文章汇总
LoRA: W = W ( 0 ) + Δ = W ( 0 ) + B A W=W^{(0)}+\Delta =W^{(0)}+BA W=W(0)+Δ=W(0)+BA
AdaLoRA:$W=W^{(0)}+\Delta =W^{(0)}+P\Lambda Q$
AdaLoRA的做法是让模型学习SVD分解的近似。在损失函数中增加了惩罚项(4),防止矩阵 P P P和 Q Q Q偏离正交性太远,以实现稳定训练。
R ( P , Q ) = ∥ P T P − I ∥ F 2 + ∥ Q T Q − I ∥ F 2 ( 4 ) R(P,Q)=\|P^TP-I\|^2_F+\|Q^TQ-I\|^2_F\ (4) R(P,Q)=∥PTP−I∥F2+∥QTQ−I∥F2 (4)
摘要
在下游任务上对大型预训练语言模型进行微调已经成为自然语言处理的一个重要范例。然而,通常的做法是对预训练模型中的所有参数进行微调,当存在大量下游任务时,这变得令人望而却步。因此,提出了许多微调方法,以参数有效的方式学习预训练权值的增量更新,例如低秩增量。这些方法通常在所有预训练的权重矩阵上均匀地分配增量更新预算,而忽略了不同权重参数的不同重要性。因此,调优性能不是最优的。为了弥补这一差距,我们提出了AdaLoRA算法,该算法根据权重矩阵的重要性评分自适应地在权重矩阵之间分配参数预算。特别是,AdaLoRA以奇异值分解的形式将增量更新参数化。这种新颖的方法使我们能够有效地修剪不重要更新的奇异值,这本质上是为了减少它们的参数预算,但避免了密集的精确SVD计算。我们在自然语言处理、问答和自然语言生成方面对几个预训练模型进行了大量实验,以验证AdaLoRA的有效性。结果表明,AdaLoRA在基线上表现出显着的改善,特别是在低预算设置下。我们的代码可在https://github.com/QingruZhang/AdaLoRA公开获取。
1 介绍
预训练语言模型(PLMs)在各种自然语言处理任务中表现出优越的性能(Devlin等人,2019;Liu et al ., 2019;He et al ., 2021b;Radford等人,2019;Brown et al, 2020)。使预训练模型适应下游任务的最常见方法是微调所有参数(full fine-tuning, Qiu et al (2020);拉斐尔等人(2020))。然而,预训练模型通常会占用大量内存。例如,BERT模型(Devlin et al, 2019)由多达3亿个参数组成;T5 (rafael et al, 2020)包含多达110亿个参数,GPT-3 (Brown et al, 2020)包含多达1750亿个参数。当在这些预训练模型上构建NLP系统时,我们通常会处理同时到达的多个任务(Radford et al, 2019)。给定大量的下游任务,完整的微调要求每个任务维护大型模型的独立副本。由此产生的内存消耗非常昂贵。
为了解决这个问题,研究人员提出了两个主要的研究方向,以减少微调参数,同时保持甚至提高PLM的性能。具体来说,**一条研究路线侧重于在PLM中添加小型神经模块,并针对每个任务仅对这些模块进行微调——基本模型保持冻结并在任务之间共享。**这样,只需要引入和更新少量特定于任务的参数,大大增强了大型模型的实用性。例如,适配器调谐(Houlsby等人,2019;Rebuffi et al ., 2017;Pfeiffer et al, 2020;他等人,2022)在基本模型的层之间插入称为适配器的小神经模块。前缀调优(Li & Liang, 2021)和提示调优(Lester et al, 2021)将额外的可训练前缀令牌附加到基础模型的输入层或隐藏层。这些方法已经被证明可以达到与完全微调相当的性能,同时只更新不到1%的原始模型参数,显著地释放了内存消耗。
