万字长文警告!!!
目录
2.4.2 Spark Streaming与Storm的对比
2.4.3 从“Hadoop+Storm”架构转向Spark架构
5.7 编写Spark Streaming程序使用Kafka数据源
一、离线计算与流式计算
1.1 离线计算
离线计算是指在数据处理和分析中,数据不是实时或即时处理的,而是先被收集和存储起来,然后按照预定的时间间隔或基于特定事件触发进行批量处理的过程。离线计算通常用于处理大数据,因为它允许系统在处理之前累积大量数据,从而提高数据处理的效率和准确性。
1.1.1 离线计算的特点
批量处理:离线计算通常涉及对大量数据的批量处理,而不是对单个数据记录的即时响应。
时间间隔:数据处理按照一定的时间间隔进行,如每小时、每天或每周等。
资源利用:离线计算可以在计算资源非高峰时段执行,从而更有效地利用硬件资源。
容错性:由于数据处理是批量进行的,离线计算通常具有更好的容错性,因为错误或失败可以在整个批次结束时进行处理。
复杂计算:离线计算可以执行更复杂的数据分析和机器学习算法,因为它们不需要即时响应。
1.1.2 离线计算的应用场景
数据分析:对历史数据进行深入分析,生成报告和洞察。
数据仓库:构建和管理数据仓库,支持企业决策。
机器学习训练:训练机器学习模型,通常需要大量数据和计算资源。
数据备份和归档:定期备份重要数据,并将其归档到长期存储中。
数据清洗和转换:对收集的数据进行清洗、转换和标准化,以便于分析。
1.1.3 离线计算代表技术
Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据
Sqoop: Apache Sqoop是一个用于在Hadoop和结构化数据存储(如关系型数据库)之间高效传输大量数据的工具。它主要用于两个方向的数据迁移:
- Import:从关系型数据库批量导入数据到Hadoop的HDFS(Hadoop Distributed File System)中。
- Export:将Hadoop HDFS中的数据批量导出到关系型数据库中。
HDFS (Hadoop Distributed File System): HDFS是Hadoop的核心组件之一,它是一个高度可靠的分布式文件系统,设计用于存储大量数据,并支持在廉价硬件上运行。HDFS允许批量存储数据,它将文件分割成多个块,并跨不同的节点存储这些块的副本,从而提供高吞吐量的数据访问。
MapReduce: Apache MapReduce是一个分布式计算模型和编程范式,用于在Hadoop上进行批量计算。它通过两个主要阶段来处理数据:
- Map阶段:处理输入数据并生成键值对(key-value pairs)。
- Reduce阶段:对Map阶段的输出进行汇总和归纳,生成最终结果。
MapReduce允许用户编写可以在分布式环境中并行运行的应用程序,以处理和分析大规模数据集。
Hive: Apache Hive是建立在Hadoop之上的一个数据仓库工具,它提供了一个类似于SQL的查询语言(HiveQL),用于在Hadoop上执行批量计算。Hive允许用户执行以下操作:
- 创建、修改和管理存储在HDFS或Hadoop兼容文件系统(如Amazon S3)中的大数据集。
- 执行批量数据查询,这些查询会被转换成MapReduce作业来执行。
通过Hive,用户可以无需编写复杂的MapReduce代码,就能进行数据汇总、查询和分析。
1.2 流式计算
流计算是一种数据处理模式,它可以处理无限流式数据,而不是一次性处理一组固定大小的数据集。在流计算中,数据是持续产生和处理的,系统可以实时地对数据进行处理、分析和响应。这种处理方式对于需要及时反馈和实时决策的应用场景非常有用,如实时监控、实时分析、实时推荐等。流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低!
即:实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
1.2.1 流式计算的特点
实时性:流式计算能够实时处理数据,通常在数据生成后不久就进行处理和分析。
连续性:数据被视为连续的流,而不是离散的批次。
无界性:与批处理不同,流式计算不假设数据集有明确的开始和结束。
容错性:流式计算系统通常设计为容错,即使在部分组件失败的情况下也能继续处理数据。
可伸缩性:流式计算框架能够水平扩展以处理数据量的增减。
低延迟:流式计算系统旨在减少数据处理的延迟,快速产生结果。
窗口操作:流式计算通常涉及窗口操作,允许对数据的滑动窗口或固定窗口进行操作。
1.2.2 流式计算的应用场景
实时分析:如实时监控网络流量、用户行为分析等。
事件驱动系统:如股票交易平台、在线广告投放系统等。
物联网(IoT):处理来自传感器的实时数据流。
实时推荐系统:根据用户行为实时更新推荐列表。
实时数据处理和监控:如日志处理、实时仪表板更新等。
1.2.3 流式计算的代表技术
Flume实时获取数据、Kafka实时数据存储、Storm/JStorm实时数据计算、Spark Streaming实时数据计算、Redis实时结果缓存、mysql持久化存储
Flume:
用于实时数据获取。Flume是Apache软件基金会下的顶级项目,是一个分布式、可靠且可用的系统,用于有效收集、聚合和移动大量日志数据。它从各种源(如日志文件、网络连接、消息队列等)捕获数据,并将数据传输到中央数据存储系统。Kafka:
用于实时数据存储。Apache Kafka是一个分布式流处理平台,主要用于构建实时数据管道和流式应用程序。它能够高效地处理高吞吐量的数据,并支持消息发布和订阅模型。Kafka充当消息队列,可以存储和传输这些数据,同时提供数据缓冲和流量控制。Storm/JStorm:
用于实时数据计算。Apache Storm是一个开源的实时计算系统,适用于处理无限数据流的实时数据处理场景。JStorm是Storm的一个Java版本,它提供了更低的延迟和更高的吞吐量。这些系统可以对Kafka中的数据进行实时处理和分析。Spark Streaming:
用于实时数据计算。Spark Streaming是Apache Spark项目的一个组件,它通过将数据流分割成一系列小批次,然后使用Spark的核心引擎对这些批次数据进行处理,从而实现了对数据流的批处理。Redis:
用于实时结果缓存。Redis是一个开源的内存数据结构存储系统,它可以用作数据库、缓存和消息代理。在实时数据处理中,Redis常用于缓存计算结果,因为它提供极高的读写速度。MySQL:
用于持久化存储。MySQL是一个关系型数据库管理系统(RDBMS),广泛用于持久化存储结构化数据。在实时数据处理架构中,MySQL可以用于存储经过实时处理和分析后的数据,以便于后续的查询、分析和报告。
流处理系统与传统的数据处理系统有如下不同:
- 流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据
- 用户通过流处理系统获取的是实时结果,而通过传统的数据处理系统,获取的是过去某一时刻的结果
- 流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户
流计算的处理流程一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务

二、Spark Streaming
2.1 什么是Spark Streaming
让我们把视线移到官方文档概述:
Spark Streaming 是核心 Spark API 的扩展,可实现缩放、高吞吐量、 实时数据流的容错流处理。可以从多个来源引入数据,例如Kafka、Kinesis 或 TCP 套接字,并且可以使用复杂的高级函数表示的算法,如map, reduce, join和window. 最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。

