文章目录
-
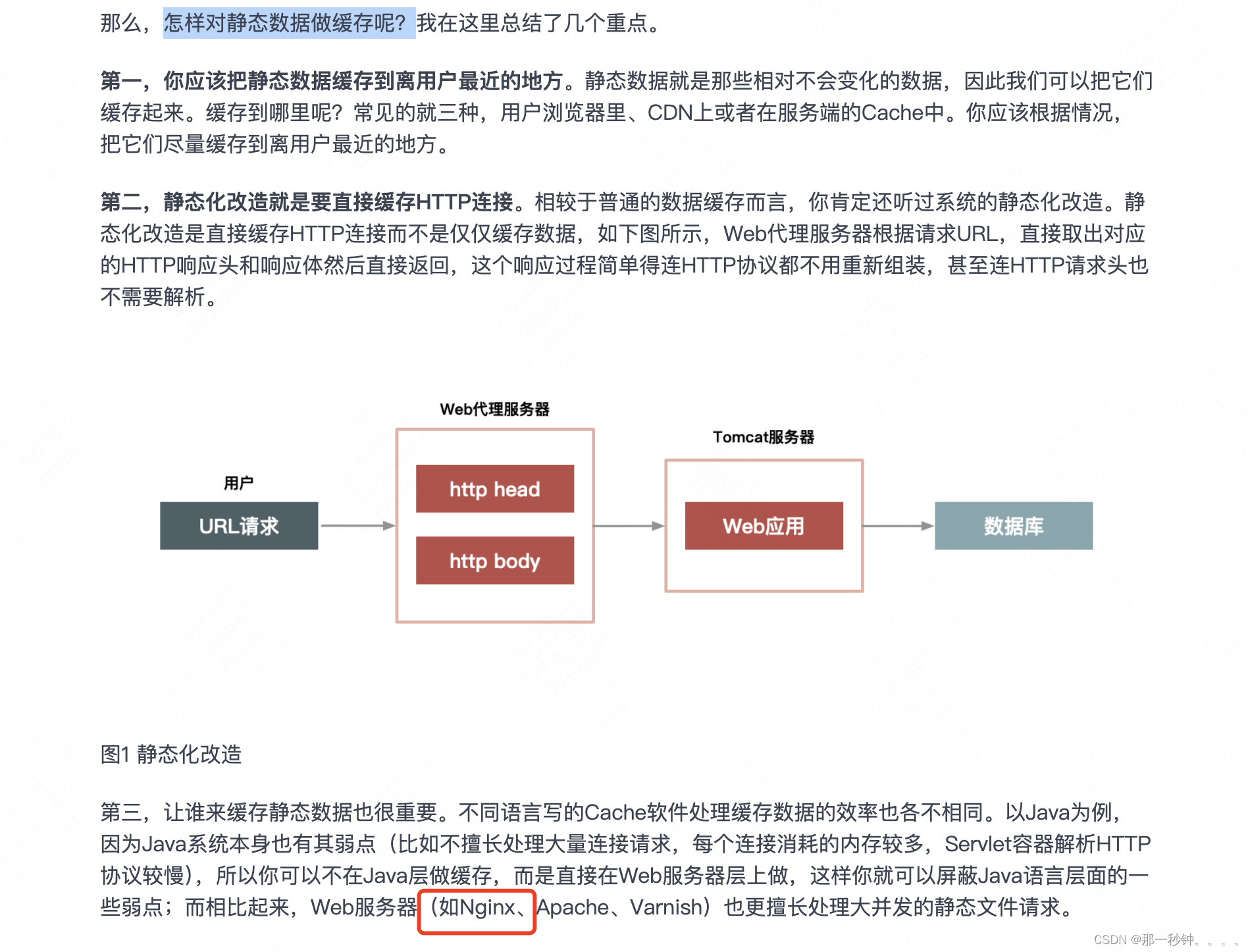
- 问题
- group by到底做了什么
- 举个例子
- 简单来说
- 为什么select字段,count()不能和*共同使用
- 总结
问题

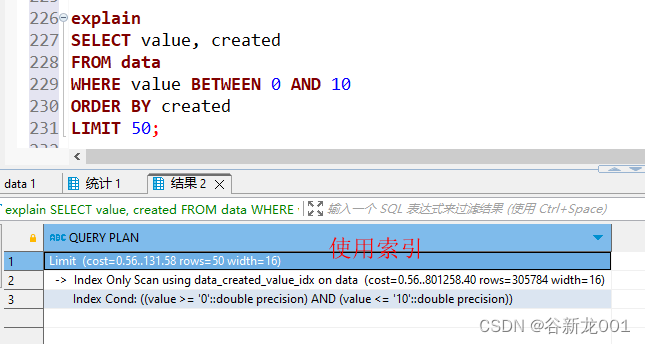
这是一段摘抄自MySQL官网的文字。其大致意思是MySQL拓展了group by的使用,MySQL允许选择没有出现在group by中的字段。换句话说,标准SQL是不允许select column出现没在group by中出现的字段
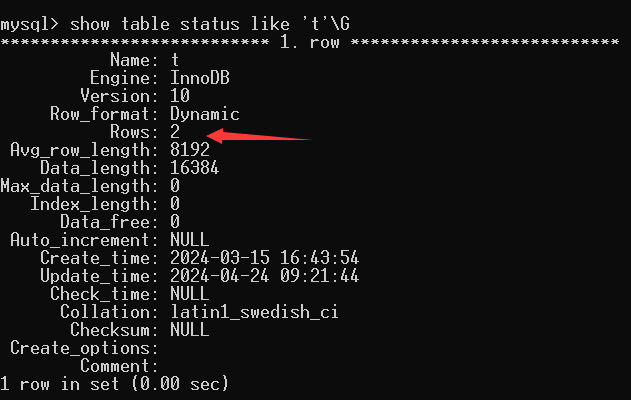
所以在MySQL中,select * from table group by column是允许的
BUT
select *, count(column) from table group by column是不允许的
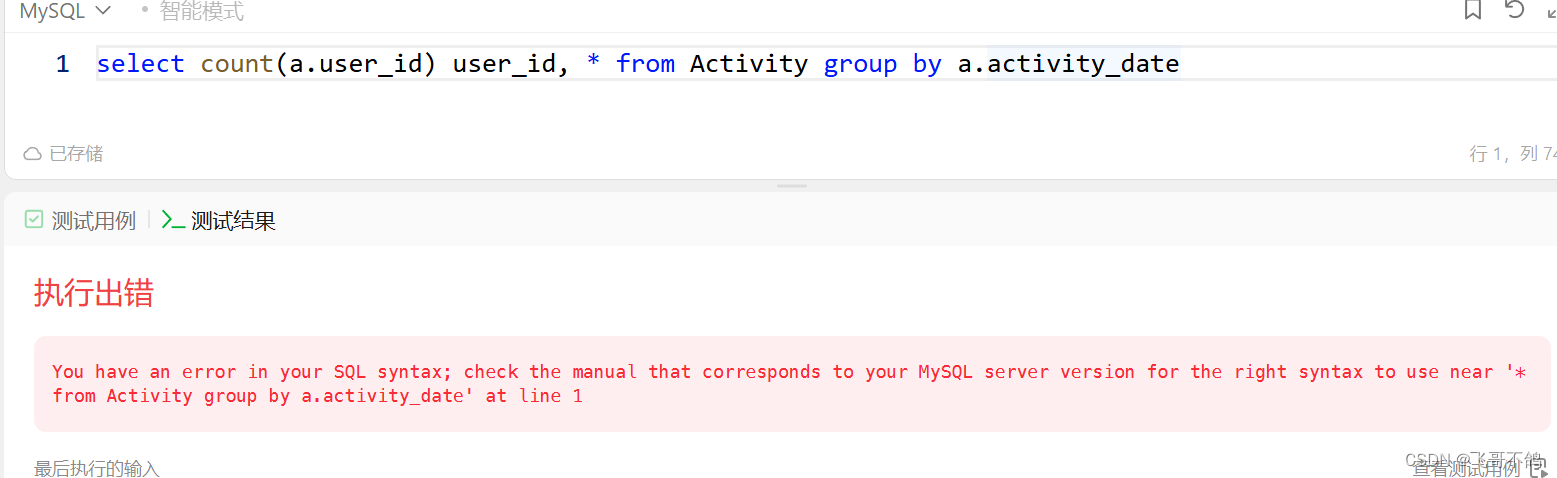
我们来简单分析一下原因
group by到底做了什么
扫描表数据:
- 数据库引擎从表中读取所有行。
按分组列进行排序或哈希:
- 数据库引擎根据 GROUP BY 子句中指定的列对行进行排序,或使用哈希算法将行分到不同的分组中。不同的数据库系统可能使用不同的实现方式(排序、哈希、甚至混合方法)来高效地实现分组。