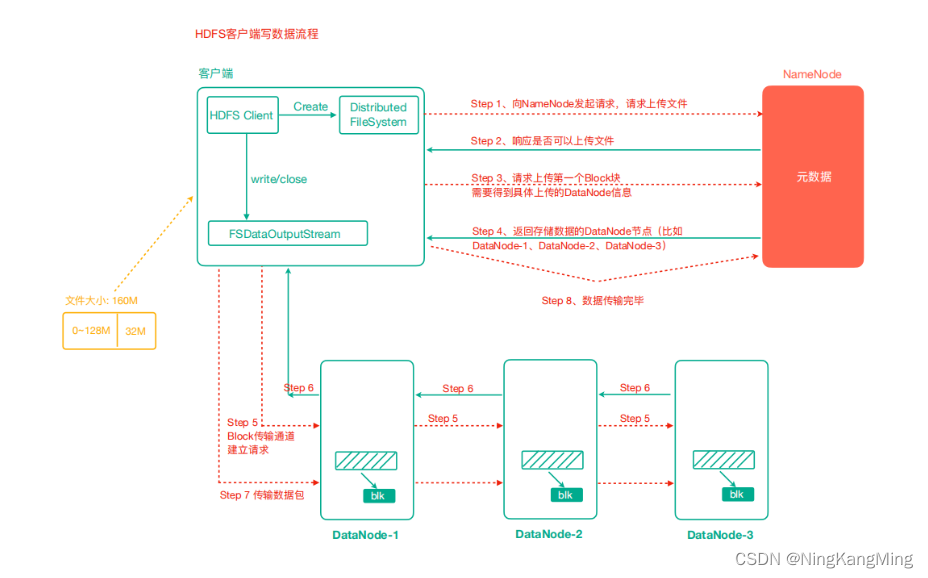
另一项研究建议在不修改模型架构的情况下,以参数有效的方式对预训练权重的增量更新进行建模(Zaken等人,2021;郭等,2020;Hu et al ., 2022)。例如,给定一个预训练的权重矩阵 W ( 0 ) W^{(0)} W(0), diff剪枝(Guo et al, 2020)将其增量更新 △ \triangle △建模为一个稀疏矩阵。Diff修剪将 △ \triangle △初始化为与 W ( 0 ) W^{(0)} W(0)相同的维度,然后根据条目的大小逐个修剪 △ \triangle △。因此,diff剪枝可以自适应地保留重要的更新并剪枝不重要的更新,从而大大提高参数效率。尽管如此,diff修剪有几个限制。首先,它依赖于底层实现来加速非结构化稀疏矩阵的计算,这是现有深度学习框架不支持的。因此,在训练过程中,我们需要将 △ \triangle △存储为一个密集矩阵。其次,它需要用 △ \triangle △的梯度更新每个条目,然后对它们进行修剪。这导致了与完全微调相似的计算成本(Guo et al, 2020)。
为了克服这些缺点,Hu等人(2022)提出了一种名为LoRA的方法,通过两个小得多的矩阵的乘积将 △ \triangle △参数化为低秩矩阵:
W = W ( 0 ) + △ = W ( 0 ) + B A W=W^{(0)}+\triangle =W^{(0)}+BA W=W(0)+△=W(0)+BA
式中 W ( 0 ) , △ ∈ R d 1 × d 2 , B ∈ R d 1 × r , A ∈ R r × d 2 , r ≪ m i n ( d 1 , d 2 ) W^{(0)},\triangle\in \mathbb{R}^{d_1\times d_2},B\in \mathbb{R}^{d_1\times r},A\in \mathbb{R}^{r\times d_2},r \ll min(d_1,d_2) W(0),△∈Rd1×d2,B∈Rd1×r,A∈Rr×d2,r≪min(d1,d2)。在微调期间,只更新 A A A和 B B B。选择rank r r r远小于 W W W的维数(例如,当 d 1 = d 2 = 1024 d_1 = d_2 = 1024 d1=d2=1024时, r = 8 r = 8 r=8)。与完全微调相比,使用不到0.5%的额外可训练参数,训练开销可以减少多达70%。然而,LoRA实现了与完全微调相当甚至更好的性能(Hu et al, 2022)。同时,在差分剪枝中,两个小矩阵的乘积比非结构化稀疏矩阵更易于实现和部署。
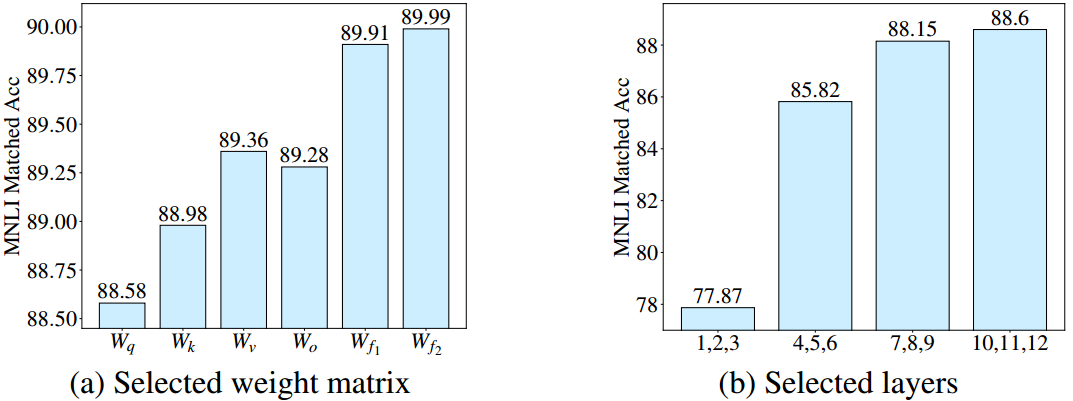
图1:给定总可训练参数为0.28M,我们仅对DeBERTaV3-base的选定权重矩阵(左)或选定层(右)应用LoRA,并比较MNLI-m上的微调性能。图1a:我们只对每一层transformer的一个选定类型的权重矩阵进行微调,包括自关注中的查询/键/值投影 ( W q , W k , W v ) (W_q,W_k,W_v) (Wq,Wk,Wv),输出投影 ( W o ) (W_o) (Wo),两层ffn中的两个权重矩阵 ( W f 1 , W f 2 ) (W_{f_1}, W_{f_2}) (Wf1,Wf2)。在图1b中,我们将LoRA应用于所选层的每个权重矩阵。
