- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
理论知识
前面已经学习了GAN与CGAN,这节开始学习Pix2Pix。
Pix2Pix是一个以CGAN为基础,用于图像翻译(Image Translation)的通用框架,旨在将一个图像域中的图像转换成另一个图像域中的图像,它实现了模型结构和损失函数的通用化,并在诸多的图像翻译数据集上取得了令人瞩目的效果。
图像翻译
首先要先理解 图像内容(Image Content)、图像域(Image Domain)和图像翻译这三个概念。
- 图像内容:指的是图像的固有内容,它是区分不同图像的依据
- 图像域:指在特定上下文中所涵盖的一组图像的集合,这些图像通常具有某种相似性或共同特征。图像域可以用来表示 一类具有共同属性或内容的图像。在图像处理和计算机视觉领域,图像域常常被用于描述参数某项任务或问题的图像集合
- 图像翻译:是将一个物体的图像表征转换为该物体的另一个表征,例如根据皮包的轮廓得到皮包的彩色图。也就是找到一个函数,能让域A的图像映射到域B,从而实现图像的跨域转换。
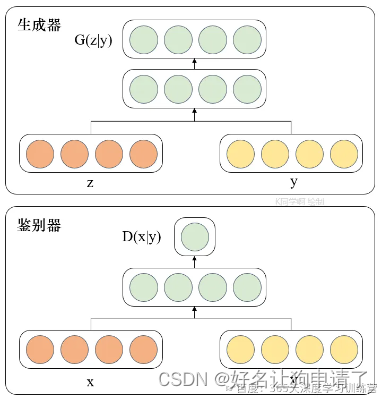
CGAN
在之前的学习中我们知道CGAN是在GAN的基础上进行了一些改进。对于原始的GAN生成器而言,其生成的图像数据是随机不可预测的,因此CGAN在生成器和判别器中加入了额外的条件。它的本质是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,旨在把无监督学习的GAN转化为有监督学习的CGAN,便于网络能够在我们的掌控下更好地进行训练 。
U-Net
U-Net是一个用于医学图像分割的全卷积模型。它分为两个部分,其中左侧是由卷积和降采样操作组成的压缩路径,右侧是由卷积和上采样组成的扩张路径,扩张的每个网络块的输入由上一层上采样的特征和压缩路径部分的特征拼接而成。网络模型整体是一个U形的结构,因此被叫做U-Net
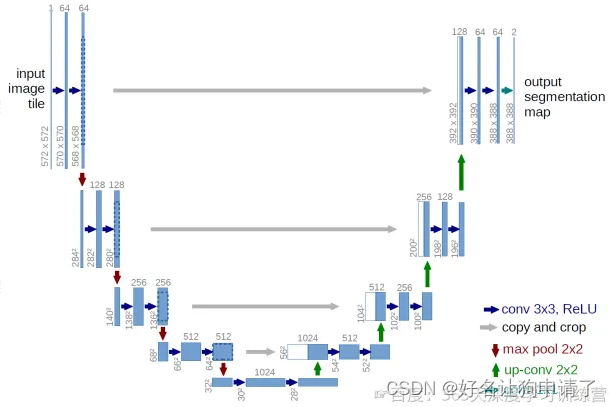
分割任务是图像翻译任务的一个分支,因此U-Net也可以被用作其它的图像翻译任务,Pix2Pix就是采用了U-Net作为主体结构。
Pix2Pix
在Pix2Pix中,图像翻译任务可以建模为给定一个输入数据 x x x和随机噪声 z z z,生成目的图像 y y y,即 G : { x , z } → y G:\{x,z\} \rightarrow y G:{x,z}→y。