一言以蔽之:Spark Streaming是构建在Spark上的实时计算框架

2.2 Spark Streaming的基本原理
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据

2.3 Spark Streaming的数据抽象
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。

在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作
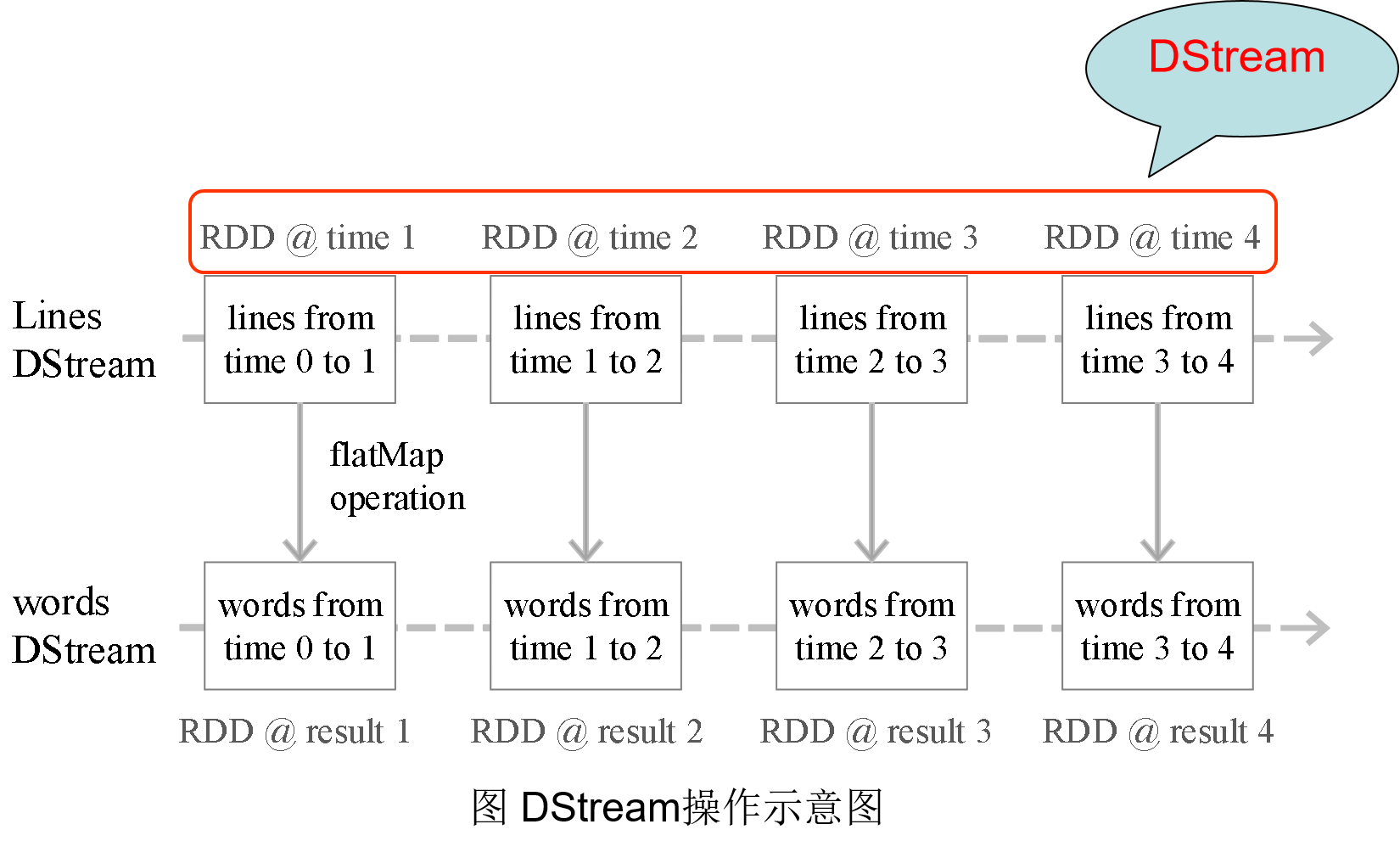
2.4 Spark Streaming与Storm的对比
2.4.1 什么是Storm
Apache Storm是一个开源的分布式实时计算系统,主要用于处理高吞吐量的数据流。它由Nathan Marz于2010年创建,并在2011年成为Twitter的一个开源项目。Storm的设计目标是能够提供高可靠性、可扩展性以及容错性,同时保证数据的准确性。
2.4.2 Spark Streaming与Storm的对比
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合

