Python 机器学习 基础 之 【实战案例】新闻内容分类实战
目录
Python 机器学习 基础 之 【实战案例】新闻内容分类实战
2、使用 jieba 分词器进行分词,使用 Pandas 创建DataFrame
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、新闻内容分类实战
接下来的实战案例将基于一个公开的新闻数据集,我们首先对这些新闻内容进行了细致的分词处理和数据清洗,以确保数据的质量和准确性。分词是文本处理中的关键步骤,它有助于将连续的文本信息分解成可理解的单元,从而为后续的分析打下基础。而数据清洗则是去除无效、错误或无关的数据,保证分析结果的可靠性。
接下来,我们构建了一个基于这些经过预处理的新闻文本的语料库。语料库的建立是自然语言处理中的一个重要环节,它为建模和分析提供了丰富的原始材料。通过对语料库的深入分析和挖掘,我们可以捕捉到新闻文本中的关键信息和模式。
在语料库的基础上,我们进一步进行了模型的构建。我们的目标是通过机器学习技术,训练已有的语料库文本数据,从而得到一个高效的分类模型。这个模型能够识别和分类新闻内容,为新闻数据集中的不同的新闻类别提供准确的标签。
这种新闻分类技术在现实世界中有着广泛的应用场景。
- 首先,在新闻网站中,自动分类功能可以帮助用户快速找到感兴趣的新闻类别,提高用户体验。
- 其次,在电子邮件服务中,垃圾邮件检测功能可以有效地过滤掉不想要的邮件,保护用户的邮箱不被无关信息充斥。
- 此外,非法信息过滤功能则可以用于监控和阻止不当内容的传播,维护网络环境的安全和健康。
该案例不仅在理论上具有探索性,而且在实际应用中也展现了其重要价值。通过构建和优化新闻分类模型,我们不仅能够提高新闻处理的自动化水平,还能够在多个领域中发挥积极的作用,推动信息技术的发展和社会的进步,加油。
三、数据准备
在进行新闻数据获取的过程中,我们可以利用网络爬虫技术来自动地从互联网上收集新闻信息。网络爬虫是一种能够自动浏览网页并提取所需数据的程序,它可以帮助我们高效地从新闻网站中抓取信息。以下是对新闻数据获取过程的丰富描述:
爬虫设计:首先,我们需要设计一个高效的爬虫程序,它能够根据预设的规则访问新闻网站,识别新闻内容,并遵循网站的robots.txt文件,尊重网站的爬取政策。
数据提取:爬虫将遍历目标新闻网站,识别并提取新闻标题、正文、发布时间、作者等关键信息。这些信息是构建语料库的基础,也是后续分析和分类的关键数据。
格式统一:为了便于后续处理和分析,我们需要将爬取的数据统一成一种格式。通常,这涉及到将HTML、XML等网页格式的数据转换为结构化的文本数据,如JSON或CSV格式。
本地存储:清洗后的数据将以一定的格式保存到本地存储设备中。这可以是数据库、文件系统或云存储服务,具体取决于数据量的大小和未来的使用需求。
通过上述步骤,我们不仅能够高效地获取新闻数据,还能够确保数据的质量和可用性,为后续的新闻内容分析和分类工作奠定坚实的基础。
爬虫数据获取不是本节的重点,大家可以在源码中直接使用 data/news.txt 数据进行练习,数据预览如下:
四、分词与清洗工作
1、读取数据
# 导入pandas库,并为其设置别名pd,这是一个用于数据分析的库。
import pandas as pd
# 导入warnings库,用于处理警告信息。
import warnings
# 使用warnings.filterwarnings("ignore")来忽略执行代码时产生的警告信息。
warnings.filterwarnings("ignore")
# 使用pandas的read_table函数读取本地路径./data/news.txt中的文本数据,
# 指定列名分别为'category', 'theme', 'URL', 'content',并且指定文件编码为'utf-8'。
df_news = pd.read_table('./data/news.txt', names=['category', 'theme', 'URL', 'content'], encoding='utf-8')
# 使用dropna()函数去除DataFrame中的空值行,以确保数据的完整性。
df_news = df_news.dropna()
# 使用head()函数显示DataFrame的前几行数据,通常用于快速查看数据的前5行。
df_news.head()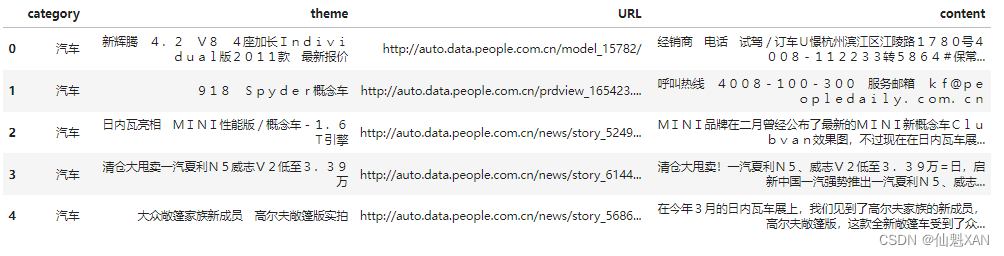
2、使用 jieba 分词器进行分词,使用 Pandas 创建DataFrame
2.1、将数据中的content(即新闻内容)列取出来,然后转换为list格式。取第256条数据进行查看,代码如下:
# 从DataFrame df_news中获取名为'content'的列,这个列包含新闻内容。
# 使用.values将该列转换为NumPy数组。
# 使用.tolist()将NumPy数组转换为Python列表。
content = df_news.content.values.tolist()
# 打印列表中索引为1024的元素,假设列表索引是从0开始的,这将打印第1025条新闻的内容。
# 请注意,如果列表中没有256个元素,这将引发IndexError。
print(content[256])
2.2、接下来进行分词,指定一个content_S列表,用于存储分词后的结果。对每一行进行遍历,使用jieba分词器内置的模块进行分词,去除换行符。把第1024条数据进行分词,代码如下:
# 导入jieba库,这是一个中文文本分词库,用于将中文文本分割成单独的词语。
import jieba
# 初始化一个空列表,用于存储分词后的结果。
content_S = []
# 遍历content列表中的每一条新闻内容。
for line in content:
# 使用jieba.lcut()函数对当前行的新闻内容进行分词,得到一个词语列表。
current_segment = jieba.lcut(line)
# 检查当前分词结果的长度是否大于1,并且确保分词结果不是由换行符组成的空字符串。
# '\r\n'是Windows系统中的换行符,这里用于过滤掉只包含换行符的无效分词结果。
if len(current_segment) > 1 and current_segment != '\r\n':
# 如果条件满足,则将当前行的分词结果添加到content_S列表中。
content_S.append(current_segment)
# 尝试访问content_S列表中索引为256的元素,这通常对应于第257个分词结果。
# 请注意,如果列表中没有256个元素,这将引发IndexError。
content_S[256]
2.3 、在分词完成之后,使用Pandas创建一个DataFrame,将字段名content_S作为key,将列表中的内容作为value进行查看,代码如下:
# 创建一个字典,其中包含一个键'content_S',其值是之前分词后得到的列表content_S。
# 这个列表现在将被转换为DataFrame中的一列。
df_content = pd.DataFrame({'content_S': content_S})
# 使用head()函数显示新创建的DataFrame df_content的前几行数据。
# 这通常用于快速查看DataFrame的前5行,以确认数据加载和结构正确无误。
df_content.head()
3、数据清洗
3.1、导入停用词表(tools/stopwords.txt),再进行简单查看停用词数据,代码如下:
