阅读时间:2023-12-13
1 介绍
年份:2018
作者:Rahaf Aljundi,丰田汽车欧洲公司研究员;阿卜杜拉国王科技大学(KAUST)助理教授;Marcus Rohrbach德国达姆施塔特工业大学多模式可靠人工智能教授
会议: Proceedings of the European conference on computer vision (ECCV)
引用量:1416
代码:https://github.com/wannabeOG/MAS-PyTorch
https://github.com/rahafaljundi/MAS-Memory-Aware-Synapses
Aljundi R, Babiloni F, Elhoseiny M, et al. Memory aware synapses: Learning what (not) to forget[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 139-154.
鉴于模型容量有限而新信息无限,知识需要被选择性地保留或抹去。提出了一种新的方法,称为“记忆感知突触”(Memory Aware Synapses, MAS),该算法不仅以在线方式计算网络参数的重要性,而且以无监督的方式适应网络测试的数据。当学习新任务时,对重要参数的更改可以受到惩罚,有效防止与以前任务相关的知识被覆盖。构建了一个能够适应权重重要性的持续系统,以系统需要记住的内容。我们的方法需要恒定的内存量,并具有我们上面列出的主要期望的终身学习特性,同时实现了最先进的性能。
2 创新点
- 记忆感知突触(MAS)方法:提出了一种新的终身学习方法,能够选择性地保留或抹去知识,以适应不断变化的学习任务和有限的模型容量。
- 无监督在线参数重要性评估:MAS能够在没有标签数据的情况下,在线地评估神经网络参数的重要性,这一点与传统的依赖于损失函数的方法不同。
- 基于输出函数敏感性的权重调整:MAS通过评估输出函数对参数变化的敏感性来计算参数的重要性,而不是依赖于损失函数的梯度,这避免了在损失函数局部最小值处梯度接近零的问题。
- 与Hebb学习规则的联系:展示了MAS方法与Hebb学习规则之间的联系,这是一种解释突触可塑性的生物学理论,表明MAS具有生物学上的合理性。
- 适应性权重更新:MAS能够根据未标记的测试数据更新参数的重要性权重,使得模型能够适应特定的测试条件和上下文。
- 实验验证:在多个任务和数据集上进行了实验验证,包括对象识别任务和学习预测<主体,谓语,对象>三元组的任务,证明了MAS方法的有效性。
- 性能提升:在标准终身学习设置和特定测试条件下,MAS都展现出了优于现有技术的性能,尤其是在减少灾难性遗忘方面。
- 内存效率:MAS方法在保持性能的同时,具有较低的内存消耗,这对于资源受限的应用场景尤为重要。
- 灵活性和通用性:MAS不仅限于特定的任务或数据类型,能够广泛应用于各种终身学习的场景。
3 相关研究
3.1 基于数据的方法
- Aljundi R, Chakravarty P, Tuytelaars T. Expert gate: Lifelong learning with a network of experts[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 3366-3375.
- Li Z, Hoiem D. Learning without forgetting[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(12): 2935-2947.
- Rannen A, Aljundi R, Blaschko M B, et al. Encoder based lifelong learning[C]//Proceedings of the IEEE international conference on computer vision. 2017: 1320-1328.
- Shmelkov K, Schmid C, Alahari K. Incremental learning of object detectors without catastrophic forgetting[C]//Proceedings of the IEEE international conference on computer vision. 2017: 3400-3409.
3.2 基于模型的方法
- Fernando C, Banarse D, Blundell C, et al. Pathnet: Evolution channels gradient descent in super neural networks[J]. arXiv preprint arXiv:1701.08734, 2017.
- Lee S W, Kim J H, Jun J, et al. Overcoming catastrophic forgetting by incremental moment matching[J]. Advances in neural information processing systems, 2017, 30.
