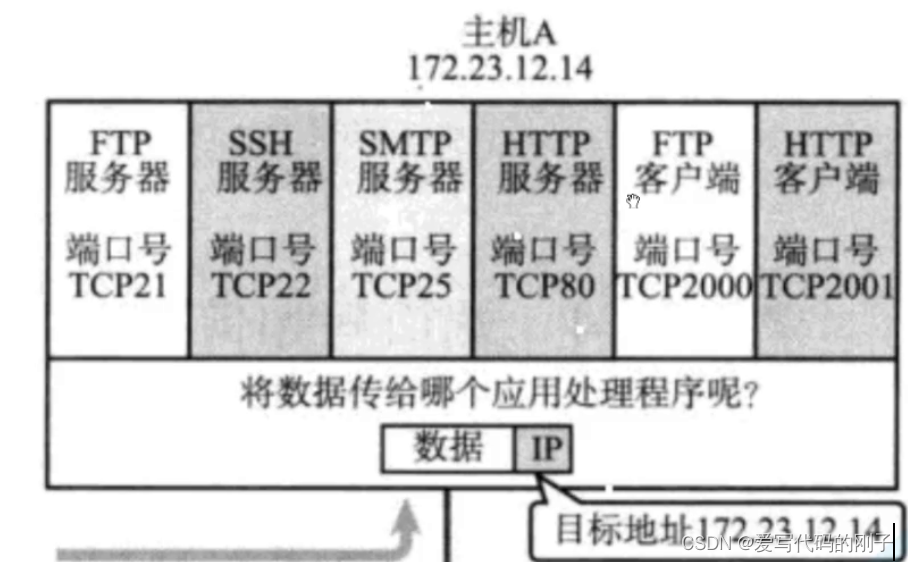
更多关于Selenium的知识请访问“兰亭序咖啡”的专栏:专栏《Selenium 从入门到精通》
文章目录
前言
如何定位一个XML(尤其是HTML)中的一个节点?前文我们学习了Selenium的常用的几种选择器,相比其它几种比较简单的比如id选择器、name选择器等外,最强大也是我们使用最频繁的是xpath选择器。
本文,我们就对xpath进行全面的学习。
一、什么是xpath?
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。(简单说就是在一个庞大复杂的XML中找到一个特定节点)
而我们的 HTML 就是一种特殊的XML。所以 XPath 当然也可以用来对 HTML 元素和属性进行遍历。
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
/html/body/div[1]/div[2]/div[1]/input这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
/usr/local/apache/log/二、XPath 节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及根节点。
下面我们对每种节点介绍。
XPath 是对 XML 的操作,但是我们用得比较多的是 HTML,所以下面的代码都会以 HTML 来演示。
<html xmlns:example="http://www.example.com">
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<!-- 测试 HTML -->
<h1 name="header">我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>对于上面的代码:
- <html> 就是根节点
- 每个标签都是一个元素,比如:<h1>我的第一个标题</h1>
- <h1 name="header">中的name=“header”就是一个属性
- <p>我的第一个段落。</p> 中的“我的第一个段落。”就是文本
- <html xmlns:example="http://www.example.com">中的namespace就是命名空间
- <!-- 测试 HTML -->就是一个注释
- 处理指令一般不怎么常用,如果在Vue中<div v-if="show">会比较常见。
特别注意:节点和元素的区别:
- 节点是很广泛的概念,包括了元素、属性、文本、命名空间、处理指令、注释以及根节点
- 元素只是节点的一种,属性也是一种节点,元素通常是html标签对!