# 使用pandas库的read_csv函数读取名为"tools/stopwords.txt"的文件,该文件包含停用词。
# index_col=False表示不将任何列设置为DataFrame的索引。
# sep="\t"指定了制表符(\t)作为字段分隔符。
# quoting=3用于指定引用字符的样式,3代表只引用那些字段中包含特殊字符的字段。
# names=['stopword']为读取的数据指定列名'stopword'。
# encoding='utf-8'指定文件的编码格式为UTF-8。
stopwords = pd.read_csv("tools/stopwords.txt", index_col=False, sep="\t", quoting=3, names=['stopword'], encoding='utf-8')
# 使用head(15)函数显示DataFrame 'stopwords'的前15行数据。
# 这通常用于快速查看停用词列表的前15个条目,以确认数据加载和格式正确。
stopwords.head(15)
3.2、如果分完词后的词出现在了停用词表当中,可以过滤一下,并将所有处理完的词进行统计,用于之后的可视化展示。因为需要进行遍历,所以执行需要一定的时间(由语料库的大小决定)。代码如下:
# 定义一个函数drop_stopwords,用于从文本内容中移除停用词。
# 参数contents是包含多个文本行的列表,stopwords是包含停用词的列表。
def drop_stopwords(contents, stopwords):
# 初始化一个空列表,用于存储清理后的文本内容。
content_clean = []
# 初始化一个空列表,用于存储所有非停用词。
all_words = []
# 遍历contents列表中的每一行文本。
for line in contents:
# 初始化一个空列表,用于存储当前行清理后的词语。
line_clean = []
# 遍历当前行的每一个词语。
for word in line:
# 如果词语是停用词,则跳过不处理。
if word in stopwords:
continue
# 如果词语不是停用词,则添加到当前行的清理列表中。
line_clean.append(word)
# 将当前词语转换为字符串并添加到所有非停用词的列表中。
all_words.append(str(word))
# 将当前行的清理列表添加到总的清理内容列表中。
content_clean.append(line_clean)
# 返回清理后的文本内容列表和所有非停用词的列表。
return content_clean, all_words
# 从DataFrame df_content中获取'content_S'列的值,将其转换为列表。
contents = df_content.content_S.values.tolist()
# 从DataFrame stopwords中获取'stopword'列的值,将其转换为列表。
stopwords = stopwords.stopword.values.tolist()
# 调用drop_stopwords函数,传入contents和stopwords,获取清理后的文本内容和所有非停用词。
contents_clean, all_words = drop_stopwords(contents, stopwords)
# 创建一个新的DataFrame,其中包含清理后的文本内容,列名为'contents_clean'。
df_content = pd.DataFrame({'contents_clean': contents_clean})
# 显示新创建的DataFrame的前几行,以确认数据已经被正确清理和转换。
df_content.head()
3.3、词频统计,有助于可视化输出。同时,我们通过Pandas的内置函数,按词频进行排序。代码如下:
# 导入numpy库,并为其设置别名np,这是一个用于科学计算的库。
import numpy as np
# 假设all_words是一个包含所有非停用词的列表,这里我们打印出第一个元素,用于调试或查看数据。
all_words[0]
# 创建一个DataFrame,其中包含一个名为'all_words'的列,其值为之前得到的all_words列表。
df_all_words = pd.DataFrame({'all_words': all_words})
# 使用groupby函数根据'all_words'列的值对DataFrame进行分组,并计算每个分组的大小。
# 这里使用agg函数和np.size来计算每个单词的频率,np.size返回数组中元素的总数。
words_count = df_all_words.groupby('all_words')['all_words'].agg(count=np.size)
# 重置索引,将分组键'all_words'列变为普通列,并保留计数结果。
# 然后,根据'count'列的值对结果进行降序排序,ascending=False表示从大到小排序。
words_count = words_count.reset_index().sort_values(by="count", ascending=False)
# 显示排序后的单词频率DataFrame的前几行,通常用于查看最常见的单词。
words_count.head()
3.4 下面进行词云的可视化展示。先通过pip安装wordcloud库,词云GitHub链接为https://github.com/amueller/word_cloud。我们选择前100条数据进行展示,代码如下:
# 从wordcloud库中导入WordCloud类,用于生成词云。
from wordcloud import WordCloud
# 导入matplotlib.pyplot模块,并为其设置别名plt,这是一个用于绘图的库。
import matplotlib.pyplot as plt
# %matplotlib inline 是一个IPython魔术命令,用于在Jupyter Notebook中内嵌绘图。
# 当使用Jupyter Notebook时,这个命令确保绘图显示在输出单元格中。
%matplotlib inline
# 导入matplotlib库,用于进一步定制绘图设置。
import matplotlib
# 设置matplotlib的全局配置选项,指定生成的图形的默认大小为宽10.0英寸,高5.0英寸。
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
# 创建一个WordCloud对象,设置字体路径、背景颜色和最大字体大小。
# font_path指定了字体文件的路径,确保中文能够正确显示。
# background_color设置了词云的背景颜色。
# max_font_size设置了词云中文字的最大字号。
wordcloud = WordCloud(font_path="./data/simhei.ttf", background_color="white", max_font_size=80)
# 创建一个字典word_frequence,包含出现频率最高的前100个单词及其频率。
# 这里假设words_count是一个包含单词频率信息的DataFrame,head(100)用于获取前100行数据。
word_frequence = {x[0]: x[1] for x in words_count.head(100).values}
