string模拟实现
1. string接口预览
#include <iostream>
#include <assert.h>
using namespace std;
namespace hb
{
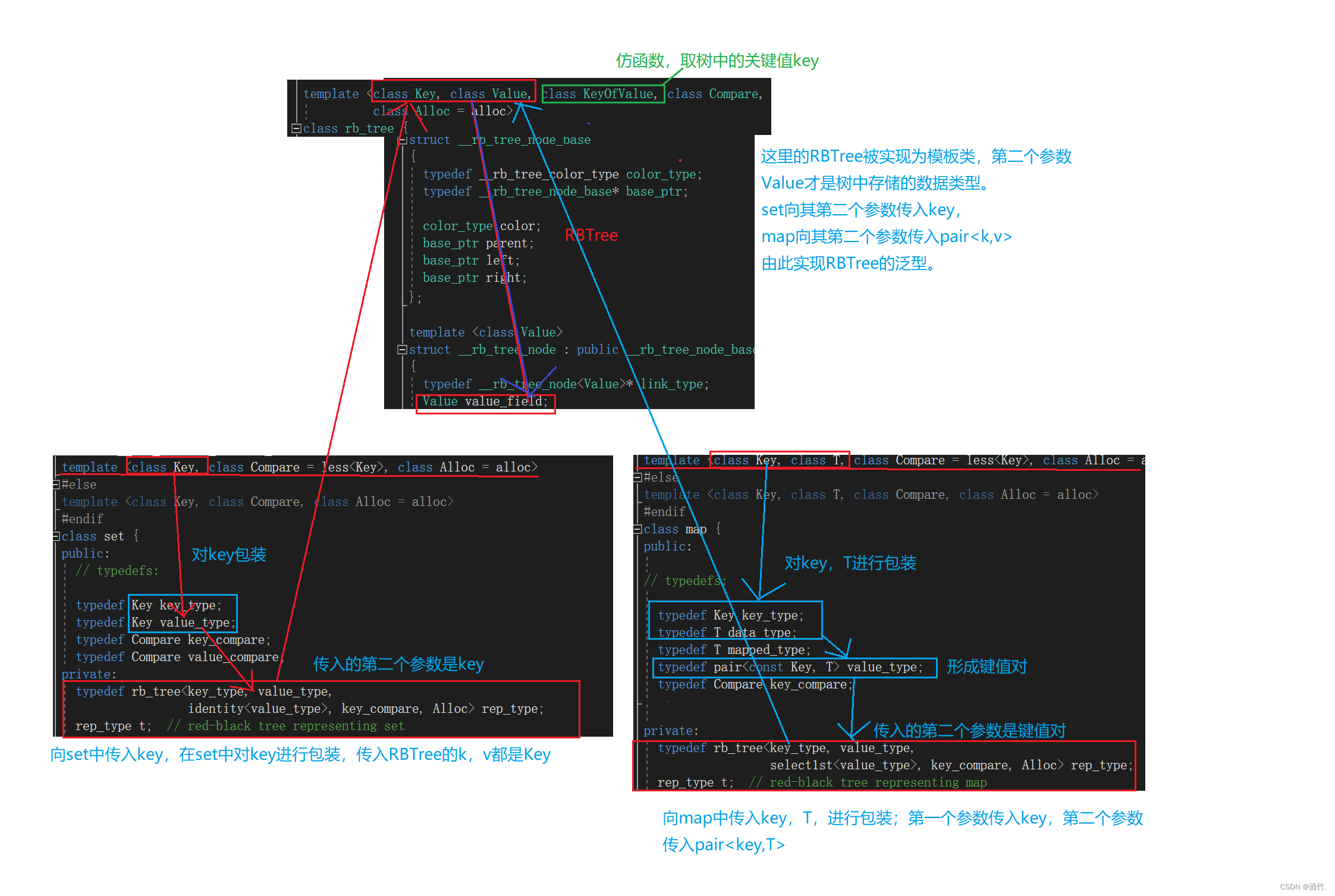
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
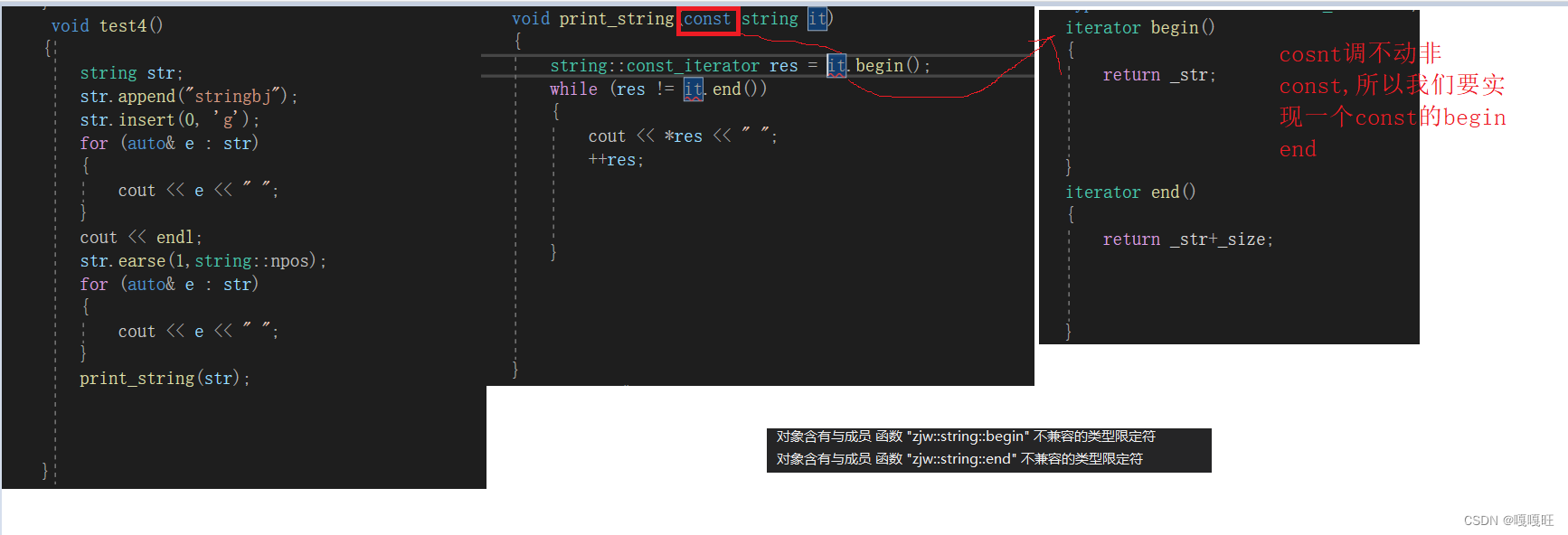
iterator begin();
iterator end();
const_iterator begin() const;
const_iterator end() const;
string(const char* str = "");
string(const string& s);
~string();
//string& operator=(const string& s);
string& operator=(string s);
const char* c_str() const;
size_t size() const;
size_t capacity() const;
char& operator[](size_t pos);
const char& operator[](size_t pos) const;
void push_back(char ch);
void append(const char* str);
void reserve(size_t n);
void resize(size_t n, char ch = '\0');
void shrink_to_fit();
string& operator+=(char ch);
string& operator+=(const char* str);
void insert(size_t pos, char ch);
void insert(size_t pos, const char* str);
void erase(size_t pos, size_t len = npos);
size_t find(char ch, size_t pos = 0);
size_t find(const char* str, size_t pos = 0);
string substr(size_t pos = 0, size_t len = npos);
bool operator<(const string& s) const;
bool operator<=(const string& s) const;
bool operator>(const string& s) const;
bool operator>=(const string& s) const;
bool operator==(const string& s) const;
bool operator!=(const string& s) const;
void swap(string& s);
void clear();
private:
char* _str;
size_t _size;
size_t _capacity;
public:
const static size_t npos;
};
ostream& operator<<(ostream& out, const string& s);
istream& operator>>(istream& in, string& s);
istream& getline(istream& in, string& s);
}
2. string各种接口函数
构造函数
构造函数设置为缺省参数,若不传入参数,则默认构造为空字符串。字符串的初始大小和容量均设置为传入的字符串的长度
//声明和定义分离的写法
string::string(const char* str)//声明和定义分离时声明留缺省值
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
析构函数
当对象销毁时堆区对应的空间并不会自动销毁,为了避免内存泄漏,所以我们需要使用delete释放堆区的空间。
string::~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
拷贝构造
浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
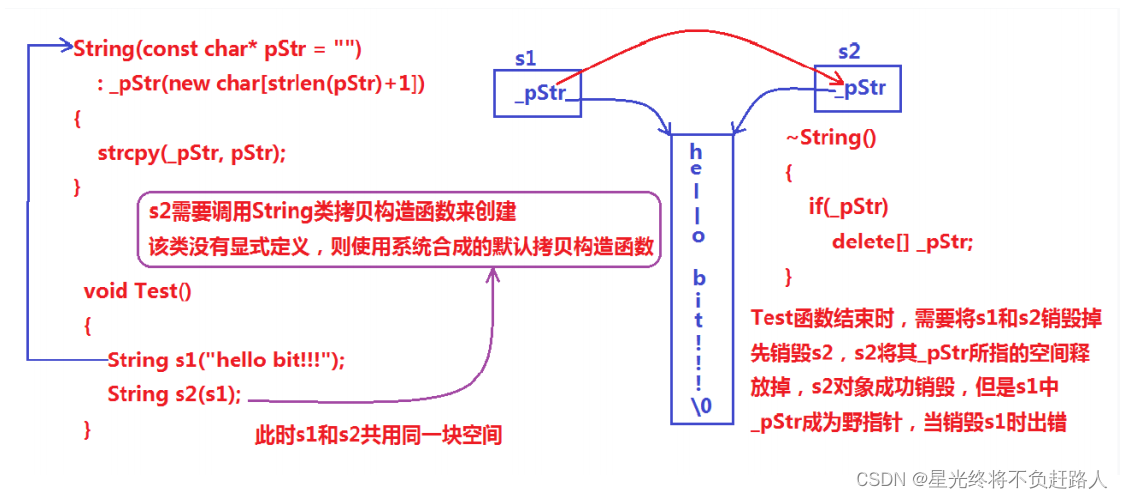
String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
深拷贝
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供。
