贝叶斯机器学习:从经济衰退预测到动态对冲交易
在本章中,我们将介绍贝叶斯机器学习(Bayesian ML)方法,以及它们在开发和评估交易策略时如何通过不同的不确定性视角增加价值。
贝叶斯统计允许我们量化未来事件的不确定性,并随着新信息的到来以有条理的方式完善我们的估计。这种动态方法很好地适应了金融市场不断变化的性质。当相关数据较少时,需要系统地整合先验知识或假设的方法尤其有用。
我们将看到,贝叶斯机器学习方法可以为统计度量、参数估计和预测的不确定性提供更丰富的见解。应用范围从更细粒度的风险管理到动态更新的预测模型,后者可以吸收市场环境的变化。资产配置的Black-Litterman方法(参见第5章 投资组合优化和绩效评估)可以被解释为一个贝叶斯模型。它将资产的预期收益计算为市场均衡和投资者观点的加权平均值,权重由该资产的波动率、跨资产相关性和每个预测的置信度决定。
内容
贝叶斯机器学习是如何工作的
古典统计学被认为遵循频率主义方法,因为它将概率解释为长期内事件发生的相对频率,即在观察到大量试验后。在概率的背景下,事件是实验的一个或多个基本结果的组合,例如掷两个骰子的任何六个等可能结果或某资产价格在给定一天内下跌10%或更多。
而贝叶斯统计学将概率视为对事件发生的信心或信念的度量。因此,贝叶斯观点比频率主义解释留出了更多的主观视角和意见差异空间。对于发生频率不足以得出长期客观频率度量的事件,这种差异最为明显。
换句话说,频率主义统计学假设数据是从一个群体中随机抽取的样本,旨在识别生成数据的固定参数。相反,贝叶斯统计学将数据视为已知,并认为参数是可以从数据中推断出分布的随机变量。因此,频率主义方法至少需要与要估计的参数数量一样多的数据点。而贝叶斯方法则可以适用于较小的数据集,并且非常适合一次一个样本的在线学习。
贝叶斯观点对于许多现实世界中罕见或独特的事件非常有用。例如,下一次选举的结果或市场是否将在三个月内崩盘的问题。在每种情况下,都存在相关的历史数据以及随着事件的临近而展开的独特环境。
我们首先介绍贝叶斯定理,它阐明了通过将先验假设与新的经验证据相结合来更新信念的概念,并将其结果参数估计与频率主义方法进行比较。然后,我们演示两种贝叶斯统计推断方法,即共轭先验和近似推断,它们可以提供对潜在的未观测参数(如期望值)的后验分布的洞见:
- 共轭先验通过提供一个封闭形式的解决方案,简化了更新过程,使我们能够精确地计算解决方案。但是,这种精确的解析方法并不总是可用的。
- 近似推断模拟了由假设和数据结合而产生的分布,并使用该分布的样本来计算统计见解。
参考文献
如何从经验证据更新假设
250多年前,贝叶斯牧师提出的定理使用基本的概率理论来规定,当相关的新信息到来时,概率或信念应该如何变化,正如约翰·梅纳德·凯恩斯所说:“当事实发生变化时,我就改变我的想法。你呢,先生?”。
- 贝叶斯规则:指南
