如上面:10是右值,r是10的引用,但r其实是个左值
这里相当于是开了一块名叫r的空间,将10这个右值给存起来了(可以这样理解,实际并不一定是这样)
但是编译器为什么要这样做呢?我们看如下的例子:

上图中:str会移动拷贝给ret。str是个右值,会做为实参传递给string(string&& s)中的s,这个s是个右值引用。如果s是右值,那么下面就会有两个错误:
- 第一个:s无法传递给swap函数,因为swap的形参是个左值引用,它只能接收左值
- 第二个:就算给swap函数改成
const string& s或者string&& s,但是这两种情况下的s都是不能修改的。因此swap无法完成资源交换
综合上述两个原因:string(string&& s)中的s只能是个左值。否则在移动拷贝的场景下,无法完成资源转移
总结
左值引用的核心价值是减少拷贝,提高性能
右值引用的核心价值是进一步减少拷贝,弥补左值引用没用解决的场景
假如某个自定义类型涉及深拷贝,那么就必须实现它的移动拷贝和移动赋值
右值出现的最大价值,就是有了左右值的区分。当数据要拷贝时,如果是做左值,那就老老实实的拷贝;如果是将亡值,那就转移资源
比如说这里,ret3是个左值,所以只能老老实实的拷贝
string ret("1111");
string copy=ret;