即:每个对象都有一份独立的资源,不要和其他对象共享。

写法一:传统写法
先开辟一块空间,然后拷贝数据过去,接着把源对象的其他成员变量也赋值过去。
string::string(const string& s)
:_size(s._size)
, _capacity(s._capacity)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
}
写法二:现代写法
先根据源字符串的C字符串调用构造函数构造一个tmp对象,然后再将tmp对象与拷贝对象的数据交换即可,这里注意_str要初始化为空指针,因为交换后会析构tmp,释放空指针时没问题的,而释放随机值就会报错。
string::string(const string& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);
}
赋值重载
写法一:传统写法
先开一块新空间,然后在拷贝旧数据,再释放掉旧空间,这里尽量是先开空间再释放,避免我们开空间失败导致原始数据的丢失。
string& string::operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
写法二:现代写法
拷贝构造函数的现代写法是通过调用构造函数构造出一个对象,然后将该对象与拷贝对象交换。
string& string::operator=(string s)
{
swap(s);
return *this;
}
swap
swap函数用于交换两个对象的数据,这里我们只需要交换两对象的指向,同时改变_size和_capacity的大小就可以了。
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
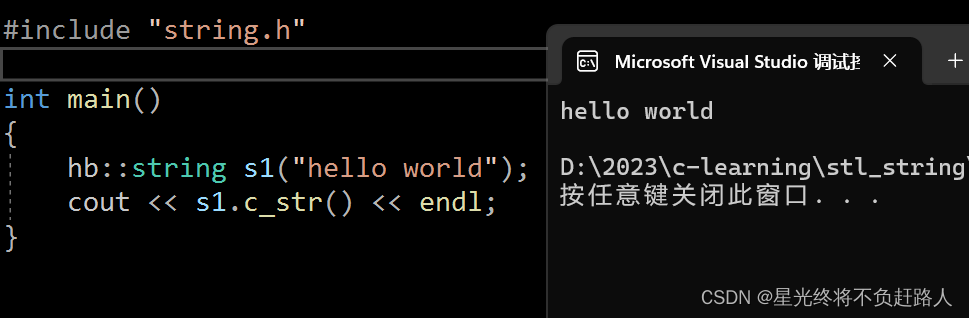
获取C类型字符串
const char* string::c_str() const
{
return _str;
}
运行结果如图:
求长度和容量
因为string类的成员变量是私有的,所以不能直接进行访问它的私有成员,所以string类设置了size( )和capacity( )这两个成员函数,用来获取string对象的大小和容量。
size函数用于获取字符串当前的有效长度
size_t string::size() const
{
return _size;
}
capacity函数用于获取字符串当前的容量。
size_t string::capacity() const
{
return _capacity;
}
访问字符串相关函数
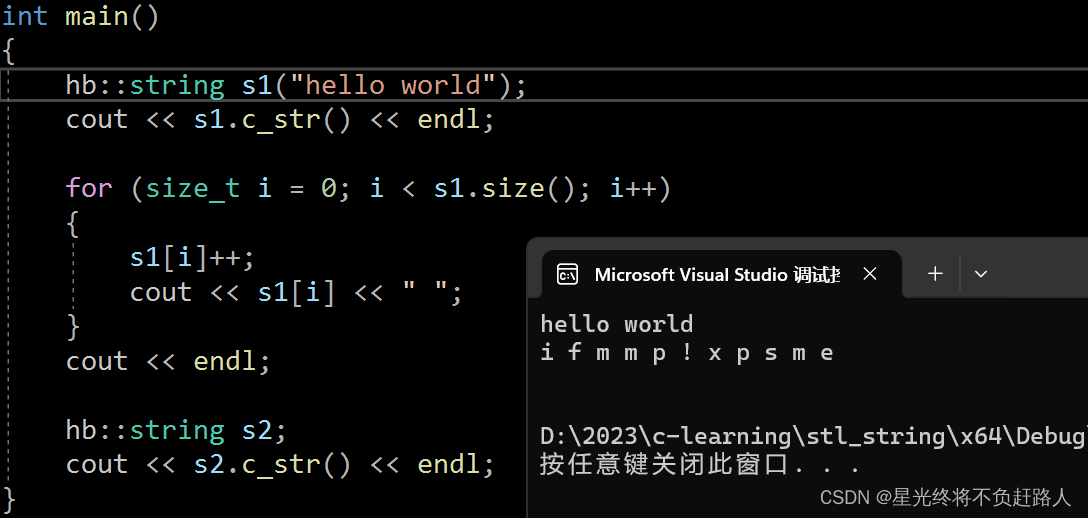
[ ]运算符的重载是为了支持像C字符串和数组一样,通过[ ] +下标的方式访问对应位置的元素。
我们可以通过[ ] +下标的方式可以获取字符串对应位置的字符,并可以对其进行修改,只需要在实现[ ] 运算符的重载时返回string对象_str指向对应位置字符的引用即可,但需要注意下标不能越界。
//operator[](可读可写)
char& string::operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
运行结果如图:
在某些场景下,我们可能只能用[ ] +下标的方式读取字符而不能对其进行修改,所以可以重载一个const版本。
//[]运算符重载(只读)
const char& string::operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
迭代器相关函数
string类中的迭代器有两种实现方法:一种是自定义类型,后面链表讲,一种用原生指针实现,实际上就是字符指针,只是给字符指针起了一个别名叫iterator而已。
// 封装:屏蔽了底层实现细节,提供了一种简单通用访问容器的方式
typedef char* iterator;
typedef const char* const_iterator;
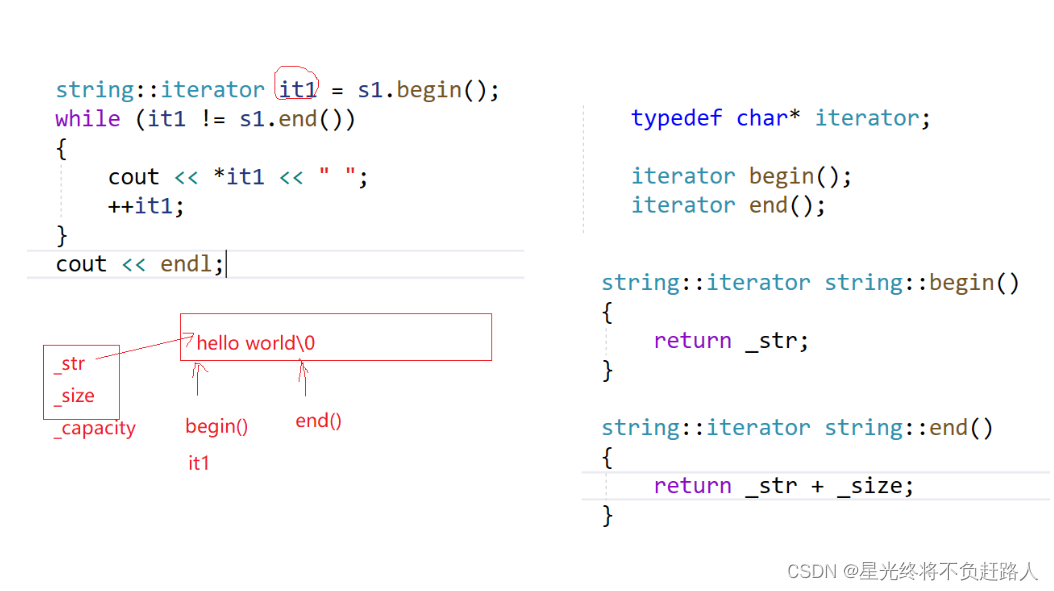
begin和end
string类中的begin和end函数很简单,begin函数用来返回字符串中第一个字符的地址
string::iterator string::begin()
{
return _str;
}
string::const_iterator string::begin() const
{
return _str;
}
end函数的作用就是返回字符串中最后一个字符下一个字符的地址(即末尾 \0 的地址)
string::iterator string::end()
{
return _str + _size;