2.4.3 从“Hadoop+Storm”架构转向Spark架构


三、DStream操作概述
3.1 Spark Streaming工作机制

- 在Spark Streaming中,会有一个组件Receiver(接收数据),作为一个长期运行的task跑在一个Executor上
- 每个Receiver都会负责一个input DStream(比如从文件中读取数据的文件流,比如套接字流,或者从Kafka中读取的一个输入流等等)
- Spark Streaming通过input DStream与外部数据源进行连接,读取相关数据
3.2 Spark Streaming程序的基本步骤
- 1.通过创建输入DStream来定义输入源
- 通过对DStream应用转换操作和输出操作来定义流计算
- 用streamingContext.start()来开始接收数据和处理流程
- 通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)
- 可以通过streamingContext.stop()来手动结束流计算进程
3.3 创建StreamingContext对象
如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口,可以通过以下两种方式其一进行创建:
- 通过SparkConf对象创建一个StreamingContext对象:
val ssc= new StreamingContext(conf,Durations.seconds(5)) - 在pyspark中通过SparkContext对象创建:
>>> from pyspark.streaming import StreamingContext >>> ssc = StreamingContext(sc, 1)
如果是编写一个独立的Spark Streaming程序,而不是在pyspark中运行,则需要通过如下方式创建StreamingContext对象:
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 1)解释:初始化一个 Spark 应用程序和一个 Spark Streaming 上下文,为接下来的实时数据流处理做准备
from pyspark import SparkContext, SparkConf: 导入 SparkContext 和 SparkConf 类,它们是 PySpark 中用于配置和管理 Spark 应用程序的关键类。from pyspark.streaming import StreamingContext: 导入了StreamingContext 类,该类是 PySpark 中用于创建和管理实时流处理的主要类。conf = SparkConf(): 创建一个 SparkConf 对象,用于配置 Spark 应用程序的属性。conf.setAppName('TestDStream'): 设置 Spark 应用程序的名称为 "TestDStream"。应用程序名称是在 Spark UI 中显示的标识符。conf.setMaster('local[2]'): 设置 Spark 应用程序的运行模式为本地模式,使用了两个工作线程。本地模式是指应用程序将在本地计算机上运行,而不是在集群上运行。sc = SparkContext(conf=conf): 创建一个 SparkContext 对象,使用之前创建的 SparkConf 对象来初始化。ssc = StreamingContext(sc, 1): 创建一个 StreamingContext 对象,使用之前创建的 SparkContext 对象,并设置了批处理间隔为 1 秒。意味着 Spark Streaming 将每秒处理一次输入数据流。
四、基本输入源
4.1 文件流
4.1.1 在pyspark中创建文件流
mkdir -p sparksj/mycode/streaming/logfile
cd sparksj/mycode/streaming/logfile
进入pyspark创建文件流,打开一个终端窗口,启动进入pyspark
# 导入 SparkContext 类
>>> from pyspark import SparkContext
# 导入 StreamingContext 类
>>> from pyspark.streaming import StreamingContext
# 使用 SparkContext 对象创建 StreamingContext 对象,设置批处理间隔为10秒
>>> ssc = StreamingContext(sc, 10)
# 从文件系统中读取文本文件流,文件路径为 'file:///home/hadoop/sparksj/mycode/streaming/logfile'
>>> lines = ssc.textFileStream('file:///home/hadoop/sparksj/mycode/streaming/logfile')
# 将每行文本按空格拆分成单词
>>> words = lines.flatMap(lambda line: line.split(' '))
# 对每个单词进行映射为 (单词, 1) 的键值对,然后根据键(单词)进行聚合统计
>>> wordCounts = words.map(lambda x: (x, 1)).reduceByKey(lambda a, b: a + b)
# 打印每个时间间隔内计算出的单词统计结果
>>> wordCounts.pprint()
# 启动流式计算,开始接收数据并处理
>>> ssc.start()
# 等待流式处理终止(手动或由于任何错误)
>>> ssc.awaitTermination()
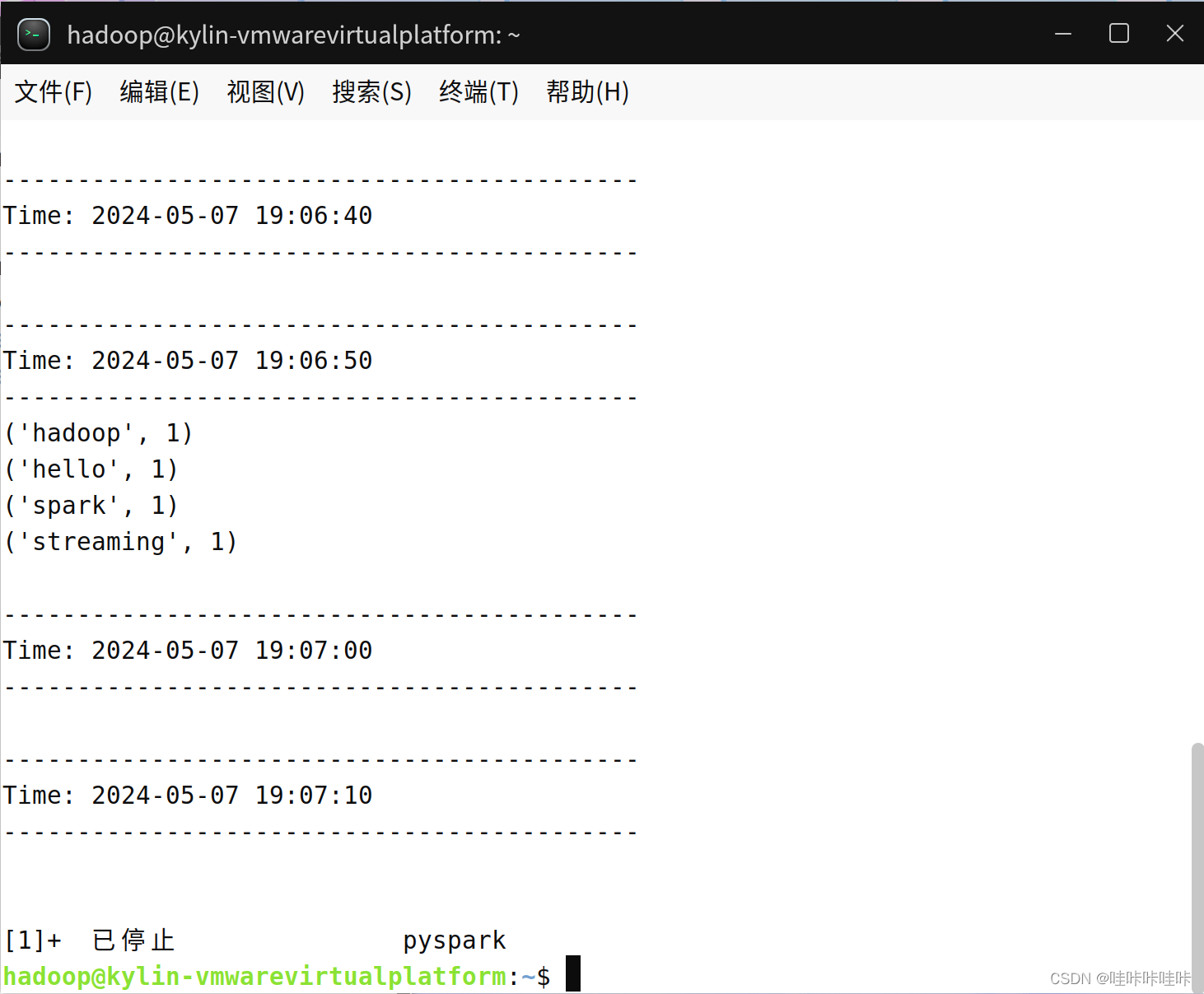
上面在pyspark中执行的程序,一旦你输入ssc.start()以后,程序就开始自动进入循环监听状态,屏幕上会显示一堆的信息,如下:
保持上述窗口正常运行(切勿关闭,保持打开状态),在"/home/hadoop/sparksj/mycode/streaming/logfile"目录下新建一个log.txt文件(文件名任意),就可以在监听窗口中显示词频统计结果:


如果读者手速没有那么快,因为屏幕上不断输出新的信息,导致读者无法看清楚单词统计结果是否已经被打印到屏幕上。所以现在必须停止这个监听程序,否则它一直在pyspark窗口中不断循环监听,停止的方法是,按键盘Ctrl+Z,或者Ctrl+C。停止以后,就彻底停止,并且退出了pyspark状态,回到了Shell命令提示符状态。然后,读者就可以看到屏幕上,在一大堆输出信息中,可以找到打印出来的单词统计信息。
!!!注意:
- 监听程序只监听"/home/hadoop/sparksj/mycode/streaming/logfile"目录下在程序启动后新增的文件,不会去处理历史上已经存在的文件
- 处理后,对当前窗口中的文件所做的更改不会导致重新读取该文件。 也就是说:更新将被忽略
4.1.2 采用独立应用程序方式创建文件流
cd sparksj/mycode/streaming/logfile
vim FileStreaming.pyfrom pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream('file:///home/hadoop/sparksj/mycode/streaming/logfile')
words = lines.flatMap(lambda line: line.split(' '))
wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
执行如下代码启动流计算(笔者已配置spark的环境变量,故无需进入spark安装目录执行"spark-submit FileStreaming.py"命令,若读者未配置环境变量可执行以下命令运行(以spark安装路径为/usr/local/spark为例):"/usr/local/spark/bin/spark-submit FileStreaming.py"):
cd sparksj/mycode/streaming/logfile
spark-submit FileStreaming.py文件内容与运行结果如下(同理,要停止监听按Ctrl+Z):

4.2 套接字流
Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应处理
4.2.1 Socket工作原理

TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议。Socket是一种通信端点,它允许两个设备上的程序通过网络进行通信。以下是TCP服务器端和客户端通过Socket建立和结束连接的步骤:
服务器端创建Socket(socket()):服务器首先需要创建一个Socket,这是通信的起点。
服务器端绑定(bind()):服务器将Socket绑定到一个IP地址和端口号上,这样客户端才能知道通过哪个地址和端口与服务器通信。
服务器监听(listen()):服务器开始监听绑定的端口,等待客户端的连接请求。
客户端创建Socket(socket()):客户端也需要创建一个Socket。
客户端连接(connect()):客户端使用服务器的IP地址和端口号发起连接请求。
服务器接受连接(accept()):服务器接收到客户端的连接请求后,通过
accept方法接受连接,此时TCP连接建立。建立连接后的数据交换:
- 服务器向客户端请求数据(write()):服务器可以向客户端发送数据。
- 客户端读取数据(read()):客户端读取服务器发送的数据。
- 客户端处理请求:客户端对收到的数据进行处理。
- 客户端回应数据(write()):客户端可以向服务器发送响应数据。
- 服务器读取数据(read()):服务器读取客户端发送的响应数据。
结束连接:
- 服务器关闭Socket(close()):服务器完成数据交换后,关闭Socket。
- 客户端读取剩余数据(read()):客户端可能需要读取服务器发送的任何剩余数据。
- 客户端关闭Socket(close()):客户端也关闭Socket,至此,TCP连接正式关闭。
这个过程也描述了TCP三次握手的过程,包括连接建立、数据传输和连接终止。三次握手确保了连接的可靠性,允许数据在客户端和服务器之间安全地传输。
4.2.2 使用套接字流作为数据源
cd sparksj/mycode/streaming
mkdir socket
cd socket
vim NetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 检查命令行参数是否正确
if len(sys.argv) != 3:
print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建一个 SparkContext 对象,并设置应用程序名称
sc = SparkContext(appName="PythonStreamingNetworkWordCount")
# 创建一个 StreamingContext 对象,设置批处理间隔为1秒
ssc = StreamingContext(sc, 1)
# 从指定的主机和端口创建一个文本套接字流
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 对每行文本按空格进行拆分,并映射为 (word, 1) 的键值对,然后根据键进行聚合统计
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
# 打印每个时间间隔内计算出的单词统计结果
counts.pprint()
# 启动流式计算
ssc.start()
# 等待流式处理终止
ssc.awaitTermination()

新打开一个窗口作为nc窗口,启动nc程序:
nc -lk 9999再新建一个终端(记作“流计算终端”),执行如下代码启动流计算:
cd sparksj/mycode/streaming/socket
spark-submit NetworkWordCount.py localhost 9999可以在nc窗口中随意输入一些单词,监听窗口就会自动获得单词数据流信息,在监听窗口每隔1秒(可自行设置"ssc = StreamingContext(sc, 1)",笔者在此设置的5秒以便输入和查看)就会打印出词频统计信息,大概会在屏幕上出现类似如下的结果:

4.2.3 使用Socket编程实现自定义数据源
把数据源头的产生方式修改一下,不要使用nc程序,而是采用自己编写的程序产生Socket数据源:
cd sparksj/mycode/streaming/socket
vim DataSourceSocket.py
import socket
# 生成socket对象
server = socket.socket()
# 绑定ip和端口
server.bind(('localhost', 9999))
# 监听绑定的端口
server.listen(1)
while 1:
# 为了方便识别,打印一个“我在等待”
print("我在等待连接...")
# 这里用两个值接受,因为连接上之后使用的是客户端发来请求的这个实例
# 所以下面的传输要使用conn实例操作
conn,addr = server.accept()
# 打印连接成功
print("连接成功! 连接来自于 %s " % addr[0])
# 打印正在发送数据
print('正在发送数据...')
conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())
conn.close()
print('连接关闭.')
执行如下命令启动Socket服务端,启动Socket服务端:
cd sparksj/mycode/streaming/socket
spark-submit DataSourceSocket.py
启动客户端,即 4.2.2 中的NetworkWordCount程序。新建一个终端(记作“流计算终端”),输入以下命令启动NetworkWordCount程序:
cd sparksj/mycode/streaming/socket
spark-submit NetworkWordCount.py localhost 9999

若运行时遇到端口号被占用的问题可参考:端口被其他进程占用:OSError: [Errno 98] Address already in use-CSDN博客
4.3 RDD队列流
在调试Spark Streaming应用程序的时候,我们可以使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream
新建一个RDDQueueStream.py代码文件,功能是:每隔1秒创建一个RDD,Streaming每隔2秒就对数据进行处理
cd /home/hadoop/sparksj/mycode/streaming
mkdir rddqueue
cd rddqueue
vim RDDQueueStream.py
# 导入所需的库:time 用于延迟,SparkContext 用于创建 Spark 上下文,StreamingContext 用于创建 Spark 流上下文
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建 Spark 上下文 sc,并为应用程序命名 PythonStreamingQueueStream
# 创建一个流上下文 ssc,并指定批次间隔为 2 秒
if __name__ == "__main__":
sc = SparkContext(appName="PythonStreamingQueueStream")
ssc = StreamingContext(sc, 2)
# 创建一个队列,通过该队列可以把RDD推给一个RDD队列流
# 初始化一个空的 RDD 队列 rddQueue
# 循环创建 5 个 RDD,每个 RDD 包含从 1 到 1000 的整数,并将这些 RDD 添加到 rddQueue 中
# "parallelize([j for j in range(1, 1001)], 10)" 表示将 1000 个整数分成 10 个分区进行并行处理
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]
time.sleep(1) # 在每次循环中,延迟 1 秒
#创建一个RDD队列流
inputStream = ssc.queueStream(rddQueue) # 使用 queueStream 方法创建一个基于 rddQueue 的队列流 inputStream
mappedStream = inputStream.map(lambda x: (x % 10, 1)) # 对 inputStream 进行映射操作,创建一个键值对,其中键是 x % 10,值是 1。这一步将每个元素按它除以 10 的余数分组
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b) # 对 mappedStream 进行 reduceByKey 操作,将每个键对应的值相加。这一步按键聚合,将同样的键的值相加
reducedStream.pprint() # 打印 reducedStream 的输出结果
ssc.start() # 启动流上下文 ssc
ssc.stop(stopSparkContext=True, stopGraceFully=True) # 停止流上下文 ssc,并选择关闭 Spark 上下文,同时确保以良好的方式停止(stopGraceFully=True)

cd sparksj/mycode/streaming/rddqueue
spark-submit RDDQueueStream.py
五、高级数据源
本节提醒:
根据官方文档所述:Kafka 项目在 0.8 和 0.10 版本之间引入了一个新的使用者 API,因此有 2 个单独的对应 Spark 流式处理包可用。0.8 集成与更高版本的 0.9 和 0.10 代理兼容,但 0.10 集成与早期的代理不兼容。
从 Spark 2.3.0 开始,不推荐使用 Kafka 0.8 支持。

故笔者建议使用新的api或降低pyspark版本来完成Spark Streaming程序使用Kafka数据源,在此笔者不过多赘述,有兴趣的读者可以查看以下资料与官方文档:
No module named 'pyspark.streaming.kafka' - 木叶流云 - 博客园 (cnblogs.com)
Spark Streaming + Kafka Integration Guide - Spark 2.4.7 Documentation (apache.org)
基于PySpark整合Spark Streaming与Kafka_pyspark 集成kafka-CSDN博客
5.1 Kafka简介
- Kafka基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
- Kafka可以同时满足在线实时处理和批量离线处理
- Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
- 在公司的大数据生态系统中,可以把Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据库、NoSQL数据库、流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换

5.2 Kafka术语
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker 进行数据存储
- Topic(主题):每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition(分区):每个topic中的消息会被分为若干个partition,以提高消息的处理速度还有就是容错能力
- Producer(消息生产者):负责发布消息到Kafka broker
- Consumer(消息消费者):消息消费者,向Kafka broker读取消息的客户端
- Consumer Group(消费者群组):每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)

Kafka的运行依赖于Zookeeper。Topic、Consumer、Patition、Broker等注册信息都存储在ZooKeeper中。
5.3 Kafka消息队列
Kafka的消息队列分为两种:
点对点模式(生产者的消息只由一个用户来消费)

发布订阅模式(一个生产者或者多个生产者对应一个或者多个消费者(消费者群组))

5.4 Kafka核心API

5.5 Kafka准备工作
5.5.1 安装Kafka
安装Kafka的步骤请参考:Ubuntu22.04下安装kafka_2.12-2.6.0并运行简单实例-CSDN博客
5.5.2 启动Kafka
打开第一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