- Zenke F, Poole B, Ganguli S. Continual learning through synaptic intelligence[C]//International conference on machine learning. PMLR, 2017: 3987-3995.(和本文相似)
- Kirkpatrick J, Pascanu R, Rabinowitz N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of sciences, 2017, 114(13): 3521-3526.(和本文相似)
但是这些方法有缺点:
(1)EWC基于Fisher信息矩阵对角线的近似来估计参数的重要性,这可能不完全准确反映参数的真实重要性。
(2)EWC为每个先前任务使用单独的惩罚项,这在实际应用中可能计算量大且不可行,因此需要对惩罚项进行简化。
(3)SI在新任务训练期间以在线方式估计重要性权重,依赖于批量梯度下降中的权重变化,这可能会高估权重的重要性。
(4)SI算法当从预训练网络开始学习时,一些权重可能在使用中没有大的变化,导致它们的重要性被低估。
(5)SI在训练过程中计算重要性权重,并在训练结束后固定这些权重,这限制了模型对测试数据的适应性。
4 算法
(1)MAS全局版本
- 参数重要性估计:
- 对于数据点 x k x_k xk,计算网络输出函数 F ( x k ; θ ) F(x_k; \theta) F(xk;θ) 对参数 θ i j \theta_{ij} θij 的梯度 g i j ( x k ) = ∂ F ( x k ; θ ) ∂ θ i j g_{ij}(x_k) = \frac{\partial F(x_k; \theta)}{\partial \theta_{ij}} gij(xk)=∂θij∂F(xk;θ)。
- 为了简化计算,使用平方 ℓ2 范数的梯度:
g i j ( x k ) = ∂ [ ∣ ∣ F ( x k ; θ ) ∣ ∣ 2 2 ] ∂ θ i j g_{ij}(x_k) = \frac{\partial [|| F(x_k; \theta) ||_2^2]}{\partial \theta_{ij}} gij(xk)=∂θij∂[∣∣F(xk;θ)∣∣22]
- 累积梯度以计算重要性权重:
- 使用公式计算参数 θ i j \theta_{ij} θij 的重要性权重:
Ω i j = 1 N ∑ k = 1 N ∣ ∣ g i j ( x k ) ∣ ∣ \Omega_{ij} = \frac{1}{N} \sum_{k=1}^{N} || g_{ij}(x_k) || Ωij=N1k=1∑N∣∣gij(xk)∣∣
4. 学习新任务时的正则化:
- 新任务损失函数 L ( θ ) L(\theta) L(θ) 包括正则化项,正则化项事是惩罚了对之前任务重要参数 θ i j ∗ \theta_{ij}^* θij∗的改变。
L ( θ ) = L n ( θ ) + λ ∑ i , j Ω i j ( θ i j − θ i j ∗ ) 2 L(\theta) = L_n(\theta) + \lambda \sum_{i,j} \Omega_{ij} (\theta_{ij} - \theta_{ij}^*)2 L(θ)=Ln(θ)+λi,j∑Ωij(θij−θij∗)2
其中 λ \lambda λ 是正则化系数, θ i j ∗ \theta_{ij}^* θij∗ 是先前任务中确定的“旧”网络参数。
- 更新重要性权重:
- 训练新任务后,根据之前计算的 Ω \Omega Ω 更新重要性矩阵 Ω \Omega Ω。
(2)MAS局部版本
局部版本的MAS方法不是考虑整个网络学习到的函数F,而是将其分解为一系列对应于网络每层的函数Fl。通过局部地保留每层给定其输入的输出,可以保留全局函数F。
其中参数重要性可以通过神经元激活的相关性来衡量:
Ω i j = 1 N ∑ k = 1 N y i k ⋅ y j k \Omega{ij} = \frac{1}{N} \sum_{k=1}^{N} y_{i}^k \cdot y_{j}^k Ωij=N1k=1∑Nyik⋅yjk
对于 ReLU 激活函数,简化为:
g i j ( x k ) = 2 ⋅ y i k ⋅ y j k g_{ij}(x_k) = 2 \cdot y_{i}^k \cdot y_{j}^k gij(xk)=2⋅yik⋅yjk
其中 y i k y_{i}^k yik 和 y j k y_{j}^k yjk分别是输入 x k x_k xk对应的第i个和第j个神经元的激活值。
(3优缺点:
全局MAS方法
优点:
- 全面性:全局MAS考虑整个网络学习到的函数,从而评估参数对整体性能的影响,这有助于捕捉不同层级之间的相互作用。
- 精确性:通过计算整个网络输出的梯度,全局MAS可以更精确地评估参数的重要性。
- 适应性:能够适应不同的数据分布,因为它是基于网络最终输出的敏感度来评估参数的重要性。
- 通用性:适用于任何类型的数据和任务,因为它不依赖于特定层级的激活模式。
缺点:
- 计算成本:可能需要更多的计算资源,因为它需要对整个网络的输出函数进行梯度计算。
- 复杂性:实现起来可能比局部MAS更复杂,因为它涉及到整个网络的梯度传播。
局部MAS方法(基于Hebb理论)
优点:
- 计算效率:局部MAS通过仅考虑单层的激活来计算参数的重要性,这减少了计算量。
- 实现简单:由于其简单性,局部MAS更容易实现和集成到现有的神经网络架构中。
- 快速适应:可以快速适应新任务或数据,因为它只需要局部的激活信息。
- 与生物学习机制的联系:局部MAS与Hebb学习规则有直接联系,这为理解人工神经网络中的学习过程提供了生物学上的见解。
缺点:
- 可能的不准确性:由于它只考虑局部信息,可能会忽略不同层级间参数的相互作用,导致对参数重要性的估计不够准确。
- 过度依赖局部激活:如果局部激活不能很好地代表整个网络的行为,那么局部MAS可能无法正确评估参数的重要性。
- 特定任务的局限性:可能在某些任务或数据分布上表现不如全局MAS,特别是当任务需要跨层级的信息整合时。
5 实验分析
(1)对比的模型
本文中提到的对比模型包括以下几种:
- Finetuning (FineTune): 这是一种基线方法,当学习新任务时,对网络的参数进行微调,以适应新任务的数据。
- Learning without Forgetting (LwF): 该方法在面对新任务时,通过记录先前任务的输出概率,并在新的损失函数中使用这些概率作为目标,以减少对旧知识的遗忘。
- Encoder Based Lifelong Learning (EBLL): EBLL在LwF的基础上,为每个任务学习一个浅层编码器,并应用变化惩罚和知识蒸馏损失来减少对先前任务的遗忘。
- Incremental Moment Matching (IMM): IMM通过对共享参数的变化施加L2惩罚来学习新任务,并在序列结束时通过第一或第二矩匹配合并模型。
- Elastic Weight Consolidation (EWC): EWC是首个提出在新任务学习时使用正则化网络参数的方法,它使用Fisher信息矩阵的对角线作为重要性度量。