}
string::const_iterator string::end() const
{
return _str + _size;
}
如图所示:
运行结果如图:
reserve和resize
reserve函数通常用来扩容,但是注意一般只有当新的容量大于当前容量时才执行。
void string::reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
new char[n+1] 是用来分配足够的内存来存储 n 个字符和一个额外的字符(存储\0),然后再把原来的字符串拷贝到新的空间中,然后释放旧空间,并使原来的指针指向新空间,最后修改capacity为n
resize规则:
1、当n大于当前的size时,将size扩大到n,扩大的字符填充为ch,ch的默认值为’\0’。
2、当n小于当前的size时,将size缩小到n。
void string::resize(size_t n, char ch)
{
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
while (_size < n)
{
_str[_size] = ch;
_size++;
}
_str[_size] = '\0';
}
}
shrink_to_fit
shrink_to_fit函数用于缩容到_size位置,用的比较少,首先,开_size大小空间,拷贝数据,释放旧空间,改变容量大小到_size。
void string::shrink_to_fit()
{
char* tmp = new char[_size + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;//这里我经常忘写,大家也要注意
_capacity = _size;
}
push_back 和 append
push_back函数就是在字符串的末尾插上一个字符,尾插之前需要判断是否需要增容,如果需要,调用reserve函数进行增容,然后再尾插字符,注意尾插完字符后需要在末尾增加’\0’同时_size++
void string::push_back(char ch)
{
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
append函数就是在当前字符串末尾插一个字符串,尾插前需要判断当前字符串的空间能否够尾插后的字符串,如果不行,就需要先进行增容,然后再在进行尾插,因为尾插的字符串后方有’\0’,所以直接用strcpy就可以,注意_size要变成_size + len
void string::append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
运行结果如图:
operator+=
+=运算符的重载是为了实现字符串与字符、字符串之间能够直接使用+=运算符进行尾插。
+=运算符实现字符串与字符之间的尾插直接复用push_back函数即可。
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
+=运算符实现字符串与字符串之间的尾插直接复用append函数即可。
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
运行结果如图:

insert
insert函数是用来在字符串的任意位置插入字符或字符串。
首先需要判断pos在有效范围内,然后还需判断string对象能否容纳插入字符后的字符串,如果不能就需调用reserve函数进行扩容,插入一个字符时需要从最后一个位置开始往后挪动一位直到把pos位置挪动后结束。

方法一:
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
for (int i = _size; i >= (int)pos; i--)
{
_str[i + 1] = _str[i];
}
_str[pos] = ch;
_size++;
}
方法二:(推荐)
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
for (size_t i = _size + 1; i > pos; i--)
{
_str[i] = _str[i - 1];
}
_str[pos] = ch;
_size++;
}
运行结果如图:

首先需要判断pos在有效范围内,然后还需判断string对象能否容纳插入字符后的字符串,如果不能就需调用reserve函数进行扩容,插入字符串时需要从最后一个位置开始往后挪动 len 个长度直到把pos位置挪动后结束,然后将其插入字符串即可。
