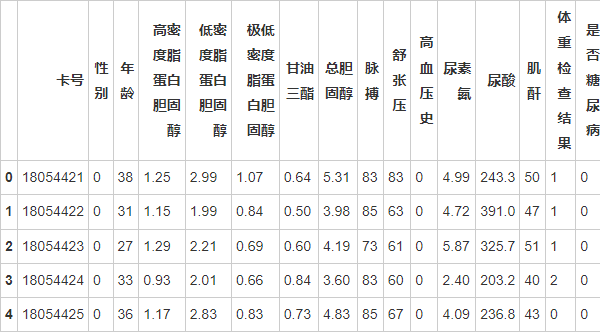
1. Pima Indians Diabetes 数据集
Pima Indians Diabetes 数据集是最常用的糖尿病数据集之一。它包含768个样本和8个特征,目标变量是二分类(是否患有糖尿病)。
在R中加载 Pima Indians Diabetes 数据集
# 安装并加载 mlbench 包(如果尚未安装)
install.packages("mlbench")
library(mlbench)
# 加载 Pima Indians Diabetes 数据集
data(PimaIndiansDiabetes)
dataset <- PimaIndiansDiabetes
# 查看数据集的结构
str(dataset)
2. Diabetes 130-US hospitals for years 1999-2008 数据集
该数据集包含了130家美国医院在1999-2008年间的糖尿病患者数据。它包含超过100,000条记录和50个特征。
在R中加载 Diabetes 130-US hospitals 数据集
这个数据集可以从UCI机器学习库下载,然后在R中加载。首先需要下载数据集并保存为CSV文件。
# 假设已经下载并保存为 "diabetes_130_us_hospitals.csv"
# 使用 read.csv 函数加载数据集
dataset <- read.csv("path/to/diabetes_130_us_hospitals.csv")
# 查看数据集的结构
str(dataset)
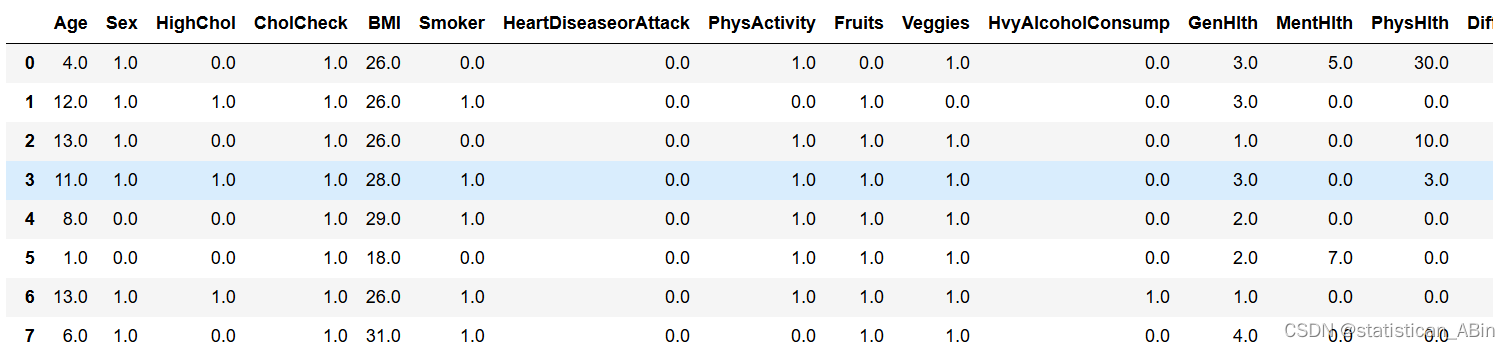
3. Diabetes Health Indicators Dataset
该数据集包含了超过70,000条记录,记录了患者的健康指标和糖尿病情况。
在R中加载 Diabetes Health Indicators 数据集
同样,这个数据集需要先下载并保存为CSV文件。
# 假设已经下载并保存为 "diabetes_health_indicators.csv"
# 使用 read.csv 函数加载数据集
dataset <- read.csv("path/to/diabetes_health_indicators.csv")
# 查看数据集的结构
str(dataset)
4. Kaggle上的糖尿病数据集
Kaggle是一个数据科学竞赛平台,上面有许多开源的数据集。你可以在Kaggle上搜索“diabetes”来找到相关的数据集。
在R中加载 Kaggle 数据集
首先需要从Kaggle下载数据集,然后在R中加载。
# 假设已经从Kaggle下载并保存为 "kaggle_diabetes.csv"
# 使用 read.csv 函数加载数据集
dataset <- read.csv("path/to/kaggle_diabetes.csv")
# 查看数据集的结构
str(dataset)
示例:使用Pima Indians Diabetes数据集构建糖尿病检测模型
以下是一个完整的示例,使用Pima Indians Diabetes数据集构建和评估糖尿病检测模型。
# 安装并加载必要的包
install.packages("caret")
install.packages("mlbench")
library(caret)
library(mlbench)
# 加载数据集
data(PimaIndiansDiabetes)
dataset <- PimaIndiansDiabetes
# 将因变量转换为因子类型
dataset$diabetes <- as.factor(dataset$diabetes)
# 划分训练集和测试集
set.seed(123)
trainIndex <- createDataPartition(dataset$diabetes, p = 0.8, list = FALSE)
trainData <- dataset[trainIndex, ]
testData <- dataset[-trainIndex, ]
# 训练逻辑回归模型
model <- train(diabetes ~ ., data = trainData, method = "glm", family = binomial)
# 使用测试集进行预测
predictions <- predict(model, newdata = testData)
# 计算混淆矩阵和准确率
confMatrix <- confusionMatrix(predictions, testData$diabetes)
print(confMatrix)
accuracy <- confMatrix$overall['Accuracy']
print(paste("Model Accuracy: ", round(accuracy * 100, 2), "%", sep = ""))
通过这些步骤,你可以加载不同的糖尿病数据集,并使用R语言构建和评估糖尿病检测模型。
![[Python] 机器学习 - 常用<span style='color:red;'>数据</span><span style='color:red;'>集</span>(Dataset)之<span style='color:red;'>糖尿病</span>(diabetes)<span style='color:red;'>数据</span><span style='color:red;'>集</span>介绍,<span style='color:red;'>数据</span>可视化和使用案例](https://img-blog.csdnimg.cn/direct/b5ea47fa416a4d40b44085c550b3ab85.png)































![[XYCTF新生赛]-Reverse:ez_rand解析(爆破时间戳,汇编结合反汇编)](https://img-blog.csdnimg.cn/direct/fc9ee39d43d7419687e37e81090a2c14.png)