- Synaptic Intelligence (SI): SI在训练新任务时,以在线方式估计重要性权重,并在训练后期任务时对先前任务的重要参数变化进行惩罚。
- Memory Aware Synapses (MAS): 本文提出的新方法,它通过无监督和在线的方式计算神经网络参数的重要性,基于预测输出函数对参数变化的敏感度。
(2)分类任务分析
实验使用基于三个数据集的两任务序列:MIT Scenes(室内场景分类)、Caltech-UCSD Birds(细粒度鸟类分类)和Oxford Flowers(细粒度花卉分类)。将MAS方法与其他几种终身学习(LLL)方法进行了比较,包括Finetune(微调)、Learning without Forgetting (LwF)、Encoder Based Lifelong Learning (EBLL)、Incremental Moment Matching (IMM)、Elastic Weight Consolidation (EWC)和Synaptic Intelligence (SI)。

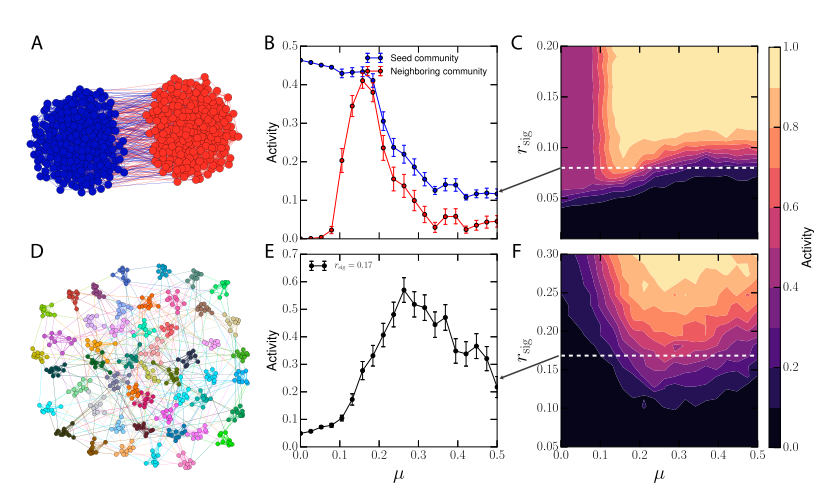
每个任务的分类准确率。从图中可以看出,Finetune基线方法在新任务上性能较好,但在旧任务上性能下降显著,这表明了灾难性遗忘的问题。相比之下,MAS方法在所有任务上都显示出较高的准确率,并且与其他终身学习方法相比,其性能下降非常小。

为性能下降情况。FineTune方法在旧任务上的性能下降非常严重,这再次证实了其在连续学习中的不足。其他方法如LwF、EBLL、IMM、EWC和SI都显示出一定程度的遗忘,但遗忘程度较Finetune有所减轻。MAS方法在所有任务上的遗忘率最低,显示出最小的性能下降,这表明其在终身学习环境中对旧知识的保留效果最好。
(3)内存容量要求

- MAS (Memory Aware Synapses):本文提出的方法,它在每个学习步骤中的内存需求是所有方法中最低的,这表明MAS在处理遗忘问题时非常内存高效。
- SI、EWC、**LwF **、EBLL 和 IMM的内存需求随着任务序列的进行而逐渐增加。特别是IMM方法,其内存需求随任务数量线性增长,因为它需要存储所有任务的模型。
(4)敏感度分析

在一系列经过排列的MNIST任务中,平均性能和平均遗忘率随超参数λ的变化情况。
- 超参数λ的影响:λ是全局MAS方法中用于权衡新任务学习和旧任务遗忘的正则化项的权重。通过改变λ的值,可以观察到模型在新任务学习性能和旧任务遗忘之间的权衡。
- 性能与遗忘的平衡:从图中可以看出,当λ的值增加时,模型倾向于更多地保留旧任务的知识,从而减少遗忘。然而,如果λ过大,可能会对新任务的学习造成负面影响,因为模型过于保守,不愿意对参数进行足够的更新。
(5)检索任务性能分析
在6DS数据集的体育子集上,经过4个任务序列学习后,每种方法的平均精度均值(Mean Average Precision, MAP)的变化情况。MAP是信息检索和计算机视觉领域常用的性能指标,用于衡量模型对于检索任务的准确性。6DS数据集,全称为"Six Domains Dataset",是一个用于事实学习(Fact Learning)的中等规模数据集。它专门设计用于支持图像中事实的学习和检索任务,例如理解图像中的对象、属性和它们之间的关系。6DS数据集通常包含多种类别的图像,并且每个图像都与一个或多个事实相关联,这些事实以三元组的形式表示,包括主体(Subject)、谓语(Predicate)和对象(Object)。