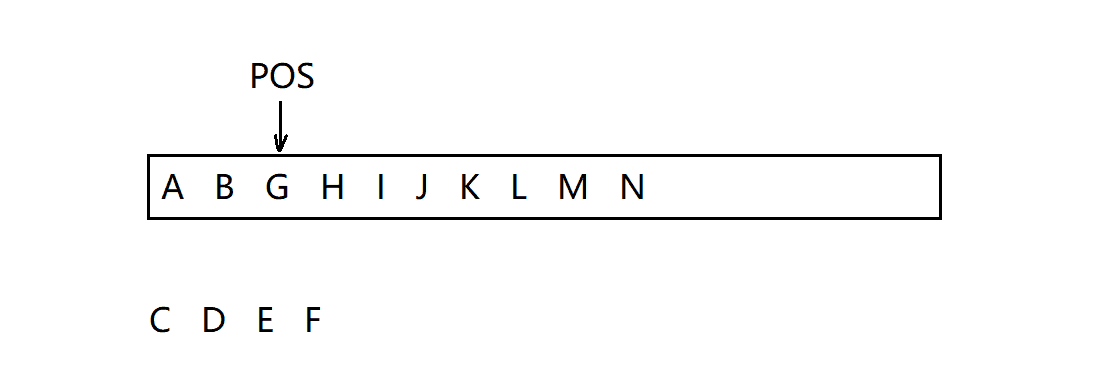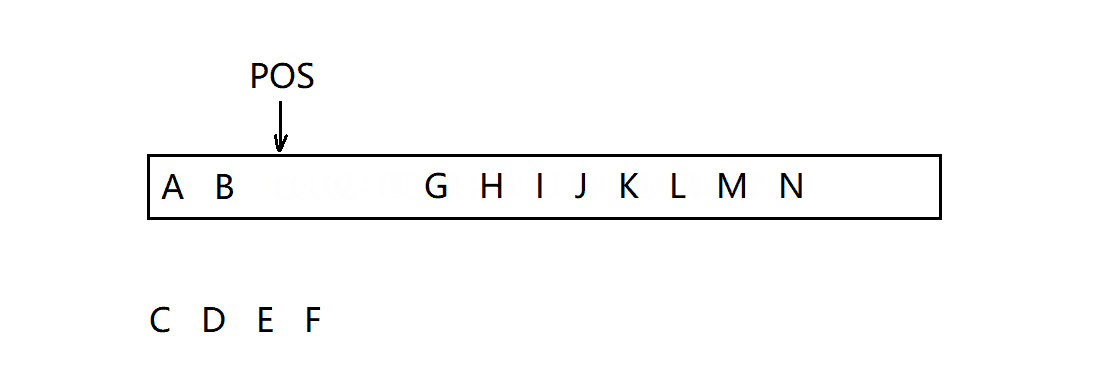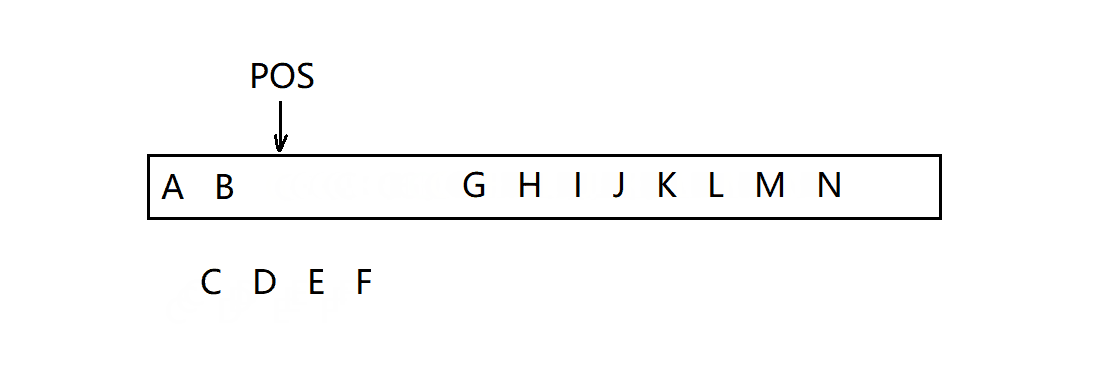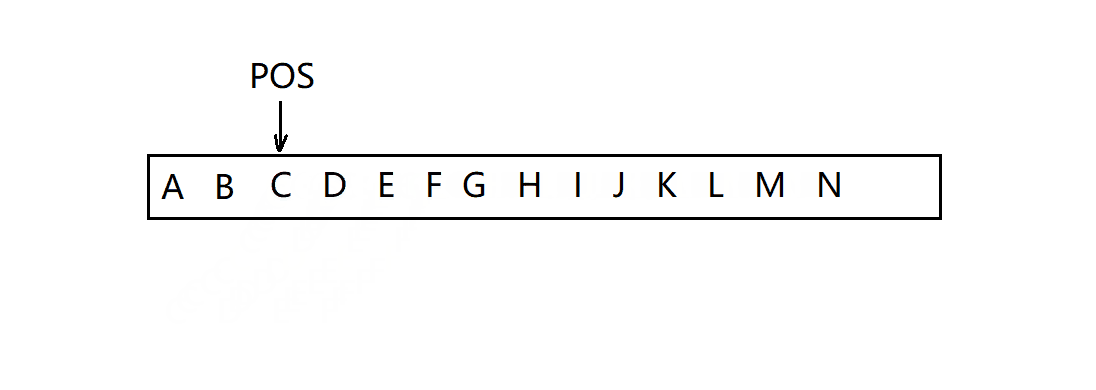
方法一:
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
int len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
for (int i = _size; i >= (int)pos; i--)
{
_str[i + len] = _str[i];
}
strncpy(_str + pos, str, len);
_size += len;
}
方法二:
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
int len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
/*for (size_t i = _size + len; i > pos + len - 1; i--)
{
_str[i] = _str[i - len];
}*/
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
}
运行结果如图:

erase
erase函数用来删除字符串任意位置开始的n个字符。首先,需要判断pos的合法性,删除的时候分两种情况:
- 从pos位置开始后面的字符全部被删除。
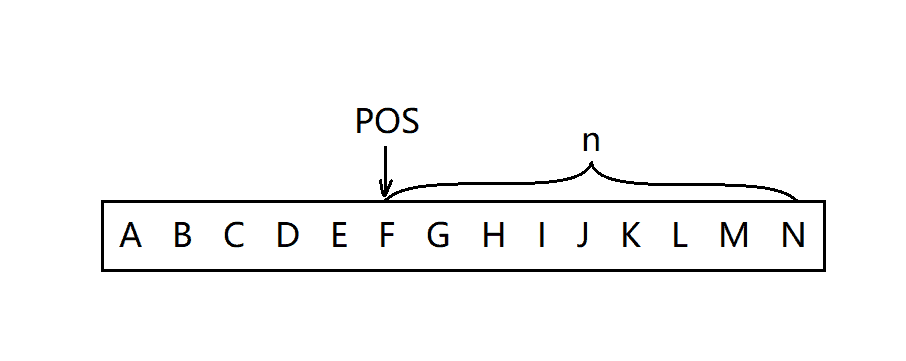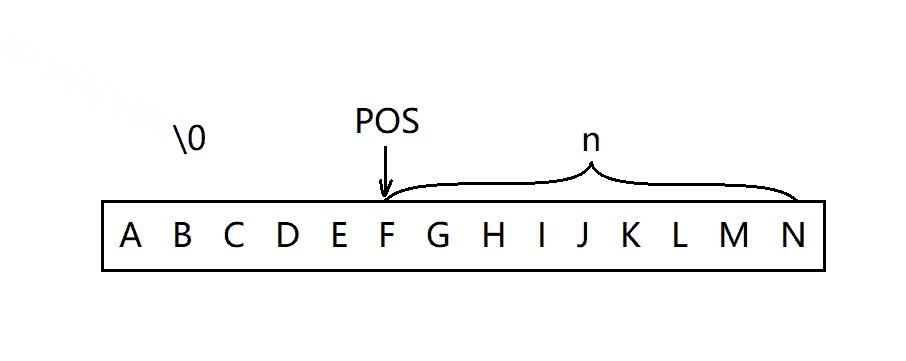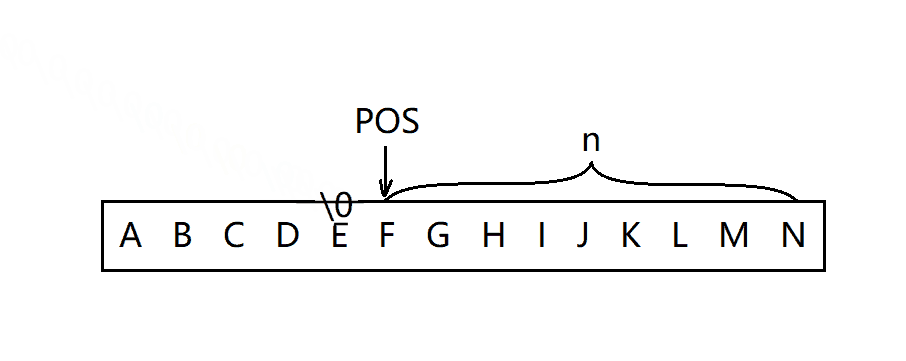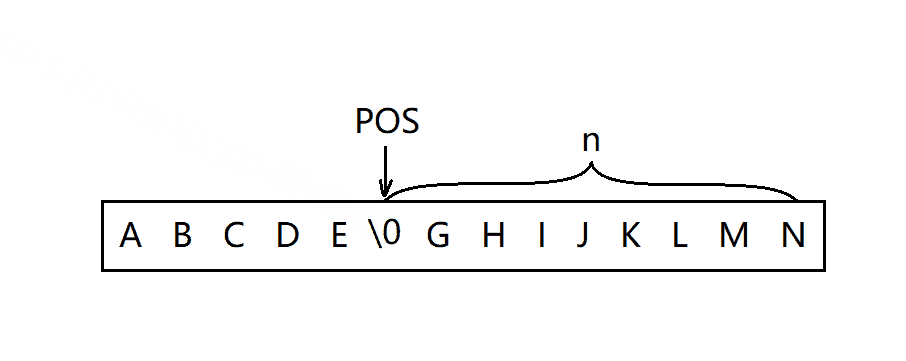
- 只需删除从pos位置开始的一部分字符。

void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_size = pos;
_str[_size] = '\0';
}
else
{
//strcpy(_str + pos, _str + pos + len);
for (size_t i = pos + len; i <= _size ; i++)
{
_str[i - len] = _str[i];
}
_size -= len;
}
}
find
find函数用于在字符串中查找一个字符或字符串
1、查找第一个匹配的字符。
从pos位置开始向后寻找目标字符,如果找到,就返回其下标;如果没有找到,就返回npos。
size_t string::find(char ch, size_t pos)
{
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
2、查找第一个匹配的字符串。
这里可以使用strstr函数查找,strstr函数若是找到了目标字符串会返回字符串的起始位置,若是没有找到会返回一个空指针。

size_t string::find(const char* str, size_t pos)
{
const char* tmp = strstr(_str + pos, str);
if (tmp != nullptr)
{
return tmp - _str;
}
return npos;
}
运行结果如图:
substr
substr函数用来从字符串中提取出一个子字符串
方法一:
string string::substr(size_t pos, size_t len)
{
string s;
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
len = _size - pos;
end = _size;
}
reserve(len);
for (size_t i = pos; i < end; i++)
{
s += _str[i];
}
return s;
}
方法二:
string string::substr(size_t pos, size_t len)
{
if (len == npos || pos + len >= _size)
{
string sub(_str + pos);
return sub;
}
else
{
string sub;
sub.reserve(len);
for (size_t i = pos; i < pos + len; i++)
{
sub += _str[i];
}
return sub;
}
}
关系运算符重载函数
