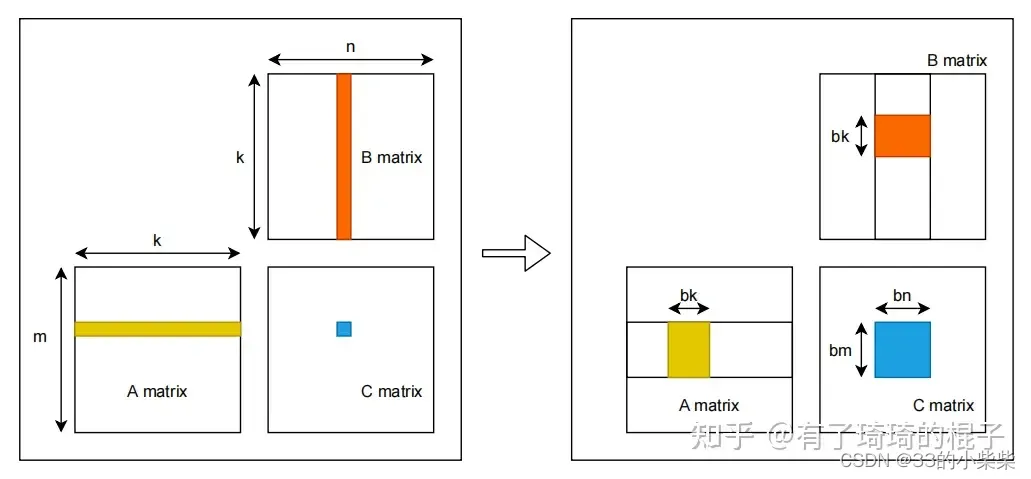
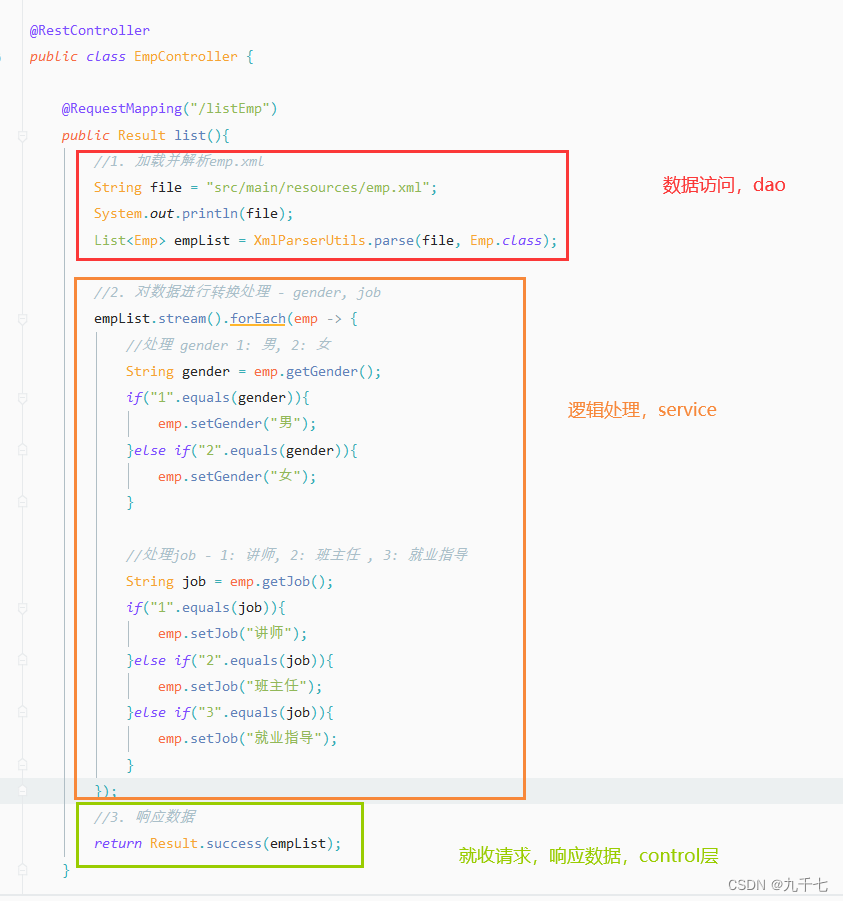
在 Windows 上安装 Spark 并进行配置需要一些步骤,包括安装必要的软件和配置环境变量。以下是详细的步骤指南:
步骤一:安装 Java
下载和安装 Java Development Kit (JDK)
- 到 Oracle JDK 下载页面 或 OpenJDK 下载页面 下载适合你系统的 JDK。
- 安装 JDK,记住安装路径。
配置环境变量
右键点击“此电脑”或“计算机”,选择“属性”。
点击“高级系统设置”。
点击“环境变量”。
在“系统变量”下,点击“新建”,然后添加以下内容:
- 变量名:
JAVA_HOME - 变量值:JDK 安装路径(例如:
C:\Program Files\Java\jdk-11.0.10)
- 变量名:
找到
Path变量,选择它并点击“编辑”。在变量值的末尾添加以下内容:%JAVA_HOME%\bin
步骤二:安装 Hadoop
下载 Hadoop 二进制文件
- 到 Hadoop 官方网站 下载最新的二进制发行版,例如
hadoop-3.3.1.tar.gz。 - 解压缩文件到你的本地目录,例如
C:\hadoop-3.3.1。
- 到 Hadoop 官方网站 下载最新的二进制发行版,例如
配置 Hadoop 环境变量
回到“环境变量”窗口,点击“新建”,然后添加以下内容:
- 变量名:
HADOOP_HOME - 变量值:Hadoop 安装路径(例如:
C:\hadoop-3.3.1)
- 变量名:
编辑
Path变量,在变量值的末尾添加以下内容:%HADOOP_HOME%\bin
配置 Hadoop Winutils
- 下载 Hadoop 的 winutils.exe 文件,可以从 GitHub 仓库 找到对应版本。
- 将
winutils.exe放到C:\hadoop-3.3.1\bin目录下。
步骤三:安装 Apache Spark
下载 Spark
