前言
本文是该专栏的第29篇,后面会持续分享python爬虫干货知识,记得关注。
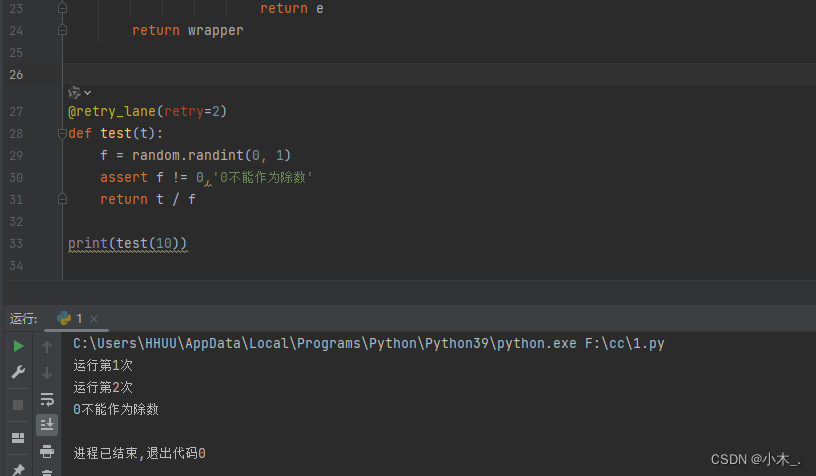
处理过爬虫项目的同学,相信或多或少都知道python爬虫进行数据采集的时候,不可能每次都是100%采集成功,正因为如此,所以才有了爬虫的“自动重试机制”。
在web开发中,有时候需要通过网络请求获取数据。但是,网络请求并不总是稳定的,有时会因为多种原因导致请求失败。而我们为了提高程序的稳定性和用户体验,通常会加入重试机制,即我们在请求失败的时候,自动重新发起请求。
而本文,笔者将详细介绍一种“python爬虫在运行过程中,出现网络请求失败,从而自动触发重试机制,并进行自动请求”的方法。
具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。废话不多说,跟着笔者直接往下看正文详细内容。(附带完整代码)
正文
要知道,python的requests库是一个常用的http客户端库,而它本身没有直接提供重试机制,但是我们却可以结合其它方法来实现重试机制的逻辑。
在requests库中,有一个urllib3,它是requests库底层使用的HTTP客户端库,它提供了Retry类来实现重试逻