关系运算符总共有 >、>=、<、<=、==、!= 这六个,但是对于C++中任意一个类的关系运算符重载,我们只需重载其中 >,= 或者 <,= 剩下的四个关系运算符可以通过复用已经重载好了的两个关系运算符来实现。
bool string::operator<(const string& s) const
{
return strcmp(_str, s._str) < 0;
}
bool string::operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool string::operator<=(const string& s) const
{
return *this < s || *this == s;
}
bool string::operator>(const string& s) const
{
return !(*this <= s);
}
bool string::operator>=(const string& s) const
{
return !(*this < s);
}
bool string::operator!=(const string& s) const
{
return !(*this == s);
}
>>和<<运算符的重载
<<运算符的重载,直接把string对象的字符串依次输出就可以了
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); i++)
{
cout << s[i];
}
return out;
}
>>运算符的重载,在输入前需要我们清空原来string对象的字符串,然后从标准输入流读取字符,直到读取到空格或是换行便停止读取。
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
getline
getline函数用于读取一行含有空格的字符串,当读取到’\n’的时候才停止读取字符。
istream& getline(istream& in, string& s)
{
s.clear();
char ch = in.get();
while (ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
运行结果如图:
3. 全部代码实现
#include "string.h"
namespace hb
{
string::string(const char* str)
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
/*string::string(const string& s)
:_size(s._size)
, _capacity(s._capacity)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
}*/
string::string(const string& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);
}
//string& string::operator=(const string& s)
//{
// if (this != &s)//?
// {
// char* tmp = new char[s._capacity + 1];
// strcpy(tmp, s._str);
// delete[] _str;
// _str = tmp;
// _size = s._size;
// _capacity = s._capacity;
// }
// return *this;
//}
string& string::operator=(string s)
{
swap(s);
return *this;
}
string::~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
const char* string::c_str() const
{
return _str;
}
size_t string::size() const
{
return _size;
}
size_t string::capacity() const
{
return _capacity;
}
char& string::operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& string::operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
string::iterator string::begin()
{
return _str;
}
string::iterator string::end()