成功启动所有服务后,读者将拥有一个基本的 Kafka 环境,可供使用。
5.5.3 测试Kafka是否正常工作
主题(Topics)类似于文件系统中的文件夹,事件(events)是该文件夹中的文件。因此,在编写第一个事件之前,必须创建一个主题。
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic(主题):
cd /usr/local/kafka
# 创建一个名为 wordsendertest 的 Kafka 主题
./bin/kafka-topics.sh --create --topic wordsendertest --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
# 列出所有主题
./bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 描述特定主题的细节
./bin/kafka-topics.sh --describe --topic wordsendertest --bootstrap-server localhost:9092- kafka-topics.sh: 指定用于创建、列出和管理 Kafka 主题的脚本
- --create:表示创建一个新的主题
- --topic wordsendertest:指定要创建的主题名称,这里是 wordsendertest
- --bootstrap-server localhost:9092:指定 Kafka 服务器的地址和端口。此处的localhost:9092表示本地的 Kafka 服务器,默认端口是9092
- --replication-factor 1:设置副本因子为 1,意味着数据只有一个副本(不容错)
- --partitions 1:设置分区数为 1,意味着只有一个分区
- --describe:用于获取某个主题的详细信息

Kafka客户端通过网络与Kafka代理进行通信,以写入(或读取)事件。一旦收到事件,直到需要事件,代理程序都将以持久和容错的方式存储事件,甚至永远。
下面用生产者(Producer)来产生一些数据,在主题中写入一些事件。默认情况下,输入的每一行都将导致一个单独的事件写入主题。请在第三个终端(记作“数据源终端”)内继续输入下面命令:
cd /usr/local/kafka
./bin/kafka-console-producer.sh --topic wordsendertest --bootstrap-server localhost:9092- kafka-console-producer.sh:这是 Kafka 提供的一个用于生产者的控制台工具脚本
- --topic wordsendertest:指定要创建的主题名称,这里是 wordsendertest
- --bootstrap-server localhost:9092:指定 Kafka 服务器的地址和端口。此处的localhost:9092表示本地的 Kafka 服务器,默认端口是9092
当执行这个命令后,控制台会等待读者输入消息。每输入一行消息,它就会将该消息发送到指定的主题中。读者可以通过按下 Ctrl+C 来退出生产者控制台。
上面命令执行后,就可以在当前终端内用键盘输入一些英文单词(也可以等消费者启用后再输入)
现在可以启动一个消费者(Consumer),来查看刚才生产者产生的数据。请另外打开第四个终端,输入下面命令:
cd /usr/local/kafka
./bin/kafka-console-consumer.sh --topic wordsendertest --from-beginning --bootstrap-server localhost:9092- kafka-console-consumer.sh:这是 Kafka 提供的一个用于消费者的控制台工具脚本
- --topic wordsendertest:指定要创建的主题名称,这里是 wordsendertest
- --from-beginning: 这个选项表示从该主题的起始位置开始消费消息。如果不指定这个选项,消费者将只会消费自启动后发布的消息
- --bootstrap-server localhost:9092:指定 Kafka 服务器的地址和端口。此处的localhost:9092表示本地的 Kafka 服务器,默认端口是9092
执行这个命令后,控制台将开始从 wordsendertest 主题中消费消息,并将其显示在控制台上。读者可以通过按下 Ctrl+C 来退出消费者控制台。
因为事件是持久存储在Kafka中的,所以它们可以被任意多次读取,也可以被任意多的消费者读取。可以通过打开另一个终端会话并再次运行该命令来验证这一点

-> 实例运行结束后可以Ctrl+Z或Ctrl+C停止进程 ~~~
5.6 Spark准备工作
5.6.1 添加相关jar包
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件),对于Spark 3.2.0版本,如果要使用Kafka,则需要下载spark-streaming-kafka-0-10_2.12-3.2.0.jar,现附上下载地址:
百度网盘下载地址:
链接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw
提取码:wkk6
官方下载地址:
Maven Repository: org.apache.spark » spark-streaming-kafka-0-10_2.12 » 3.2.0 (mvnrepository.com)

完成下载后将下载好的jar包放到虚拟机Ubuntu系统家目录中的下载目录下,放置好后接着进行以下操作:
cd /usr/local/spark/jars
mkdir kafka
cd ~/下载
cp ./spark-streaming-kafka-0-10_2.12-3.2.0.jar /usr/local/spark/jars/kafka继续把Kafka安装目录的libs目录下的所有jar文件复制到“/usr/local/spark/jars/kafka”目录下:
cd /usr/local/kafka/libs
cp ./* /usr/local/spark/jars/kafka
5.6.2 修改Spark配置文件
cd /usr/local/spark/conf
vim spark-env.sh把Kafka相关jar包的路径信息增加到spark-env.sh,修改后的spark-env.sh类似如下(请读者依据自己的路径进行配置):
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*:/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
上述内容是在Spark 3.2.0使用Kafka数据源的基本思路,其他版本的Spark使用Kafka数据源基本思路亦是如此!!!
5.7 编写Spark Streaming程序使用Kafka数据源
!!!正如本节开头所述,0.10 集成与早期的代理不兼容,故使用Kafka数据源时会出现No module named 'pyspark.streaming.kafka'的报错,读者可以使用新的api或降低pyspark版本来实现Spark Streaming程序使用Kafka数据源,笔者在此不再显示,只提供基本思路,读者如有需要可参考本节开头所给链接进行参考,见谅!!!
基本思路如下(Spark 2.4.0):
cd sparksj/mycode/streaming
mkdir kafka
cd kafka
vim KafkaWordCount.py
from __future__ import print_function # 使用 Python 3.x 的 print 函数特性
import sys # 导入 sys 模块,用于处理命令行参数
from pyspark import SparkContext # 导入 SparkContext 模块
from pyspark.streaming import StreamingContext # 导入 StreamingContext 模块
from pyspark.streaming.kafka import KafkaUtils # 导入 KafkaUtils 模块,用于从 Kafka 中创建 DStream
if __name__ == "__main__":
if len(sys.argv) != 3: # 检查命令行参数数量是否正确
print("Usage: KafkaWordCount.py <zk> <topic>", file=sys.stderr) # 打印使用说明
exit(-1) # 退出程序
sc = SparkContext(appName="PythonStreamingKafkaWordCount") # 创建 SparkContext,设置应用名
ssc = StreamingContext(sc, 1) # 创建 StreamingContext,参数为 SparkContext 和批处理间隔(这里为1秒)
zkQuorum, topic = sys.argv[1:] # 从命令行参数中获取 ZooKeeper 地址和主题名
kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1}) # 从 Kafka 中创建一个输入数据流,参数分别为 StreamingContext、ZooKeeper 地址、消费者组、主题名和分区数量
lines = kvs.map(lambda x: x[1]) # 将输入数据流中的每个记录转换为其值(消息内容)
counts = lines.flatMap(lambda line: line.split(" ")) \ # 将每个输入行拆分为单词,并转换为 (word, 1) 键值对
.map(lambda word: (word, 1)) \ # 将每个单词映射为 (word, 1) 键值对
.reduceByKey(lambda a, b: a+b) # 对相同键的值进行求和,即统计每个单词的出现次数
counts.pprint() # 打印每个批次的结果
ssc.start() # 启动 StreamingContext
ssc.awaitTermination() # 等待终止,直到手动终止或发生错误
①打开第一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了(Kafka工作运行完毕后不再使用时再关闭)
②打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了(Kafka工作运行完毕后不再使用时再关闭)
③打开第三个终端(记作“数据源终端”)内输入下面命令:
cd /usr/local/kafka
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wordsendertest④打开第四个终端(记作“流计算终端”),执行KafkaWordCount.py:
cd sparksj/mycode/streaming/kafka
spark-submit ./KafkaWordCount.py localhost:2181 wordsendertest时再切换到之前已经打开的“数据源终端”,用键盘手动敲入一些英文单词
在流计算终端内就可以看到类似如下的词频统计动态结果:
-------------------------------------------
Time: 2024-5-10 10:40:42
-------------------------------------------
('hadoop', 1)
-------------------------------------------
Time: 2024-5-10 10:40:43
-------------------------------------------
('spark', 1)
六、转换操作
6.1 DStream无状态转换操作
- map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的Dstream
- flatMap(func): 与map相似,但是每个输入项可用被映射为0个或者多个输出项
- filter(func): 返回一个新的DStream,仅包含源DStream中满足函数func的项
- repartition(numPartitions): 通过创建更多或者更少的分区改变DStream的并行程度
- reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream(相加)
- count():统计源DStream中每个RDD的元素数量
- union(otherStream): 返回一个新的DStream,包含源DStream和其他DStream的元素
- countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数
- reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来
- join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新Dstream
- cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组
- transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作
无状态转换操作实例: 之前“套接字流”部分介绍的词频统计,就是采用无状态转换,每次统计,都是只统计当前批次到达的单词的词频,和之前批次无关,不会进行累计
- countByKey:根据key进行分组,统计每个分组下有多少个元素
- countByValue:根据value进行分组,统计相同value有多少个(会将列表中每一个元素看做是value)
>>> rdd1=sc.parallelize([('01','a'),('02','b'),('01','c')])
>>> rdd1.countByKey()
defaultdict(<class 'int'>, {'01': 2, '02': 1})
>>> rdd1.countByValue()
defaultdict(<class 'int'>, {('01', 'a'): 1, ('02', 'b'): 1, ('01', 'c'): 1})
>>> rdd2=sc.parallelize([1,2,1,4,4,5])
>>> rdd2.countByValue()
defaultdict(<class 'int'>, {1: 2, 2: 1, 4: 2, 5: 1})

- cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组
>>> x=sc.parallelize([('a',1),('b',2),('a',3)])
>>> y=sc.parallelize([('a',2),('b',3),('b',5)])
>>> z=x.cogroup(y)
>>> z.collect()
[('a', (<pyspark.resultiterable.ResultIterable object at 0x7f6b02202e30>, <pyspark.resultiterable.ResultIterable object at 0x7f6b02202d70>)), ('b', (<pyspark.resultiterable.ResultIterable object at 0x7f6b02202c80>, <pyspark.resultiterable.ResultIterable object at 0x7f6af66c3be0>))]
>>> w=z.map(lambda x:(x[0],list(x[1][0]),list(x[1][1]))) #索引方式引用查看(x[0]:key,list(x[1][0]):value的第一个,list(x[1][1]):value的第二个)
>>> print(w.collect())
[('a', [1, 3], [2]), ('b', [2], [3, 5])]
>>> w.collect()
[('a', [1, 3], [2]), ('b', [2], [3, 5])]
6.2 DStream有状态转换操作
6.2.1 滑动窗口转换操作
- 事先设定一个滑动窗口的长度(也就是窗口的持续时间)
- 设定滑动窗口的时间间隔(每隔多长时间执行一次计算),让窗口按照指定时间间隔在源DStream上滑动
- 每次窗口停放的位置上,都会有一部分Dstream(或者一部分RDD)被框入窗口内,形成一个小段的Dstream
- 可以启动对这个小段DStream的计算