- 使用连续先验的贝叶斯更新, MIT开放课程,18.05概率和统计导论
精确推断:最大后验估计
将贝叶斯规则应用于精确计算后验概率的实际应用非常有限,因为计算分母中的证据项非常具有挑战性。
如何保持推断简单:共轭先验
当后验分布与先验分布属于同一类型的分布(除了参数不同)时,我们称该先验分布与似然函数是共轭的。先验和似然的共轭性意味着后验分布有一个封闭形式的解决方案,这简化了更新过程,避免了使用数值方法来近似后验分布的需要。
代码示例:如何动态估计资产价格变动的概率
笔记本updating_conjugate_priors演示了如何使用共轭先验来更新来自S&P 500样本的价格变动估计。
确定性和随机近似推断
对于大多数实际相关的模型来说,不可能解析地推导出精确的后验分布并计算潜在参数的期望值。
虽然对于某些应用程序,未观测参数的后验分布可能是感兴趣的,但通常主要需要评估期望值,例如进行预测。在这种情况下,我们可以依赖近似推断:
基于马尔可夫链蒙特卡罗(MCMC)采样的随机技术已经使贝叶斯方法在许多领域广为人知。它们通常具有收敛到精确结果的性质。在实践中,采样方法可能计算量很大,通常局限于小规模问题。
- 汉密尔顿蒙特卡罗方法的概念性介绍, Michael Betancourt, 2018
- 无U转采样器:在汉密尔顿蒙特卡罗中自适应设置路径长度, Matthew D. Hoffman, Andrew Gelman, 2011
- ML、MAP和贝叶斯 - 参数估计和数据预测的神圣三位一体
称为变分推断或变分贝叶斯的确定性方法基于对后验分布的解析近似,可以很好地扩展到大规模应用。它们做出简化假设,例如后验分布在某种特定方式下分解,或具有特定参数形式如高斯分布。因此,它们不会产生精确的结果,可以作为采样方法的补充。
- 变分推断:统计学家的综述, David Blei等, 2018
使用PyMC3的概率编程
概率编程提供了一种描述和拟合概率分布的语言,因此我们可以设计、编码并自动估计和评估复杂的模型。它旨在抽象掉一些计算和分析复杂性,让我们能够专注于贝叶斯推理和推断的概念上更直接和直观的方面。
自从优步开源了基于PyTorch的Pyro,以及谷歌最近为TensorFlow添加了一个概率模块以来,这个领域变得相当活跃。
使用Theano的贝叶斯机器学习
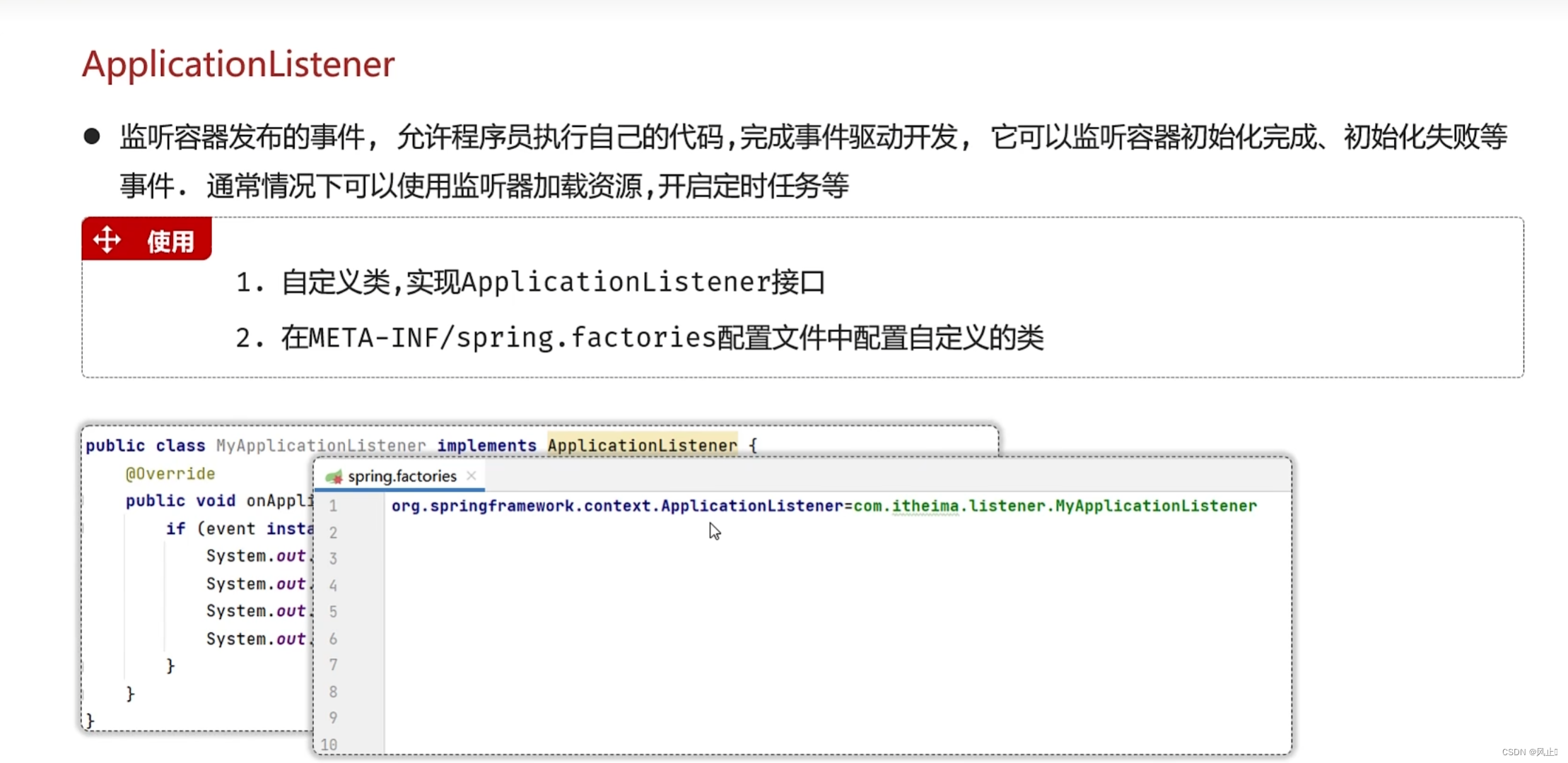
- PyMC3于2017年1月发布,为使用在PyMC2(2012年发布)中的Metropolis-Hastings采样器添加了汉密尔顿蒙特卡罗方法。PyMC3使用Theano作为其计算后端,用于动态C编译和自动微分。Theano是一个由Yoshua Bengio的蒙特利尔机器学习算法研究所(MILA)开发的专注于矩阵的GPU加速优化库,启发了TensorFlow。由于新的深度学习库的成功,MILA最近决定不再进一步开发Theano(详见第16章)。
