1. 引言
1.1.研究背景
随着科技的进步和互联网的普及,人们对搜索图像的方式提出了更高要求。首先,用户渴望一种更直观、更便捷的搜索方式。自然语言搜索图像技术应运而生,它允许用户以自然语言描述他们的搜索需求,无需精确选择关键词,大大提高了搜索的直观性和便捷性。无论是通过语音输入还是文本输入,用户都能轻松表达意图,快速找到想要的图像内容。
其次,随着图像数据的快速增长,传统的基于关键词的图像搜索方式已经无法满足用户对于搜索准确性和效率的需求。自然语言搜索图像技术通过结合自然语言处理和图像识别技术,能够深入理解用户的查询意图,并据此提供更准确的搜索结果。它能够处理复杂的查询需求,包括多个概念、关系和约束条件的组合,从而满足用户多样化的搜索需求。这种技术对于大规模图像数据的快速、准确处理具有重要意义。
最后,自然语言搜索图像技术还具有广阔的市场应用和商业潜力。在电商、社交媒体、医疗等多个领域,它都有着广泛的应用前景。通过自然语言搜索图像技术,用户能够更快速地找到他们想要的商品、分享图片资源,提高购买转化率。对于企业而言,这种技术能够提升用户体验和满意度,进而增加商业价值。因此,研究自然语言搜索图像技术具有重要的现实意义和商业价值。
1.2 双塔模型
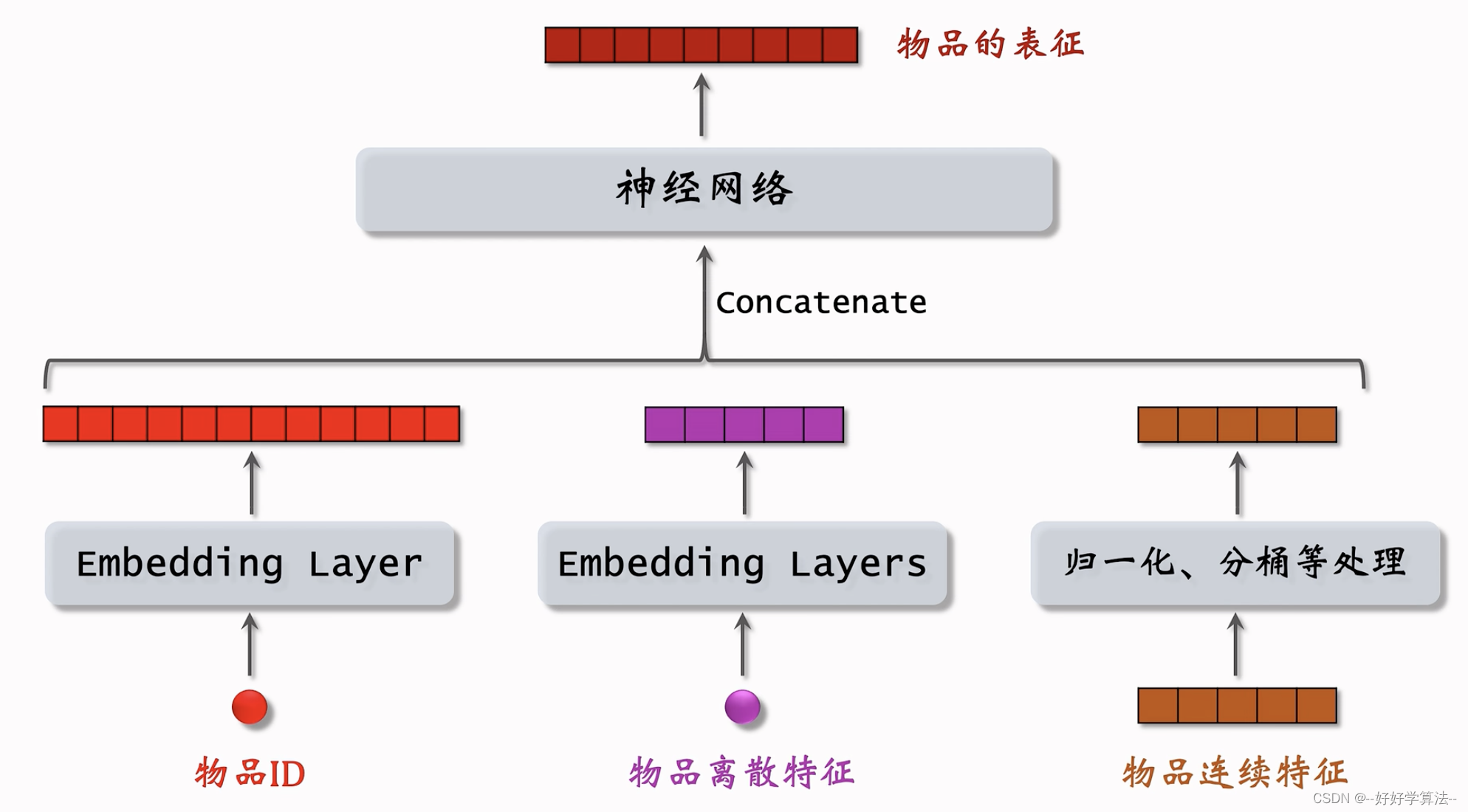
Dual Encoder 模型是一种特殊的神经网络架构,它采用了两个并行的编码器来分别处理不同类型的输入数据,例如文本和图像。这种模型的主要目标是学习文本和图像之间的关联,从而能够完成诸如跨模态检索、图像描述生成等任务。
1.2.1.模型结构
Dual Encoder 模型通常由两个编码器和一个相似度计算模块组成:
- 文本编码器:文本编码器通常是一个循环神经网络(RNN)或其变体(如LSTM、GRU),它能够捕捉文本中的序列信息。文本编码器将输入的文本序列(如单词、句子或段落)编码为一个固定长度的向量表示,这个向量捕捉了文本的主要语义信息。
- 图像编码器:图像编码器则是一个卷积神经网络(CNN),它能够从输入的图像中提取特征。图像编码器将图像转换为一个或多个特征向量,这些向量包含了图像中的视觉信息。
- 相似度计算模块:在得到文本和图像的向量表示后,相似度计算模块会计算这两个向量之间的相似度得分。常用的相似度度量方法包括余弦相似度、欧氏距离等。这个相似度得分反映了文本和图像之间的匹配程度。
1.2.2.工作原理
在训练阶段,Dual Encoder 模型会接收成对的文本和图像作为输入,并学习如何将这些输入编码为向量表示。同时,模型还会根据一个损失函数(如三元组损失、对比损失等)来优化编码器的参数,使得相似的文本和图像对在向量空间中的距离更近,而不相似的对则距离更远。
在推理阶段,给定一个文本查询,模型可以使用文本编码器将其编码为一个向量表示。然后,模型可以通过计算这个向量与所有图像向量的相似度得分,来找到与给定文本最匹配的图像。
1.2.3.应用场景
Dual Encoder 模型在多个跨模态任务中都有广泛的应用,包括:
- 跨模态检索:在给定一个文本查询时,从图像库中找到与查询最相关的图像。
- 图像描述生成:根据输入的图像,生成描述该图像的文本。
- 视觉问答:根据输入的图像和文本问题,生成问题的答案。
1.2.4.技术细节
- 编码器选择:对于文本编码器,可以选择不同类型的RNN或其变体,具体取决于任务的复杂性和数据的特点。对于图像编码器,常用的CNN结构包括VGG、ResNet等。
- 损失函数设计:损失函数的设计对于模型的性能至关重要。常用的损失函数包括三元组损失、对比损失等,它们能够使得相似的文本和图像对在向量空间中的距离更近,而不相似的对则距离更远。
- 相似度度量方法:除了余弦相似度和欧氏距离外,还可以使用其他更复杂的相似度度量方法,如基于学习的度量方法。
1.3.自然语言搜索图像
自然语言搜索图像技术是一种结合自然语言处理(NLP)和图像识别技术的搜索方法,它允许用户通过自然语言查询来检索相关的图像。以下是关于自然语言搜索图像技术的清晰概述:
1.3.1. 技术原理
- 自然语言处理(NLP):NLP技术用于理解和解析用户的自然语言查询。它涉及词汇分析、句法分析、语义理解等步骤,以捕捉查询中的关键信息和意图。
- 图像识别:图像识别技术用于从图像中提取特征,并将其转换为计算机可理解的表示形式(如特征向量)。这通常通过深度学习算法(如卷积神经网络CNN)实现,这些算法能够学习并识别图像中的关键元素和模式。
1.3.2. 工作流程
- 用户输入:用户输入自然语言查询,表达他们想要搜索的图像内容或主题。
- NLP处理:NLP系统对查询进行解析,识别其中的关键词、短语和概念。它还可以利用同义词、上下文等信息来增强查询的语义理解。
- 图像标记与索引:在图像库中,每个图像都被自动标记和索引。这些标记通常基于图像的视觉特征(如对象、场景、颜色等)和/或基于图像的自然语言描述(如图像标题、标签等)。
- 查询与图像匹配:NLP系统将解析后的查询映射到与图像标记相关的概念或特征上。然后,系统计算查询与图像标记之间的相似度或距离度量(如余弦相似度),以找出与查询最匹配的图像。
- 结果展示:系统根据相似度得分对匹配的图像进行排序,并将最相关的图像展示给用户。用户还可以根据需要进行进一步的筛选和浏览。
1.3.3. 关键技术
- 自然语言处理技术:包括词汇分析、句法分析、语义理解等,用于解析和增强查询的语义信息。
- 图像识别技术:如卷积神经网络CNN,用于从图像中提取关键特征和模式。
- 相似度度量方法:如余弦相似度、欧氏距离等,用于计算查询与图像标记之间的相似度。
1.3.4. 应用场景
- 可视化搜索:允许用户通过自然语言描述来搜索图像,提高搜索的直观性和便捷性。
- 图像描述生成:结合图像识别技术,为图像自动生成自然语言描述,有助于图像内容的理解和传播。
- 智能推荐:根据用户的查询和浏览历史,为用户推荐相关的图像内容,提升用户体验和满意度。
1.3.5. 挑战与未来
- 语义理解深度:提高NLP系统对自然语言查询的语义理解能力,以更准确地匹配用户意图和图像内容。
- 图像标记准确性:提高图像标记的准确性和丰富性,以更好地表达图像的内容和特征。
- 多模态融合:结合文本、图像、视频等多种模态的信息,实现更全面的搜索和推荐功能。
自然语言搜索图像技术通过结合NLP和图像识别技术,为用户提供了更直观、便捷的图像搜索体验。随着技术的不断发展和完善,相信未来它将在更多领域发挥重要作用。
2. 自然语言图像搜索过程
在本文中,我们将探讨如何使用双编码器(通常被称为双塔)神经网络模型,来实现通过自然语言搜索图像的功能。该模型受到Alec Radford等人提出的CLIP(Contrastive Language-Image Pre-training)方法的启发。CLIP方法的核心思想是通过共同训练一个视觉编码器和一个文本编码器,将图像和它们的文本描述投影到同一个嵌入空间中。这样,描述同一图像内容的文本嵌入将会位于该图像嵌入的附近,从而实现通过自然语言搜索相关图像的功能。
为了构建这样的模型,我们将利用TensorFlow这一强大的深度学习框架,并假定读者已经安装了TensorFlow 2.4或更高版本。同时,为了实现高质量的文本表示,我们将采用BERT模型作为我们的文本编码器,这需要我们安装TensorFlow Hub和TensorFlow Text库。TensorFlow Hub提供了大量预训练的模型和模块,而TensorFlow Text则提供了文本处理所需的工具和函数。
此外,为了优化模型的训练过程,我们将使用AdamW优化器,它是Adam优化器的一个变种,加入了权重衰减项以改进正则化效果。为了使用AdamW优化器,我们需要安装TensorFlow Addons库,它提供了许多额外的TensorFlow功能和工具。
2.1. 设置
import os
# 导入用于处理文件和目录的库
import collections
# 导入JSON模块用于处理JSON格式的数据
import json
# 导入NumPy库,用于科学计算
import numpy as np
# 导入TensorFlow库,用于深度学习模型的构建和训练
import tensorflow as tf
# 从TensorFlow中导入Keras API
from tensorflow import keras
# 从Keras中导入各种层
from tensorflow.keras import layers
# 导入TensorFlow Hub库,用于加载预训练的模型
import tensorflow_hub as hub
# 导入TensorFlow Text库,用于文本处理
import tensorflow_text as text
# 导入TensorFlow Addons库,该库提供了TensorFlow的额外功能和优化器
import tensorflow_addons as tfa
# 导入Matplotlib库,用于数据可视化
import matplotlib.pyplot as plt
# 导入Matplotlib的图像处理模块
import matplotlib.image as mpimg
# 导入tqdm库,用于显示进度条
from tqdm import tqdm
# 禁用tf.hub的警告信息
# 这里使用setLevel方法将TensorFlow的日志级别设置为ERROR,从而只显示错误信息
tf.get_logger().setLevel("ERROR")
2.2. 数据预处理
为了准备数据并训练双编码器模型,我们首先需要下载MS-COCO数据集,并处理图像和标题以适用于我们的任务。以下是一个简化的步骤来下载、解压并准备MS-COCO数据集:
- 下载数据集
MS-COCO数据集可以从官方网站(https://cocodataset.org/#home)下载。由于数据集较大,您可能需要使用命令行工具(如wget或curl)或下载管理器来下载。通常,您需要下载train2017和annotations_trainval2017(或根据您的需求选择其他子集)的压缩文件。
- 解压数据集
将下载的压缩文件解压到您的工作目录。对于Linux或macOS,您可以使用unzip或tar命令来解压。对于Windows,您可以使用7-Zip或Windows自带的解压工具。