一些窗口转换操作的含义:
- window(windowLength, slideInterval):基于源DStream产生的窗口化的批数据,计算得到一个新的Dstream
- countByWindow(windowLength, slideInterval):返回流中元素的一个滑动窗口数
- reduceByWindow(func, windowLength, slideInterval):返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算
- countByValueAndWindow(windowLength, slideInterval, [numTasks]):当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]):更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入)
下面来完成一个简单的词频动态统计:
cd sparksj/mycode/streaming/dstream
vim WindowedNetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 检查命令行参数数量是否正确
if len(sys.argv) != 3:
print("Usage: WindowedNetworkWordCount.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建 SparkContext 对象,设置应用程序名称
sc = SparkContext(appName="PythonStreamingWindowedNetworkWordCount")
# 创建 StreamingContext 对象,设置批处理间隔为 10 秒
ssc = StreamingContext(sc, 10)
# 设置检查点路径,用于保存状态信息,防止数据丢失
ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointwindow/checkpoint")
# 创建一个从指定主机和端口接收数据的 DStream 对象
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 对接收到的数据进行处理:
# 使用 flatMap 对每行文本进行单词切分,并扁平化为一个单词列表
# 使用 map 将每个单词映射为 (单词, 1) 的键值对
# 使用 reduceByKeyAndWindow 对窗口内的数据进行聚合操作,其中窗口长度为 30 秒,滑动间隔为 10 秒
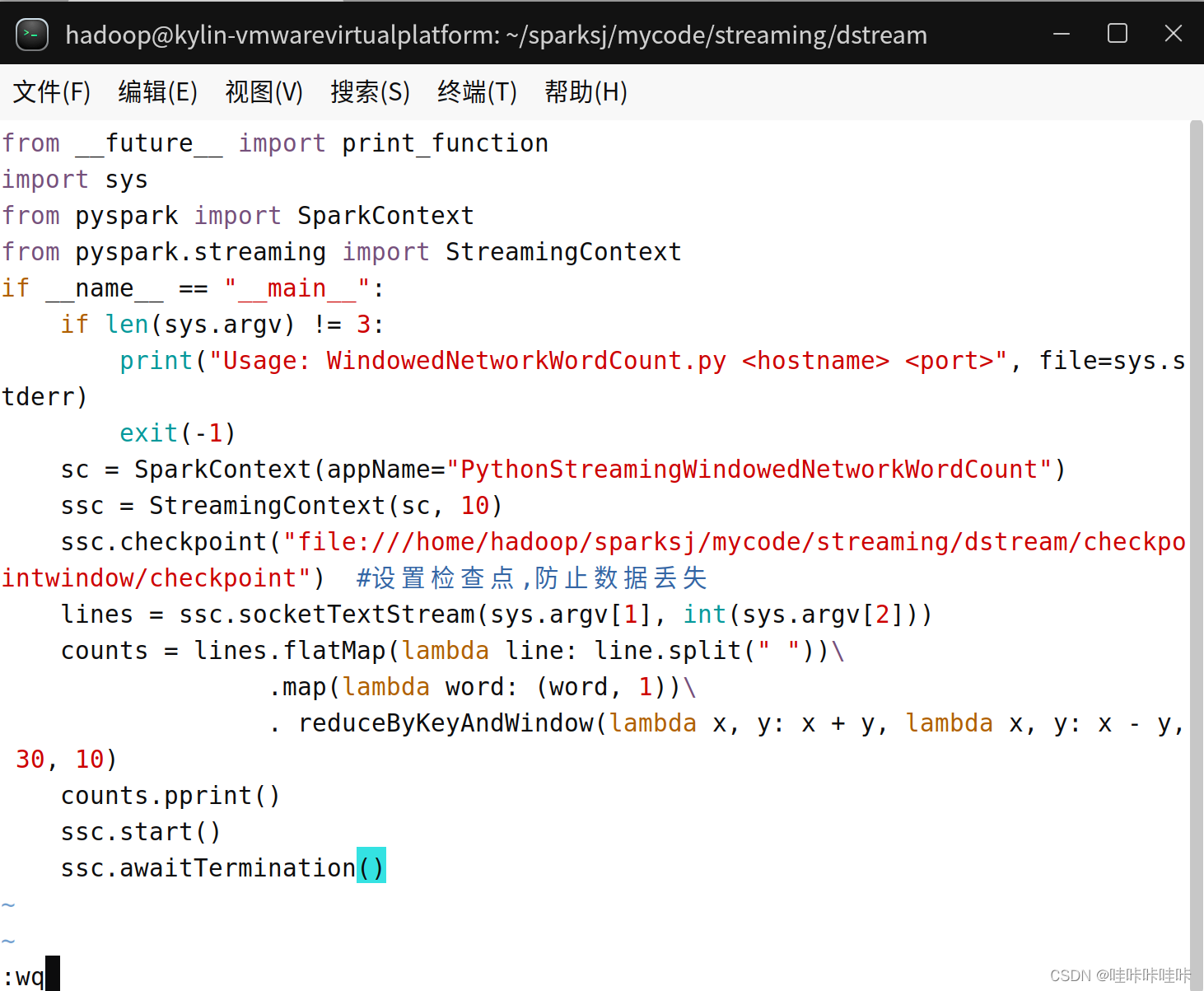
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
# 调用 pprint() 方法打印每个窗口的单词计数结果
counts.pprint()
# 启动流处理作业
ssc.start()
# 等待作业结束
ssc.awaitTermination()
新建一个终端(记作“数据源终端”),执行如下命令运行nc程序:
nc -lk 9999再新建一个终端(记作“流计算终端”),运行客户端程序WindowedNetworkWordCount.py:
cd sparksj/mycode/streaming/dstream
spark-submit WindowedNetworkWordCount.py localhost 9999
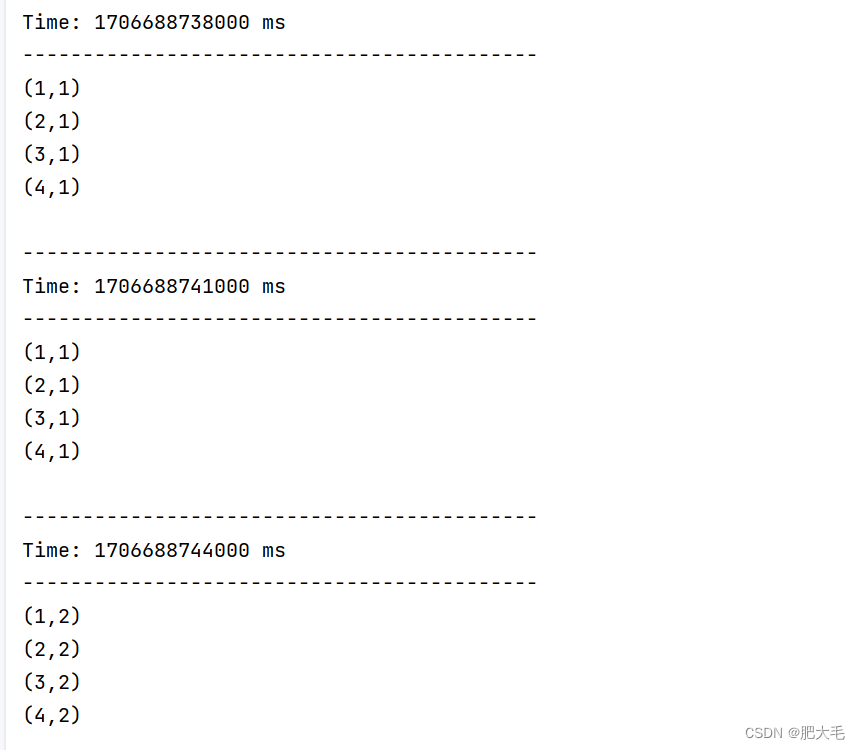
可以看到,随着时间的流逝,词频统计结果会发生动态变化!!!
进入设置的检查点目录(/home/hadoop/sparksj/mycode/streaming/dstream/checkpointwindow/checkpoint)可以看到会出现很多文件

关键操作:

6.2.2 updateStateByKey操作
需要在跨批次之间维护状态时,就必须使用updateStateByKey操作
词频统计实例:
对于有状态转换操作而言,本批次的词频统计,会在之前批次的词频统计结果的基础上进行不断累加,所以,最终统计得到的词频,是所有批次的单词的总的词频统计结果
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStateful.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 检查命令行参数数量是否正确
if len(sys.argv) != 3:
print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建 SparkContext 对象,并设置应用程序名称
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
# 创建 StreamingContext 对象,并设置批处理间隔为 10 秒
ssc = StreamingContext(sc, 10)
# 设置检查点路径,用于保存状态信息,防止数据丢失
ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpoint")
# 定义一个初始状态的 RDD,包含 (key, value) 对
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
# 定义一个更新函数,用于更新状态
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
# 创建一个从指定主机和端口接收数据的 DStream 对象
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 对接收到的数据进行处理:
# 使用 flatMap 对每行文本进行单词切分,并扁平化为一个单词列表
# 使用 map 将每个单词映射为 (单词, 1) 的键值对
# 使用 updateStateByKey 对状态进行更新
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
# 调用 pprint() 方法打印每个时间段内的计数结果
running_counts.pprint()
# 启动流处理作业
ssc.start()
# 等待作业结束
ssc.awaitTermination()

