之前都用的集成算法,发现差异不大,考虑在特征优化上提升数据质量,用NLP算法优化id列
有两种方法,分别是countervector和TF-IDF,前者就是词频,后者由TF(词频)和IDF(反文档词频)两部分组成,具体理论部分可参考推荐算法课程学习笔记2:文本特征提取基础_countervector-CSDN博客这篇文章
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from scipy import sparse
# 创建空DataFrame用于保存NLP特征
train_x = pd.DataFrame()
test_x = pd.DataFrame()
# 实例化CountVectorizer评估器与TfidfVectorizer评估器
cntv = CountVectorizer()
tfv = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9, use_idf=1, smooth_idf=1, sublinear_tf=1) #max_df指词汇表中超过这个阈值的词会被剔除
# 创建空列表用户保存修正后的列名称
vector_feature=[]
for co in ['merchant_id', 'merchant_category_id', 'state_id', 'subsector_id', 'city_id']:
vector_feature.extend([co+'_new', co+'_hist', co+'_all']) #
# 提取每一列进行新特征衍生
for feature in vector_feature:
print(feature)
cntv.fit([feature].append(test[feature])) #统计词频
train_x = sparse.hstack((train_x, cntv.transform(train[feature]))).tocsr() #tocsr作用是保存成稀疏矩阵的格式,sparse.hstack
test_x = sparse.hstack((test_x, cntv.transform(test[feature]))).tocsr()
tfv.fit(train[feature].append(test[feature]))
train_x = sparse.hstack((train_x, tfv.transform(train[feature]))).tocsr()
test_x = sparse.hstack((test_x, tfv.transform(test[feature]))).tocsr()
# 保存NLP特征衍生结果
sparse.save_npz(\ preprocess/train_nlp.npz\ , train_x)
sparse.save_npz(\ preprocess/test_nlp.npz\ , test_x)
接下来进行xgboost训练,先导入包
import xgboost as xgb
from sklearn.feature_selection import f_regression
from numpy.random import RandomState
from bayes_opt import BayesianOptimization
然后读数据
train = pd.read_csv('preprocess/train.csv')
test = pd.read_csv('preprocess/test.csv')
注意由于xgboost会自动做特征筛选,因此自己不会去筛
导入特征名和训练数据集
features = train.columns.tolist()
features.remove('card_id')
features.remove('target')
train_x = sparse.load_npz(\ preprocess/train_nlp.npz\ )
test_x = sparse.load_npz(\ preprocess/test_nlp.npz\ )
train_x = sparse.hstack((train_x, train[features])).tocsr()
test_x = sparse.hstack((test_x, test[features])).tocsr()
模型训练与优化
参数回调函数 (声明那些固定的参数)
def params_append(params):
\ \ \
:param params:
:return:
\ \ \
params['objective'] = 'reg:squarederror'
params['eval_metric'] = 'rmse'
params['min_child_weight' ] = int(params[\ min_child_weight\ ])
params['max_depth'] = int(params['max_depth'])
return params
声明贝叶斯优化过程:
def param_beyesian(train):
# Part 1.数据准备
train_y = pd.read_csv(\ data/train.csv\ )['target']
# 数据封装
sample_index = train_y.sample(frac=0.1, random_state=2020).index.tolist() #随机抽取一些样例
train_data = xgb.DMatrix(train.tocsr()[sample_index, : ], train_y.loc[sample_index].values, silent=True)
# 借助cv过程构建目标函数 :即输入一组超参数
def xgb_cv(colsample_bytree, subsample, min_child_weight, max_depth,