解压后的train2017文件夹将包含图像,而annotations_trainval2017文件夹将包含与图像相关的注释文件。
- 准备数据
接下来,您需要编写代码来读取图像和相关的标题注释,并将它们转换为您的模型可以使用的格式。这通常包括以下几个步骤:
- 读取
annotations_trainval2017/captions_train2017.json文件,它包含了训练图像的标题注释。 - 解析JSON文件,提取图像ID和相关的标题列表。
- 根据图像ID从
train2017文件夹中加载相应的图像。 - 将图像和标题转换为模型可以接受的张量格式(例如,图像可能需要预处理并转换为浮点张量,而标题可能需要通过BERT模型进行编码)。
- 数据增强和划分
为了训练模型,您可能还需要对数据进行增强(如随机裁剪、翻转等)以增加模型的泛化能力。此外,您还需要将数据集划分为训练集和验证集(如果有必要,还可以包括测试集)。
- 构建数据加载器
使用TensorFlow的tf.data API构建数据加载器,以便在训练过程中高效地加载和批处理数据。
2.2.1.下载数据集
以下代码是一个数据预处理脚本,目的是将原始的MS-COCO数据集整理成适合机器学习模型训练的格式,特别是为图像搜索任务准备数据。通过这个脚本,可以确保数据集的完整性和可用性,为后续的模型训练打下基础。
import os
import json
import collections
import tensorflow as tf
# 定义数据集根目录变量
root_dir = "datasets"
# 构造注释文件和图像文件的目录路径
annotations_dir = os.path.join(root_dir, "annotations") # 注释文件目录
images_dir = os.path.join(root_dir, "train2014") # 图像文件目录
tfrecords_dir = os.path.join(root_dir, "tfrecords") # TFRecords文件目录
annotation_file = os.path.join(annotations_dir, "captions_train2014.json") # 注释文件路径
# 下载并解压注释文件
if not os.path.exists(annotations_dir):
# 使用tf.keras.utils.get_file下载文件并自动解压
annotation_zip = tf.keras.utils.get_file(
"captions.zip", # 下载后文件名
cache_dir=os.path.abspath("."), # 缓存目录
origin="http://images.cocodataset.org/annotations/annotations_trainval2014.zip", # 文件原始URL
extract=True, # 是否解压
)
# 下载完成后删除压缩文件
os.remove(annotation_zip)
# 下载并解压图像文件
if not os.path.exists(images_dir):
# 使用tf.keras.utils.get_file下载文件并自动解压
image_zip = tf.keras.utils.get_file(
"train2014.zip", # 下载后文件名
cache_dir=os.path.abspath("."), # 缓存目录
origin="http://images.cocodataset.org/zips/train2014.zip", # 文件原始URL
extract=True, # 是否解压
)
# 下载完成后删除压缩文件
os.remove(image_zip)
print("数据集已成功下载并解压。")
# 读取注释文件
with open(annotation_file, "r") as f:
annotations = json.load(f)["annotations"]
# 使用collections.defaultdict来存储图像路径和对应的注释列表
image_path_to_caption = collections.defaultdict(list)
# 遍历注释,为每个图像路径添加注释
for element in annotations:
caption = f"{element['caption'].lower().rstrip('.')}" # 格式化注释文本
image_path = os.path.join(images_dir, f"COCO_train2014_{'{'}{'0:012d}'.format(element['image_id'])}.jpg") # 构造图像文件路径
image_path_to_caption[image_path].append(caption) # 将注释添加到对应图像路径的列表中
# 获取所有图像路径列表
image_paths = list(image_path_to_caption.keys())
# 打印图像数量
print(f"图像数量: {len(image_paths)}")
代码的主要功能是处理MS-COCO数据集,包括下载、解压数据集文件,以及从注释文件中提取图像路径和对应的注释,为后续的图像搜索任务做准备。以下是代码各部分的具体功能解读:
- 定义目录变量:
root_dir:设置数据集的根目录。annotations_dir、images_dir、tfrecords_dir:基于root_dir,分别设置注释文件、训练图像和TFRecords文件的目录。
- 下载和解压注释文件:
- 检查注释文件目录是否存在,如果不存在,则使用
tf.keras.utils.get_file下载注释文件压缩包,并自动解压到指定目录。 - 下载完成后,删除压缩文件以节省空间。
下载和解压图像文件:类似于注释文件的处理,检查图像文件目录是否存在,不存在则下载并解压图像文件压缩包。
读取注释文件:使用
json.load读取注释文件,获取所有注释数据。构建图像路径与注释的映射:
- 使用
collections.defaultdict创建一个默认值为列表的字典,用于存储每个图像路径对应的注释列表。
- 使用
- 遍历注释数据,对于每条注释,构造图像的完整路径,并将其添加到字典中。
打印图像数量: 获取所有图像路径的列表,并打印出图像的数量,以确认数据集的大小。
输出信息:在数据集下载和解压成功后,打印一条成功信息。
2.2.2.数据转化为TFRecord格式
程序员可以通过修改sample_size参数来控制用于训练双编码器模型的图像-标题对的数量。在这个例子中,我们将train_size设置为30,000张图像,这大约是数据集的35%。我们为每个图像使用2个标题,因此产生了60,000个图像-标题对。训练集的大小会影响生成的编码器的质量,但更多的样本会导致更长的训练时间。
以下是一个简化的流程,说明如何将MS-COCO数据集处理和保存为TFRecord文件,用于训练双编码器模型:
读取MS-COCO数据集:首先,你需要读取MS-COCO数据集的图像和标题注释。
选择样本:根据
sample_size参数,随机选择一部分图像和对应的标题。在这个例子中,我们将sample_size设置为30,000。预处理图像:将图像调整为模型所需的尺寸(例如,224x224),并将其归一化到0-1的范围。
预处理标题:如果使用的是BERT模型,你需要将标题转换为BERT可以处理的格式(如token IDs和注意力掩码)。
创建TFRecord文件:使用TensorFlow的
tf.io.TFRecordWriter将预处理后的图像和标题写入TFRecord文件。每个TFRecord文件可以包含多个图像-标题对。保存TFRecord文件:将TFRecord文件保存到磁盘上,以便在训练模型时使用。
import os
import numpy as np
import tensorflow as tf
from tqdm import tqdm # 进度条显示库
# 设置训练集和验证集的大小,以及每个图像对应的注释数量和每个TFRecord文件中图像的数量
train_size = 30000
valid_size = 5000
captions_per_image = 2
images_per_file = 2000
# 根据设置的大小截取训练集和验证集的图像路径
train_image_paths = image_paths[:train_size]
# 计算训练集需要的TFRecord文件数量
num_train_files = int(np.ceil(train_size / images_per_file))
# 设置训练集TFRecord文件的前缀
train_files_prefix = os.path.join(tfrecords_dir, "train")
# 对验证集也进行相同的操作
valid_image_paths = image_paths[-valid_size:]
num_valid_files = int(np.ceil(valid_size / images_per_file))
valid_files_prefix = os.path.join(tfrecords_dir, "valid")
# 确保TFRecord文件存储目录存在
tf.io.gfile.makedirs(tfrecords_dir)
# 定义一个函数,用于创建字节特征
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 定义一个函数,用于创建TFRecord中的例子
def create_example(image_path, caption):
feature = {
"caption": bytes_feature(caption.encode()), # 将注释编码为字节特征
"raw_image": bytes_feature(tf.io.read_file(image_path).numpy()), # 读取图像文件并转换为字节特征