与传统的CGAN不同的是,在Pix2Pix中判别器的输入是生成图像 G ( x ) G(x) G(x)(或是目标图像 y y y)和源图像 x x x,而生成器的输入是源图像 x x x和随机噪声 z z z
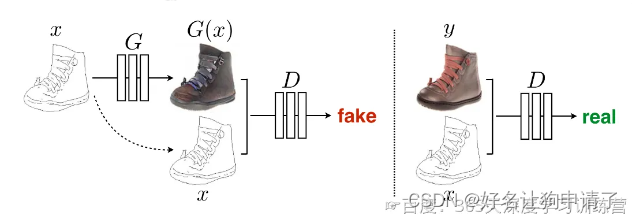
损失函数
因为Pix2Pix和CGAN相比,输入的数据不太相同了,所以它们的损失函数也要对应进行调整,可以表示为
L c G A N ( G , D ) = E x , y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ] \mathcal{L}_{cGAN}(G,D) =\mathbb {E}_{x,y}[logD(x,y)] + \mathbb {E}_{x,z}[log(1-D(x, G(x,z)))] LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
当然Pix2Pix也可以像CGAN一样在损失函数中加入正则项来提升生成图像的质量,不同的是Pix2Pix使用的是L1正则而不是L2正则,使用L1正则有助于使生成的图像更清楚
L L 1 ( G ) = E x , y , z [ ∣ ∣ y − G ( x , z ) ∣ ∣ 1 ] \mathcal{L_{L1}}(G) = \mathbb{E}_{x,y,z}[||y-G(x,z)||_1] LL1(G)=Ex,y,z[∣∣y−G(x,z)∣∣1]
最终训练的目标是在正则约束情况下的生成器和判别器的最大最小博弈
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) + λ L L 1 ( G ) G^*=arg\ \mathop{min}\limits_{G}\ \mathop{max}\limits_{D}\mathcal{L}_{cGAN}(G,D) + \lambda\mathcal{L}_{L1}(G) G∗=arg Gmin DmaxLcGAN(G,D)+λLL1(G)
之所以在生成数据中加入随机噪声 z z z,是为了使生成模型生成的数据具有一定的随机性,但是实验结构表明完全随机的噪声并不会产生特别有效的效果。在Pix2Pix中是通过在生成器的模型层中加入Dropout来引入随机噪声的,但是Dropout带来输出内容的随机性并没有很大
模型结构
Pix2Pix使用了CNN中常用的卷积+BN+ReLU的模型结构
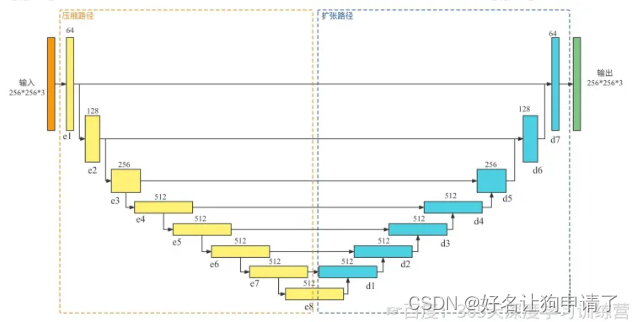
生成器
对于图像翻译这种任务来说,经典的编码器-解码器结构是最优的选择。
- Pix2Pix使用的是以U-Net为基础的结构 ,即在压缩路径和扩张路径之间添加一个跳跃连接
