本文主要基于Time Series Shapelets: A New Primitive for Data Mining
KDD' 2009
Author : Lexiang Ye, Eamonn Keogh
对该论文的理解,所以该文中有关shapelet的信息都是有关原始shapelet的理解
一、Shapelet的概述
Shapelet可以拆成Shape与let,Shape是形状,-let表示“小”的后缀,Shapelet即表示时间序列的“小形状”,即一个子序列。这个子序列是这段时间序列数据中一个特别的子序列,其能表达时序数据中最显著的特点。
找到最有代表性的一段子序列(Shapelet)用于分类
Shapelet实际上是一种特征提取的方法
Time series -> shapelet
原始shapelet分类器有两个主要局限性
首先,它很慢:shapelet发现过程非常耗时。其次,通过使决策树成为算法的一个组成部分,它无法将形状元素与其他分类器结合。
shapelet是时间序列中能最大程度反映类别信息的连续子序列, 它可以很好地解释分类结果
背景
时间序列分类定义
给定一个包含N个时间序列对象的数据集(每个时间序列对象的长度可能不一样),其中每个时间序列对象Ti属于一个类别ci(ci∈C),然后对没有标签的时间序列对象进行分类。
应用:故障检测、健康检测。例如:对一个机器进行长期监测,并标注出现的故障为异常,就可以用来检测每天是否正常运行。
传统方法
全量时序数据用来判断(knn,DTW)
问题:非常耗时,解释性差(早期,现在好像具有很好的解释性)
二、Shapelet初阶方法-找shapelet
1.shapelet长度=[Minlen,Maxlen]
2.截取每个时间序列对象T对应长度的子序列,作为shapelet candidates
例:时间序列对象为[1,1,2,2,3,3,5],shapelet可以有[1,1,2]、[1,2,2]、······、[1,,1,2,2]、 [1,2,2,3]、[2,2,3,3,5]。(任意子序列)
