背景:
今天翻看了之前练习的一些题。发现还是不够简洁。原来“温故而知新,可以为师矣”是真的。索性直接贴出源码来露个像,当个现眼包。
以前注重先实现,后优化。现在来看。确实有不少可以采用更简单的策略来实现。这也是编码能力的进阶了。在一些复杂场景下,只有优化代码策略才能满足。
letcode后面的一些题,开始有二叉树了,那种题,本地还调试不了。慢慢记录就停了。
desc: 145. 二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历
""
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
listt=[]
def rankt(root: Optional[TreeNode], listt:List[int]) -> List[int]:
if not root:
return
if root.left:
rankt(root.left,listt)
if root.right:
rankt(root.right,listt)
listt.append(root.val)
rankt(root,listt)
return listt
"""
desc: 121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
#2023-9-9 23:44:13 there is no better answer for this problem。 must be out of time including official answer
def max_profit(prices=[]):
lenth = len(prices)
mark = 0
for i in range(1, lenth):
maxt = max(list(set(prices[i::])))
mint = min(list(set(prices[0:i])))
if maxt < mint:
continue
tmp = maxt - mint
mark = tmp if tmp > mark else mark
return mark
def max_profit2(prices=[]):
lenth = len(prices)
mark = 0
for i in range(1, lenth):
maxt = max(list(set(prices[i::])))
mint = min(list(set(prices[0:i])))
if maxt < mint:
continue
tmp = maxt - mint
mark = tmp if tmp > mark else mark
return mark
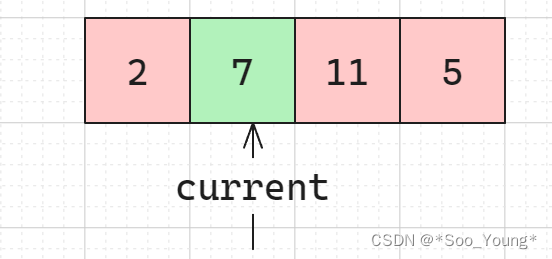
print(max_profit([1,2,4,11,7]))
"""没记录题目
"""
start_time:
end_time:
desc: 模版
def singleNumber(nums):
nums.sort()
lent = len(nums)-1
t=[nums[k] for k in range(lent) if k % 2 == 0 and nums[k] != nums[k + 1]]
return t[0] if t else nums[-1]
def singleNumber2(nums):
nums.sort()
lent = len(nums)-1
#result = [nums[k] for k,_ in enumerate(nums) if nums[k]!=nums[k+1]]
for k in range(lent):
if k%2 ==0 and nums[k]!=nums[k+1]:
return nums[k]
return nums[-1]
print(singleNumber([1,3,2,2,1,3,4]))
"""desc: 验证回文串
"""
desc: 验证回文串
def isPalindrome(s):
s = [x.lower() for x in s if x.isalnum()]
return s==s[::-1]
print(isPalindrome("A man, a plan, a canal: Panama"))
print(isPalindrome("raceacar"))
"""desc: 94:二叉树的中序遍历
"""
end_time:
desc: 94:二叉树的中序遍历
def iteration(root,res):
if not root:
return
iteration(root.left,res)
res.append(root)
iteration(root.right,res):
def vsxu(root):
res=[]
iteration(root,res)
return res
"""desc: 88. 合并两个有序数组
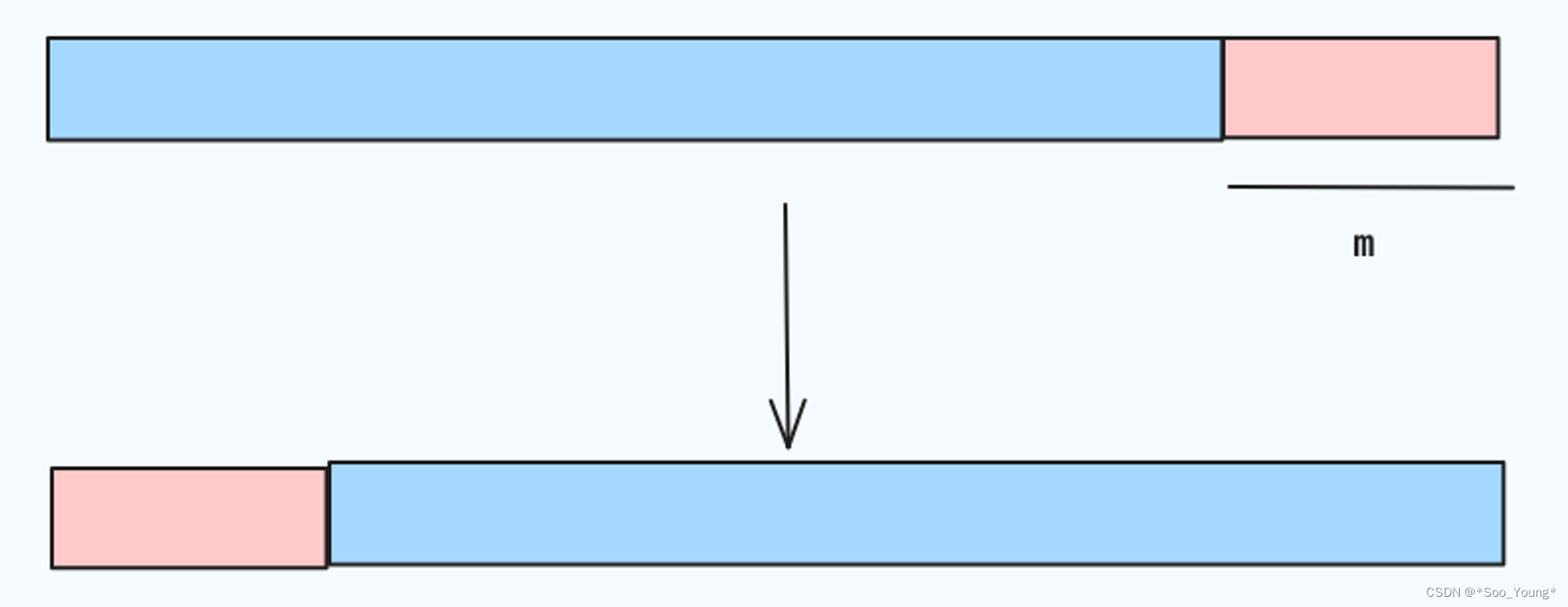
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
你可以设计实现一个时间复杂度为 O(m + n) 的算法解决此问题吗?
#pass
def combine_two_list(nums1, nums2, m, n):
i = 0
j = 0
while (i < m+n and j < n):
if nums1[i]< nums2[j]:
if i< m+j:
i+=1
else:
nums1[i] = nums2[j]
j+=1
else:
nums1.insert(i,nums2[j])
nums1.pop(-1)
i+=1
j+=1
def combine_two_list3(nums1, nums2, m, n):
i = 0
j = 0
while (i < m+n and j < n):
if nums1[i] != 0 and nums2[j] < nums1[i]:
nums1[i], nums2[j] = nums2[j], nums1[i]
i += 1
elif nums1[i] == 0 and nums2[j]:
nums1[i], nums2[j] = nums2[j], nums1[i]
j += 1
else:
i += 1
# 用了空间换时间。使用了切片。默认会copy一份nums来赋值。
def combine_two_list2(nums1, nums2, m, n):