- 后面会介绍 * 表示所有元素,而node()表示任意节点。
三. 节点的关系
人和人之间有关系,比如父子,兄弟等,节点同样有这些关系。
这些关系可以帮我们定位一个节点。
1. 父(Parent)
每个元素都只有一个父节点。
- coffe的父节点是list
- list的父节点是drink
但是注意:coffe只有一个父节点,drink不是coffe的父节点。
<div class="food">
<div class="drink">
<ol class="list">
<li item="coffe">Coffee</li>
<li item="tea">Tea</li>
<li item="milk">Milk</li>
</ol>
</div>
</div>2. 子(Children)
每个节点都有零个、一个或多个子节点。
- food的子节点是drink
- list的子节点有3个,分别是coffe、tea和milk
- coffe没有子节点
特别注意:coffe不是food和drink的子节点。
<div class="food">
<div class="drink">
<ol class="list">
<li item="coffe">Coffee</li>
<li item="tea">Tea</li>
<li item="milk">Milk</li>
</ol>
</div>
</div>3. 同胞(Sibling)
拥有相同父节点的节点。
- coffe、tea、milk他们的父节点都是list,所以他们是同胞节点。
- drink只有list一个子节点,所以list没有同胞节点。
<div class="food">
<div class="drink">
<ol class="list">
<li item="coffe">Coffee</li>
<li item="tea">Tea</li>
<li item="milk">Milk</li>
</ol>
</div>
</div>4. 先辈(Ancestor)
某节点的父、父的父……
- coffe的先辈节点有list、drink和food
<div class="food">
<div class="drink">
<ol class="list">
<li item="coffe">Coffee</li>
<li item="tea">Tea</li>
<li item="milk">Milk</li>
</ol>
</div>
</div>5. 后代(Descendant)
某个节点的子,子的子,等等。
- food的后代节点有drink、list,还有coffe、tea、milk
<div class="food">
<div class="drink">
<ol class="list">
<li item="coffe">Coffee</li>
<li item="tea">Tea</li>
<li item="milk">Milk</li>
</ol>
</div>
</div>四. 路径表达式
XPath 使用路径表达式在 XML 文档中选取节点。
| 路径表达式 | 作用 | 示例 |
|---|---|---|
| nodename | 选取此节点的所有子节点。 | input:选择所有<input>节点的所有子节点。 |
| / | 从根节点选取。 也就是绝对路径。 |
/html:选择根节点,网页的根节点都是<html>节点。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 也就是相对路径。 |
//input:选中所有<input>节点。 |
| . | 选取当前节点。 | |
| .. | 选取当前节点的父节点。 | |
| @ | 选取属性。 | //@id:选中所有有id属性的节点。 |
| * | 匹配任何元素 | //*:任意元素的节点 //@*:属性为任意值的节点,换句话说就是有属性的节点,比如<html>和<body>这种节点不会被选中。 |
| node() | 匹配任何类型的节点 (特别区别*,元素是特殊的节点,属性也是节点) |
//node():选中任意节点 |
| | | 使用“|”运算符,可以选取若干个路径。也就是或 | //input | //ul:选中所有的<input>或者<ul>节点 |
是不是和 Linux 的路径语法很类似!区别在于一个是选择目录,一个是选择节点!
//div/span 和 //div//span 有什么区别?(非常重要)
- //div/span:选择div元素的子节点中的span
- //div//span:选择div元素的后代节点中的span
比如对于下面的html,使用“//div/span”只能选中一个span,但是使用"//div//span"可以选中两个span!
<div>
<span>Hello<span>
<ul>
<span>World</span>
</ul>
<div>节点和元素的区别?(特别重要)
以 * 和 node()为例:
- //*:选中了5个元素:(5) [html, head, title, body, div.box]
- //node():选中了8个节点:(8) [<!DOCTYPE html>, html, head, title, text, body, div.box, text]
<!DOCTYPE html>
<html>
<head>
<title>预定</title>
</head>
<body>
<div class="box">Hello</div>
</body>
</html>五. 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
是不是不太好理解。
其实,我们学习中文或者英文语法的时候,也接触过 主+谓+宾语 的结构,这和XPath的谓语很类似。
谓语(Predicate) 是对主语动作状态或特征的陈述或说明,指出"做什么(what to do)" , "是什么(what is this)"。
谓语动词的位置一般在主语之后, 经常用动词和形容词搭配来充当谓语动词。
比如:
- 选择div的第二个子节点
- 选择有id属性的div节点
- 数值大于35的节点
- ……
有了这些谓词,我们可以更精确的定位到特定的节点!
六. 轴(Axes)
前面介绍了节点之间的关系,比如父子关系、兄弟关系等。
Xpath 使用轴 定义了节点与当前节点之间的关系,相当于节点的运动路径。每一个轴都有一个基本节点类型。
在 XPath 中,我们使用轴(如 child、parent、attribute 等)来定位节点。
用关系来定位节点!