# 使用WordCloud对象的fit_words方法,传入word_frequence字典,生成词云。
wordcloud = wordcloud.fit_words(word_frequence)
# 使用plt.imshow()函数显示生成的词云图像。
plt.imshow(wordcloud)
# 使用plt.savefig()函数将生成的词云图像保存为文件。
# 'Images/01Main-01.png'是文件的保存路径和名称。
# bbox_inches='tight'参数确保所有的图形内容都被包含在保存的图像中,没有被裁剪。
plt.savefig('Images/01Main-01.png', bbox_inches='tight')
# 使用plt.show()函数显示图像。如果在一个脚本或Jupyter Notebook中运行,这将触发图像的显示。
plt.show()
3.5、下面对某段内容提取关键词测试。通过Jieba分词器内置的函数进行关键字提取,topK对应的是“返回关键字”的个数,代码如下:
# 导入jieba库中的analyse模块,该模块提供文本分析功能,如关键词提取。
import jieba.analyse
# 设置索引值,用于选择DataFrame中特定行的数据。
index = 256
# 打印出df_news DataFrame中'content'列的第256行数据。
# 假设DataFrame的索引是从0开始的,这将打印第257条新闻的内容。
print(df_news['content'][index])
# 从之前分词得到的列表content_S中选取第256个元素,即第257条新闻的分词结果。
# 使用"".join()将分词结果连接成一个字符串。
content_S_str = "".join(content_S[index])
# 打印使用jieba.analyse.extract_tags函数提取的关键词标签。
# extract_tags函数用于从文本中提取关键词,topK=5表示提取前5个关键词。
# withWeight=False表示不按照词权重排序。
print(" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))经销商 电话 试驾/订车;剖东路725号(总店)/天河区龙洞广汕一路128号/广州增城市荔湾街增城大道126号4008-112233转9987#保埃98万9愣省广州市海珠区广州大道南1601号华南汽贸广场28-36档4008-112233转9979#保埃98万I钲谑辛城特发龙飞工业园D2栋一层#矗埃埃福112233转9819#保埃98万;坪哟蟮佬鲁导熘行亩悦嬖通汽车家园内#矗埃埃福112233转3568#保埃98万:颖笔⌒咸ㄊ泄守敬大道西段汽车物流园区#保埃96万I钲谑懈L锴深南大道6068号联合华鹏汽车贸易广场C1-2#保埃98万D诿晒藕袈妆炊市海拉尔区加格达奇路8号10.98万U闹菔辛文区迎宾大道586号10.98万a橹菔腥衢路925-949号10.98万9愣省中山市南区城南9号(南区汽车站斜对面105国道旁)#保埃98万@萨市金珠西路158号10.98万G嗟菏惺斜鼻福州北路129号甲#保埃98万L┌彩嗅吩狼泰东路国际汽车城#保埃98万VV菔谢ㄔ奥繁倍瘟林#保埃98万@贾菔刑焖北路省政协正对面(团结路)良志嘉年华北侧#保埃98万D暇┦谢ㄔ奥罚保泛牛保埃98万N靼彩形囱肭西部国际车城4-003号10.98万I挛魇∮芰质杏苎羟上郡路132号10.98万Lㄖ菔形铝胧泻嵘酵泛炻痰瓶邶#保埃98万T颇鲜±ッ魇形魃角前卫西路1号(广福路省公安厅斜对面)#保埃98万D波市江北区环城北路东段551号10.98万1踔菔胁澈N迓坊坪邮二路路口东侧#保埃98万9阒菔刑旌忧黄埔大道西668号赛马场三鹰汽车城北区A12#保埃98万S口市盼盼路智泉街东25-甲1甲2号10.98万N尬市北塘区江海西路南侧全丰路口西(华东汽车城对面)#保埃98万V曛奘泻炱毂甭罚ǎ牵常玻埃168号10.98万I轿魇√原市平阳路444号10.98万I虾J衅中枪路180号10.98万L粕绞新纺锨汽车文化展示园区内#保埃98万A岩市龙门海西物流园物流大道308号10.98万P咸ㄊ泄守敬大道西段汽车物流园区#保埃98万I蜓羰刑西区北二西路19号10.98万D诿晒藕艉秃铺厥行鲁乔北垣东街272号10.98万O妹攀泻里区枋钟路1919号10.98万<媚高新区东外环路东崇文大道南东艺工业园#保埃98万=苏省南通市城港路136号10.98万0睬焓杏⒌吕国际汽车城3期4栋1号10.98万9愣省佛山市南海区桂城海八路(麦当劳侧)#保埃98万N髂市八一中路17-1号10.98万9愣省东莞市塘厦镇林村国际汽车城#保埃98万3啥寄先环三段内侧科创路16号10.98万:颖笔”6ㄊ心鲜星南二环路1399号10.98万:戏适邪河区纬二路12号10.98万I蕉省济南市经十西路239号10.98万9阍市西滨大道商展中心#保埃98万=门市江沙路联合村路口#保埃98万@萨市罗布林卡路23号10.98万VV菔斜被仿分卸危矗负牛保埃98万8费羰序V萸阜南路四里桥666号10.98万9愣省肇庆市端州一路(大冲广场东侧)#矗埃埃福112233转9935#保埃98万I钲谑懈L锴侨城东路鹏城宝汽车城B-004号10.98万8仕嗍【迫市飞天路642号10.98万I钲谑懈L锴深南大道6068号联合华鹏汽车贸易广场C1-2#保埃98万9愣省佛山市顺德区广珠公路伦教路段#保埃98万 保埃 大道 愣省 汽车城 西路
提取的关键字共5个,为保埃、大道、愣省、汽车城、西路。
五、模型建立
首先导入了所需的库,包括numpy、pandas、CountVectorizer和LatentDirichletAllocation。
然后,创建了一个CountVectorizer实例用于文本的向量化处理,并将contents_clean列表中的每个文档转换为字符串格式。之后,使用fit_transform方法将文本数据转换为词袋模型,得到一个稀疏矩阵X。
接着,设置LDA模型中的主题数,并创建LDA模型实例,然后使用fit方法训练模型。
之后,定义了一个函数print_top_words,用于打印每个主题的前n_top_words个关键字及其权重。
最后,调用这个函数并传入LDA模型、特征名称和关键字数量,以打印每个主题的关键字权重信息。
代码如下:
# 导入numpy库,用于数值计算。
import numpy as np
# 导入pandas库,用于数据分析和操作。
import pandas as pd
# 从scikit-learn库中导入CountVectorizer,用于将文本数据转换为词袋模型。
from sklearn.feature_extraction.text import CountVectorizer
# 从scikit-learn库中导入LatentDirichletAllocation,用于主题模型的LDA算法。
from sklearn.decomposition import LatentDirichletAllocation
# 创建一个CountVectorizer实例,用于文本数据的向量化处理。
vectorizer = CountVectorizer()
# 确保contents_clean列表中的每个文档都是字符串格式。
# 如果文档是列表类型(即分词后的结果),则使用' '.join()将其转换为字符串;否则直接使用文档。
contents_clean = [' '.join(doc) if isinstance(doc, list) else doc for doc in contents_clean]