分配行到各个分组:
- 数据库将每一行放入相应的分组。所有具有相同 GROUP BY 列值的行将被分配到同一个分组。
应用聚合函数:
- 对每个分组应用指定的聚合函数(如 COUNT, SUM, AVG, MAX, MIN 等)。这些聚合函数会对每个分组中的行进行计算,并返回一个聚合结果。
生成输出:
- 对于每个分组,生成一行输出结果,包含 GROUP BY 列以及聚合函数的计算结果。
举个例子
假设我们有一个简单的表 Sales:
CREATE TABLE Sales (
sale_id INT,
sale_date DATE,
amount DECIMAL(10, 2)
);
INSERT INTO Sales (sale_id, sale_date, amount) VALUES
(1, '2023-06-01', 100.00),
(2, '2023-06-01', 150.00),
(3, '2023-06-02', 200.00),
(4, '2023-06-03', 250.00),
(5, '2023-06-03', 300.00);
我们要按 sale_date 分组,并计算每个日期的总销售额:
SELECT sale_date, SUM(amount) AS total_sales
FROM Sales
GROUP BY sale_date;
执行步骤:
扫描表数据:
- 数据库读取所有行:(1, ‘2023-06-01’, 100.00), (2, ‘2023-06-01’, 150.00), (3, ‘2023-06-02’, 200.00), (4, ‘2023-06-03’, 250.00), (5, ‘2023-06-03’, 300.00)。
按分组列进行排序或哈希:
- 数据库根据 sale_date 对数据进行排序或哈希:[‘2023-06-01’, ‘2023-06-01’, ‘2023-06-02’, ‘2023-06-03’, ‘2023-06-03’]。
分配行到各个分组:
- 数据库将行分配到分组:
- Group 1 (‘2023-06-01’): (1, ‘2023-06-01’, 100.00), (2, ‘2023-06-01’, 150.00)
- Group 2 (‘2023-06-02’): (3, ‘2023-06-02’, 200.00)
- Group 3 (‘2023-06-03’): (4, ‘2023-06-03’, 250.00), (5, ‘2023-06-03’, 300.00)
- 数据库将行分配到分组:
应用聚合函数:
- 对每个分组应用 SUM(amount):
- Group 1: SUM(100.00, 150.00) = 250.00
- Group 2: SUM(200.00) = 200.00
