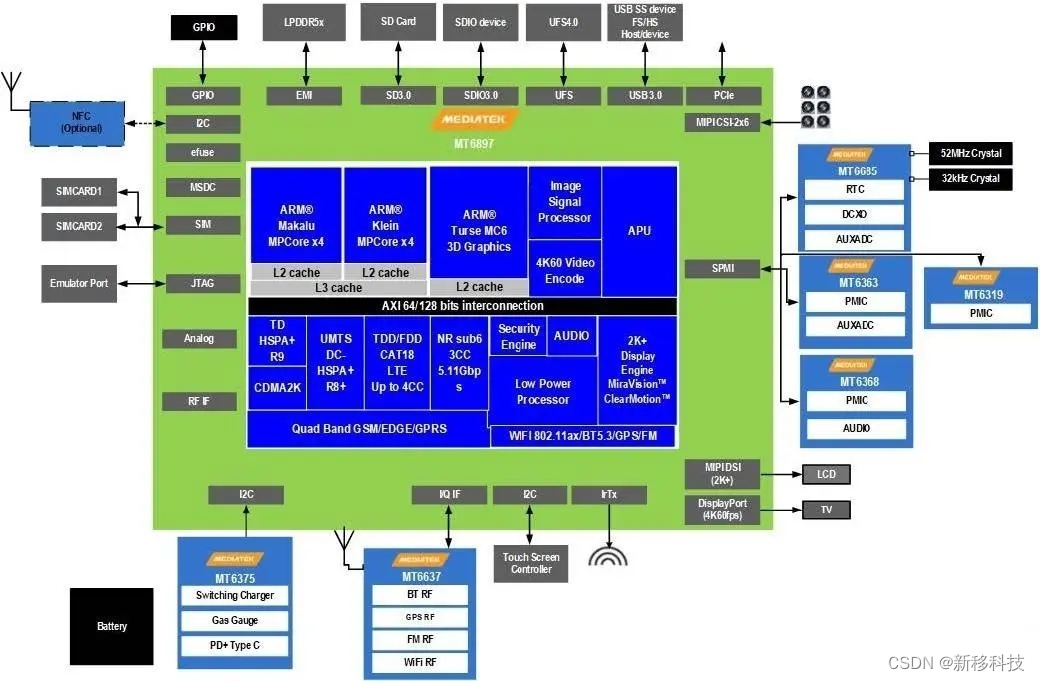
语言模型
联合概率
给定文本序列 x 1 , ⋯ , x t x_1,\cdots,x_t x1,⋯,xt,语言模型的目标是估计联合概率 P ( x 1 , ⋯ , x t ) P(x_1,\cdots,x_t) P(x1,⋯,xt). 这里的 x t x_t xt 可以认为是文本序列在时间步 t t t 处的观测或标签,而所谓联合概率指的是一个句子的整体概率,即句子中所有单词相继出现的概率。
语言模型的用处:可以在语音识别上解决同音句歧义问题和断句问题。
语言建模
根据上一节中的序列模型的分析,有基础概率规则: P ( x 1 , x 2 , ⋯ , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , ⋯ , x t − 1 ) P(x_1,x_2,\cdots,x_T)=\prod_{t=1}^TP(x_t|x_1,\cdots,x_{t-1}) P(x1,x2,⋯,xT)=t=1∏TP(xt∣x1,⋯,xt−1)例如一个四个单词的文本序列的概率表示为: P ( d e e p , l e a r n i n g , i s , f u n ) = P ( d e e p ) P ( l e a r n i n g ∣ d e e p ) P ( i s ∣ d e e p , l e a r n i n g ) P ( f u n ∣ d e e p , l e a r n i n g , i s ) P(deep,learning,is,fun)=P(deep)P(learning|deep)P(is|deep,learning)P(fun|deep,learning,is) P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is)
为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。
计数建模
最容易想到的方法是统计单词(词元)在数据集中出现的次数,然后除以整个语料库的单词总数。例如: P ( l e a r n i n g ∣ d e e p ) = n ( d e e p , l e a r n i n g ) n ( d e e p ) P(learning|deep)=\frac{n(deep,learning)}{n(deep)} P(learning∣deep)=n(deep)n(deep,learning) 其中 n ( x ) , n ( x , x ‘ ) n(x),n(x,x`) n(x),n(x,x‘) 分别表示单个单词和连续单词出现次数。
这种方法在一些高频词上表现的不错,但是在一些低频词和长句多单词组合的情况表现不佳,因为可能语料库中这样的数据很少,即使提出了一些解决办法如拉普拉斯平滑(通过计数中添加小常量),但仍不能解决该问题。
马尔可夫模型与n元语法
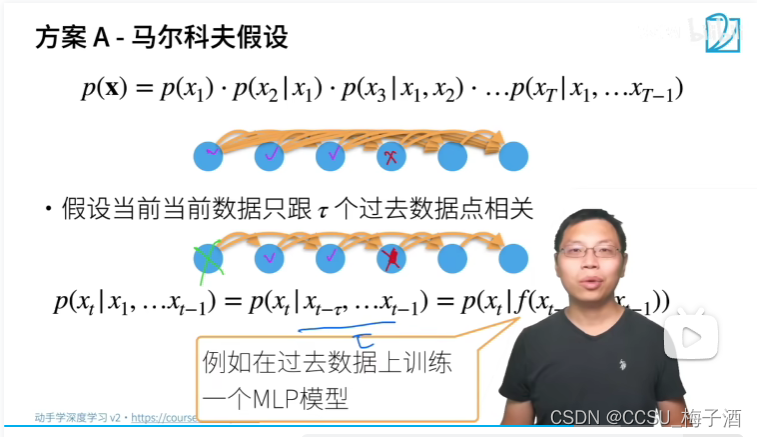
当单纯使用计数法时可能存在长单词序列样本极少导致 n ( x 1 , ⋯ , x t ) ≤ 1 n(x_1,\cdots,x_t)\leq1 n(x1,⋯,xt)≤1 的情况。回忆上一章序列模型中提到的马尔可夫模型,将其用于语言建模。
我们可以不用考虑整个序列模型,而是只用考虑长度为 τ \tau τ 的时间跨度,还是以长度为 4 4 4 的句子的联合概率举例。
一元语法 τ = 0 \tau = 0 τ=0:不用考虑单词之间的联系,只考虑互相独立概率,这样前后文之间无关联的语法并不适用时序的模型。 P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) = n ( x 1 ) n ( x 2 ) n ( x 3 ) n ( x 4 ) n 4 P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2)P(x_3)P(x_4)=\frac{n(x_1)n(x_2)n(x_3)n(x_4)}{n^4} P(x1,x2,x3,x4)=P(x1)P(x2)P(x3)P(x4)=n4n(x1)n(x2)n(x3)n(x4)
二元语法:只与前一个词元有关。 P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 2 ) P ( x 4 ∣ x 3 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_2)P(x_4|x_3) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x2)P(x4∣x3)
通常,涉及一个、两个和三个变量的概率公式分别被称为一元语法(unigram)、二元语法(bigram)和三元语法。 n n n 元语法模型最大好处在于:在处理比较长的序列时可以将所有长为 n n n 的子序列概率存下来,假设存下来所有情况的数量为 k k k,那么之后查询时复杂度固定为 O ( k ) O(k) O(k) 而不用遍历整个文本 O ( n ) O(n) O(n).