# 使用CountVectorizer实例将文本数据转换为词袋模型,得到一个稀疏矩阵X。
X = vectorizer.fit_transform(contents_clean)
# 设置LDA模型中的主题数为20。
num_topics = 20
# 创建并训练LDA模型,指定主题数、随机状态和迭代次数。
lda = LatentDirichletAllocation(n_components=num_topics, random_state=0, max_iter=10)
lda.fit(X)
# 获取CountVectorizer实例中的词汇表,即特征名称。
feature_names = vectorizer.get_feature_names_out()
# 定义一个函数print_top_words,用于打印每个主题的前n_top_words个关键字及其权重。
def print_top_words(model, feature_names, n_top_words):
# 遍历模型中的每个主题。
for topic_idx, topic in enumerate(model.components_):
print(f"Topic #{topic_idx}:")
# 获取每个主题的关键字索引,按权重从高到低排序。
top_features_ind = topic.argsort()[:-n_top_words - 1:-1]
# 根据索引获取每个主题的关键字。
top_features = [feature_names[i] for i in top_features_ind]
# 获取每个关键字的权重。
top_weights = topic[top_features_ind]
# 格式化输出每个关键字及其权重。
topic_representation = " + ".join(f"{weight:.3f}*\"{word}\"" for word, weight in zip(top_features, top_weights))
print(topic_representation)
print()
# 调用print_top_words函数,打印每个主题的前5个关键字及其权重。
n_top_words = 5
print_top_words(lda, feature_names, n_top_words)
六、分类任务
1、使用贝叶斯分类器完成新闻数据的分类任务。首先打印新闻的类别,代码如下:
# 创建一个新的DataFrame df_train,包含两列:'contents_clean'和'label'。
# 'contents_clean'列包含清理后的文本内容,'label'列包含原始新闻数据集df_news中的'category'列数据,即新闻的类别标签。
df_train = pd.DataFrame({'contents_clean': contents_clean, 'label': df_news['category']})
# 使用unique()函数获取'label'列中所有独特的值。
# 这通常用于查看数据集中的类别标签是否齐全,以及每个类别的值是什么。
df_train.label.unique()array(['汽车', '财经', '科技', '健康', '体育', '教育', '文化', '军事', '娱乐', '时尚'],
dtype=object)
首先创建了一个名为df_train的DataFrame,它包含两个字段:contents_clean和label。contents_clean字段预期包含经过预处理和清理的文本数据,而label字段则包含从df_news DataFrame中提取的新闻类别标签。
接着,代码使用unique()函数从df_train的label列中提取所有不同的(唯一的)值。这个函数返回一个数组,包含label列中所有不重复的条目。这有助于了解数据集中包含哪些不同的类别标签,以及每个类别的值是什么。这对于数据探索和后续的数据分析工作非常重要。
2、将对应的类别名通过Pandas映射为(key, value)的形式,例如("科技", 3)。再传入DataFrame中进行替换。代码如下:
# 创建一个字典label_mapping,用于将新闻类别的名称映射为数字标签。
# 例如,"汽车"类别映射为数字1,"财经"类别映射为数字2,依此类推。
label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
# 使用map函数将df_train中的'label'列的值替换为映射后的数字标签。
# 这里,map函数会根据label_mapping字典,将'label'列中的每个类别名称替换为对应的数字。
df_train['label'] = df_train['label'].map(label_mapping)
# 使用head()函数显示df_train DataFrame的前几行,以确认标签替换操作已经成功执行。
df_train.head()
首先定义了一个名为label_mapping的字典,用于将新闻的分类名称(如"汽车"、"财经"等)映射为一个数字标签。这是一种常见的做法,特别是在机器学习中,因为算法通常需要数值输入。
接着,代码使用map函数将df_train DataFrame中'label'列的值替换为label_mapping字典中对应的数字标签。这样,每个新闻类别的名称就被转换为了一个数值,这有助于后续的数据处理和模型训练。
最后,使用head()函数显示df_train DataFrame的前几行,这样可以快速检查标签替换是否正确执行,以及DataFrame的当前状态。
3、将数据分为训练集和测试集,可以自行指定训练集和测试集的划分比例,也可以按照默认比例执行。代码如下:
# 从scikit-learn库中的model_selection模块导入train_test_split函数。
# train_test_split函数用于将数据集分割为训练集和测试集。
from sklearn.model_selection import train_test_split
# 使用train_test_split函数分割数据。
# df_train['contents_clean'].values提供了用于训练模型的文本数据的特征值。
# df_train['label'].values提供了对应的标签值。
# random_state=1设定了一个随机状态,确保每次分割数据时结果相同,以便于复现实验结果。
x_train, x_test, y_train, y_test = train_test_split(
df_train['contents_clean'].values, # 特征:清理后的文本内容
df_train['label'].values, # 标签:新闻类别的数字标签
random_state=1 # 随机状态,用于确保结果的可复现性
)4、由于向量构造器的需要,我们将之前的list of list类型的数据转换为string类型,并进行存储,代码如下:
# 确保 x_train 是一个包含字符串的列表
# 此注释说明了接下来的代码块的目的是确保x_train中的每个元素都是字符串格式。
words = []
for line_index in range(len(x_train)):
try:
# 遍历x_train中的每个元素,通过索引line_index定位当前元素。
# 将每个文档的单词列表(如果存在)转换为由空格分隔的字符串。
# 如果x_train中的元素已经是字符串,则直接添加到words列表中。
if isinstance(x_train[line_index], list):