与其他方法相比,MAS在体育子集上的MAP值下降较少,表明其在面对新任务时,能够更有效地保留先前任务的知识,减少灾难性遗忘。
6 思考
(1)MAS算法缺点
- 超参数调整:MAS算法引入了一个新的超参数λ,用于平衡新任务学习和旧任务遗忘之间的权衡。确定合适的λ值可能需要额外的调整工作,这可能在实际应用中增加复杂性。
- 计算资源:尽管MAS算法在内存效率方面有所优化,但在计算参数重要性时,尤其是在使用全局版本时,可能需要较多的计算资源,尤其是当数据集很大时。
- 适应性:MAS算法能够根据未标记的测试数据自适应地调整参数重要性,但在某些情况下,这种自适应性可能不如预期,特别是如果测试条件与训练条件差异很大时。
- 局部与全局方法的权衡:论文中提到了MAS的局部版本(基于Hebb理论)和全局版本。局部版本计算更快,但可能在准确性上有所折衷。选择使用哪种版本可能取决于具体应用的需求。
- 特定任务的泛化能力:MAS算法在论文中的任务上表现良好,但其泛化能力到其他类型的问题或任务上可能会有所不同,这需要在更广泛的任务和数据集上进行验证。
- 灾难性遗忘问题:尽管MAS算法旨在减少灾难性遗忘,但在学习大量新任务或非常不同的任务时,仍然可能面临知识遗忘的挑战。
- 实际应用的复杂性:在实际应用中,可能需要进一步的调整和优化,以适应特定的数据分布、任务特性或计算约束。
- 理论基础与实际效果的验证:MAS算法虽然在理论上受到Hebb学习规则的启发,但其在真实世界数据和任务上的有效性需要通过更多的实验来验证。
- 长期维护和更新:在长期学习和连续任务中,MAS算法可能需要持续的维护和更新,以适应不断变化的数据和任务需求。
- 对特定数据类型的依赖:MAS算法可能对某些类型的数据更加敏感,例如,如果数据具有特定的分布特性或噪声模式,算法的效果可能会受到影响。
(2)如何计算使用平方 ℓ2 范数的梯度,为什么要这么计算来表示参数的重要性?
- 简化计算:如果直接使用多维输出的每个维度来计算梯度,就需要对每个输出维度执行一次反向传播,这将需要与输出维度数量相同次数的计算。而使用平方 ℓ 2 \ell_2 ℓ2范数,可以得到一个标量值,这意味着只需要一次反向传播,从而简化了计算过程。
- 避免梯度接近零的问题:在某些情况下,如果模型已经收敛到局部最小值,那么基于损失函数的梯度可能会非常小,这会导致参数重要性的估计不准确。使用输出函数的敏感度而不是损失函数的梯度可以避免这个问题,因为输出函数不太可能处于局部最小值。
- 与Hebb学习规则的联系:在文中提到的局部MAS方法中,使用平方 ℓ 2 \ell_2 ℓ2 范数的梯度与Hebb学习理论相联系。Hebb理论指出,如果两个神经元的激活同时发生,它们之间的突触连接应该被加强。在人工神经网络中,这可以被解释为如果两个神经元的激活值高度相关,那么它们之间的连接权重就更重要。平方 ℓ 2 \ell_2 ℓ2范数的梯度可以反映这种相关性。
- 参数重要性的准确估计:通过平方 ℓ 2 \ell_2 ℓ2范数的梯度,可以更准确地衡量参数对输出的影响。如果一个参数的小变化导致输出的平方 ℓ 2 \ell_2 ℓ2范数有较大变化,那么这个参数对模型的预测就非常重要。
- 无监督和在线适应性:使用平方 ℓ 2 \ell_2 ℓ2范数的梯度允许模型在无监督的情况下在线地适应新数据。这意味着模型可以在没有标签数据的情况下,根据输入数据动态调整参数的重要性权重。
- 提高效率:相比于基于损失的权重变化,使用平方 ℓ 2 \ell_2 ℓ2范数的梯度可以更高效地估计参数的重要性,因为它只需要一次反向传播,并且可以利用所有可用的数据点来更新权重的重要性,而不需要额外的存储或处理。