nums1 = nums1[:m-n ] + nums2
nums1.sort(reverse=False)
nums1 = [1,2,3,0,0,0]
nums2 = [2,5,6]
combine_two_list(nums1, nums2, 3, 3)
print(nums1)
"""desc: 83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
""" 麻烦
二刷
end_time:
desc: 83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
val ,next
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def del_repeat(head:ListNode,tmp=[]):
if head is None:
return None
cur = head
while cur.next:
if cur.next.val == cur.val:
cur.next = cur.next.next
else:
cur = cur.next
return head
print(del_repeat({"val":1,"next":{"val":1,"next":{"val":2,"next":{}}}}))
"""desc: 70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
"""
desc: 70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
def n_n(N):
if N<=1:
return 1
else:
return N*n_n(N-1)
def climb_stairs(stairs=0):
num_method=0
for i in range(stairs+1):
if (stairs-i) % 2==0:
if stairs-i !=0:
tmp1= n_n(i+(stairs-i)//2)
tmp2=(n_n((stairs-i)//2)*n_n(i))
tmp = tmp1/tmp2
print("tmp=",tmp,"i=",i)
num_method+=tmp
else:
num_method+=1
return int(num_method)
print(climb_stairs(stairs=2))
"""desc: 快速排序。
如题,快速排序是很牛的一种排序方式。
"""
end_time:
desc: 快速排序。
def quick_sort(alist,left=None,right=None):
left=0 if not left else left
right=len(alist)-1 if not right else right
if left>=right or left<0 or right<=0:
return
pivot = alist[left]
index=left+1
while(index<=right):
if alist[index]<pivot:
alist[index],alist[left] = alist[left],alist[index]
left+=1
else:
#index+=1
pass
index+=1
quick_sort(alist,0,left-1)
quick_sort(alist,left,right)
pass
a_list = [random.randint(1, 100) for x in range(10)]
b_list= [5,1,3,4,8,1,7,2,5,9,6,1]
quick_sort(b_list, None, None)
print(b_list)
#用空间换遍历,使用了额外的内存空间。
def quick_sort2(alist, left=None, right=None):
left = 0 if not left else left
right = len(alist) - 1 if not right else right
if left >= right:
return alist
index = left + 1
slist = []
llist = []
while (index <= right):
if alist[left] < alist[index]:
llist.append(alist[index])
else:
slist.append(alist[index])
index += 1
left_list = quick_sort(slist, left=0, right=len(slist) - 1)
right_list = quick_sort(llist, left=0, right=len(llist) - 1)
return left_list+[alist[left]]+right_list
pass
def quick_sort2_x(a_list, left=None, right=None):
if left > right:
return
left = 0 if not left else left
right = len(a_list) - 1 if not right else right
pivot = left
left = left + 1
while (left <= right):
if a_list[left] > a_list[pivot]:
while (a_list(right) < a_list(pivot) and right > left):
right -= 1
a_list[left], a_list[right] = a_list[right], a_list[left]
left += 1
right -= 1
left += 1
a_list[pivot], a_list[left] = a_list[left], a_list[pivot]
quick_sort(a_list, None, left)
quick_sort(a_list, left + 1, None)
pass
"""desc: 69. x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
"""
end_time:
desc: 69. x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