words.append(' '.join(x_train[line_index]))
else:
words.append(x_train[line_index])
except Exception as e:
# 如果在处理过程中发生任何异常,打印出错误信息和发生错误的行索引。
print(f"Error at line {line_index}: {e}")
# 过滤words列表,确保所有文档都不为空。
# 使用列表推导式创建一个新的words列表,只包含非空字符串的文档。
words = [doc for doc in words if doc.strip() != '']
# 调试信息:检查处理后的数据
# 打印出处理后words列表中的第一个文档,用于调试目的。
print(f"First document: {words[0]}")
# 打印出处理后words列表中的文档总数,用于了解数据规模。
print(f"Number of documents: {len(words)}")First document: 中新网 上海 月 日电 记者 于俊 今年 父亲节 人们 网络 吃 一顿 电影 快餐 微 电影 爸 对不起 我爱你 定于 本月 日 父亲节 当天 各大 视频 网站 首映 葜 谱 鞣 剑 保慈 障蚣 钦 呓 樯 埽 ⒌ 缬 埃 ǎ 停 椋 悖 颍 铩 妫 椋 欤 恚 称 微型 电影 专门 运用 新 媒体 平台 播放 移动 状态 短时 休闲 状态 下 观看 完整 策划 系统 制作 体系 支持 显示 较完整 故事情节 电影 具有 微 超短 时 放映 秒 - 秒 微 周期 制作 - 天 数周 微 规模 投资 人民币 几千 数万元 / 每部 特点 内容 融合 幽默 搞怪 时尚 潮流 人文 言情 公益 教育 商业 定制 主题 单独 成篇 系列 成剧 唇 开播 微 电影 爸 对不起 我爱你 讲述 一对 父子 观念 缺少 沟通 导致 关系 父亲 传统 固执 人 钟情 传统 生活 方式 儿子 新派 音乐 达 人 习惯 晚出 早 生活 性格 张扬 叛逆 两种 截然不同 生活 方式 理念 差异 一场 父子 间 战斗 拉开序幕 子 失手 打破 父亲 最 心爱 物品 父亲 赶出 家门 剧情 演绎 父亲节 妹妹 帮助 哥哥 化解 父亲 这场 矛盾 映逋坏 嚼 斫 狻 ⒍ 粤 ⒌ 桨容 争执 退让 传统 现代 尴尬 父子 尴尬 情 男人 表达 心中 那份 感恩 一杯 滤挂 咖啡 父亲节 变得 温馨 镁 缬 缮 虾 N 逄 煳 幕 传播 迪欧 咖啡 联合 出品 出品人 希望 观摩 扪心自问 每年 父亲节 一次 父亲 了解 记得 父亲 生日 哪一天 知道 父亲 最 爱喝 跨出 家门 那一刻 是否 感觉 一颗 颤动 心 操劳 天下 儿女 父亲节 大声 喊出 父亲 家人 爱 完 Number of documents: 3750
5、使用sklearn的特征选择模块与贝叶斯模块,通过向量构造器生成向量,代码如下:
# 确保文档非空
# 如果words列表为空,抛出ValueError异常,提示处理后的文档为空。
# 这通常意味着输入数据存在问题,需要检查。
if not words:
raise ValueError("The processed documents are empty. Please check your input data.")
# 创建 CountVectorizer 实例
# CountVectorizer用于将文本数据转换为词袋模型,即文本数据的数值表示。
# analyzer='word'表示对每个单词进行分词。
# max_features=4000表示选择最常见的4000个特征(单词)。
# lowercase=False表示不将所有文本转换为小写,保留原始大小写。
# stop_words=None表示不移除停用词。
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase=False, stop_words=None)
# 训练词袋模型
# 尝试使用fit_transform方法从words列表中学习词汇,并转换数据。
try:
X = vec.fit_transform(words)
except ValueError as e:
# 如果发生ValueError,打印错误信息,并提示检查输入数据。
# 然后重新抛出异常以供进一步处理。
print("ValueError:", e)
print("Please check your input data for issues.")
raise
# 打印转换后的数据矩阵X的形状,即样本数和特征数。
print(f"Shape of X: {X.shape}")
# 打印前10个特征名称,这些是词汇表中的单词。
# 这有助于了解模型所使用的特征。
print(f"Feature names: {vec.get_feature_names_out()[:10]}")Shape of X: (3750, 4000) Feature names: ['一一' '一下' '一下子' '一个' '一个月' '一举' '一事' '一些' '一人' '一代']
# 从scikit-learn库中的naive_bayes模块导入MultinomialNB类。
# MultinomialNB是用于处理多项式分布数据的朴素贝叶斯分类器,适用于文本分类。
from sklearn.naive_bayes import MultinomialNB
# 创建MultinomialNB类的实例,即初始化朴素贝叶斯分类器。
classifier = MultinomialNB()
# 使用fit方法训练朴素贝叶斯分类器。
# vec.transform(words)将words列表中的文本数据转换为词袋模型的数值表示。
# y_train是对应的训练标签。
# 这里,分类器从转换后的文本数据和对应的标签中学习如何预测新数据的标签。
classifier.fit(vec.transform(words), y_train)6、对测试集进行测试,按照与训练集一样的步骤进行处理,代码如下:
# 构建测试集的单词列表
# 初始化一个空列表test_words,用于存储测试集文档转换后的字符串。
test_words = []
for doc in x_test:
try:
# 遍历测试集x_test中的每个文档。
# 如果文档是列表形式,则使用' '.join()将其元素(单词)连接成一个字符串,并添加到test_words列表中。
test_words.append(' '.join(doc))
except Exception as e:
# 如果在处理文档时发生异常,打印出错误信息。
print(f"Error processing document: {e}")
# 打印测试集的第一个文档,用于调试和检查文档格式。
print("First document in test set:", test_words[0])
# 确保 test_words 非空
# 如果test_words为空,抛出ValueError异常,提示测试文档处理后为空。
# 这通常意味着输入数据存在问题,需要检查。
if not test_words:
raise ValueError("The processed test documents are empty. Please check your input data.")