- Pix2Pix的输入图像的大小 256 × 256 256 \times 256 256×256
- 每个操作仅进行了三次降采样,每次降采样的通道数均乘以2,初始的通道数是64
- 在压缩路径中,每个箭头表示的操作是卷积核大小为 4 × 4 4 \times 4 4×4的相同卷积 + BN + ReLU,它根据是否降采样来控制卷积的步长
- 在扩张路径中,它使用的是反卷积上采样
- 压缩路径和扩张路径使用的是拼接操作进行特征融合
差别器
传统的GAN有一个棘手的问题是它生成的图像普遍比较模糊,其中一个重要的原因是它使用了整图作为判别器的输入。不同于传统将整个图像作为判别器差别的目标(输入),Pix2Pix提出了将输入图像分成 N × N N \times N N×N 个图像块(Patch),然后将这些图像块依次提供给判别器,因此这个方法被命名为PatchGAN,PatchGAN可以看作针对图像纹理的损失。实验结果表明,当 N = 70 N = 70 N=70 时模型的表现最好,但是从生成结果来看, N N N 越大,生成的图像质量越高。其中 1 × 1 1\times1 1×1大小的图像块的判别器又被叫做PixelGAN
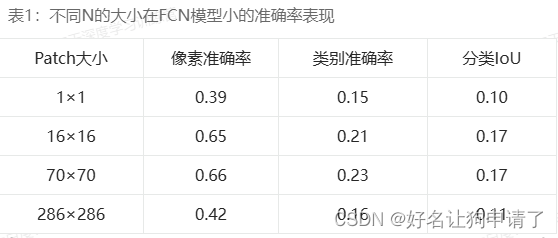

对于不同大小的N,需要根据 N N N的值来调整判别器的层数,进而得到最合适的模型感受野,我们可以根据表格来计算,进而运行Patch大小和层数。
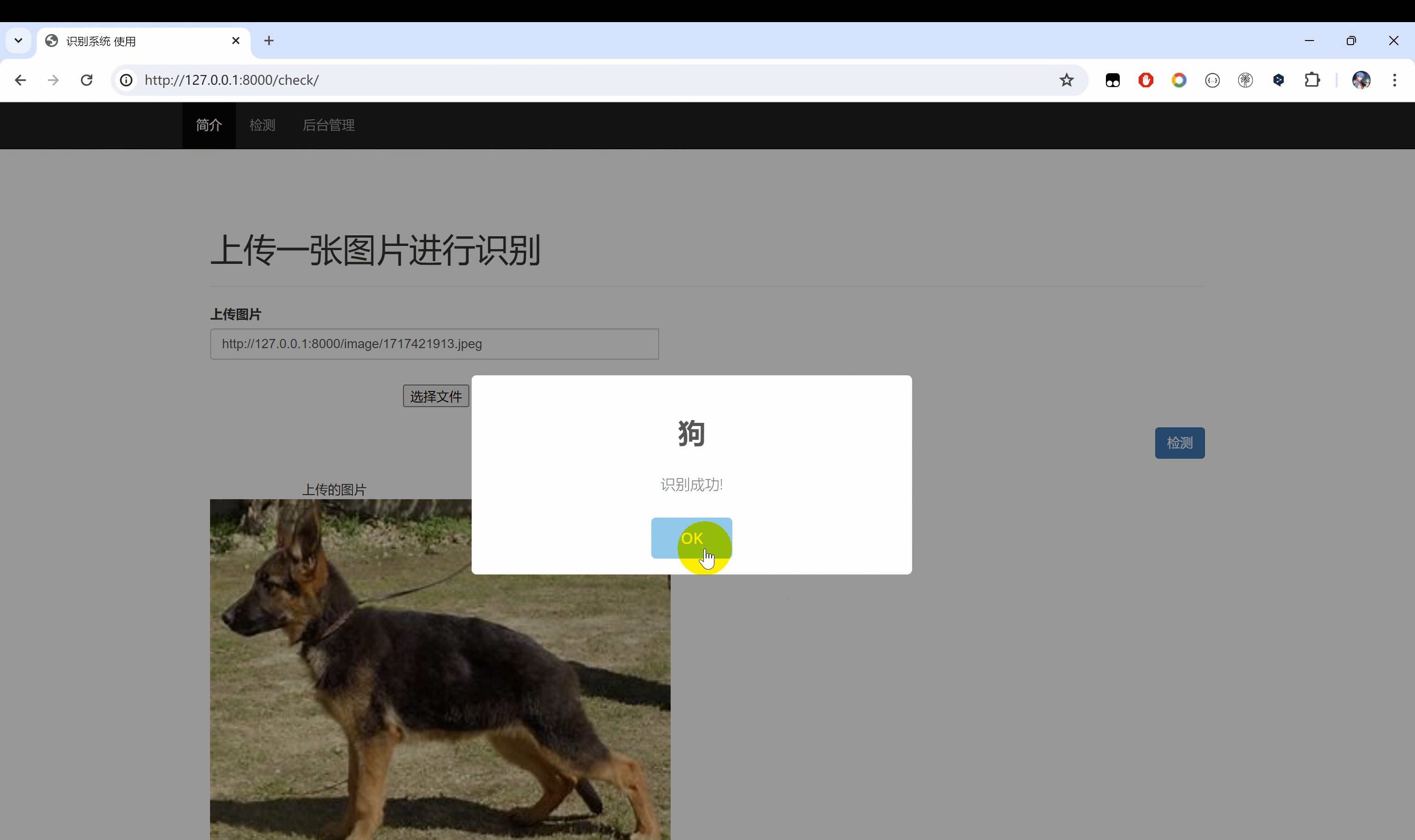
模型效果
模型代码暂未实现,使用了Up给提供的直接运行。

总结与心得体会
通过对Pix2Pix模型的学习,最让我印象深刻的特点是它把判别器由CGAN那种统一压缩完直接预测的逻辑转换成了分成一个Patch,这样提升了模型生成的精度。在了解了这个修改后,我对之前GAN和CGAN产生的斑点很多的生成有了更加深入的理解。应该是由于模型对特征的压缩,导致部分像素失去代表性,产生斑点。
还有一个印象深刻的点是完全随机的噪声 z z z并不会对生成有什么特别的结果,于是作者直接使用Dropout来产生噪声,不再对分布单独处理,这个问题在我实现CGAN时也有疑问,但是我没有认真验证,以后应当想办法抓住这些想法,去试着实现并验证。



















![Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023](https://img-blog.csdnimg.cn/direct/137dc32d7e3d4195ae92d52c66255928.png)