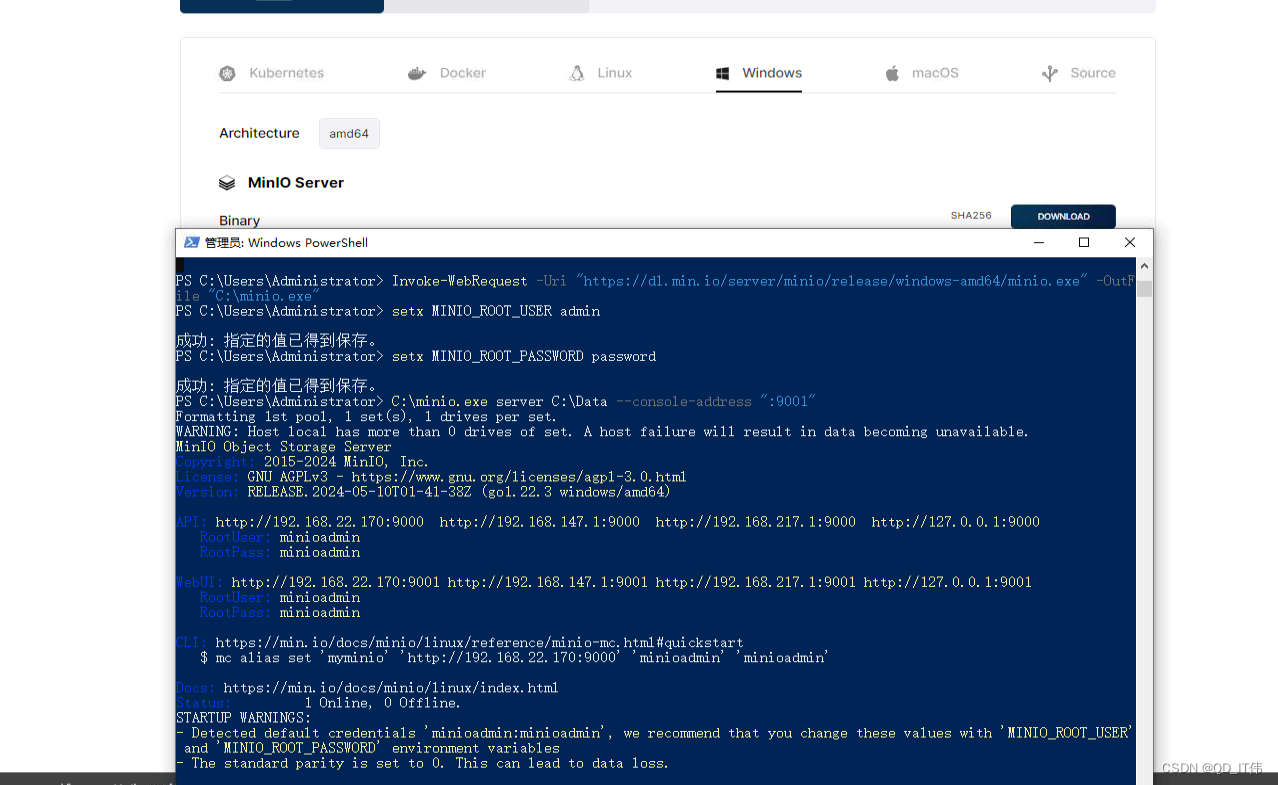
网页解析之lxml与xpath
lxml库详解
lxml库是一个非常高性能和功能丰富的库,支持XML和HTML的解析、导航和任何操作。它基于C语言库libxml2和libxslt。主要包括两个核心模块:
1. **etree** - 用于解析和处理XML和HTML数据
2. **objectify** - 将XML数据映射为Python对象
etree是比较常用的模块,提供了XPath和XSLT支持。
解析HTML
from lxml import etree
# 解析HTML字符串
parser = etree.HTMLParser()
html = etree.HTML(html_str, parser=parser)
# 解析HTML文件
html = etree.parse('path/to/file.html', parser)解析XML
# 解析XML字符串
xml = etree.fromstring(xml_str)
# 解析XML文件
xml = etree.parse('path/to/file.xml')节点操作
etree提供了丰富的API用于获取、修改和创建节点:
- 获取节点 `find()`、`findall()`、`xpath()`
- 修改节点 `set()`、`append()`、`remove()`
- 创建节点 `Element()`、`SubElement()`
XPath语法详解
XPath是一种查询语言,用于在XML/HTML文档中选取节点。它的语法涵盖路径表达式、条件表达式和运算表达式。
节点选取
- 节点 `bookstore`
- 子节点 `bookstore/book`
- 所有节点 `//book`
- 父节点 `../`
- 属性节点 `//book/@price`
- 文本节点 `//book/title/text()`
条件
- 等于 `[@price="25"]`
- 不等于 `[@price!="25"]`
- 大于 `[@price>25]`
- 小于 `[@price<25]`
- 包含 `[contains(@category,"fic")]`
运算
- `|` 或者
- `+` 加法
- `-` 减法
- `*` 乘法
- `div` 除法
函数
XPath提供了大量内置函数,如`string()` `count()` `sum()` `concat()` 等。也可以自定义函数。
轴
轴用于在节点树中定位节点,如`child` `parent` `ancestor` `following` 等。
lxml与XPath实战
接下来通过一个实例演示如何利用lxml和XPath获取网页数据:
import requests
from lxml import etree
url = 'https://movie.douban.com/top250'
# 获取网页源码
response = requests.get(url)
html = etree.HTML(response.text)
# 获取所有电影信息节点
movie_nodes = html.xpath('//ol[@class="grid_view"]/li')
# 遍历电影节点,提取每部电影的信息
movies = []
for node in movie_nodes:
title = node.xpath('.//span[@class="title"][1]/text()')[0]
rating = node.xpath('.//span[@class="rating_num"]/text()')[0]
movie = {
'title': title,
'rating': rating
}
movies.append(movie)
print(movies)在这个例子中,我们首先发送请求获取豆瓣电影Top250网页源码,构建HTML树。然后通过XPath表达式`//ol[@class="grid_view"]/li`选取所有电影信息节点。
接着遍历这些节点,分别使用XPath表达式提取出电影标题和评分。最终将所有提取的数据组合成列表。
可以看到,借助lxml的解析能力和XPath强大的节点选取能力,我们用较少的代码就实现了网页数据的抓取,而且精确性很高。XPath语法看似简单,但功能异常强大,灵活性极高,值得我们深入学习掌握。
总结
lxml和XPath是处理HTML/XML文档的利器,功能强大且高性能。lxml是整合了libxml2和libxslt的Python解析库,支持XPath/XSLT;而XPath则提供了精准、高效的节点选取能力。二者完美结合,使得Python语言在网页解析领域能够发挥极大威力。对lxml和XPath有深入的理解和掌握,是Python开发者提升技能的重要一环。