}
return tf.train.Example(features=tf.train.Features(feature=feature))
# 定义一个函数,用于将图像路径和注释写入TFRecord文件
def write_tfrecords(file_name, image_paths):
caption_list = []
image_path_list = []
# 为每个图像收集指定数量的注释
for image_path in image_paths:
captions = image_path_to_caption[image_path][:captions_per_image]
caption_list.extend(captions)
image_path_list.extend([image_path] * len(captions))
# 写入TFRecord文件
with tf.io.TFRecordWriter(file_name) as writer:
for example_idx in range(len(image_path_list)):
example = create_example(
image_path_list[example_idx], caption_list[example_idx]
)
writer.write(example.SerializeToString())
# 返回写入的例子总数
return example_idx + 1
# 定义一个函数,用于批量写入TFRecord文件
def write_data(image_paths, num_files, files_prefix):
example_counter = 0 # 初始化例子计数器
for file_idx in tqdm(range(num_files)): # 显示进度条
file_name = files_prefix + "-%02d.tfrecord" % (file_idx) # 构造文件名
start_idx = images_per_file * file_idx # 计算起始索引
end_idx = start_idx + images_per_file # 计算结束索引
# 调用write_tfrecords函数,并更新例子计数器
example_counter += write_tfrecords(file_name, image_paths[start_idx:end_idx])
return example_counter # 返回总例子数
# 调用write_data函数,为训练集和验证集写入TFRecord文件,并打印写入的例子数量
train_example_count = write_data(train_image_paths, num_train_files, train_files_prefix)
print(f"{train_example_count} 训练例子被写入到tfrecord文件中。")
valid_example_count = write_data(valid_image_paths, num_valid_files, valid_files_prefix)
print(f"{valid_example_count} 验证例子被写入到tfrecord文件中。")
代码的主要功能是:
- 定义训练集和验证集的大小,以及每个图像的注释数量和每个TFRecord文件的图像数量。
- 根据定义的大小,从图像路径列表中截取训练集和验证集的图像路径。
- 计算所需的TFRecord文件数量,并设置文件名前缀。
- 确保TFRecord文件存储目录存在。
- 定义辅助函数来创建TFRecord所需的字节特征和例子。
- 定义函数来将图像路径和注释批量写入TFRecord文件,并计算写入的例子总数。
- 调用写入函数,为训练集和验证集生成TFRecord文件,并打印出写入的例子数量。
2.2.3. 创建tf.data.Dataset
在TensorFlow中,tf.data.Dataset是一个强大的工具,用于构建复杂的输入管道,用于机器学习模型的数据预处理和批量处理。以下是如何为训练和评估任务创建tf.data.Dataset的简要步骤:
准备数据:首先,你需要准备好你的数据。这通常意味着你已经有了图像和对应的标签(在这个例子中是图像和标题对),并且它们已经被正确地处理和编码。
创建Dataset:使用
tf.data.Dataset.from_tensor_slices(如果你的数据已经是Tensor格式)或者tf.data.TFRecordDataset(如果你的数据保存在TFRecord文件中)来创建一个初始的Dataset。应用转换:使用
Dataset的map、batch、shuffle、repeat等方法来应用数据增强、预处理、批量处理和其他必要的转换。分割数据:如果你有一个包含所有数据的
Dataset,你可能想要分割它以创建训练和评估(验证/测试)集。这可以通过take和skip方法或使用Python的索引来实现。缓存和预取:为了提高性能,你可以使用
Dataset的cache和prefetch方法来缓存数据和预取下一个批次的数据。用于训练:将训练
Dataset传递给你的模型训练循环。用于评估:将验证或测试
Dataset用于在训练过程中或训练结束后评估模型的性能。
import tensorflow as tf
# 定义TFRecord中的数据特征描述
feature_description = {
"caption": tf.io.FixedLenFeature([], tf.string), # 单行文本特征
"raw_image": tf.io.FixedLenFeature([], tf.string), # 原始图像数据特征
}
# 定义一个函数,用于解析单个TFRecord例子
def read_example(example):
# 解析TFRecord中的例子
features = tf.io.parse_single_example(example, feature_description)
# 从解析结果中提取原始图像数据
raw_image = features.pop("raw_image")
# 将原始图像数据解码并调整大小
features["image"] = tf.image.resize(
tf.image.decode_jpeg(raw_image, channels=3), # 解码JPEG图像,指定3个通道
size=(299, 299) # 调整图像大小到299x299
)
return features
# 定义一个函数,用于获取数据集
def get_dataset(file_pattern, batch_size):
# 使用TFRecordDataset读取匹配file_pattern的TFRecord文件
return (
tf.data.TFRecordDataset(tf.data.Dataset.list_files(file_pattern)) # 列出所有文件并创建数据集
.map( # 映射函数,用于处理数据集中的每个元素
read_example, # 使用read_example函数处理每个例子
num_parallel_calls=tf.data.AUTOTUNE, # 自动调整并行调用的数量
deterministic=False, # 非确定性模式,允许随机性以提高性能
)
.shuffle(batch_size * 10) # 打乱数据,缓冲区大小为batch_size的10倍
.prefetch(buffer_size=tf.data.AUTOTUNE) # 预取数据,提高性能
.batch(batch_size) # 将数据分批处理,每批batch_size个元素
)
代码的主要功能是:
定义特征描述:
feature_description字典定义了TFRecord文件中每个例子的特征类型和形状。这里有两个特征:caption(单行文本)和raw_image(原始图像数据)。解析TFRecord例子:
read_example函数用于解析TFRecord文件中的单个例子,提取出原始图像数据,并将其解码和调整大小。获取数据集:
get_dataset函数用于创建一个tf.data.Dataset对象,该对象可以迭代处理TFRecord文件中的数据。以下是该函数的关键步骤:- 使用
tf.data.TFRecordDataset和tf.data.Dataset.list_files读取匹配给定模式的TFRecord文件。 - 使用
.map方法和read_example函数处理数据集中的每个例子,进行解码和图像大小调整。 - 使用
.shuffle方法打乱数据,提高模型训练的泛化能力。 - 使用
.prefetch方法预取数据,以减少等待时间,提高数据处理的效率。 - 使用
.batch方法将数据分批处理,每批包含指定数量的元素。
- 使用
2.3 建立双塔模型
2.3.1.定义投影头(Projection Head)
投影头用于将图像和文本的嵌入(embeddings)转换到具有相同维度的同一嵌入空间中。这样做的目的是为了让图像和文本在同一维度上进行比较,从而可以计算它们之间的相似性或差异。在跨模态检索、视觉和语言对齐等任务中,投影头是一个重要的组件。
投影头通常是一个或多个神经网络层(如全连接层或线性层),它们接受不同模态的嵌入作为输入,并输出具有相同维度的向量。这些向量随后可以用于计算不同模态之间的相似性分数,例如通过点积或余弦相似度等度量方法。
import tensorflow as tf
def project_embeddings(
embeddings, # 输入的嵌入向量
num_projection_layers, # 投影层的数量
projection_dims, # 投影层的维度
dropout_rate # Dropout率,用于正则化,防止过拟合
):
# 第一个全连接层,将输入嵌入向量投影到指定维度
projected_embeddings = tf.keras.layers.Dense(units=projection_dims)(embeddings)