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
语法规则:
轴名称::节点测试[谓语]
下面列举一些实例来说明!!!
| 例子 | 结果 |
|---|---|
| //div//child::input | 选取所有属于div节点的子元素的 input 节点。 不过直接用简单的写法就行了://div//input |
| //input//attribute::id | 选取所有input节点的 id 属性。(属性也是一种节点!) 比如<input id="username" name="uname"> |
| //ul//child::* | 选取当前节点的所有子元素。(因为使用了//相对路径, 所以是所有后代节点) 如果 //ul/child::* 因为是 / 绝度路径, 所以选中所有子节点。 |
| //input//attribute::* | 选取input节点的所有属性。 <input id="username" name="uname" class="big"> |
| //a//child::text() | 选取a节点的所有文本子节点。 简单写法://a/text() 比如:<a>测试</a> <a>Hello</a> |
| //a//child::node() | 选取a节点的所有子节点。(注意是节点,所以也包括元素,而且使用的//相对,所以所有后代的节点) |
| //ul//descendant::input | 选取ul节点的所有 input 后代节点。 |
| //input//ancestor::li | 选择input节点的所有 li 先辈节点。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| //ul/child::*/child::input | 选取ul节点的所有 input 孙节点。 相当于://ul/*/inut |
所有的child::XXX 都可以直接写XXX
比如://a//child::text() --> //a//text()
//div//child::input --> //div//input
七. XPath 示例
1. 绝对路径
/html/body/div[2]/top-menu/header/div/div[1]/h1/a/img2. 所有位置元素
//div //任意div节点
//div//img /*div的所有img后代*/3. 使用谓语
//ul//li[1] /*选择第一个*/
//ul//li[position() = 1] /*多种写法*/
//ul//li[last()] /*选择最后一个*/4. 通过@根据属性筛选
//@jscontent /*所有带jscontent属性的节点*/
//span[@jscontent] /*所有带jscontent属性的span节点*/
//span[@*] /*所有带任意属性的span节点*/
//div[not(@*)] /*没有任何属性的div节点*/
//div[not(@id)] /*没有id属性的div节点*/5. 通过属性值筛选
//span[@class='currency']
//span[normalize-space(@class)='currency'] /*去掉前后空格后再比较*/6. 元素计数器
//ul[count(li)=5] /*有5个li的ul*/
//*[count(*)=3] /*有3个子元素的任意节点*/7. 根据标签名筛选
//*[name()='span'] /*等同于//span*
//span
//*[starts-with(name(), 'scri')] /*标签名以scri开头的标签*/
//*[contains(name(), 'pt')] /*标签名包含pt的标签*/8. 函数—包含 contains
//div[contains(@class, 'rowFlightItem')]如果使用全匹配是获取不到的//div[@class, 'tripselector_inbound'] 除非//div[@class, 'tripselector_inbound ng-star-inserted']
但是要特别注意,模糊匹配可能会匹配到不期望的对象
//flight//div[contains(@class, 'row')]
9. 函数—字符串长度
//*[string-length(name()) = 3] /*标签名字为3个字符串的节点,比如div,img*/10. 逻辑或
//ul | //button /*ul标签或button*/11. 轴
//div//child::ul /*选择子节点是ul的div*/
//div/ul /*简洁写法*/注意child和descendant的区别,一个儿子,一个是后代。儿子也是后代
后代节点轴
//div//descendant::* /*选择div下面的所有元素*/
//div//*后面的兄弟节点
//ul//li/following-sibling::* /*ul下第一个后面的子节点!*/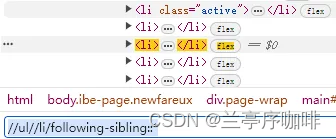
12. 根据符合条件的子节点选父节点
//table[.//th[@scope="colgroup" and normalize-space(.)="成人"]]
.//tr[contains(@class, 'taxesOrFees-tr') and (.//td)] /*子节点有td的tr*/<table class="table">
<caption class="">Departure flight - adult prices resume table</caption>
<tbody>
<tr class="colgroup_title">
<th colspan="2" scope="colgroup">成人</th>
</tr>八. Selenium 中使用XPath
使用非常简单,就是By.xpath()方法即可:
WebElement element = driver.findElement(By.xpath("//input[@id='username']"));总结
以上就是今天要讲的内容,本文系统全面的介绍了Xpath,从什么是Xpath讲起,到Xpath的基本概念,最后到语法和实战!相信这会让你在使用 Selenium 时如虎添翼!关注兰亭序咖啡的博客,我们一起对 Selenium 学习和探讨!