reg_alpha, eta,
reg_lambda):
params = {'objective': 'reg:squarederror',
'early_stopping_round': 50,
'eval_metric': 'rmse'}
params['colsample_bytree'] = max(min(colsample_bytree, 1), 0)
params['subsample'] = max(min(subsample, 1), 0)
params['min_child_weight'] = int(min_child_weight)
params['max_depth'] = int(max_depth)
params['eta'] = float(eta)
params['reg_alpha'] = max(reg_alpha, 0)
params['reg_lambda'] = max(reg_lambda, 0)
print(params)
cv_result = xgb.cv(params, train_data,
num_boost_round=1000,
nfold=2, seed=2,
stratified=False,
shuffle=True,
early_stopping_rounds=30,
verbose_eval=False)
return -min(cv_result['test-rmse-mean'])
# 调用贝叶斯优化器进行模型优化
xgb_bo = BayesianOptimization(
xgb_cv,
{'colsample_bytree': (0.5, 1),
'subsample': (0.5, 1),
'min_child_weight': (1, 30),
'max_depth': (5, 12),
'reg_alpha': (0, 5),
'eta':(0.02, 0.2),
'reg_lambda': (0, 5)}
)
xgb_bo.maximize(init_points=21, n_iter=5) # init_points表示初始点,n_iter代表迭代次数(即采样数)
print(xgb_bo.max['target'], xgb_bo.max['params'])
return xgb_bo.max['params']
def train_predict(train, test, params):
\ \ \
:param train:
:param test:
:param params:
:return:
\ \ \
train_y = pd.read_csv(\ data/train.csv\ )['target']
test_data = xgb.DMatrix(test)
params = params_append(params)
kf = KFold(n_splits=5, random_state=2020, shuffle=True)
prediction_test = 0
cv_score = []
prediction_train = pd.Series()
ESR = 30
NBR = 10000
VBE = 50
for train_part_index, eval_index in kf.split(train, train_y):
# 模型训练
train_part = xgb.DMatrix(train.tocsr()[train_part_index, :],
train_y.loc[train_part_index])
eval = xgb.DMatrix(train.tocsr()[eval_index, :],
train_y.loc[eval_index])
bst = xgb.train(params, train_part, NBR, [(train_part, 'train'),
(eval, 'eval')], verbose_eval=VBE,
maximize=False, early_stopping_rounds=ESR, )
prediction_test += bst.predict(test_data)
eval_pre = bst.predict(eval)
prediction_train = prediction_train.append(pd.Series(eval_pre, index=eval_index))
score = np.sqrt(mean_squared_error(train_y.loc[eval_index].values, eval_pre))
cv_score.append(score)
print(cv_score, sum(cv_score) / 5)
pd.Series(prediction_train.sort_index().values).to_csv(\ preprocess/train_xgboost.csv\ , index=False)
pd.Series(prediction_test / 5).to_csv(" preprocess/test_xgboost.csv" , index=False)
test = pd.read_csv('data/test.csv')
test['target'] = prediction_test / 5
test[['card_id', 'target']].to_csv(" result/submission_xgboost.csv" , index=False)
return
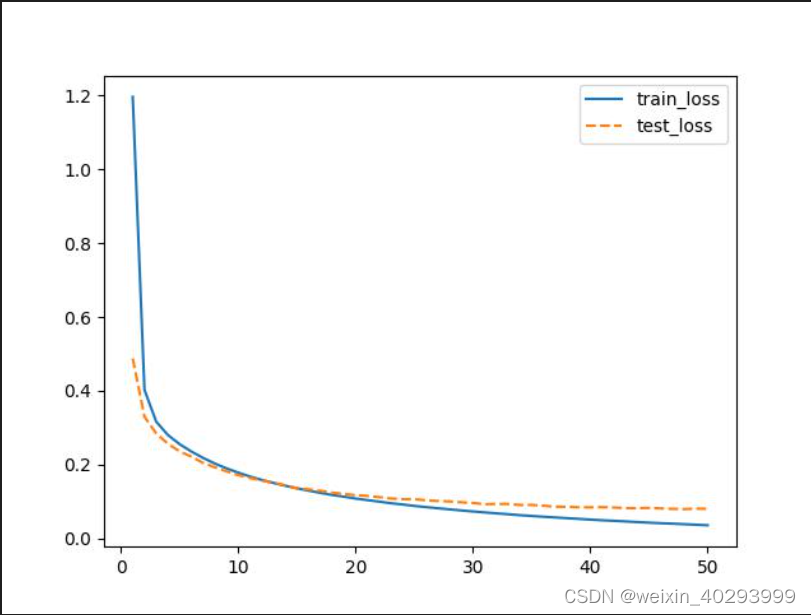
发现私榜分数3.62,公榜3.72,提升了





















![[Linux]内网穿透nps](https://img-blog.csdnimg.cn/img_convert/a4e90d22aa420a30736b44be409aced3.png)