# 使用分类器进行预测并评估性能
# 使用之前训练好的分类器classifier对测试集的单词列表test_words进行转换和预测。
# vec.transform(test_words)将test_words中的文本数据转换为词袋模型的数值表示。
# score方法计算分类器在测试集上的准确率得分,并将其存储在变量score中。
# 打印分类器在测试集上的得分,用于评估模型性能。
score = classifier.score(vec.transform(test_words), y_test)
print("Classifier score on test set:", score)First document in test set: 国 家 公 务 员 考 试 申 论 应 用 文 类 试 题 实 质 一 道 集 概 括 分 析 提 出 解 决 问 题 一 体 综 合 性 试 题 说 一 道 客 观 具 体 凝 练 小 申 发 论 述 文 章 题 目 分 析 历 年 国 考 申 论 真 题 看 出 公 文 类 试 题 类 型 多 样 包 括 公 文 类 事 务 性 文 书 类 题 材 丰 富 从 题 干 作 答 要 求 主 要 集 中 材 料 内 容 整 合 分 析 无 需 太 创 造 性 发 挥 纵 观 历 年 申 论 真 题 作 答 要 求 应 用 文 类 试 题 文 种 格 式 作 出 特 别 要 求 重 在 内 容 考 查 行 文 格 式 考 生 平 常 心 面 对 应 用 文 类 试 题 准 确 把 握 作 答 要 求 深 入 领 会 内 在 含 义 全 面 把 握 题 材 主 旨 材 料 结 构 完 全 轻 松 应 对 应 用 文 类 试 题 R 弧 ⒆ 钒 盐 展 文 写 作 原 则 T 材 料 中 来 应 用 文 类 试 题 主 要 材 料 总 体 把 握 客 观 总 结 考 生 严 格 坚 持 材 料 中 来 材 料 中 全 面 把 握 材 料 反 映 问 题 准 确 理 解 题 材 反 映 主 旨 T 政 府 角 度 作 答 应 用 文 类 试 题 更 应 注 重 政 府 角 度 坚 持 所 有 观 点 政 府 角 度 出 发 原 则 表 述 观 点 提 出 解 决 之 策 考 生 作 答 时 站 政 府 人 员 角 度 看 待 问 题 提 出 问 题 解 决 问 题 T 掌 握 文 体 结 构 形 式 考 查 重 点 文 体 结 构 大 部 分 掌 握 评 分 时 关 键 点 解 答 方 法 薄 ⒆ ス 丶 词 明 方 向 作 答 题 目 题 干 作 答 要 求 明 确 作 答 方 向 确 定 作 答 角 度 关 键 向 导 考 生 仔 细 阅 读 题 干 作 答 要 求 抓 住 关 键 词 明 确 作 答 方 向 相 关 要 点 整 理 作 答 思 路 年 国 考 地 市 级 真 题 为 例 潦 惺 姓 府 准 备 大 力 宣 传 推 进 近 海 水 域 污 染 整 治 工 作 请 结 合 给 定 资 料 市 政 府 工 作 人 员 身 份 草 拟 一 份 宣 传 纲 要 分 R 求 保 对 宣 传 内 容 要 点 进 行 提 纲 挈 领 陈 述 玻 体 现 政 府 精 神 使 全 市 各 界 关 心 支 持 污 染 整 治 工 作 通 俗 易 懂 超 过 字 肮 丶 词 近 海 水 域 污 染 整 治 工 作 市 政 府 工 作 人 员 身 份 宣 传 纲 要 提 纲 挈 领 陈 述 体 现 政 府 精 神 使 全 市 各 界 关 心 支 持 污 染 整 治 工 作 通 俗 易 懂 提 示 归 结 作 答 要 点 包 括 污 染 情 况 问 题 原 因 解 决 对 策 作 答 思 路 情 况 - 问 题 - 原 因 - 对 策 - 意 义 逻 辑 顺 序 安 排 文 章 结 构 病 ⒋ 缶 殖 龇 ⅲ 明 结 构 解 答 应 用 文 类 试 题 考 生 材 料 整 体 出 发 大 局 出 发 高 屋 建 瓴 把 握 材 料 主 题 思 想 事 件 起 因 存 在 问 题 解 决 对 策 一 一 明 确 阅 读 文 章 就 要 心 里 构 建 好 文 章 结 构 直 至 最 后 快 速 解 答 场 ⒗ 硭 乘 悸 罚 明 逻 辑 应 用 文 类 试 题 要 求 严 密 逻 辑 思 维 情 况 - 问 题 - 原 因 - 对 策 - 意 义 考 生 作 答 之 前 就 要 先 弄 清 楚 解 答 思 路 统 筹 安 排 脉 络 清 晰 逻 辑 合 理 表 达 内 容 表 述 础 把 握 要 求 明 详 略 考 生 仔 细 阅 读 分 析 揣 摩 应 用 文 类 试 题 内 容 要 求 答 题 时 要 详 略 得 当 主 次 分 明 安 排 部 分 内 容 增 加 文 章 层 次 感 使 阅 卷 老 师 阅 卷 时 能 明 白 清 晰 一 目 了 然 玻 埃 保 蹦 旯 考 年 考 试 申 论 试 卷 分 为 省 级 地 市 级 两 套 试 卷 能 力 要 求 大 有 省 级 申 论 试 题 要 求 考 生 宏 观 角 度 看 问 题 注 重 问 题 深 度 广 度 要 求 考 生 深 谋 远 虑 地 市 级 试 题 要 求 考 生 微 观 视 角 观 察 问 题 侧 重 考 查 具 体 解 决 实 际 问 题 能 力 要 求 考 生 贯 彻 执 行 具 体 作 答 时 区 别 对 待 Classifier score on test set: 0.0864
7、使用sklearn模块下的TF-IDF进行向量的构造,训练完成之后,用测试集进行验证,代码如下:
# 从scikit-learn库中的feature_extraction.text模块导入TfidfVectorizer类。
# TfidfVectorizer用于将文本数据转换为TF-IDF特征。
from sklearn.feature_extraction.text import TfidfVectorizer
# 创建TfidfVectorizer实例,用于文本数据的向量化处理。
# analyzer='word'表示按单词进行分词。
# max_features=4000表示限制特征集的大小为4000个词汇。
# lowercase=False表示不对文本进行小写转换,保留原始的大小写。
vectorizer = TfidfVectorizer(analyzer='word', max_features=4000, lowercase=False)
# 使用fit方法训练TfidfVectorizer,从words列表中学习词汇。
# 这一步会构建词汇表,并计算每个单词的词频(TF)。
vectorizer.fit(words)
# 从scikit-learn库中的naive_bayes模块导入MultinomialNB类。
# MultinomialNB是多项式朴素贝叶斯分类器,适用于分类离散数据,如文本数据。
from sklearn.naive_bayes import MultinomialNB
# 创建MultinomialNB实例,初始化朴素贝叶斯分类器。
classifier = MultinomialNB()