- Group 3: SUM(250.00, 300.00) = 550.00
生成输出:
- 生成每个分组的输出:
- (‘2023-06-01’, 250.00)
- (‘2023-06-02’, 200.00)
- (‘2023-06-03’, 550.00)
- 生成每个分组的输出:
简单来说
说的通俗点就是形成如下数据结构
Map<Column, List> groupBy
- k1 -> [row1, row2, row3]
- k2 -> [row4, row5, row6]
然后迭代groupBy,对每个List做聚合处理
ans = []
for key, values in groupBy:
ans.append(key, 聚合函数(values))
为什么select字段,count()不能和*共同使用
通过上述分析不难发现,count() 函数是对**聚合后的List<Row>**使用
加入我们是select *,那么Row中的数据将会包含一行的所有字段,此时的count应该处理的是count函数 中所指定的字段。count处理完成后,将List<Row>聚合成一个值,那么其他的字段呢?其他的字段也要聚合成一个值,但没有聚合规则呀
所以,count()和*理论上不能同时出现在select字段中。因为count只聚合函数指定的字段,而select *则表示数据行出现所有字段。
其中 一个字段制定了聚合规则,从List聚合为value,那其他字段可不知道怎么聚合,处理后依然是List,因此出现了数据维度的差异,所以理论上count()和*不能同时出现
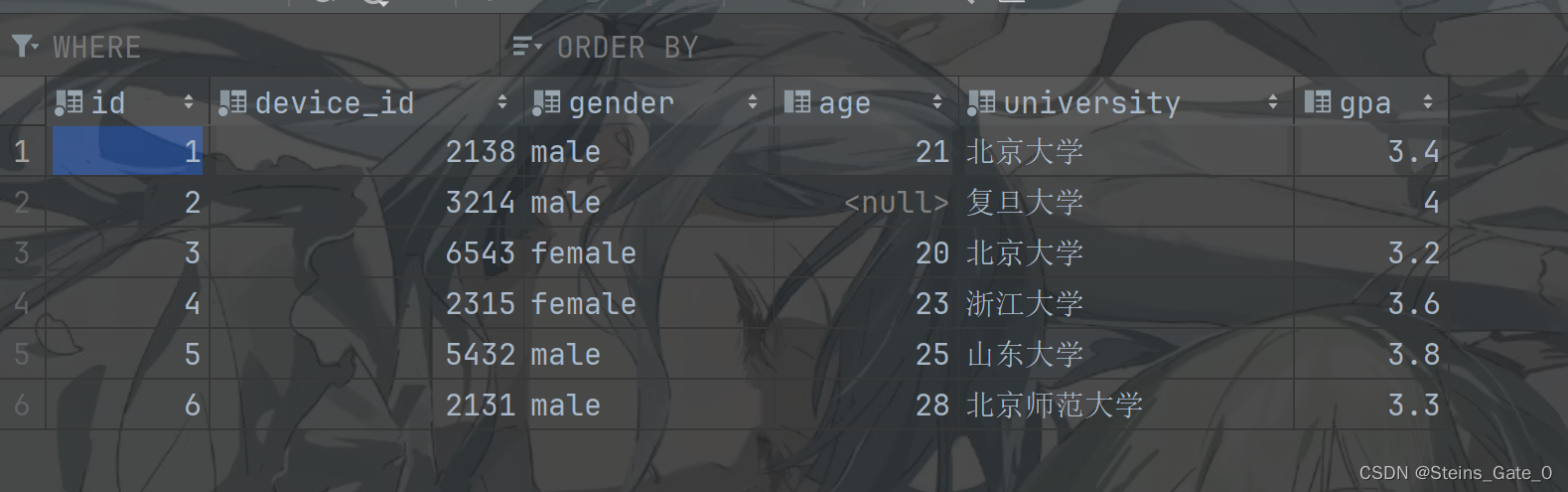
BUT,我们看看这段SQL
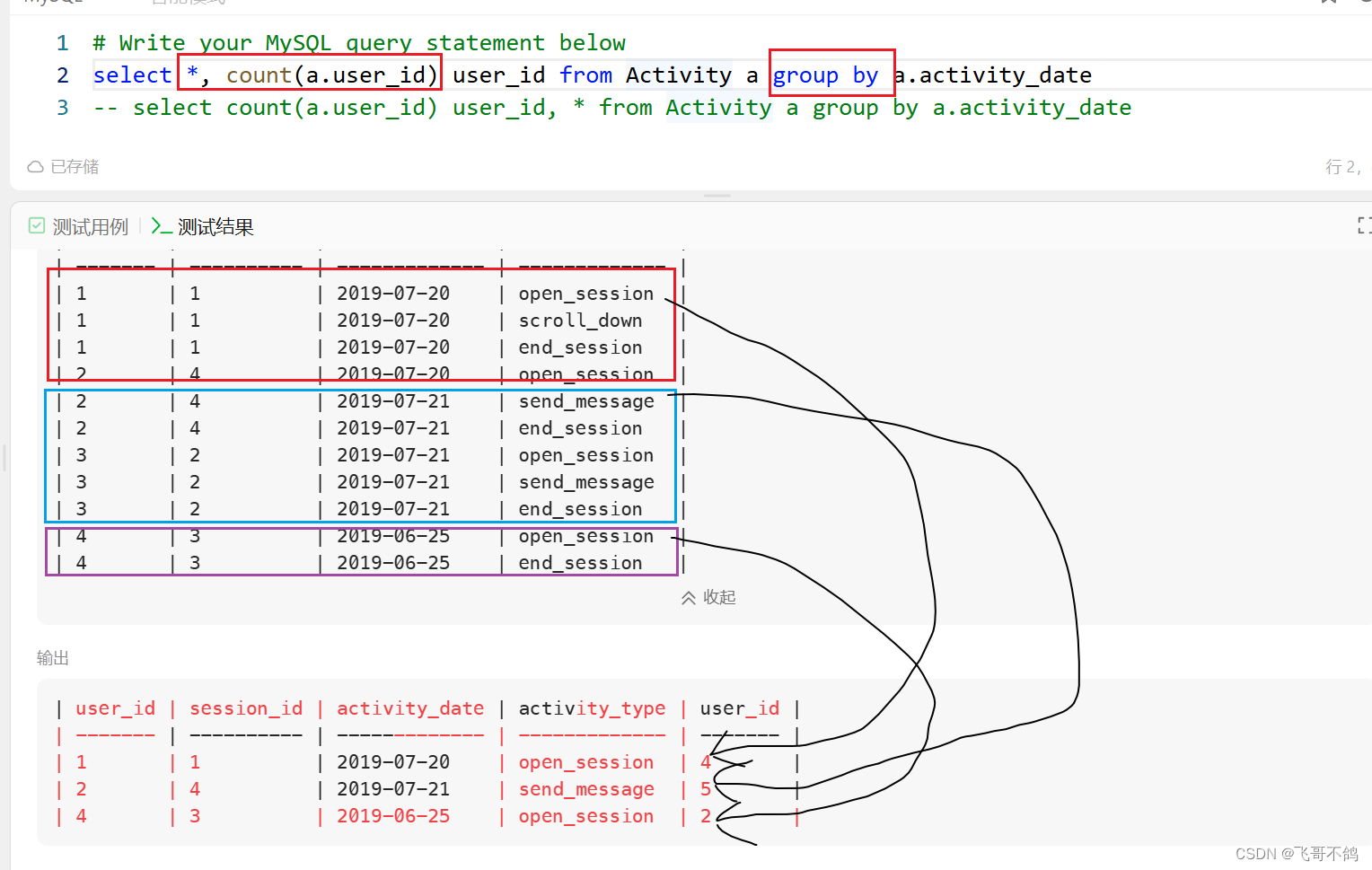
依然是能够跑通的,但这是为什么呢?
其实原因很简单。虽然其他字段不知道聚合规则,但要从List聚合为value,随便选一条数据不久完事了。我们从上图可知,对于非聚合字段,MySQL选择了组间第一行数据作为输出
总结
理论上,group by [col1, col2…]只能和select [col1, col2…]配合,也就是如果存在group by,那么select的字段必须出现在group by中
但是MySQL做出了拓展,允许非聚合字段和聚合字段同时出现
并且允许select *, count(col1) from table group by col1这种形式的SQL出现























![【已解决】FileNotFoundError: [Errno 3] No such file or directory: ‘xxx‘](https://img-blog.csdnimg.cn/direct/54dbfb4788b847e282fbdbe2a8715db7.png)