{
return _str + _size;
}
string::const_iterator string::begin() const
{
return _str;
}
string::const_iterator string::end() const
{
return _str + _size;
}
void string::push_back(char ch)
{
/*if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';*/
insert(_size, ch);
}
void string::append(const char* str)
{
/*size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;*/
insert(_size, str);
}
void string::reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void string::resize(size_t n, char ch)
{
if (n <= _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
while (_size < n)
{
_str[_size] = ch;
_size++;
}
_str[_size] = '\0';
}
}
void string::shrink_to_fit()
{
char* tmp = new char[_size + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = _size;
}
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
const size_t string::npos = -1;
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
for (size_t i = _size + 1; i > pos; i--)
{
_str[i] = _str[i - 1];
}
_str[pos] = ch;
_size++;
}
//void string::insert(size_t pos, char ch)
//{
// assert(pos <= _size);
// if (_size == _capacity)
// {
// size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
// reserve(newcapacity);
// }
// for (int i = _size; i >= (int)pos; i--)
// {
// _str[i + 1] = _str[i];
// }
// _str[pos] = ch;
// _size++;
//}
//void string::insert(size_t pos, const char* str)
//{
// assert(pos <= _size);
// int len = strlen(str);
// if (_size + len > _capacity)
// {
// reserve(_size + len);
// }
// for (int i = _size; i >= (int)pos; i--)
// {
// _str[i + len] = _str[i];
// }
// strncpy(_str + pos, str, len);
// _size += len;
//}
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
/*for (size_t i = _size + len; i > pos + len - 1; i--)
{
_str[i] = _str[i - len];
}*/
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
}
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_size = pos;
_str[_size] = '\0';
}
else
{
//strcpy(_str + pos, _str + pos + len);
for (size_t i = pos + len; i <= _size ; i++)
{
_str[i - len] = _str[i];
}
_size -= len;
}
}
size_t string::find(char ch, size_t pos)