# 使用fit方法训练朴素贝叶斯分类器。
# vectorizer.transform(words)将words列表中的文本转换为TF-IDF特征。
# y_train是对应的训练标签。
# 这里,分类器学习如何根据TF-IDF特征预测文本的标签。
classifier.fit(vectorizer.transform(words), y_train)
# 使用分类器对测试集进行预测并计算得分。
# vectorizer.transform(test_words)将测试集的文本转换为TF-IDF特征。
# y_test是测试集的标签。
# score方法计算分类器在测试集上的准确率得分。
classifier.score(vectorizer.transform(test_words), y_test)0.0864
七、编写一段新闻,预测结果,得到返回的新闻标签
首先创建了 inverse_label_mapping 作为 label_mapping 的逆映射。然后,我们对测试新闻文本进行了分词和向量化处理,并使用分类器进行了预测。最后,我们使用 inverse_label_mapping 来查找预测标签对应的类别名称,并打印出来。
请注意,predicted_label[0] 是因为我们的 predict 方法返回的是一个数组,即使我们只预测了一个样本。因此,我们通过索引 [0] 来获取预测标签的值。
# 假设 label_mapping 是之前创建的标签映射字典,如下所示:
# label_mapping = {"汽车": 1, "财经": 2, ...}
# 我们需要创建它的逆映射
inverse_label_mapping = {value: key for key, value in label_mapping.items()}
print(inverse_label_mapping)
# 测试新闻文本
test_news = "6月3日,法国网球公开赛将进入第9比赛日的争夺。男女单打第4轮比赛继续上演,此前被雨水积压的双打赛程,也会紧锣密鼓进行,青少年组的比赛将在这个周一正式开拍。德约科维奇将力争冲击大满贯新纪录,张之臻则会搭档马哈奇向着法网男双16强发起冲击。"
# 使用jieba进行分词
test_news_segmented = " ".join(jieba.cut(test_news))
# 将分词结果转换为TF-IDF特征
test_news_tfidf = vectorizer.transform([test_news_segmented])
# 使用训练好的朴素贝叶斯分类器进行预测
predicted_label = classifier.predict(test_news_tfidf)
# 使用逆映射字典来获取预测的类别名称
predicted_category = inverse_label_mapping.get(predicted_label[0])
# 打印预测的新闻标签
print("预测的新闻标签:", predicted_category){1: '汽车', 2: '财经', 3: '科技', 4: '健康', 5: '体育', 6: '教育', 7: '文化', 8: '军事', 9: '娱乐', 0: '时尚'}
预测的新闻标签: 体育
八、小结
本节深入探讨了基于新闻文本内容的自动分类技术,涵盖了从文本预处理到模型构建、评估的完整工作流程。以下是对本节内容的丰富和扩展:
文本分词与清洗:本节首先介绍了文本分词的重要性,分词是文本分析的第一步,它将连续的文本切分为独立的词语单元。接着,讲解了如何清洗文本数据,包括去除停用词、标点符号和特殊字符,以及如何处理缺失值和重复数据。
文本向量化:在文本清洗的基础上,本节详细阐述了如何将文本转换为机器学习算法可以处理的数值形式。介绍了两种主要的向量化方法:词袋模型(Bag of Words)和TF-IDF模型,包括它们的工作原理和优缺点。
贝叶斯分类模型构建:本节重点讲解了朴素贝叶斯分类器的原理和应用。朴素贝叶斯分类器是一种基于贝叶斯定理的分类方法,适用于大量特征的数据集,如文本数据。本章提供了构建和训练朴素贝叶斯分类器的代码示例。
分类测试与评估:在模型构建之后,本节介绍了如何使用测试集对分类模型进行评估。评估指标包括准确率、召回率和F1分数等,这些指标有助于理解模型的性能。
代码实现:每一部分知识点都配有详细的代码实现,使读者能够通过实践来加深理解。代码示例清晰地展示了文本处理和模型构建的每个步骤。
通过本节的学习,读者不仅能够掌握文本分类的基本流程和关键技术,还能够获得必要的实战经验,为进一步探索文本分析和自然语言处理领域打下坚实的基础。
附录
一、代码地址
github:https://github.com/XANkui/PythonMachineLearningBeginner
二、Pandas创建一个DataFrame 的作用
在 Pandas 中创建一个 DataFrame 是进行数据分析和处理的基础操作。DataFrame 是一种二维的、带有标签的数据结构,类似于数据库中的表格、Excel 表格,或是 R 语言中的数据框。DataFrame 提供了丰富的功能来操作、分析和可视化数据。
DataFrame 的作用
1. 数据存储和展示
DataFrame 是一种直观的数据存储方式,能够以行和列的形式展示数据,并且支持不同类型的数据。
2. 数据清洗和预处理
DataFrame 提供了一系列的数据清洗和预处理功能,例如:
- 处理缺失值:
df.dropna(),df.fillna()- 数据筛选和过滤:
df[df['Age'] > 25]- 数据转换和操作:
df['Age'] = df['Age'] * 23. 数据分析和计算
Pandas 提供了多种数据分析和计算的功能,例如:
- 统计描述:
df.describe()- 数据分组和聚合:
df.groupby('City').mean()- 数据排序:
df.sort_values(by='Age')4. 数据合并和连接
Pandas 提供了多种方式来合并和连接不同的 DataFrame,例如:
- 合并:
pd.merge(df1, df2, on='key')- 连接:
pd.concat([df1, df2], axis=0)5. 数据可视化
虽然 Pandas 本身不是一个可视化工具,但它与其他可视化库(如 Matplotlib 和 Seaborn)集成良好,可以直接利用这些库进行数据可视化:
示例代码
以下是一个完整的示例代码,展示了如何创建 DataFrame 并进行一些基本操作:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 从字典创建 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
# 显示 DataFrame
print("DataFrame:")
print(df)
# 描述统计信息
print("\n描述统计信息:")
print(df.describe())
