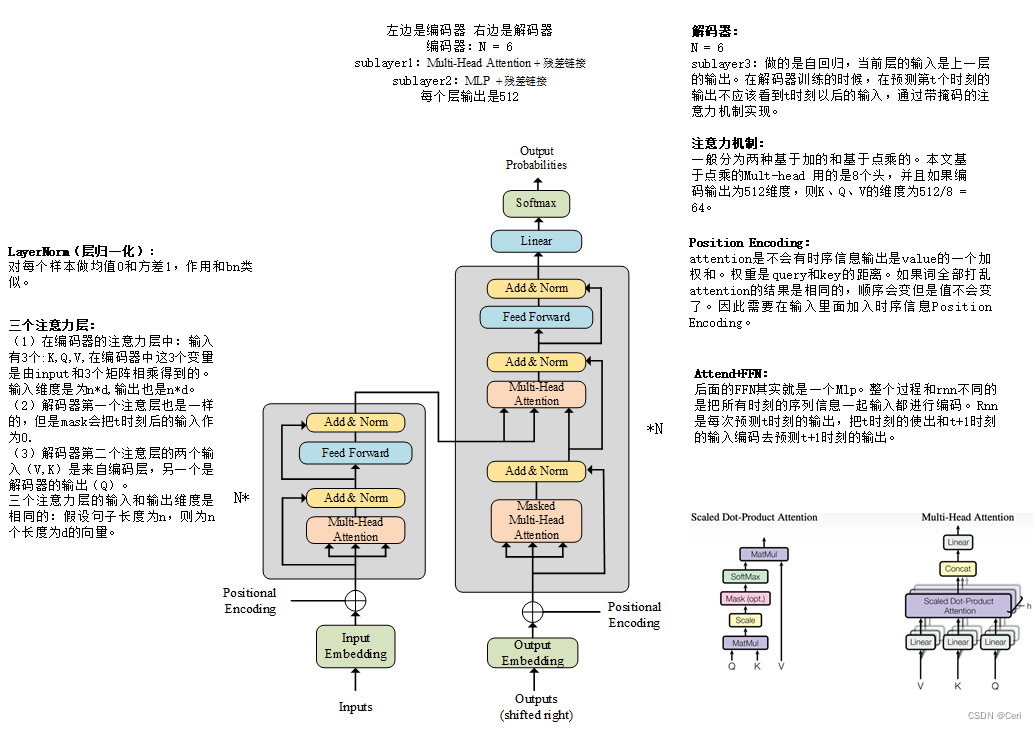
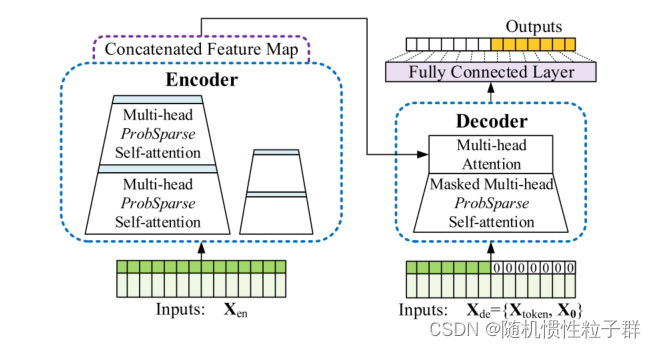
详细解释Informer模型的各部分

1. 输入时间序列 ( T )
- 时间戳 ( t ):
- 代表每个数据点的时间信息。例如,时间戳可能是具体的日期和时间,如“2024-06-01 00:00”。
- 标量 ( D_x ):
- 代表时间序列的具体值,例如温度、湿度等。在我们的例子中,标量可能是“20.5℃”这样的温度值。
2. Embedding 层
- 目的:将输入的时间序列数据转换成高维特征向量,以便后续处理。
- 步骤:
- 时间戳嵌入:
- 使用一维卷积层(Conv1d)将时间戳转换成高维向量。
- 例如,将时间戳“2024-06-01 00:00”通过卷积操作得到一个长度为d的向量。
- 标量嵌入:
- 同样使用一维卷积层(Conv1d)将标量数据转换成高维向量。
- 例如,将温度“20.5℃”通过卷积操作得到一个长度为d的向量。
- 特征融合:
- 将时间戳嵌入向量和标量嵌入向量相加,得到综合的特征表示。
- 时间戳嵌入:
3. Attention Block 1
- 目的:捕捉时间序列中的长短期依赖关系。
- 步骤:
- 多头自注意力(Multi-Head Self-Attention):
- 将嵌入的特征向量通过多头自注意力机制处理。每个头捕捉不同的依赖关系。
- 例如,一个注意力头可能关注过去几个小时的温度变化,另一个注意力头可能关注一天内的温度变化。
- 位置编码(Positional Encoding):
- 为了保留序列的位置信息,可能会加入位置编码。
- 多头自注意力(Multi-Head Self-Attention):
4. MaxPooling 1d
- 目的:通过降采样减少特征图的尺寸,保留最重要的特征。
- 步骤:
- 最大池化:
- 对注意力块输出的特征进行最大池化操作,通常每两个值取一个最大值。
- 例如,如果输入特征为[1, 3, 2, 4],最大池化后的输出为[3, 4]。
- 最大池化:
5. Attention Block 2 和 Attention Block 3
- 目的:进一步提取特征,捕捉更深层次的依赖关系。
- 步骤:
- 重复多头自注意力机制:
- 每个Attention Block都会再次使用多头自注意力机制处理特征。
- 捕捉更多层次的时间序列依赖关系。
- 重复最大池化:
- 每个Attention Block之后都会进行最大池化操作,进一步降采样。
- 重复多头自注意力机制:
6. 最终特征图(Feature Map)
- 目的:得到最终的特征表示,用于后续的预测任务。
- 步骤:
- 输出特征图:
- 通过多次Attention Block和Pooling操作,最终得到的特征图是一个压缩但具有代表性的高维向量。
- 预测任务:
- 这个特征图可以输入到预测模块,例如全连接层(Fully Connected Layer)进行时间序列预测。
- 在我们的温度预测例子中,最终的特征图用于预测未来一周的温度值。
- 输出特征图:
示例说明
假设我们有一个气象站的数据集,记录了每小时的温度(标量数据)和时间戳。我们希望使用Informer模型来预测未来一周的温度。
输入数据准备
- 输入数据 ( T ) 包含时间戳和温度值。
- 示例数据可能为:
[(2024-06-01 00:00, 20.5), (2024-06-01 01:00, 21.0), ...]
Embedding 层处理
- 时间戳通过Conv1d层转换成高维向量,例如
[0.1, 0.3, 0.5, ..., 0.2]。 - 温度值通过另一个Conv1d层转换成高维向量,例如
[0.5, 0.6, 0.7, ..., 0.4]。 - 两者相加,得到综合的特征表示。
- 时间戳通过Conv1d层转换成高维向量,例如
Attention Block 处理
- 多头注意力机制捕获温度时间序列中的依赖关系。
- 例如,某个注意力头可能发现凌晨2点的温度与上午8点的温度有很强的相关性。
MaxPooling 1d 处理
- 最大池化层对特征进行降采样。
- 保留最重要的特征,减少计算量。
重复Attention Block 和 Pooling
- 进一步提取特征,捕获更深层次的依赖关系。
- 多次降采样使得特征图逐渐变小但更具代表性。
最终特征图
- 最终得到的特征图用于预测未来一周的温度。
- 预测结果可能为未来一周每天的最高温度和最低温度。
通过这些步骤,Informer模型可以有效地处理时间序列数据,捕捉复杂的时间依赖关系,从而进行准确的时间序列预测。