# 循环构建多个投影层
for _ in range(num_projection_layers):
# GELU激活函数
x = tf.nn.gelu(projected_embeddings)
# 另一个全连接层,维度与投影维度相同
x = tf.keras.layers.Dense(projection_dims)(x)
# Dropout层,按照给定的dropout_rate丢弃一定比例的神经元输出
x = tf.keras.layers.Dropout(dropout_rate)(x)
# 将原始嵌入向量与当前层的输出相加
x = tf.keras.layers.Add()([projected_embeddings, x])
# 层归一化,使输出的分布更加稳定
projected_embeddings = tf.keras.layers.LayerNormalization()(x)
return projected_embeddings
代码主要功能:
函数定义:
project_embeddings函数接受四个参数:embeddings表示输入的嵌入向量,num_projection_layers表示要构建的投影层的数量,projection_dims表示投影层的输出维度,dropout_rate表示Dropout层的丢弃率。第一层投影:使用
tf.keras.layers.Dense创建一个全连接层,将输入的嵌入向量投影到指定的维度。这个维度由projection_dims参数指定。循环构建投影层:通过一个循环,构建多个投影层。每个投影层都包含以下操作:
- 使用GELU激活函数
tf.nn.gelu对上一层的输出进行非线性变换。 - 通过另一个全连接层进一步处理数据,确保输出的维度与投影维度相同。
- 应用Dropout层,按照
dropout_rate参数指定的比例丢弃神经元的输出,这是一种正则化手段,用于防止模型过拟合。
- 使用GELU激活函数
残差连接:在每个投影层之后,将原始嵌入向量与当前层的输出相加,形成残差连接。这有助于梯度流动,避免深层网络训练中的梯度消失问题。
层归一化:使用
tf.keras.layers.LayerNormalization对残差连接的结果进行归一化,确保输出的分布更加稳定,有助于提高模型的训练效率和稳定性。返回结果:函数返回经过投影和归一化处理后的嵌入向量。
2.3.2.定义视觉编码器
当实现一个视觉编码器时,我们通常会选择一个预训练的深度神经网络模型作为基础架构,如Xception。这样的模型已经在大规模图像数据集(如ImageNet)上进行了训练,因此它们能够提取图像中的复杂特征和模式。为了将视觉编码器应用于特定的任务,如多模态学习或跨模态检索,我们需要对预训练模型进行一些修改和调整。
首先,我们选择一个预训练的模型,如Xception,作为视觉编码器的基础。这个模型通常包括多个卷积层、池化层和全连接层,它们共同协作以提取图像中的层次化特征。然而,对于我们的任务,我们可能不需要模型的所有层,特别是顶部的全连接层,因为它们通常用于分类任务,并且具有固定的输出维度。
接下来,我们去掉预训练模型的顶部全连接层,并冻结其余层的权重。这样做是为了保留模型在训练过程中学习到的特征表示,并防止这些权重在后续的训练过程中被更新。通过冻结这些权重,我们可以确保视觉编码器能够提取到与预训练模型相同的特征,同时减少训练时间和计算资源的需求。
然后,我们需要在模型的某个中间层(如全局平均池化层之后)添加一个投影层。这个投影层通常是一个全连接层,它接受来自前一个层的特征向量作为输入,并将其转换为一个具有固定维度的输出向量。这个输出向量的维度应该与文本嵌入的维度相匹配,以便我们可以在相同的嵌入空间中比较和融合来自不同模态的信息。
在添加投影层时,我们可以根据需要调整神经元的数量和激活函数。更多的神经元和更复杂的激活函数可以增加模型的表达能力,但也可能导致过拟合和计算成本的增加。因此,我们需要根据任务的具体需求和可用的计算资源来做出权衡。
最后,我们将修改后的模型作为一个新的视觉编码器来使用。这个编码器可以接受任意大小的图像作为输入,并通过一系列卷积、池化和全连接操作来提取图像的特征表示。然后,它将通过投影层将这些特征表示转换为一个固定维度的向量,以便与文本嵌入进行比较和融合。
除了Xception之外,还有许多其他预训练的深度神经网络模型可以作为视觉编码器的基础,如ResNet、VGGNet和MobileNet等。这些模型具有不同的架构和特性,因此我们可以根据任务的具体需求选择最适合的模型。
总之,实现一个视觉编码器需要选择一个预训练的深度神经网络模型作为基础,并对其进行适当的修改和调整。通过冻结模型的权重、添加投影层和使用适当的激活函数,我们可以得到一个能够在相同嵌入空间中表示图像和文本的视觉编码器。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 定义视觉编码器创建函数
def create_vision_encoder(
num_projection_layers, # 投影层的数量
projection_dims, # 投影层的维度
dropout_rate, # Dropout率
trainable=False # 是否训练基础编码器层
):
# 加载预训练的Xception模型作为基础编码器
xception = keras.applications.Xception(
include_top=False, # 不包含顶层全连接层
weights="imagenet", # 使用预训练在ImageNet上的权重
pooling="avg" # 使用平均池化
)
# 设置基础编码器的可训练性
for layer in xception.layers:
layer.trainable = trainable
# 接收图像作为输入
inputs = layers.Input(shape=(299, 299, 3), name="image_input")
# 对输入图像进行预处理
xception_input = keras.applications.xception.preprocess_input(inputs)
# 使用xception模型生成图像的嵌入表示
embeddings = xception(xception_input)
# 对生成的嵌入进行投影变换
outputs = project_embeddings(
embeddings, num_projection_layers, projection_dims, dropout_rate
)
# 创建视觉编码器模型
return keras.Model(inputs, outputs, name="vision_encoder")
代码主要功能:
函数定义:
create_vision_encoder函数用于创建一个视觉编码器模型,它接受参数:投影层的数量、投影层的维度、Dropout率和是否训练基础编码器层。加载Xception模型:使用
keras.applications.Xception加载预训练的Xception模型。include_top=False表示不包含顶层的全连接层,weights="imagenet"表示使用在ImageNet数据集上预训练的权重,pooling="avg"表示使用平均池化来减少特征图的空间维度。设置可训练性:通过遍历Xception模型中的所有层,并设置
layer.trainable属性,来决定是否在训练过程中更新这些层的权重。定义输入层:使用
layers.Input定义模型的输入层,指定输入图像的形状和名称。图像预处理:使用
keras.applications.xception.preprocess_input对输入图像进行预处理,以匹配Xception模型的输入要求。生成嵌入表示:将预处理后的图像输入到Xception模型中,生成图像的特征嵌入表示。
投影嵌入:调用之前定义的
project_embeddings函数,对Xception生成的嵌入表示进行进一步的投影变换,以获得更适合下游任务的嵌入向量。创建模型:使用
keras.Model创建视觉编码器模型,将输入和输出封装成模型,并指定模型名称。
当我们实现文本编码器时,我们选择使用TensorFlow Hub提供的BERT模型作为我们的文本编码器。BERT(Bidirectional Encoder Representations from Transformers)是一个基于Transformer架构的预训练模型,它在大量的文本数据上进行了训练,能够捕获文本中的上下文信息,并生成高质量的文本表示。
2.3.3.定义文本编码器
选择BERT模型:
首先,你需要从TensorFlow Hub或其他预训练模型库中选择一个适合你的任务的BERT模型。TensorFlow Hub提供了多种BERT模型变体,包括不同大小和配置的模型,以适应不同的计算资源需求。加载BERT模型:
在选择了BERT模型后,你需要使用TensorFlow Hub的URL来加载该模型。加载过程将下载BERT模型的权重和架构,并准备将其用于文本编码。加载模型时,你可以选择是否让BERT的权重在后续的训练过程中保持可训练,这取决于你的具体需求。准备输入数据:
为了使用BERT模型进行文本编码,你需要将原始文本数据转换为BERT模型所接受的输入格式。这通常包括将文本进行分词(tokenization),生成对应的token IDs,以及创建输入掩码(mask)和段标识符(segment IDs)。分词是将文本拆分为模型能够理解的单词或子词单元的过程,而输入掩码和段标识符则用于指示模型输入中的不同部分。使用BERT模型进行文本编码:
一旦你将文本数据转换为BERT模型所需的输入格式,你就可以将输入数据传递给BERT模型进行编码。BERT模型将接收输入数据,并通过其内部的Transformer层进行处理,生成一个表示输入文本语义的向量。这个向量通常被称为BERT的嵌入(embedding)或表示(representation),它包含了文本中的丰富信息,并可以用于各种自然语言处理任务。匹配视觉编码器输出(如果需要):