- 到 Spark 官方网站 下载预编译的 Spark 版本,例如
spark-3.1.2-bin-hadoop3.2.tgz。 - 解压缩文件到你的本地目录,例如
C:\spark-3.1.2-bin-hadoop3.2。
- 到 Spark 官方网站 下载预编译的 Spark 版本,例如
配置 Spark 环境变量
回到“环境变量”窗口,点击“新建”,然后添加以下内容:
- 变量名:
SPARK_HOME - 变量值:Spark 安装路径(例如:
C:\spark-3.1.2-bin-hadoop3.2)
- 变量名:
编辑
Path变量,在变量值的末尾添加以下内容:%SPARK_HOME%\bin
步骤四:验证安装
打开命令提示符
- 按
Win + R打开“运行”窗口,输入cmd并按Enter。
- 按
验证 Java 安装
- 在命令提示符中输入:
java -version - 应该显示已安装的 Java 版本。
- 在命令提示符中输入:
验证 Hadoop 安装
- 在命令提示符中输入:
hadoop version - 应该显示已安装的 Hadoop 版本。
- 在命令提示符中输入:
验证 Spark 安装
- 在命令提示符中输入:
spark-shell - 应该启动 Spark Shell 并显示 Spark 版本和其他信息。
- 在命令提示符中输入:
步骤五:运行 Spark 示例
- 在命令提示符中
- 进入 Spark 安装目录,例如:
cd C:\spark-3.1.2-bin-hadoop3.2 - 运行 Spark 示例:
bin\spark-submit --class org.apache.spark.examples.SparkPi examples\jars\spark-examples_2.12-3.1.2.jar 10 - 这将运行 Spark Pi 示例并输出结果。
- 进入 Spark 安装目录,例如:
通过以上步骤,你已经在 Windows 系统上成功安装并配置了 Spark,可以开始进行分布式数据处理和分析任务。如果在安装过程中遇到问题,请确保每一步的环境变量配置和软件版本匹配。