3.遍历每个shapelet candidate,计算找到最优的shapelet
如何判断是否是最优的shapelet:信息增益
信息增益是表示数据集中某个特征X的信息使类Y的信息的不确定性减少的程度,即特征X让类Y不确定度降低。
特征A对训练数据集D的信息的信息增益g(D,A),定义为集合D的熵H(D)𝐻(𝐷)与特征A给定条件下D的条件熵H(D|A之差
g(D,A)=H(D)−H(D|A)
其中H(D)和H(D|A)之差成为互信息
信息增益算法的流程
数据集为D;样本容量为|D|,即样本个数。
K为分类个数,表示属于类别
的样本个数,
=|D|。
特征A取值有a1,a2,...,an𝑎1,𝑎2,...,𝑎𝑛,根据A的取值,把D划分成n个子集D1,D2..,Dn𝐷1,𝐷2,...,𝐷𝑛,|𝐷𝑖|是Di𝐷𝑖的样本个数
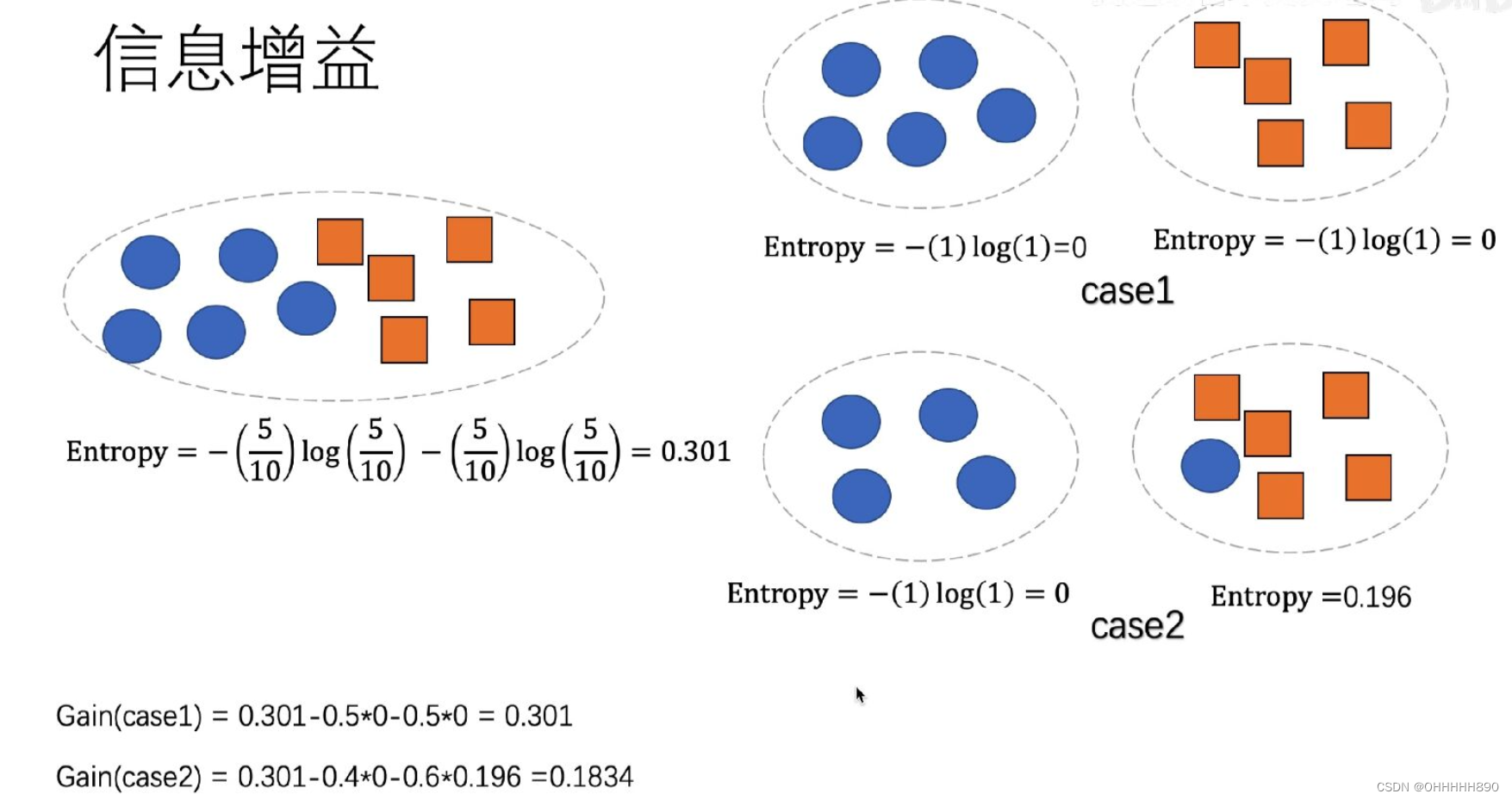
如下图:
我们用gain的大小来衡量分类效果的好坏
entropy代表集合中的熵,当五个圆形和五个方形在一个集合时,熵为0.301
将他们分成上面这种情况,熵均变为0,则此时计算Gain为0.301
分为下面那种情况,则熵变为0,0.196,则此时gain的值变为0.1834
则可以判断出上面的分类效果优于下面。
当我们对原始时序序列提取出shapelet候选集后,去遍历每个shapelet评判其好与坏时:
将每一个shapelet candidate定义为S
计算每个时间序列对象与S之间的距离,将距离从小到大排序之后,两两之间的平均值作为分类边界,根据距离将所有时间序列对象分为两类,记录信息增益最大的情况以及其分类边界。
图例:
d表示选取样本与原序列之间的距离

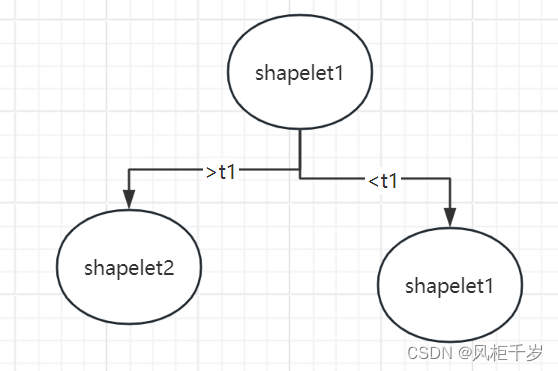
基于Shapelet分类(这里说的并不是分类算法)
类似于决策树
如图,判断一个时间序列时,先与shapelet1进行比较计算距离分为大于t1,小于t1分为..........