def squre_root(x):
pass
# 法1:遍历。x越大,耗时越久。
def squre_root1(x):
if x in [0, 1]:
return x
for y in range(2, 2 + x // 2):
if y * y > x:
return y - 1
return -1
pass
print(squre_root(1))
print(squre_root(2))
print(squre_root(4))
print(squre_root(8))
"""两种解法。28min分钟。内存消耗都比较大。24%胜率在内存。
desc: 66. 加一
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
"""
两种解法。28min分钟。内存消耗都比较大。24%胜率在内存。
desc: 66. 加一
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
def devide_number(int_d):
if int_d // 10 == 0:
return [int_d]
return devide_number(int_d // 10) + [int_d % 10]
# if int_d//10 !=0:
# return devide_number(int_d)+ list[int_d//10]
# return list[int_d]
def add_one(digits=[]):
len_d = len(digits) # 123,3
origin_d = 0
for k, x in enumerate(digits):
origin_d += x * 10 ** (len_d - 1 - k)
arm_d = origin_d + 1
return devide_number(arm_d)
def plusOne(digits=[]):
len_d = len(digits) # 123,3
origin_d = 0
for k, x in enumerate(digits):
origin_d += x * 10 ** (len_d - 1 - k)
arm_d = origin_d + 1
return [int(x) for x in str(arm_d)]
print(add_one([1, 2, 3]))
print(add_one([4, 3, 2, 1]))
print(add_one([0]))
"""
desc: 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为5。
示例 2:
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为4。
示例 3:
输入:s = "luffy is still joyboy"
输出:6
解释:最后一个单词是长度为6的“joyboy”。
提示:
1 <= s.length <= 104
s 仅有英文字母和空格 ' ' 组成
s 中至少存在一个单词
"""
desc: 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为5。
示例 2:
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为4。
示例 3:
输入:s = "luffy is still joyboy"
输出:6
解释:最后一个单词是长度为6的“joyboy”。
提示:
1 <= s.length <= 104
s 仅有英文字母和空格 ' ' 组成
s 中至少存在一个单词
def length_of_last_word(s):
return len(s.strip().split(" ")[-1])
print(length_of_last_word("Hello World"))
print(length_of_last_word(" fly me to the moon "))
print(length_of_last_word("luffy is still joyboy"))
"""
number:35. 搜索插入位置
desc: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
"""
number:35. 搜索插入位置
desc: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
def search_insert_position2(nums=[], target=None):
for k, x in enumerate(nums):
if x == target:
return k
elif x > target:
return k
else:
continue
return len(nums)
pass
def search_insert_position(nums=[], target=None):
# 内存使用
k = len(nums)
for x in range(k):
if nums[x] == target:
return x
elif nums[x] > target:
return x
return k
def search_insert_position3(nums=[], target=None):
# 内存使用最小,击败92.61%的内存python3用户。
tmp = [k for k, v in enumerate(nums) if v >= target]
if not tmp:
return len(nums)
else:
return tmp[0]
"""desc: 有效的括号,g给定一个只包括(),{},[]的字符串 s ,判断字符串是否有效
有效字符串需满足:
1、左括号必须用相同类型的右括号闭合
2、左括号必须以正确的顺序闭合
3、每个右括号都有一个对应的相同类型的左括号。
test= (),()[]{}, (], ([)], )]([
评价:第一批次处理很快,时间少于20分钟。但是处理两个较复杂的场景时调试耗时较多。超过40分钟
"""
desc: 有效的括号,g给定一个只包括(),{},[]的字符串 s ,判断字符串是否有效
有效字符串需满足:
1、左括号必须用相同类型的右括号闭合
2、左括号必须以正确的顺序闭合
3、每个右括号都有一个对应的相同类型的左括号。
test= (),()[]{}, (], ([)], )]([