{
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t string::find(const char* str, size_t pos)
{
const char* tmp = strstr(_str + pos, str);
if (tmp != nullptr)
{
return tmp - _str;
}
return npos;
}
//string string::substr(size_t pos, size_t len)
//{
//
// if (len == npos || pos + len >= _size)
// {
// string sub(_str + pos);
// return sub;
// }
// else
// {
// string sub;
// sub.reserve(len);
// for (size_t i = pos; i < pos + len; i++)
// {
// sub += _str[i];
// }
// return sub;
// }
//}
string string::substr(size_t pos, size_t len)
{
string s;
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
len = _size - pos;
end = _size;
}
reserve(len);
for (size_t i = pos; i < end; i++)
{
s += _str[i];
}
return s;
}
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
bool string::operator<(const string& s) const
{
return strcmp(_str, s._str) < 0;
}
bool string::operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool string::operator<=(const string& s) const
{
return *this < s || *this == s;
}
bool string::operator>(const string& s) const
{
return !(*this <= s);
}
bool string::operator>=(const string& s) const
{
return !(*this < s);
}
bool string::operator!=(const string& s) const
{
return !(*this == s);
}
void string::clear()
{
_str[0] = '\0';
_size = 0;
}
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); i++)
{
cout << s[i];
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
istream& getline(istream& in, string& s)
{
s.clear();
char ch = in.get();
while (ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
}
测试代码实现
#include "string.h"
void test_string1()
{
hb::string s1("hello world");
cout << s1.c_str() << endl;
hb::string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
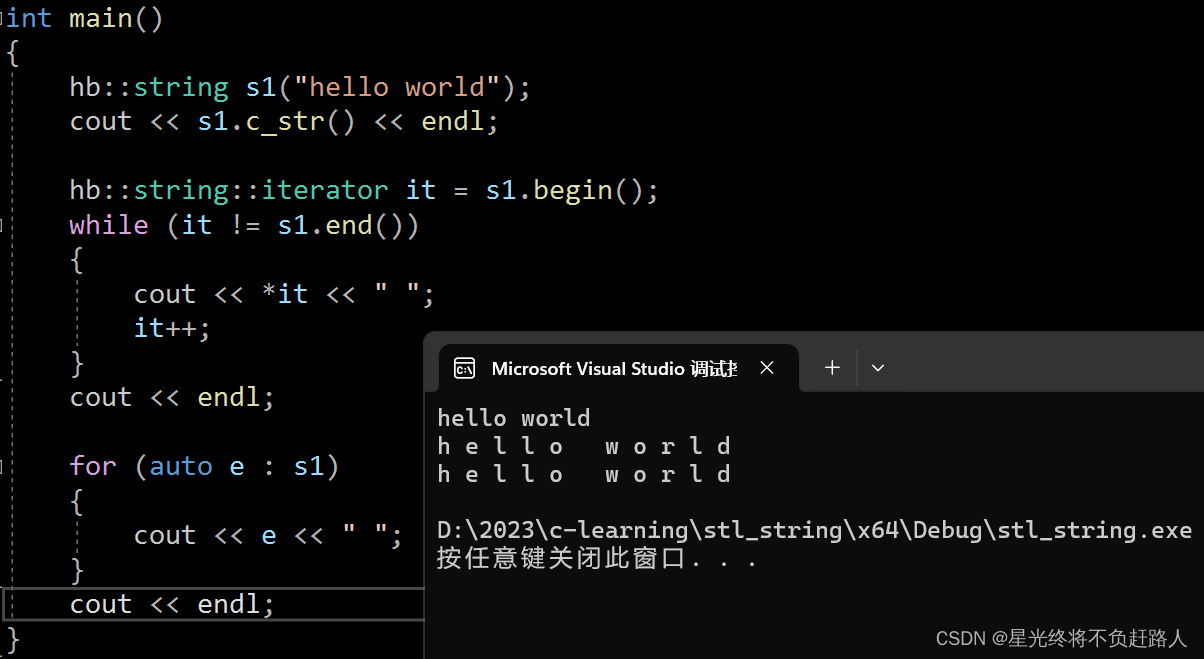
}
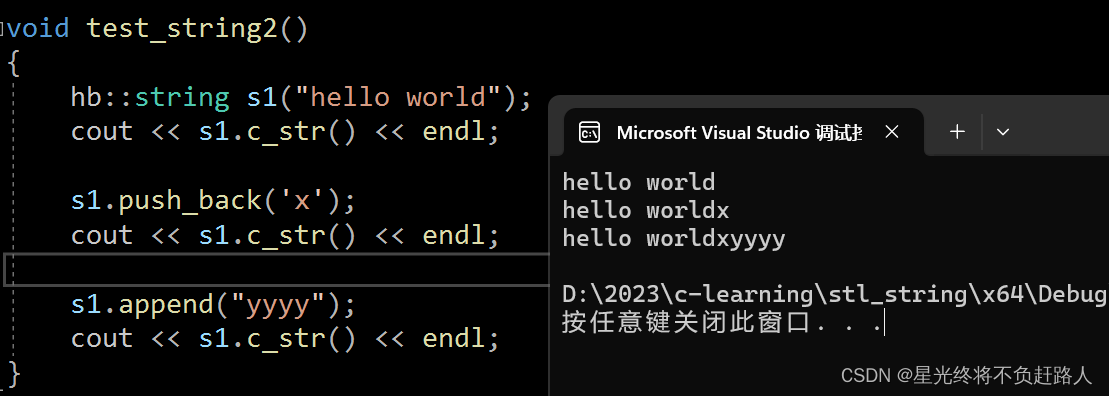
void test_string2()
{
hb::string s1("hello world");
cout << s1.c_str() << endl;
s1.push_back('x');
cout << s1.c_str() << endl;
s1.append("yyyy");
cout << s1.c_str() << endl;
s1 += 'm';
s1 += "nnn";
cout << s1.c_str() << endl;
}
void test_string3()
{
hb::string s1("hello world");
