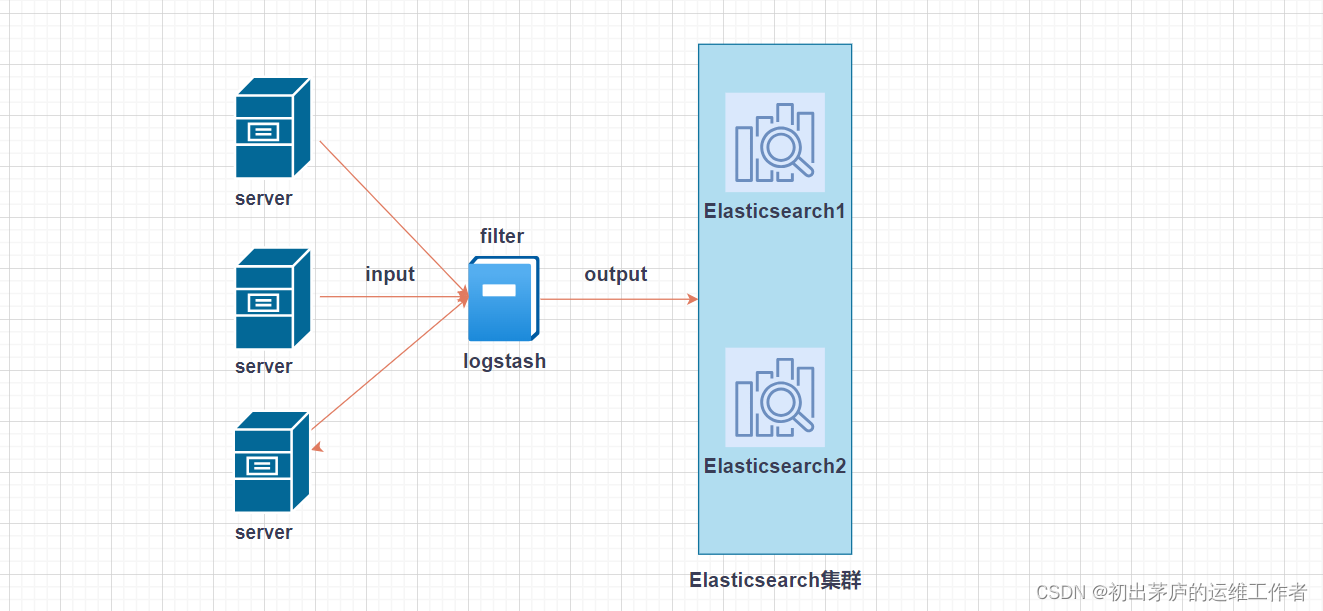
Sklearn基础教程:机器学习界的瑞士军刀
引言
在机器学习的世界里,sklearn(Scikit-learn)就像是一把瑞士军刀,小巧、多功能,而且非常实用。无论你是数据科学家还是编程新手,sklearn都能成为你解决问题的得力助手。今天,就让我们一起走进sklearn的奇妙世界,探索它的起源、发展过程、原理以及应用案例。

起源:sklearn的诞生
sklearn的诞生可以追溯到2007年,当时,一群热爱机器学习的人们聚在一起,决定创建一个易于使用、功能强大的机器学习库。他们希望这个库能够让人们更轻松地实现机器学习算法,而不需要深入了解底层的数学原理。
一个梦想的开始
想象一下,在一个充满代码和咖啡香的房间里,几位程序员围坐在一起,他们有的在白板上画着算法的流程图,有的在键盘上敲击着代码。他们的梦想是让机器学习变得更加平易近人。
发展过程:从小众到主流
随着时间的推移,sklearn逐渐从一个小众项目成长为机器学习领域的一个重要工具。
开源的力量
sklearn的成功很大程度上得益于开源社区的贡献。来自世界各地的开发者们不断地为这个项目贡献代码、修复bug、添加新功能。
持续的更新
sklearn的开发者们始终保持着对最新机器学习研究的关注,他们会定期更新库,以包含最新的算法和技术。
原理:sklearn的核心思想
sklearn的设计哲学是简洁、一致和可扩展。这些原则体现在它的每一个角落。
简洁性
sklearn的API设计简洁直观,即使是初学者也能快速上手。例如,大多数算法都遵循同样的数据输入输出模式,这大大减少了学习成本。
一致性
无论是分类、回归还是聚类,sklearn都提供了统一的接口。这意味着一旦你学会了如何使用一个算法,你就可以轻松地迁移到另一个算法。
可扩展性
sklearn的模块化设计使得开发者可以很容易地添加自己的算法或改进现有算法。
Sklearn的常见工具及其简易用法
Sklearn(Scikit-learn)是一个功能强大的机器学习库,它提供了许多工具来帮助我们进行数据挖掘和分析。以下是一些常见的sklearn工具和它们的简易用法。
1. 数据预处理
StandardScaler
- 作用:用于标准化数据,使特征的均值为0,标准差为1。
- 简易用法:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() data_scaled = scaler.fit_transform(data)
MinMaxScaler
- 作用:将特征缩放到给定的最小值和最大值(通常是0到1)。
- 简易用法:
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() data_scaled = scaler.fit_transform(data)
2. 模型训练
线性回归(LinearRegression)
- 作用:用于预测连续值输出。
- 简易用法:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
逻辑回归(LogisticRegression)
- 作用:用于分类问题,尤其是二分类问题。
- 简易用法:
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
3. 模型评估
准确度(accuracy_score)
- 作用:计算分类准确度。
- 简易用法:
from sklearn.metrics import accuracy_score accuracy = accuracy_score(y_true, y_pred)
混淆矩阵(confusion_matrix)
- 作用:显示真实类别与预测类别之间的关系。
- 简易用法:
from sklearn.metrics import confusion_matrix conf_matrix = confusion_matrix(y_true, y_pred)
4. 特征选择
递归特征消除(RFE)
- 作用:递归地消除最不重要的特征。
- 简易用法:
from sklearn.feature_selection import RFE model = LogisticRegression() rfe = RFE(model, n_features_to_select=10) fit = rfe.fit(X_train, y_train)
5. 模型持久化
joblib
- 作用:用于模型和数据的持久化。
- 简易用法:
import joblib # 保存模型 joblib.dump(model, 'model.pkl') # 加载模型 loaded_model = joblib.load('model.pkl')
6. 聚类分析
KMeans
- 作用:实现K-Means聚类算法。
- 简易用法:
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3) kmeans.fit(data) predictions = kmeans.predict(data)
7. 降维
主成分分析(PCA)
- 作用:通过线性变换将数据转换到新的坐标系统中,使得数据的任何投影的方差最大化。
- 简易用法:
from sklearn.decomposition import PCA pca = PCA(n_components=2) pca.fit(data) pca_data = pca.transform(data)
这些工具只是sklearn库中的一小部分,但它们都遵循相似的API设计模式,这使得学习和使用sklearn变得非常直观和容易。通过这些工具,你可以进行数据预处理、模型训练、评估、特征选择、持久化、聚类分析和降维等任务。
应用案例:sklearn在行动
sklearn的应用案例遍布各行各业,从金融风控到医疗诊断,从推荐系统到自然语言处理。
金融风控
在金融领域,sklearn被用来构建信用评分模型,帮助银行评估客户的信用风险。
医疗诊断
在医疗行业,sklearn的分类算法被用来分析医学影像,辅助医生进行疾病诊断。
推荐系统
在电商网站,sklearn的协同过滤算法能够根据用户的购买历史推荐商品。
自然语言处理
在自然语言处理领域,sklearn的文本向量化技术被用来处理和分析大量的文本数据。
小故事: sklearn的奇幻救援:数据星球的冒险
第一幕:数据星球的危机
在一个由数字和算法构成的神秘世界——数据星球上,居民们过着和谐的生活。他们依靠准确的数据来预测天气、规划收成,甚至决定节日的庆祝方式。然而,有一天,数据星球的宁静被一群名为“异常值怪兽”的生物打破了。
这些异常值怪兽非常狡猾,它们擅长伪装,混入正常的数据中,扭曲了数据的真相。它们的存在让预测结果变得荒谬可笑,比如预测明天的温度会是零下100度,或者预测下个月的降雨量为零。居民们的生活受到了严重的影响。
第二幕:sklearn勇士的登场
在这个危机时刻,一位名叫sklearn的勇士挺身而出。他装备了两件神秘的武器:“分类剑”和“回归弓”。这两件武器拥有强大的力量,可以帮助他识别和抵御异常值怪兽的侵袭。
分类剑:对抗异常的利刃
“分类剑”是一件锋利无比的武器,它的特殊能力在于能够将数据分为不同的类别。这把剑的秘诀在于多种分类算法,比如决策树、支持向量机(SVM)和随机森林等。通过这些算法,sklearn勇士能够识别出哪些数据点是异常的,并将它们从正常的数据中分离出来。
回归弓:预测的精准射击
而“回归弓”则是一件精准的远程武器,它能够射出预测的箭矢,击中目标值。这把弓的箭矢由线性回归、岭回归、LASSO等回归算法制成,它们能够根据已有的数据预测未知的数值,即使是在异常值怪兽的干扰下,也能保持预测的准确性。
第三幕:异常值的识别与净化
sklearn勇士首先使用了“分类剑”,通过
fit和predict两个咒语,将异常值怪兽从数据中识别出来。然后,他使用了StandardScaler魔法,这是一种能够调整数据尺度的神奇法术,它能够将所有的数据点缩小到同一尺寸,让异常值怪兽无处遁形。第四幕:预测的恢复与和谐
在异常值被识别和净化后,sklearn勇士再次拉起了“回归弓”,这次他能够准确地预测出未来的数据。数据星球的居民们重新获得了可靠的预测结果,他们的生活恢复了正常,甚至比以前更加繁荣。
结尾:数据星球的和平
sklearn勇士的英勇行为赢得了所有居民的尊敬和爱戴。他不仅恢复了数据星球的和平,还教会了居民们如何使用分类和回归的武器来保护自己。从此,数据星球上的每个人都能够识别和抵御异常值怪兽的侵袭,他们的生活变得更加安全和美好。