如果你的应用场景涉及到多模态任务,比如图像文本匹配或跨模态检索,你可能需要将BERT生成的文本表示与视觉编码器生成的图像表示进行匹配。为了实现这一点,你可以考虑在BERT模型的输出之后添加一个额外的全连接层(即投影层),以将文本表示的维度与图像表示的维度相匹配。这样,你就可以在相同的嵌入空间中比较和融合来自不同模态的信息。
通过使用BERT作为文本编码器,你可以轻松地将文本数据转换为高质量的文本表示,并利用这些表示进行各种自然语言处理任务。BERT的预训练特性和强大的上下文捕获能力使得它在文本编码领域具有广泛的应用前景。
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow import keras
from tensorflow.keras import layers
# 定义文本编码器创建函数
def create_text_encoder(
num_projection_layers, # 投影层的数量
projection_dims, # 投影层的维度
dropout_rate, # Dropout率
trainable=False # 是否训练基础编码器层
):
# 加载BERT预处理模块
preprocess = hub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2", # BERT预处理模型的URL
name="text_preprocessing" # 层的名称
)
# 加载预训练的BERT模型作为基础编码器
bert = hub.KerasLayer(
"https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1", # 小型BERT模型的URL
name="bert" # 层的名称
)
# 设置基础编码器的可训练性
bert.trainable = trainable
# 接收文本作为输入
inputs = layers.Input(shape=(), dtype=tf.string, name="text_input")
# 对文本进行预处理
bert_inputs = preprocess(inputs)
# 使用BERT模型生成预处理文本的嵌入表示
embeddings = bert(bert_inputs)["pooled_output"] # 使用BERT模型的输出中的"pooled_output"
# 对BERT模型生成的嵌入进行投影变换
outputs = project_embeddings(
embeddings, num_projection_layers, projection_dims, dropout_rate
)
# 创建文本编码器模型
return keras.Model(inputs, outputs, name="text_encoder")
函数定义:
create_text_encoder函数用于创建一个文本编码器模型,接受参数:投影层的数量、投影层的维度、Dropout率和是否训练基础编码器层。加载BERT预处理模块:使用
hub.KerasLayer加载BERT的预处理模块,这个模块用于将输入的文本字符串转换为BERT模型能够处理的格式。加载BERT模型:同样使用
hub.KerasLayer加载预训练的BERT模型,这里使用的是一个小型的BERT模型,适用于资源受限的情况。设置可训练性:设置BERT模型的
trainable属性,以决定是否在训练过程中更新BERT模型的权重。定义输入层:使用
layers.Input定义模型的输入层,指定输入为文本字符串。文本预处理:将输入文本通过BERT预处理模块进行处理,以匹配BERT模型的输入要求。
生成嵌入表示:将预处理后的文本输入到BERT模型中,获取BERT模型输出的嵌入表示,这里特别使用
pooled_output,它是对BERT模型最后一层输出的进一步处理,通常用于分类任务。投影嵌入:调用之前定义的
project_embeddings函数,对BERT生成的嵌入表示进行进一步的投影变换。创建模型:使用
keras.Model创建文本编码器模型,将输入和输出封装成模型,并指定模型名称。
2.3.4. 定义双塔模型
要实现一个双编码器(dual encoder)架构,并计算如上所述的损失,我们首先需要两个编码器:一个用于处理文本(例如,标题caption),另一个用于处理图像(images)。然后,我们将计算每个标题与批次中每个图像的点积相似度作为预测值,同时计算目标相似度,并使用交叉熵损失来比较预测值与目标值。
以下是这个过程的大致步骤,不包括具体的代码实现:
- 定义双编码器:
- 文本编码器:可以使用BERT或其他预训练的文本编码器模型。
- 图像编码器:可以使用预训练的卷积神经网络(CNN),如ResNet、VGG等,来提取图像特征。
- 准备数据:
- 文本数据(标题)需要进行适当的预处理,如分词、转换为token IDs等,以便输入到文本编码器。
- 图像数据需要被加载并预处理,通常包括调整大小、归一化等步骤,以便输入到图像编码器。
- 编码:
- 将文本数据输入到文本编码器,获取标题的嵌入向量。
- 将图像数据输入到图像编码器,获取图像的嵌入向量。
计算预测相似度:
- 对于每对标题
caption_i和图像image_j在批次中,计算它们嵌入向量的点积,得到预测相似度。
- 对于每对标题
计算目标相似度:
- 对于每对标题
caption_i和caption_j,计算它们嵌入向量的点积。 - 对于每对图像
image_i和image_j,也计算它们嵌入向量的点积(如果可能的话,可能需要将图像嵌入映射到与文本嵌入相同的空间)。 - 将上述两个点积相似度平均,得到
caption_i和image_j之间的目标相似度。
计算损失:使用交叉熵损失(cross-entropy loss)或其他合适的损失函数(如均方误差损失MSE)来比较预测相似度和目标相似度,从而得到损失值。注意,交叉熵损失通常用于分类问题,但在这个场景下,可能需要一种能处理连续目标值(相似度得分)的损失函数。如果使用MSE,则直接计算预测相似度和目标相似度之间的均方误差。
反向传播和优化:使用计算出的损失值进行反向传播,更新双编码器的权重。
import tensorflow as tf
from tensorflow import keras
class DualEncoder(keras.Model):
def __init__(self, text_encoder, image_encoder, temperature=1.0, **kwargs):
super().__init__(**kwargs)
# 初始化文本和图像编码器
self.text_encoder = text_encoder
self.image_encoder = image_encoder
# 设置温度参数,用于调整相似度计算
self.temperature = temperature
# 初始化损失追踪器
self.loss_tracker = keras.metrics.Mean(name="loss")
@property
def metrics(self):
# 返回模型的度量标准
return [self.loss_tracker]
def call(self, features, training=False):
# 将文本和图像编码器分配到不同的GPU上(如果可用)
with tf.device("/gpu:0"):
# 获取文本的嵌入表示
caption_embeddings = self.text_encoder(features["caption"], training=training)
with tf.device("/gpu:1"):
# 获取图像的嵌入表示
image_embeddings = self.image_encoder(features["image"], training=training)
# 返回文本和图像的嵌入表示
return caption_embeddings, image_embeddings
def compute_loss(self, caption_embeddings, image_embeddings):
# 计算文本和图像嵌入之间的相似度矩阵
logits = tf.matmul(caption_embeddings, image_embeddings, transpose_b=True) / self.temperature
# 计算图像之间的相似度矩阵
images_similarity = tf.matmul(image_embeddings, image_embeddings, transpose_b=True)
# 计算文本之间的相似度矩阵
captions_similarity = tf.matmul(caption_embeddings, caption_embeddings, transpose_b=True)
# 计算目标矩阵,为文本和图像之间的平均相似度
targets = keras.activations.softmax((captions_similarity + images_similarity) / (2 * self.temperature))
# 计算文本的损失
captions_loss = keras.losses.categorical_crossentropy(
y_true=targets, y_pred=logits, from_logits=True
)
# 计算图像的损失
images_loss = keras.losses.categorical_crossentropy(
y_true=tf.transpose(targets), y_pred=tf.transpose(logits), from_logits=True
)
# 返回批次的平均损失
return (captions_loss + images_loss) / 2
def train_step(self, features):
# 使用梯度磁带记录训练步骤
with tf.GradientTape() as tape:
# 前向传播
caption_embeddings, image_embeddings = self(features, training=True)
# 计算损失
loss = self.compute_loss(caption_embeddings, image_embeddings)
# 计算梯度
gradients = tape.gradient(loss, self.trainable_variables)
# 应用梯度更新
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
# 更新损失追踪器
self.loss_tracker.update_state(loss)
# 返回训练结果
return {"loss": self.loss_tracker.result()}
def test_step(self, features):
# 在测试步骤中不记录梯度
caption_embeddings, image_embeddings = self(features, training=False)
# 计算损失
loss = self.compute_loss(caption_embeddings, image_embeddings)
# 更新损失追踪器
self.loss_tracker.update_state(loss)
# 返回测试结果
return {"loss": self.loss_tracker.result()}
代码主要功能的解读:
类定义:
DualEncoder类继承自keras.Model,是一个用于图像和文本相似度学习的双编码器模型。初始化方法:
__init__方法中,接收文本编码器、图像编码器和温度参数,并初始化损失追踪器。metrics属性:返回模型使用的度量标准列表,这里是损失追踪器。
call方法:是模型的前向传播方法,用于获取文本和图像的嵌入表示。
compute_loss方法:计算文本嵌入和图像嵌入之间的相似度,并基于这些相似度计算损失。
train_step方法:定义了模型的训练步骤,包括前向传播、损失计算、反向传播和参数更新。
test_step方法:定义了模型的评估步骤,主要用于计算和返回模型在测试数据上的损失。
2.4.训练双塔模型
在训练双编码器模型时,如果我们选择冻结文本和图像的基编码器(即BERT和图像编码器如ResNet),而仅训练投影头(projection head),则我们需要构建一个架构,其中包含这些固定的编码器和一个可训练的投影层。以下是如何进行这个过程的步骤:
- 加载并冻结基编码器:
- 加载预训练的文本编码器(如BERT)和图像编码器(如ResNet)。
- 将这两个编码器的权重设置为不可训练(
trainable=False),这样它们在训练过程中就不会更新。
- 定义投影头:
- 投影头是一个或多个全连接层(dense layers),用于将文本和图像的嵌入映射到相同的维度空间,以便可以计算相似度。
- 投影头需要是可训练的(
trainable=True),这样模型在训练过程中可以更新这些层的权重。
- 构建双编码器模型:
- 将文本和图像编码器以及投影头组合成一个完整的模型。
- 确保文本和图像的嵌入通过各自的投影头,得到相同维度的输出。
- 准备数据:
- 预处理文本和图像数据,以便它们可以输入到相应的编码器。
- 通常,这包括将文本转换为token IDs,将图像调整为适当的尺寸并进行归一化。
- 计算预测和目标相似度:
- 对于每对文本和图像,通过它们的嵌入(经过投影头后)计算点积相似度作为预测值。
- 计算目标相似度,这可以通过平均文本-文本和图像-图像的点积相似度来实现(具体方法可能取决于你的应用场景和数据集)。
定义损失函数:使用均方误差(MSE)或其他适合连续目标值的损失函数来计算预测相似度和目标相似度之间的差异。
编译模型:
- 使用适当的优化器(如Adam)和损失函数来编译模型。
- 由于我们只训练投影头,因此只需将这些层的权重包含在编译过程中。
- 训练模型:
- 使用你的训练数据集来训练模型。由于基编码器是冻结的,只有投影头的权重会在训练过程中被更新。
- 监控验证集上的性能,以便在必要时调整超参数或执行早停(early stopping)。
- 评估模型:
- 在测试集上评估模型的性能。
- 计算并报告适当的评估指标,如准确率、召回率、F1分数等(具体取决于你的任务)。
注意:在训练过程中,由于基编码器是冻结的,因此你需要确保它们能够生成足够好的嵌入来表示文本和图像的内容。这通常意味着使用在大量数据上预训练的模型,并确保这些模型与你的任务和数据集相关。此外,投影头的架构和大小也可能影响模型的性能,因此可能需要通过实验来确定最佳配置。
以下是您提供的代码段的中文注释版本:
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow.keras import layers
# 设置训练的轮数,实际训练时至少应训练30个epoch
num_epochs = 5
# 设置每个批次的样本数量
batch_size = 256
# 创建视觉编码器,使用1个投影层,投影维度为256,Dropout率为0.1
vision_encoder = create_vision_encoder(
num_projection_layers=1,
projection_dims=256,
dropout_rate=0.1
)
# 创建文本编码器,使用1个投影层,投影维度为256,Dropout率为0.1
text_encoder = create_text_encoder(
num_projection_layers=1,
projection_dims=256,
dropout_rate=0.1
)
# 创建双编码器模型,文本编码器和视觉编码器的温度参数设置为0.05
dual_encoder = DualEncoder(text_encoder, vision_encoder, temperature=0.05)
# 编译双编码器模型
dual_encoder.compile(
# 使用AdamW优化器,学习率为0.001,权重衰减为0.001
optimizer=tfa.optimizers.AdamW(learning_rate=0.001, weight_decay=0.001)
)
代码主要功能:
设置训练参数:
num_epochs变量设置了训练的轮数,batch_size变量设置了每个批次的样本数量。创建视觉编码器:调用
create_vision_encoder函数创建了一个视觉编码器,该编码器使用Xception作为基础模型,并添加了一个投影层,投影到256维空间,并应用了Dropout正则化。创建文本编码器:调用
create_text_encoder函数创建了一个文本编码器,该编码器使用BERT作为基础模型,并添加了一个投影层,同样投影到256维空间,并应用了Dropout正则化。创建双编码器模型:实例化
DualEncoder类,将文本编码器和视觉编码器作为参数传入,并设置温度参数为0.05,这将影响相似度计算的缩放因子。编译模型:使用
compile方法编译双编码器模型,指定了优化器为AdamW,这是一种结合了权重衰减的Adam优化器,学习率设置为0.001,权重衰减设置为0.001。
以下是您提供的代码段的中文注释版本:
import numpy as np
import tensorflow as tf
# 打印可用的GPU数量
print(f"Number of GPUs: {len(tf.config.list_physical_devices('GPU'))}")
# 打印训练集中的样本数量(图像-标题对)
print(f"Number of examples (caption-image pairs): {train_example_count}")
# 打印每个批次的样本数量
print(f"Batch size: {batch_size}")
# 计算每个epoch的步数,向上取整以确保所有样本都被处理
print(f"Steps per epoch: {int(np.ceil(train_example_count / batch_size))}")
# 获取训练数据集,使用指定的文件模式和批次大小
train_dataset = get_dataset(os.path.join(tfrecords_dir, "train-*.tfrecord"), batch_size)
# 获取验证数据集,使用指定的文件模式和批次大小
valid_dataset = get_dataset(os.path.join(tfrecords_dir, "valid-*.tfrecord"), batch_size)
# 创建学习率调度器回调,用于在验证损失不再下降时降低学习率
reduce_lr = keras.callbacks.ReduceLROnPlateau(
monitor="val_loss", # 监控的指标
factor=0.2, # 降低因子
patience=3 # 等待的epoch数
)
# 创建早停法回调,如果在验证集上连续多个epoch没有改进则停止训练
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor="val_loss", # 监控的指标
patience=5, # 等待的epoch数
restore_best_weights=True # 恢复到最佳状态的权重
)
# 训练双编码器模型
history = dual_encoder.fit(
train_dataset, # 训练数据集
epochs=num_epochs, # 训练的epoch数
validation_data=valid_dataset, # 验证数据集
callbacks=[reduce_lr, early_stopping], # 训练过程中使用的回调
)
# 打印训练完成信息,并保存视觉和文本编码器模型
print("Training completed. Saving vision and text encoders...")