新建一个终端(记作“数据源终端”),执行如下命令启动nc程序:
nc -lk 9999新建一个Linux终端(记作“流计算终端”),执行如下命令提交运行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStateful.py localhost 9999
可以按Ctrl+C终止监听或Ctrl+Z停止监听
七、输出操作
在Spark应用中,外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中
7.1 把DStream输出到文本文件中
编写NetworkWordCountStatefulText.py实现把DStream输出到文本文件中:
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStatefulText.py
from __future__ import print_function # 使 print 函数兼容 Python 2.x
import sys # 导入 sys 模块,用于处理命令行参数
from pyspark import SparkContext # 导入 SparkContext 类
from pyspark.streaming import StreamingContext # 导入 StreamingContext 类
# 确保命令行参数数量正确
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建 SparkContext 对象,设置应用程序名称为 "PythonStreamingStatefulNetworkWordCount"
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
# 创建 StreamingContext 对象,设置批处理间隔为 10 秒
ssc = StreamingContext(sc, 10)
# 设置检查点目录
ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointtotext/output")
# 定义初始状态 RDD
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
# 定义更新函数,用于更新状态
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
# 创建一个 DStream,从指定主机和端口接收文本数据流
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 对接收到的文本数据进行处理,将每行文本按空格拆分为单词,并将每个单词映射为 (word, 1) 的键值对
# 然后使用 updateStateByKey 方法根据更新函数对状态进行更新
running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD)
# 将结果保存到文件中
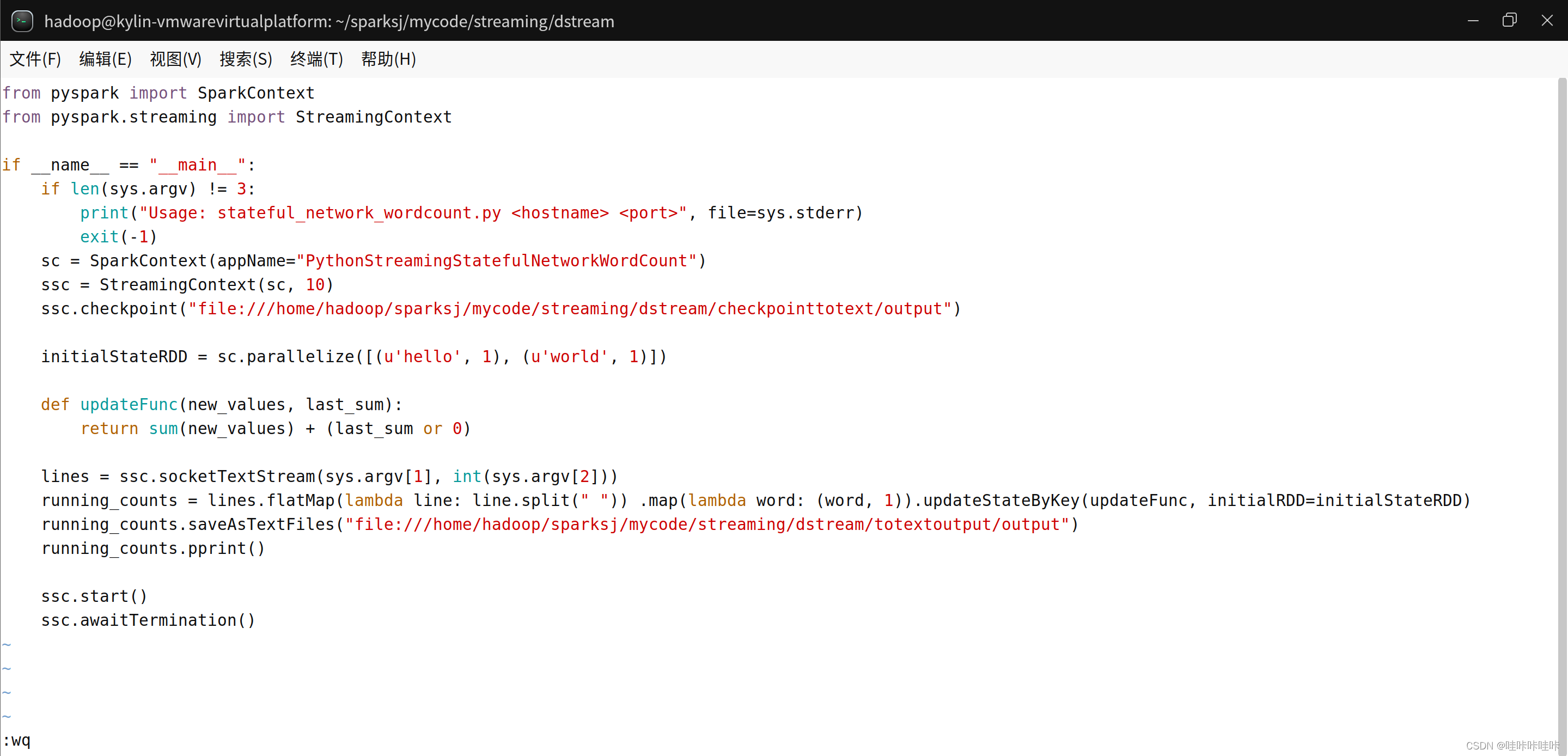
running_counts.saveAsTextFiles("file:///home/hadoop/sparksj/mycode/streaming/dstream/totextoutput/output")
# 在控制台打印计数结果
running_counts.pprint()
# 启动 StreamingContext
ssc.start()
# 等待作业完成
ssc.awaitTermination()
新建一个终端(记作“数据源终端”),执行如下命令启动nc程序:
nc -lk 9999新建一个Linux终端(记作“流计算终端”),执行如下命令提交运行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStatefulText.py localhost 9999
可以进入结果保存目录,查看每批次输出的内容:

7.2 把DStream写入到MySQL数据库中
启动MySQL数据库:
service mysql start
mysql -u root -p创建数据库与表:
create database spark;
use spark;
create table wordcount (word char(20), count int(4));
由于需要让Python连接数据库MySQL,所以,需要首先安装Python连接MySQL的模块PyMySQL,在Linux终端中执行如下命令:
sudo apt-get update
sudo apt-get install python3-pip
pip3 -V
sudo pip3 install PyMySQL笔者已经安装过PyMySQL:

编写NetworkWordCountStatefulDB.py实现把DStream写入到MySQL数据库中:
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStatefulDB.pyfrom __future__ import print_function # 确保在 Python 2.x 中可以使用 print 函数
import sys # 导入 sys 模块,用于处理命令行参数
import pymysql # 导入 pymysql 模块,用于连接 MySQL 数据库
from pyspark import SparkContext # 导入 SparkContext 类
from pyspark.streaming import StreamingContext # 导入 StreamingContext 类
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建 SparkContext 对象,设置应用程序名称为 "PythonStreamingStatefulNetworkWordCount"
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
# 创建 StreamingContext 对象,设置批处理间隔为 10 秒
ssc = StreamingContext(sc, 10)
# 设置检查点目录
ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointdb")
# 定义初始状态 RDD
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
# 定义更新函数,用于更新状态
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
# 创建一个 DStream,从指定主机和端口接收文本数据流
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 对接收到的文本数据进行处理,将每行文本按空格拆分为单词,并将每个单词映射为 (word, 1) 的键值对
# 然后使用 updateStateByKey 方法根据更新函数对状态进行更新
running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD)
# 在控制台打印计数结果
running_counts.pprint()
# 定义将结果写入 MySQL 数据库的函数
def dbfunc(records):
db = pymysql.connect(host='localhost', port=3306, user='root', passwd='123456', db='spark') # 连接 MySQL 数据库
cursor = db.cursor()
# 定义执行插入操作的函数
def doinsert(p):
sql = "insert into wordcount(word,count) values (%s, %s)"
try:
cursor.execute(sql, (str(p[0]), p[1]))
db.commit() # 提交事务
except Exception as e:
print("Error occurred:", e)
db.rollback() # 回滚事务
# 遍历 RDD 中的每个元素,并执行插入操作
for item in records:
doinsert(item)
cursor.close() # 关闭游标
db.close() # 关闭数据库连接
# 定义将结果写入数据库的函数
def func(rdd):
repartitionedRDD = rdd.repartition(3) # 对 RDD 进行重新分区
repartitionedRDD.foreachPartition(dbfunc) # 对每个分区应用 dbfunc 函数
# 对计数结果应用写入数据库的函数
running_counts.foreachRDD(func)
# 启动 StreamingContext
ssc.start()
# 等待作业完成
ssc.awaitTermination()
新建一个终端(记作“数据源终端”),执行如下命令启动nc程序:
nc -lk 9999新建一个Linux终端(记作“流计算终端”),执行如下命令提交运行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStatefulDB.py localhost 9999
foreachPartition 操作的介绍:
foreachPartition是Spark中的一个操作,它可以对RDD或DataFrame中的每个分区执行自定义的操作。它接收一个函数作为参数,该函数将作用于每个分区的迭代器上。foreachPartition操作通常用于对每个分区执行一些特定的计算或数据写入等操作。使用foreachPartition操作时,可以在每个分区上进行批量操作,提高作业的性能。
关于RDD分区函数mapPartitions与foreachPartition解析可以参考:





![HarmongOS打包[<span style='color:red;'>保姆</span><span style='color:red;'>级</span>]](https://img-blog.csdnimg.cn/direct/924bc6c7d2d8490eb8c731c067daf5b0.jpeg#pic_center)