一直划分到叶子节点。
对于每个提取的shapelet candidates都需要遍历一次(时间复杂度很高)
三、剪枝策略
剪枝策略1
计算每个时间序列对象与S之间的距离时采用early abandon策略
不把整条序列完全按照每个匹配点都做比较,如果发现距离大于历史最好的情况下停止
附加(转载):
早停机制(Early Stopping)与早退机制(Early exiting)
<1>早停机制,一种机器学习模型调优策略,提升调优效率
在机器学习中,早期停止是一种正则化形式,用于在使用梯度下降等迭代法训练学习器时避免过拟合。这种方法会更新学习器,使其每次迭代都能更好地适应训练数据。在一定程度上,这可以提高学习器在训练集以外数据上的性能。然而,超过了这一点,学习器与训练数据拟合度的提高是以泛化误差的增加为代价的。早期停止规则为学习器开始过度拟合之前可以运行多少次迭代提供了指导。许多不同的机器学习方法都采用了早期停止规则,其理论基础各不相同。
(1)Overfitting(过拟合)
机器学习算法根据有限的训练数据集来训练模型。在训练过程中,会根据模型对训练集中观测数据的预测结果进行评估。不过,一般来说,机器学习方案的目标是生成一个能够泛化的模型,即能够预测以前未见过的观测结果。当模型很好地拟合了训练集中的数据,却产生了较大的泛化误差时,就会出现过拟合。
(2)Regularization(过拟合)
在机器学习中,正则化是指修改学习算法以防止过度拟合的过程。这通常涉及对学习到的模型施加某种平滑性约束。这种平滑性可以通过固定模型中的参数数量来明确执行,也可以通过增强代价函数来执行,如在 Tikhonov 正则化中。Tikhonov 正则化以及主成分回归和许多其他正则化方案都属于频谱正则化的范畴,正则化的特点是应用滤波器。Early stopping也属于这一类方法。
<2>早退机制(Early exiting)
虽然深度神经网络得益于大量的层数,但在分类任务中,很多数据点往往只需要更少的工作就能准确分类。最近有几项研究涉及在神经网络正常终点之前退出的想法。Panda 等人在 Conditional Deep Learning for Energy-Efficient and Enhanced Pattern Recognition 一文中指出,与一些难度较高的数据点相比,很多数据点都可以轻松分类,所需的处理量也更少,他们认为这可以节省电能。Surat 等人在BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks一文中,研究了退出位置的选择性方法和早期退出的标准。
(1)Early Exiting为什么有效
早期退出是一种概念简单易懂的策略 ,下图显示了二维特征空间中的一个简单示例。虽然深度网络可以表示类别之间更复杂、更有表现力的边界(假设我们有信心避免过度拟合数据),但很明显,即使是最简单的分类边界,也能对大部分数据进行正确分类。
与靠近边界的数据点相比,远离边界的数据点可被视为 "易于分类",并能更快地获得高置信度。事实上,我们可以把外侧直线之间的区域看作是 "难以分类 "的区域,需要神经网络的全部表现力才能准确分类。
剪枝策略2(不是很理解)
计算最优的shapelet时提前过滤upper bound比当前最好的信息增益小的shapelet
假设在当前某个shapelet下最好的分类的shapelet
我们计算该shapelet与原时间序列的距离时,在未完全计算出距离来得出信息增益前,通过数据集的标签(也许)预估出最佳的距离的某种情况,计算出此时的信息增益,如果比原有的信息增益小,则不考虑该shapelet。
拓展思考
(1)基于shapelet表征学习的能源负荷预测模型
针对多个地区之间的差异性和互相影响,降低缺失数据对预测的影响
下列是通过GPT3.5生成的该方法的具体步骤,作为参考:
数据准备:收集并准备好历史能源负荷数据,确保数据质量高且具有时间序列特征。
形状子序列提取:利用一种适合的算法从时间序列数据中提取形状子序列。形状子序列是指时间序列中具有代表性的特征形状片段,可以帮助捕捉数据中的重要模式和趋势。
特征提取:对每个形状子序列进行特征提取,将其转换为可以输入机器学习模型的数值特征。这些特征可以包括形状子序列的长度、斜率、振幅等统计特征。
模型训练:利用提取的形状子序列特征和相应的能源负荷数据,训练一个预测模型。常用的模型包括支持向量机(SVM)、决策树、随机森林等。
模型评估:使用测试数据集评估模型的性能,通常采用指标如均方根误差(RMSE)、平均绝对误差(MAE)等来评价模型的准确性和泛化能力。
模型优化:根据评估结果对模型进行调优和优化,可能包括调整模型参数、增加更多的特征、尝试不同的机器学习算法等。
对于目前的机器学习阶段,针对我研究的LSTM+LIME的模型,可以在模型构建以前通过shapelet的某种表征学习方法,提取具体形状子序列,这些具有显著模式的部分可以帮助提高特征的区分能力。
- 对于每个形状子序列,提取多个特征,包括长度、均值、方差、斜率等统计特征。
- 将原始时间序列数据与提取的形状子序列特征合并,构建新的特征表示。
(2)双阶段多视角学习的能源负荷预测模型
暂不做思考
参考/转载:
【机器学习(三)】机器学习中:信息熵,信息增益,信息增益比,原理,案例,代码实现。-CSDN博客