评价:第一批次处理很快,时间少于20分钟。但是处理两个较复杂的场景时调试耗时较多。超过40分钟
def enable_bracket(strs):
# 通过偶数判断是否成对,快速判断有效
if len(strs) % 2 != 0:
return False
# 符合区分判断 周期特长X
# 通过3个计数来判断,+1,-1。小于0时则false 正解
count_s_bra = 0
count_m_bra = 0
count_l_bra = 0
# 需要将记录最后一个add 或者reduce的符号改为 顺序存所有的符号
add_sign_list = []
reduce_sign_list = []
for x in strs:
if count_l_bra < 0 or count_m_bra < 0 or count_s_bra < 0:
return False
if reduce_sign_list != []:
if add_sign_list == []:
return False
rs = reduce_sign_list.pop(-1)
if rs == add_sign_list[-1]:
add_sign_list = add_sign_list[:-1]
else:
return False
if x == "(":
count_s_bra += 1
add_sign_list.append(1)
elif x == ")":
count_s_bra -= 1
reduce_sign_list.append(1)
elif x == "[":
count_m_bra += 1
add_sign_list.append(2)
elif x == "]":
count_m_bra -= 1
reduce_sign_list.append(2)
elif x == "{":
count_l_bra += 1
add_sign_list.append(3)
elif x == "}":
count_l_bra -= 1
reduce_sign_list.append(3)
else:
print("字符串内部存在非法字符")
return False
if count_l_bra != 0 or count_m_bra != 0 or count_s_bra != 0:
return False
else:
return True
print(enable_bracket("()"))
print(enable_bracket("()[]{}"))
print(enable_bracket("(]"))
print(enable_bracket("([)]"))
print(enable_bracket(")](["))
print(enable_bracket("(([]){})"))
print(enable_bracket("[([]])"))
""" desc: 14 最长公共前缀,查找字符串最长公共前缀
strs=["flower","flow","flight"]
输出:"f1"
"""
desc: 14 最长公共前缀,查找字符串最长公共前缀
strs=["flower","flow","flight"]
输出:"f1"
def common_str(strs):
# 判空:
if not strs:
return ""
# 以最短字符串长度进行遍历,相似则计数+1
min_len = len(strs[0])
for x in strs:
if len(x) < min_len:
min_len = len(x)
times = -1
end_flag=0
for i in range(0, min_len):
value = strs[0][i]
if end_flag == 1:
i-=1
times=i- 1
break
times = i
for x in strs:
if x[i] != value:
end_flag = 1
times = times-1
break
if times == -1:
return ""
else:
# 以结果计数,进行切片返回
return strs[0][:times+1]
strs = ["fltoweradfadf", "fltoweadfad", "fltoweiwght"]
print(common_str(strs))
"""desc: 一个字符串,求第一个不重复值的下标
"""
desc: 一个字符串,求第一个不重复值的下标
def mt_test(test:str):
#test:待测字符串
#第一步:判断为空
if len(test)<1:
return -1
#转换类型
list_test = list(test)
result ={}
#第二步:统计字段个数
for i in list_test:
if i not in result.keys():
result[i] = 1
else:
result[i] += 1
#第三步:
aim = [x for x in result.keys() if result[x] == 1]
tmp_k = -1
for k, v in enumerate(test):
if v == aim[0]:
tmp_k = k
return tmp_k
test = "abcabcdeefg"
print(mt_test(test))
print(mt_test(""))
print(mt_test("adjfklacasnihcuwejccjawoeuirsbncjnajksd"))
print(mt_test([]))
print(mt_test(123))
"""
























![Linux[高级管理]——使用源码包编译安装Apache网站](https://img-blog.csdnimg.cn/direct/3b7ecfb50593488a85d6a18de8a57bc8.gif)




![[经验] 华硕怎么进入安全模式win11 #微信#知识分享#其他](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fcache%2Fly_autoimg%2F%25E5%258D%258E%25E7%25A1%2595%25E6%2580%258E%25E4%25B9%2588%25E8%25BF%259B%25E5%2585%25A5%25E5%25AE%2589%25E5%2585%25A8%25E6%25A8%25A1%25E5%25BC%258Fwin11.jpg&pos_id=kLlPKdEm)