s1.push_back('x');
s1.append("xxx");
s1.insert(0, "yyy");
cout << s1.c_str() << endl;
}
void test_string4()
{
hb::string s1("hello world");
hb::string s2("hello world");
s1.erase(6);
cout << s1.c_str() << endl;
s2.erase(6, 3);
cout << s2.c_str() << endl;
}
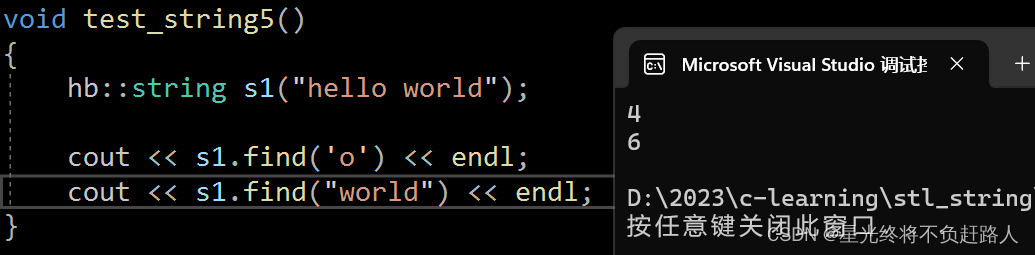
void test_string5()
{
hb::string s1("hello world");
cout << s1.find('o') << endl;
cout << s1.find("world") << endl;
}
void test_string6()
{
hb::string s1("hello world");
hb::string s2(s1);
s1[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
}
void test_string7()
{
hb::string s1("hello world");
hb::string s2("hhh");
s2 = s1;
s1[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
}
void test_string01()
{
//string s3 = "https://cplusplus.com/reference/string/string/rfind/";
hb::string s3 = "https://blog.csdn.net/qq_74319491/article/details/137381843?spm=1001.2014.3001.5501";
size_t i1 = s3.find(':');
hb::string sub1, sub2, sub3;
if (i1 != string::npos)
sub1 = s3.substr(0, i1);
size_t i2 = s3.find('/', i1 + 3);
if (i2 != string::npos)
sub2 = s3.substr(i1 + 3, i2 - i1 - 3);
size_t i3 = s3.find('/', i2 + 1);
if (i3 != string::npos)
sub3 = s3.substr(i2 + 1);
cout << sub1.c_str() << endl << sub2.c_str() << endl << sub3.c_str() << endl;
}
void test_string8()
{
hb::string s("hello world");
cin >> s;
cout << s << endl;
}
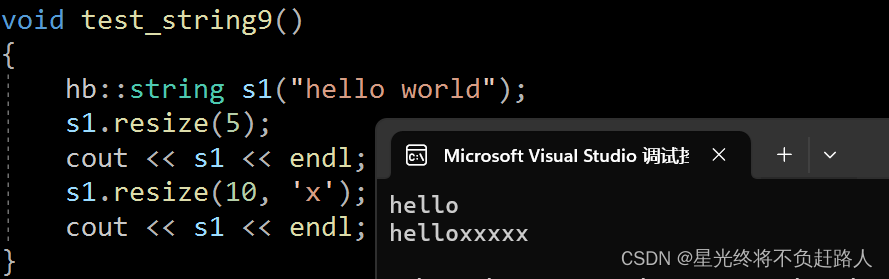
void test_string9()
{
hb::string s1("hello world");
s1.resize(5);
cout << s1 << endl;
s1.resize(10, 'x');
cout << s1 << endl;
}
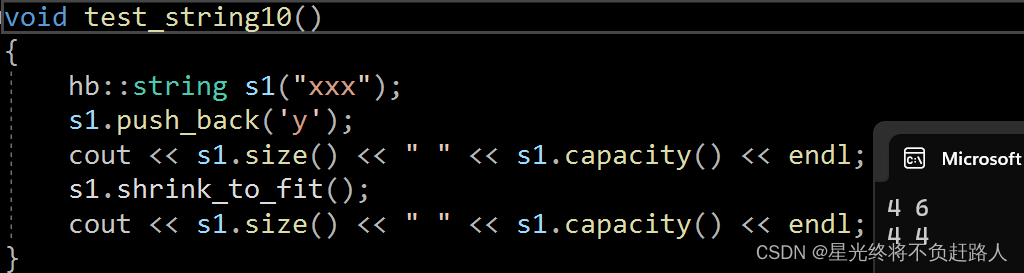
void test_string10()
{
hb::string s1("xxx");
s1.push_back('y');
cout << s1.size() << " " << s1.capacity() << endl;
s1.shrink_to_fit();
cout << s1.size() << " " << s1.capacity() << endl;
}
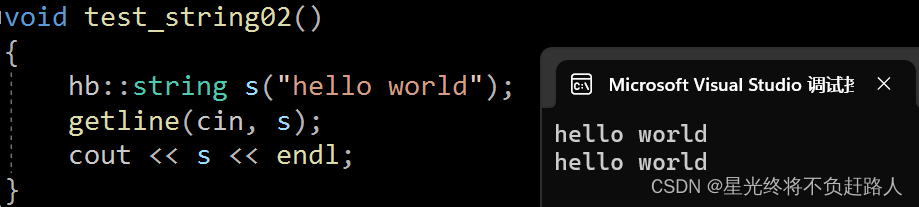
void test_string02()
{
hb::string s("hello world");
getline(cin, s);
cout << s << endl;
}
int main()
{
test_string02();
return 0;
}




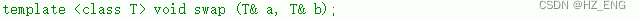



























![[力扣题解] 96. 不同的二叉搜索树](https://img-blog.csdnimg.cn/direct/a16c9c76eab2463d8055367737afdc32.png#pic_center)