- PyMC4,计划于2019年发布,将使用TensorFlow,对API的影响应该有限。
PyMC3工作流程
PyMC3旨在提供直观、易读但功能强大的语法,反映统计学家描述模型的方式。建模过程通常遵循以下三个步骤:
- 通过定义以下内容来编码概率模型:
- 量化潜在变量知识和不确定性的先验分布
- 将参数与观测数据相关联的似然函数
- 使用前一节中描述的选项之一分析后验分布:
- 使用MAP推断获得点估计
- 使用MCMC方法从后验分布中采样
- 使用变分贝叶斯近似后验分布
- 使用各种诊断工具检查您的模型
- 生成预测
- 文档
- 使用PyMC的Python中的概率编程, Salvatier等, 2015
- Theano:一个用于快速计算数学表达式的Python框架, Al-Rfou等, 2016
- Bayesian Methods for Hackers
- 糟糕的轨迹,或者不要使用Metropolis
- PyMC 4在GitHub上,包含设计指南和使用示例。
代码示例:使用PyMC3预测经济衰退
笔记本pymc3_workflow使用简单的逻辑回归模型预测经济衰退,说明了PyMC3工作流程的各个方面。
数据:领先经济衰退指标
好的,我继续翻译剩余部分:
数据:领先经济衰退指标
我们将使用一个小而简单的数据集,以便我们可以专注于工作流程。我们使用联邦储备经济数据(FRED)服务(参见第2章)下载了美国国家经济研究局定义的经济衰退日期,并获取了4个通常用于预测经济衰退开始的变量(Kelley 2019),它们也可通过FRED获得:
- 国库收益率曲线的长期利差,定义为10年期和3个月期国库收益率之差。
- 密歇根大学的消费者情绪指标
- 全国金融状况指数(NFCI)
- NFCI非金融杠杆子指数
模型定义:贝叶斯逻辑回归
如线性模型一章所述,逻辑回归估计一组特征与二元结果之间的线性关系,通过sigmoid函数将其转化为概率。频率主义方法得到了参数的点估计,这些参数度量每个特征对正类概率的影响,并基于参数分布的假设给出了置信区间。
而贝叶斯逻辑回归估计参数本身的后验分布。后验分布允许对每个参数的贝叶斯可信区间进行更稳健的估计,并提供关于模型不确定性的更多透明度。
笔记本pymc3_workflow演示了PYMC3工作流程,包括:
- MAP推断
- 马尔可夫链蒙特卡罗估计
- Metropolis-Hastings
- NUTS采样器
- 变分推断
- 模型诊断
- 能量图和森林图
- 后验预测检查(PPD)
- 可信区间(CI)
- 预测
- MCMC采样器动画
交易中的贝叶斯机器学习
现在我们熟悉了贝叶斯机器学习方法和使用PyMC3进行概率编程,让我们探讨一些相关的交易应用,即:
- 将Sharpe比率建模为概率模型,以获得更深入的绩效比较
- 使用贝叶斯线性回归计算对冲交易的对冲比率
- 从贝叶斯角度分析线性时间序列模型
代码示例:用于绩效比较的贝叶斯Sharpe比率
笔记本bayesian_sharpe_ratio说明了如何使用PyMC3将Sharpe比率(SR)定义为概率模型,以及如何比较不同收益序列的后验分布。
对两个序列进行贝叶斯估计提供了非常丰富的见解,因为它提供了可信值效应大小、组平均SR及其差异、标准差及其差异的完整分布。这个Python实现由Thomas Wiecki完成,受到R包BEST(Meredith和Kruschke 2018)的启发,见"资源"部分。
贝叶斯SR的相关用例包括分析不同策略之间的差异,或策略的样本内收益相对于样本外收益(详见bayesian_sharpe_ratio笔记本)。贝叶斯Sharpe比率也是pyfolio的贝叶斯报告单的一部分。
代码示例:用于对冲交易的贝叶斯滚动回归
上一章节介绍了对冲交易作为一种流行的交易策略,它依赖于两个或多个资产的协整。对于这样的资产,我们需要估计对冲比率来决定多头和空头头寸的相对大小。一种基本方法使用线性回归。
笔记本rolling_regression说明了贝叶斯线性回归如何随时间跟踪两个资产之间关系的变化。它遵循Thomas Wiecki的示例(见"资源"部分)。
代码示例:随机波动性模型
如时间序列模型一章所讨论的,资产价格具有随时间变化的波动性。在某些时期,收益波动很大,而在其他时期则非常稳定。
随机波动性模型以一个潜在的波动率变量建模这一点,该变量被建模为一个随机过程。无U转采样器就是使用这种模型引入的,笔记本stochastic_volatility说明了这种用例。
资源
PyMC3
PyMC3的主要作者之一、Quantopian的数据科学负责人Thomas Wiecki创建了几个示例,以下部分遵循并建立在此基础之上。PyMC3文档包含更多教程。
- PyMC3 教程
- 解决朴素贝叶斯文本分类器的错误假设, Rennie等, MIT SAIL, 2003
- 判别式vs生成式分类器:逻辑回归和朴素贝叶斯的比较, Jordan, Ng, 2002
- 贝叶斯估计优于t检验, John K. Kruschke, 实验心理学杂志, 2012
- 自动微分变分推断
其他概率编程库
- 概率编程社区仓库,包含论文和软件链接
- Stan
- Edward
- TensorFlow Probability
- Pyro



























![[LitCTF 2023]Virginia(变异凯撒)](https://img-blog.csdnimg.cn/direct/d5d199911e9b450fbcd3c08b5443790d.png)