LoRA仍然有其局限性,因为它预先规定了每个增量矩阵 △ \triangle △的秩 r r r相同。这忽略了这样一个事实,即在微调预训练模型时,权重矩阵的重要性在模块和层之间存在显著差异。为了说明这一点,我们在图1中给出了一个具体的示例。我们比较了使用相同数量的可训练参数微调特定模块或层时LoRA的性能。图1a显示,微调前馈网络(FFN)比自关注模块实现了更好的性能。此外,从图1b可以看出,顶层的权重矩阵比底层的权重矩阵更重要。
向关键权重矩阵中添加更多可训练参数可以提高模型性能。相反,向那些不太重要的权重矩阵添加更多的参数只会产生非常小的收益,甚至会损害模型的性能。给定参数预算,即总可训练参数的数量,我们总是倾向于为那些重要的模块分配更多的参数。将预算均匀地分配给所有权重矩阵/层,如LoRA和其他方法(例如,适配器和前缀调优),通常会产生次优性能。为此,一个自然的问题是:
如何根据模块的重要性自适应地分配参数预算,以提高参数高效微调的性能?
为了解决这个问题,我们提出了一种新的方法——AdaLoRA (Adaptive Low-Rank Adaptation),它在类似lora的微调过程中动态地在权重矩阵之间分配参数预算。具体来说,AdaLoRA通过调整增量矩阵的秩来控制它们的预算。关键增量矩阵被赋予较高的等级,这样它们可以捕获更细粒度和特定于任务的信息。为了防止过拟合,节省计算预算,对不重要的部分进行了排序。在现有的矩阵逼近文献中有一些控制矩阵秩的方法(Cai et al ., 2010;Koltchinskii et al, 2011;Toh & Yun, 2010)。它们大多直接计算矩阵的奇异值分解(SVD),然后截断最小的奇异值。这样的操作可以显式地操作秩,更重要的是,可以最小化结果矩阵与原始矩阵之间的差异。然而,对于微调大型模型,迭代地对大量高维权重矩阵应用SVD变得非常昂贵。因此,我们不需要精确计算 S V D SVD SVD,而是将 △ \triangle △参数化为 △ = P Λ Q \triangle=P\Lambda Q △=PΛQ来模拟 S V D SVD SVD。对角矩阵 Λ \Lambda Λ包含奇异值,正交矩阵 P P P和 Q Q Q表示 △ \triangle △的左/右奇异向量。为了正则化 P P P和 Q Q Q的正交性,在训练损失中增加了一个额外的惩罚。这种参数化避免了 S V D SVD SVD的密集计算。此外,该方法的另一个优点是在保持奇异向量的同时,只需要去掉不重要的奇异值。这保留了将来恢复的可能性,并稳定了训练。请参阅第3节中与LoRA的详细比较。
基于我们的 S V D SVD SVD参数化,AdaLoRA通过重要性评分动态调整 △ = P Λ Q \triangle=P\Lambda Q △=PΛQ的排名。具体来说,我们将增量矩阵 P Λ Q P\Lambda Q PΛQ划分为三元组,其中每个三元组 G i G_i Gi包含第 i i i个奇异值和对应的奇异向量。为了量化三元组的重要性,我们提出了一种新的重要性度量,它考虑了 G i G_i Gi中每个条目对模型性能的贡献(Sanh等人,2020;Liang等,2021;Zhang et al, 2022)。具有低重要性分数的三元组被授予低优先级,因此奇异值被归零。保留高重要性的三联体用于微调。此外,我们还提出了一个全局预算调度程序,以方便训练。具体来说,我们从一个初始参数预算开始,这个预算略高于最终预算,然后逐渐减少,直到与目标相匹配。这样的调度程序可以提高训练的稳定性和模型的性能。关于我们的重要性度量和预算调度器的详细描述,请参见第3节。