# 保存视觉编码器模型
vision_encoder.save("vision_encoder")
# 保存文本编码器模型
text_encoder.save("text_encoder")
print("Models are saved.")
代码主要功能:
打印GPU数量:输出系统中可用的GPU数量,这对于深度学习训练来说很重要,因为它们可以加速训练过程。
打印训练集样本数量:输出训练集中的样本(图像-标题对)总数。
打印批次大小和每epoch步数:输出每个批次的样本数量,并计算每个epoch需要处理的步数。
获取数据集:使用
get_dataset函数获取训练和验证数据集,传入TFRecord文件的模式和批次大小。创建学习率调度器回调:使用
keras.callbacks.ReduceLROnPlateau创建一个回调,当验证损失在指定的epoch数内没有改善时,降低学习率。创建早停法回调:使用
tf.keras.callbacks.EarlyStopping创建一个回调,如果在指定的epoch数内验证损失没有改善,则停止训练,并恢复到最佳状态的权重。训练双编码器模型:调用
dual_encoder.fit方法训练双编码器模型,传入训练数据集、验证数据集、训练的epoch数和回调列表。保存模型:训练完成后,保存视觉编码器和文本编码器模型到文件。
在训练双编码器模型时,跟踪并绘制训练损失(training loss)是一个非常重要的步骤,因为它可以帮助你了解模型的学习进度以及是否存在过拟合或欠拟合的问题。以下是如何在训练过程中绘制训练损失的步骤:
初始化一个列表来存储损失值:
在训练循环开始之前,初始化一个空的列表(或其他数据结构)来存储每个epoch的训练损失值。在每个epoch结束时记录损失:
在每次完成一个epoch的训练后,将计算得到的训练损失值添加到之前初始化的列表中。使用matplotlib等库绘制损失曲线:
训练完成后,你可以使用Python的matplotlib库或其他可视化库来绘制训练损失随epoch变化的曲线图。这将帮助你直观地看到模型的学习过程。
在每个epoch后记录损失并绘制损失曲线:
import matplotlib.pyplot as plt
# 假设 losses 是一个列表,用于存储每个epoch的损失值
losses = []
# ...(训练循环的代码)...
# 在每个epoch结束后,将损失值添加到列表中
for epoch in range(num_epochs):
# ...(进行训练的代码,包括前向传播、反向传播和优化器更新)...
# 假设 train_loss 是当前epoch的训练损失
losses.append(train_loss.numpy()) # 假设你使用的是TensorFlow,并且train_loss是一个Tensor
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(range(len(losses)), losses, marker='o')
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()
2.5.使用自然语言查询搜索图像
要通过自然语言查询检索对应的图像,我们可以按照以下步骤操作:
图像嵌入生成:我们加载图像,并将它们送入视觉编码器以生成嵌入。在大型系统中,这个步骤通常通过并行数据处理框架来加速。生成图像嵌入可能需要一些时间。
查询嵌入生成:我们输入自然语言查询到文本编码器,以生成查询的嵌入。
相似度计算:为了找到与查询最匹配的图像,我们计算查询嵌入与存储在索引中的图像嵌入之间的相似度。
显示匹配图像:根据相似度排序,我们查找并显示与查询最匹配的图像。
2.5.1. 图像嵌入生成
import tensorflow as tf
# 打印加载视觉和文本编码器的提示信息
print("Loading vision and text encoders...")
# 加载之前保存的视觉编码器模型
vision_encoder = keras.models.load_model("vision_encoder")
# 加载之前保存的文本编码器模型
text_encoder = keras.models.load_model("text_encoder")
# 打印模型加载完成的信息
print("Models are loaded.")
# 定义一个函数,用于读取并处理图像
def read_image(image_path):
# 读取图像文件并解码JPEG格式的图像,指定3个通道(RGB)
image_array = tf.image.decode_jpeg(tf.io.read_file(image_path), channels=3)
# 调整图像大小到299x299像素,以匹配编码器的输入要求
return tf.image.resize(image_array, (299, 299))
# 打印生成图像嵌入的提示信息,并输出要处理的图像数量
print(f"Generating embeddings for {len(image_paths)} images...")
# 使用视觉编码器预测图像嵌入
# 从图像路径列表创建数据集,并应用read_image函数处理每个图像
# 然后将处理后的图像批量输入编码器进行预测
image_embeddings = vision_encoder.predict(
tf.data.Dataset.from_tensor_slices(image_paths).map(read_image).batch(batch_size),
verbose=1, # 显示预测过程中的进度信息
)
# 打印生成的图像嵌入的形状
print(f"Image embeddings shape: {image_embeddings.shape}.")
代码主要功能:
加载模型:使用
keras.models.load_model函数加载之前保存的视觉编码器和文本编码器模型。读取图像函数:定义了一个名为
read_image的函数,它读取图像文件路径,解码JPEG图像,并调整图像大小以符合模型输入的要求。生成图像嵌入:使用视觉编码器对一批图像进行预测,以生成它们的嵌入表示。图像路径存储在
image_paths列表中,使用tf.data.Dataset处理和批量化这些图像,然后通过vision_encoder.predict方法获取嵌入。打印信息:打印出正在加载模型和模型已加载的提示信息,以及正在生成图像嵌入和生成的图像嵌入形状的信息。
2.5.2.检索相关图像
在图像检索任务中,我们的目标是基于用户提供的自然语言查询来找到与之最相关的图像。在这个例子中,我们将展示一个基本的检索流程,它涉及到计算查询嵌入与预先生成的图像嵌入之间的相似度。
首先,我们使用训练好的视觉编码器(vision encoder)对图像库中的每一张图像进行编码,生成对应的图像嵌入(embeddings)。这些图像嵌入捕获了图像的视觉特征,使我们能够基于这些特征进行相似度比较。
接下来,当用户输入一个自然语言查询时,我们使用文本编码器(text encoder)对该查询进行编码,生成查询嵌入。这个查询嵌入代表了查询的语义内容。
然后,我们计算查询嵌入与图像库中所有图像嵌入的点积相似度。点积相似度是一个简单但有效的相似度度量方法,它能够捕获两个向量之间的角度和大小关系。
最后,我们根据相似度得分对图像进行排序,并返回前k个最匹配的图像作为检索结果。这些图像与查询在语义上最为接近,因此最有可能满足用户的需求。
然而,在实际应用中,当图像库变得非常庞大时,直接计算查询嵌入与每个图像嵌入的相似度可能会变得非常耗时。为了提高检索效率,我们可以采用近似相似度匹配的方法。这些方法通过使用特定的数据结构(如哈希表、树形结构等)和算法(如局部敏感哈希、乘积量化等)来减少需要计算相似度的图像数量,从而在保持检索精度的同时提高检索速度。
一些流行的近似相似度匹配框架包括ScaNN(Scalable Nearest Neighbor search library)、Annoy(Approximate Nearest Neighbors Oh Yeah)和Faiss(Facebook AI Similarity Search)。这些框架提供了丰富的功能和优化选项,可以帮助我们在大规模图像库中实现高效且准确的图像检索。通过使用这些框架,我们可以轻松地将检索系统扩展到数百万甚至数十亿张图像,满足各种实时和离线应用场景的需求。
import tensorflow as tf
# 定义一个函数,用于根据文本查询在图像集合中查找匹配项
def find_matches(image_embeddings, queries, k=9, normalize=True):
# 将文本查询转换为张量并获取其嵌入表示
query_embedding = text_encoder(tf.convert_to_tensor(queries))
# 如果指定了归一化,则对图像嵌入和查询嵌入进行L2归一化
if normalize:
image_embeddings = tf.math.l2_normalize(image_embeddings, axis=1)
query_embedding = tf.math.l2_normalize(query_embedding, axis=1)
# 计算查询嵌入与图像嵌入之间的点积相似度
dot_similarity = tf.matmul(query_embedding, image_embeddings, transpose_b=True)
# 获取相似度最高的k个图像的索引
results = tf.math.top_k(dot_similarity, k).indices.numpy()