# 筛选数据
filtered_df = df[df['Age'] > 25]
print("\n筛选后 DataFrame:")
print(filtered_df)
# 处理缺失值
df_with_nan = df.copy()
df_with_nan.loc[2, 'Age'] = np.nan
print("\n含缺失值 DataFrame:")
print(df_with_nan)
print("\n处理缺失值后 DataFrame:")
df_filled = df_with_nan.fillna(df_with_nan['Age'].mean())
print(df_filled)
# 数据分组和聚合,只选择数值列
grouped_df = df.groupby('City')['Age'].mean()
print("\n分组和聚合后 DataFrame:")
print(grouped_df)
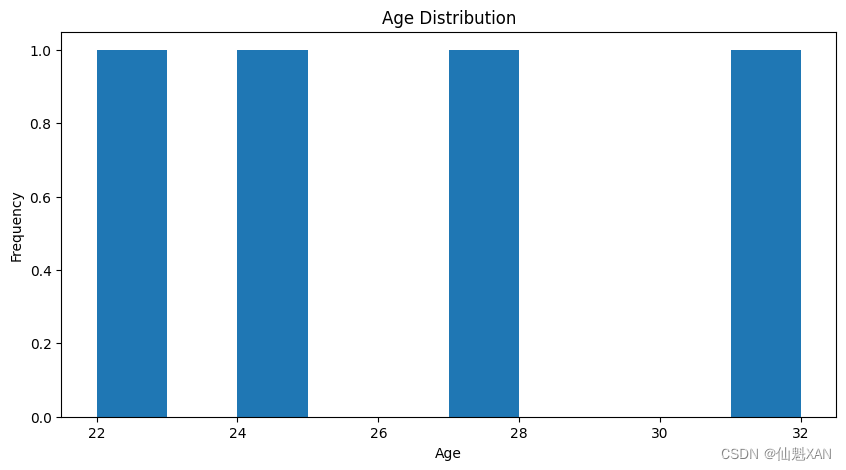
# 数据可视化
df['Age'].plot(kind='hist', title='Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
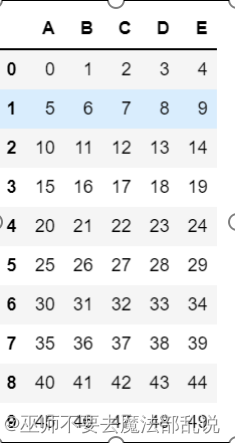
DataFrame:
Name Age City
0 Alice 24 New York
1 Bob 27 Los Angeles
2 Charlie 22 Chicago
3 David 32 Houston
描述统计信息:
Age
count 4.000000
mean 26.250000
std 4.349329
min 22.000000
25% 23.500000
50% 25.500000
75% 28.250000
max 32.000000
筛选后 DataFrame:
Name Age City
1 Bob 27 Los Angeles
3 David 32 Houston
含缺失值 DataFrame:
Name Age City
0 Alice 24.0 New York
1 Bob 27.0 Los Angeles
2 Charlie NaN Chicago
3 David 32.0 Houston
处理缺失值后 DataFrame:
Name Age City
0 Alice 24.000000 New York
1 Bob 27.000000 Los Angeles
2 Charlie 27.666667 Chicago
3 David 32.000000 Houston
分组和聚合后 DataFrame:
City
Chicago 22.0
Houston 32.0
Los Angeles 27.0
New York 24.0
Name: Age, dtype: float64
三、语料库进行映射,形成词袋模型 的作用
在自然语言处理(NLP)和机器学习中,语料库进行映射,形成词袋模型(Bag of Words, BoW)是一个常见的步骤。这个过程的作用和具体实现如下:
1、作用
文本向量化:
- 词袋模型将文本数据转换为数值形式(向量),使其能够用于机器学习算法。文本数据本质上是非结构化的,但机器学习算法通常要求输入的数据是结构化且数值化的。
特征提取:
- 词袋模型提取文本中的词汇,并将其作为特征来表示每个文档。每个文档被表示为一个固定长度的向量,其中每个位置表示一个词汇在文档中出现的次数或存在与否。
简化处理:
- 词袋模型忽略了词的顺序和语法,仅关注词汇的频率。这种简化使得处理和计算更加高效,同时也能够在某些情况下获得较好的模型性能。
2、示例代码
以下是如何使用 Python 和 sklearn 来实现词袋模型:
from sklearn.feature_extraction.text import CountVectorizer
# 假设 contents_clean 是一个包含预处理后文本数据的列表
contents_clean = [
"this is a sample document",
"this document is another sample",
"and this is yet another example"
]
# 创建一个 CountVectorizer 实例
vectorizer = CountVectorizer()
# 将文本数据转换为词袋模型
X = vectorizer.fit_transform(contents_clean)
# 打印词汇表
print("Vocabulary: ", vectorizer.vocabulary_)
# 打印转换后的特征矩阵
print("Feature Matrix: \n", X.toarray())
输出解释
词汇表(Vocabulary):
vectorizer.vocabulary_会返回一个字典,其中键是词汇,值是词汇在向量中的索引。
Vocabulary: {'this': 6, 'is': 2, 'sample': 4, 'document': 1, 'another': 0, 'and': 5, 'yet': 7, 'example': 3}
- 特征矩阵(Feature Matrix):
X.toarray()返回一个二维数组,每行代表一个文档,每列代表一个词汇在该文档中出现的次数。
Feature Matrix:
[[0 1 1 0 1 0 1 0]
[0 1 1 0 1 0 1 0]
[1 0 1 1 0 1 1 1]]
3、进一步应用
TF-IDF(Term Frequency-Inverse Document Frequency):
- 除了简单的词频计数,TF-IDF 是一种常见的增强方法,可以降低常见词的权重,提升罕见词的权重。
from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vectorizer = TfidfVectorizer() X_tfidf = tfidf_vectorizer.fit_transform(contents_clean) print("TF-IDF Feature Matrix: \n", X_tfidf.toarray())主题模型(LDA):
- 你可以在词袋模型的基础上,进一步进行主题建模,例如使用潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)来发现文档中的潜在主题。
from sklearn.decomposition import LatentDirichletAllocation lda = LatentDirichletAllocation(n_components=2, random_state=0) lda.fit(X) print("Topics: \n", lda.components_)
词袋模型是文本处理的基础步骤之一,通过将文本数据映射为数值向量,使得文本数据能够被机器学习算法处理。这个过程简单高效,是许多高级文本处理技术的基础。