我们在广泛的任务和模型上进行了大量的实验,以证明AdaLoRA的有效性。具体来说,我们使用DeBERTaV3-base (He等人,2021a)在自然语言理解(GLUE, Wang等人(2019))和问答(SQuADv1, Rajpurkar等人(2016)和SQuADv2, Rajpurkar等人(2018))数据集上评估性能。我们还将我们的方法应用于BART-large (Lewis等人,2019),并评估自然语言生成(XSum, Narayan等人(2018)和CNN/DailyMail, Hermann等人(2015))任务的性能。我们显示AdaLoRA始终优于基线,特别是在低预算设置下。例如,与最先进的方法相比,AdaLoRA在SQuAD2.0数据集上使用不到0.1%的可训练参数进行全面微调,实现了1.2%的F1改进。
2 背景
基于Transformer的模型
典型的Transformer模型由 L L L个堆叠块组成,其中每个块包含两个子模块:多头注意(MHA)和完全连接的FFN。给定输入序列 X ∈ R n × d X\in \mathbb{R}^{n\times d} X∈Rn×d, MHA以并行 h h h头执行注意函数:
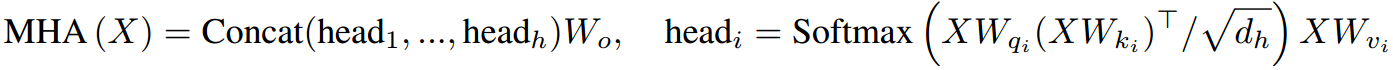
其中, W 0 ∈ R d × d W_0\in \mathbb{R}^{d\times d} W0∈Rd×d为输出投影, W q i , W k i , W v i W_{q_i},W_{k_i},W_{v_i} Wqi,Wki,Wvi为头部 i i i的查询投影、键投影、值投影。 d h d_h dh一般设为d/h。另一个重要的模块是一个FFN,它由两个线性变换组成,中间有一个ReLU激活: F F N ( X ) = R e L U ( X W f 1 + b 1 ) W f 2 + b 2 FFN(X) = ReLU(XW_{f_1} + b_1)W_{f_2} + b_2 FFN(X)=ReLU(XWf1+b1)Wf2+b2,其中 W f 1 ∈ R d × d m , W f 1 ∈ R d m × d W_{f_1}\in \mathbb{R}^{d\times d_m},W_{f_1}\in \mathbb{R}^{d_m\times d} Wf1∈Rd×dm,Wf1∈Rdm×d。最后,使用残差连接,然后进行层归一化(Ba et al, 2016)。
3 ADALORA 方法
3.1基于SVD的适配
如第1节所述,我们提出以奇异值分解的形式参数化预训练权矩阵的增量更新:
W = W ( 0 ) + Δ = W ( 0 ) + P Λ Q ( 3 ) W=W^{(0)}+\Delta =W^{(0)}+P\Lambda Q\ (3) W=W(0)+Δ=W(0)+PΛQ (3)
式中 P ∈ R d 1 × r P\in \mathbb{R}^{d_1\times r} P∈Rd1×r和 P ∈ R r × d 2 P\in \mathbb{R}^{r\times d_2} P∈Rr×d2表示 Δ \Delta Δ的左右奇异向量,对角矩阵 Λ ∈ R r × r \Lambda \in \mathbb{R}^{r\times r} Λ∈Rr×r包含奇异值 { λ i } 1 ≤ i ≤ r \{\lambda_i\}_{1\le i \le r} {λi}1≤i≤r,且 r ≪ m i n ( d 1 , d 2 ) r \ll min(d_1,d_2) r≪min(d1,d2)。进一步将 G i = { P ∗ i , λ i , Q i ∗ } G_i=\{P_{*i},\lambda_i,Q_{i*}\} Gi={P∗i,λi,Qi∗}表示为包含第 i i i个奇异值和向量的三元组。实际上,因为 Λ \Lambda Λ是对角的,我们只需要把它保存为 R r \mathbb{R}^{r} Rr中的一个向量。 Λ \Lambda Λ初始化为零, P P P和 Q Q Q采用随机高斯初始化,以保证训练开始时 Δ = 0 \Delta=0 Δ=0。为了实现 P P P与 Q Q Q的正交性,即 P T P = Q Q T = I P^TP=QQ^T=I PTP=QQT=I,我们利用以下正则化器:
R ( P , Q ) = ∥ P T P − I ∥ F 2 + ∥ Q T Q − I ∥ F 2 ( 4 ) R(P,Q)=\|P^TP-I\|^2_F+\|Q^TQ-I\|^2_F\ (4) R(P,Q)=∥PTP−I∥F2+∥QTQ−I∥F2 (4)
在我们的方法中, Λ \Lambda Λ被迭代修剪以在每个梯度体面步骤之后调整秩。如第1节所述,可以直接计算每个 Δ \Delta Δ的SVD来处理奇异值。然而,计算复杂度是 O ( m i n ( d 1 , d 2 ) d 1 d 2 ) O(min(d_1,d_2)d_1d_2) O(min(d1,d2)d1d2)。迭代地对大量高维增量矩阵应用奇异值分解变得非常昂贵。相比之下,我们的参数化避免了密集的SVD计算,极大地释放了计算开销。
我们注意到,人们也可以对LoRA应用结构化剪枝来控制秩(即,在(1)中双修BA),然而它有以下缺点。首先,当一件上衣被认为不重要时,我们必须删减它的所有元素。这使得几乎不可能重新激活修剪的双元,因为它们的条目都被归零并且没有经过训练。相比之下,**AdaLoRA仅掩盖了基于(3)的奇异值,而始终保持奇异向量。**它保留了未来可能恢复的三胞胎的错误。其次,LoRA的A和B不是正交的,这意味着双偶可以相互依赖。与截断最小的奇异值相比,丢弃重态会引起与原始矩阵更大的变化。因此,在每一步的秩分配之后,增量矩阵往往会发生巨大的变化,从而导致训练不稳定,甚至损害泛化。为了证明这一点,我们在第4.4节中提出了一项消融研究,比较了AdaLoRA与LoRA的结构化修剪。
3.3 全局预算调度器
如第1节所述,在低秩适应的情况下,调整秩自然是为了控制参数预算。因此,我们将预算 b ( t ) b^{(t)} b(t)定义为所有增量矩阵的总秩,即总奇异值的个数。回想一下,在微调期间迭代地执行预算分配。为了方便训练,我们提出了一个全局预算调度程序。具体来说,我们从略高于目标预算 b ( T ) b^{(T)} b(T)的初始预算 b ( 0 ) b^{(0)} b(0)开始(例如, b ( T ) b^{(T)} b(T)的1.5倍)。我们将每个增量矩阵的初始秩设为 r = b ( 0 ) / n r=b^{(0)}/n r=b(0)/n。我们将训练热身 t i t_i ti步,然后按照三次计划减少预算 b ( t ) b^{(t)} b(t),直到达到 b ( T ) b^{(T)} b(T)。最后,我们修正了最终的预算分布,并为 t f t_f tf步调整了模型。预算进度的确切公式见附录a。这允许AdaLoRA先探索参数空间,然后再关注最重要的权重。
5 结论
提出了一种参数高效的微调方法——AdaLoRA,根据重要性评分自适应分配参数预算。在AdaLoRA中,我们以奇异值分解的形式参数化权矩阵的增量更新。然后,我们根据一个新的重要度量,通过操纵奇异值,在增量矩阵之间动态分配参数预算。该方法有效地提高了模型性能和参数效率。我们在自然语言处理、问答和自然语言生成任务方面进行了广泛的实验。结果表明,AdaLoRA优于现有的方法。
参考资料
论文下载(ICLR(A) 2023)
https://arxiv.org/abs/2303.10512