# 根据索引获取匹配的图像路径,并返回结果
return [[image_paths[idx] for idx in indices] for indices in results]
# 注意:这里的image_paths应该是全局变量,包含了所有图像的路径列表。
代码主要功能:
函数定义:
find_matches函数接受图像嵌入image_embeddings、文本查询queries、返回匹配项数量k和是否归一化选项normalize。获取查询嵌入:使用文本编码器
text_encoder将文本查询转换为嵌入向量。归一化处理:如果
normalize为True,则对查询嵌入和所有图像嵌入进行L2归一化,这有助于计算点积相似度。计算相似度:使用矩阵乘法计算查询嵌入与图像嵌入之间的点积,得到相似度矩阵。
检索最相似的项:使用
tf.math.top_k函数找到相似度最高的k个图像的索引。返回匹配结果:根据检索到的索引从
image_paths列表中获取对应的图像路径,并返回这些路径的列表。
们可以设置一个查询变量 query 来表示我们想要搜索的图像类型。在设置了 query 变量之后,你可以按照之前描述的步骤来执行图像检索。这包括将 query 输入到文本编码器中以生成查询嵌入,然后与预先生成的图像嵌入进行比较,最后返回最匹配的图像。
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 定义文本查询
query = "a family standing next to the ocean on a sandy beach with a surf board"
# 使用find_matches函数获取匹配的图像路径列表
matches = find_matches(image_embeddings, [query], normalize=True)[0]
# 设置图像展示的画布大小
plt.figure(figsize=(20, 20))
# 根据匹配的图像数量,这里假设最多展示9个,使用3x3的子图布局
for i in range(9):
# 读取每个匹配图像的路径,并展示在相应的子图上
ax = plt.subplot(3, 3, i + 1) # 创建子图
plt.imshow(mpimg.imread(matches[i])) # 读取图像文件并展示
plt.axis("off") # 不显示坐标轴
# 显示整个图像匹配结果
plt.show()
代码主要功能:
定义查询:设置了一个描述性文本查询,该查询将用于在图像集合中寻找匹配的图像。
调用查找匹配函数:使用
find_matches函数并传入图像嵌入、查询列表以及归一化选项,获取匹配的图像路径列表。这里通过索引[0]获取第一个查询的匹配结果。展示图像:使用Matplotlib创建一个画布,并在子图上展示匹配的图像。这里假设最多展示9个匹配结果,因此使用3x3的布局。
读取和展示图像:对于每个匹配的图像路径,使用
mpimg.imread函数读取图像文件,并使用plt.imshow展示在子图上。plt.axis("off")用于隐藏坐标轴。显示结果:最后调用
plt.show()展示整个匹配结果的图像。
2.5.3.评估检索质量
为了全面评估双编码器模型的性能,我们采用一种基于标题的检索策略。具体而言,我们将图像的标题作为查询输入,然后使用这些查询来检索图像库中的图像,进而评估检索质量。这种评估方法的关键在于确保用于测试的数据(包括图像和标题)与训练模型时使用的数据完全分离,以确保评估的公正性和准确性。
在评估过程中,我们利用前k个准确度(top-k accuracy)这一指标来衡量检索结果的质量。具体来说,对于每一个标题查询,我们计算其对应的图像在检索结果中排在前k个位置的比例。如果与给定标题相关的图像出现在前k个检索结果中,我们就认为这次检索是成功的,即为一个“正确预测”(true prediction)。
为了获得更全面的评估结果,我们可以采用多种不同的k值(例如k=1, 5, 10等),并计算在不同k值下的准确度。这有助于我们了解模型在不同检索需求下的表现,从而更全面地评估其性能。
此外,我们还可以考虑使用其他评价指标来进一步评估模型的性能,例如平均精确度均值(Mean Average Precision, MAP)或召回率-精确度曲线(Recall-Precision Curve)。这些指标可以提供关于模型在不同召回率水平下的精确度表现的更详细的信息,从而更全面地评估模型的检索能力。
import numpy as np
import tqdm
# 定义一个函数,用于计算top-k准确率
def compute_top_k_accuracy(image_paths, k=100):
hits = 0 # 初始化击中计数器
num_batches = int(np.ceil(len(image_paths) / batch_size)) # 计算需要的批次数量
for idx in tqdm(range(num_batches)): # 遍历每个批次
start_idx = idx * batch_size # 计算当前批次的起始索引
end_idx = start_idx + batch_size # 计算当前批次的结束索引
current_image_paths = image_paths[start_idx:end_idx] # 获取当前批次的图像路径
# 为当前批次的每个图像获取第一个注释作为查询
queries = [image_path_to_caption[image_path][0] for image_path in current_image_paths]
# 调用find_matches函数获取每个查询的匹配结果
result = find_matches(image_embeddings, queries, k)
# 计算当前批次的击中数
hits += sum(
[
# 检查原始图像路径是否在返回的匹配列表中
image_path in matches
for (image_path, matches) in list(zip(current_image_paths, result))
]
)
# 计算总的top-k准确率
return hits / len(image_paths)
# 打印评分训练数据的提示信息
print("Scoring training data...")
# 计算训练数据的top-k准确率
train_accuracy = compute_top_k_accuracy(train_image_paths)
# 打印训练数据的准确率
print(f"Train accuracy: {round(train_accuracy * 100, 3)}%")
# 打印评分评估数据的提示信息
print("Scoring evaluation data...")
# 计算评估数据的top-k准确率,使用训练集之外的图像路径
eval_accuracy = compute_top_k_accuracy(image_paths[train_size:])
# 打印评估数据的准确率
print(f"Eval accuracy: {round(eval_accuracy * 100, 3)}%")
代码主要功能:
计算top-k准确率函数:
compute_top_k_accuracy函数通过将每个图像的注释作为查询,使用find_matches函数查找k个最相似的图像,并检查原始图像是否在这k个结果中。遍历整个图像路径列表,计算总的击中数。批次处理:由于图像路径可能很多,代码使用批次处理来避免内存不足的问题。
计算击中数:对于每个查询,如果原始图像路径出现在返回的匹配列表中,则认为是一次击中,并将击中数累计。
计算准确率:将击中数除以总的图像路径数量,得到top-k准确率。
评分训练数据:使用训练集的图像路径计算top-k准确率,并打印结果。
评分评估数据:使用训练集之外的图像路径(即评估集)计算top-k准确率,并打印结果。
3.总结和展望
3.1. 总结
本文详细介绍了自然语言搜索图像技术,这是一种结合了自然语言处理(NLP)和图像识别技术的先进搜索方法。通过使用双编码器模型,即Dual Encoder,我们能够实现用户通过自然语言描述来检索相关图像的功能。这种模型通过训练两个编码器——一个用于文本,另一个用于图像——将它们映射到同一嵌入空间,从而实现跨模态的相似性度量。
3.2.关键点概述
- 技术背景与需求:随着图像数据量的激增和用户对搜索直观性、便捷性的需求提升,自然语言搜索图像技术应运而生,它通过深度学习模型理解用户查询意图,提供更准确的搜索结果。
- 双编码器模型:由两个编码器组成,分别对文本和图像进行编码,并通过相似度计算模块找出二者的匹配程度。这种模型结构适用于多种跨模态任务,如跨模态检索、图像描述生成和视觉问答。
- 实现细节:文章提供了使用TensorFlow和相关库实现双编码器模型的步骤,包括数据预处理、模型构建、训练和评估等。此外,还探讨了如何使用预训练模型,如BERT和Xception,以及如何通过训练投影头来适应特定任务。
3.3.未来展望
自然语言搜索图像技术具有巨大的应用潜力和商业价值,它不仅能提升用户体验,还能为企业带来更大的商业潜力。随着技术的不断发展,特别是在语义理解、图像标记准确性和多模态融合方面的进步,预计将进一步提升搜索的准确性和效率。此外,通过结合更先进的NLP技术和图像识别算法,未来的模型将能够处理更复杂的查询,更好地满足用户的搜索需求,并在更广泛的领域中发挥作用。
参考文献
[1] Keras官方示例. (n.d.). NL Image Search (自然语言图像搜索). 访问日期: [2024-6-12]. 从: https://keras.io/examples/vision/nl_image_search/