前言
二分查找仅适用于有序数据、有序数组,二分查询大数据情况下表现较好,但数据量仍限制于内存。
算法原理
二分查找(Binary Search),是一种高效的查找算法,适用于已经排好序的数组。其基本原理是每次将待查找区间分成两部分,通过与中间元素的比较来确定目标元素可能存在的区间,从而缩小查找范围,直到找到目标元素或确定目标元素不存在为止,时间复杂度为O(log n),空间复杂度O(1)。
以下是二分查找的基本原理步骤:
确定查找范围:首先,确定待查找的数组范围,通常是整个数组。
计算中间位置:计算查找范围的中间位置索引,即
(左边界 + 右边界) / 2。如果数组长度为奇数,则向下取整。比较中间元素:将目标元素与中间位置的元素进行比较。
- 如果目标元素等于中间位置的元素,则找到目标元素,返回中间位置的索引。
- 如果目标元素小于中间位置的元素,则在左半部分继续查找,将右边界设为中间位置的左侧。
- 如果目标元素大于中间位置的元素,则在右半部分继续查找,将左边界设为中间位置的右侧。
缩小查找范围:根据比较的结果,缩小待查找区间,重复执行步骤2和步骤3,直到找到目标元素或确定目标元素不存在。
代码实现(c)
#include <stdio.h>
int binarySearch(int arr[], int left, int right, int target) {
while (left <= right) {
int mid = left + (right - left) / 2;
// 如果目标元素等于中间位置的元素,则返回中间位置的索引
if (arr[mid] == target) {
return mid;
}
// 如果目标元素小于中间位置的元素,则在左半部分继续查找
else if (arr[mid] > target) {
right = mid - 1;
}
// 如果目标元素大于中间位置的元素,则在右半部分继续查找
else {
left = mid + 1;
}
}
// 如果循环结束仍未找到目标元素,则返回-1表示不存在
return -1;
}
int main() {
int arr[] = {2, 5, 8, 12, 16, 23, 38, 56, 72, 91};
int n = sizeof(arr) / sizeof(arr[0]);
int target = 23;
int result = binarySearch(arr, 0, n - 1, target);
if (result != -1) {
printf("Element %d found at index %d.\n", target, result);
} else {
printf("Element %d not found in the array.\n", target);
}
return 0;
}
优点与局限性¶
二分查找在时间和空间方面都有较好的性能。
- 二分查找的时间效率高。在大数据量下,对数阶的时间复杂度具有显著优势。
- 二分查找无须额外空间。相较于需要借助额外空间的搜索算法(例如哈希查找)。
然而,二分查找并非适用于所有情况,主要有以下原因。
- 二分查找仅适用于有序数据。若输入数据无序,为了使用二分查找而专门进行排序,得不偿失。因为排序算法的时间复杂度通常为 𝑂(𝑛log𝑛) ,比线性查找和二分查找都更高。对于频繁插入元素的场景,为保持数组有序性,需要将元素插入到特定位置,时间复杂度为 𝑂(𝑛) ,也是非常昂贵的。
- 二分查找仅适用于数组。二分查找需要跳跃式(非连续地)访问元素,而在链表中执行跳跃式访问的效率较低,因此不适合应用在链表或基于链表实现的数据结构。
- 小数据量下,线性查找性能更佳。在线性查找中,每轮只需 1 次判断操作;而在二分查找中,需要 1 次加法、1 次除法、1 ~ 3 次判断操作、1 次加法(减法),共 4 ~ 6 个单元操作;因此,当数据量 𝑛 较小时,线性查找反而比二分查找更快。

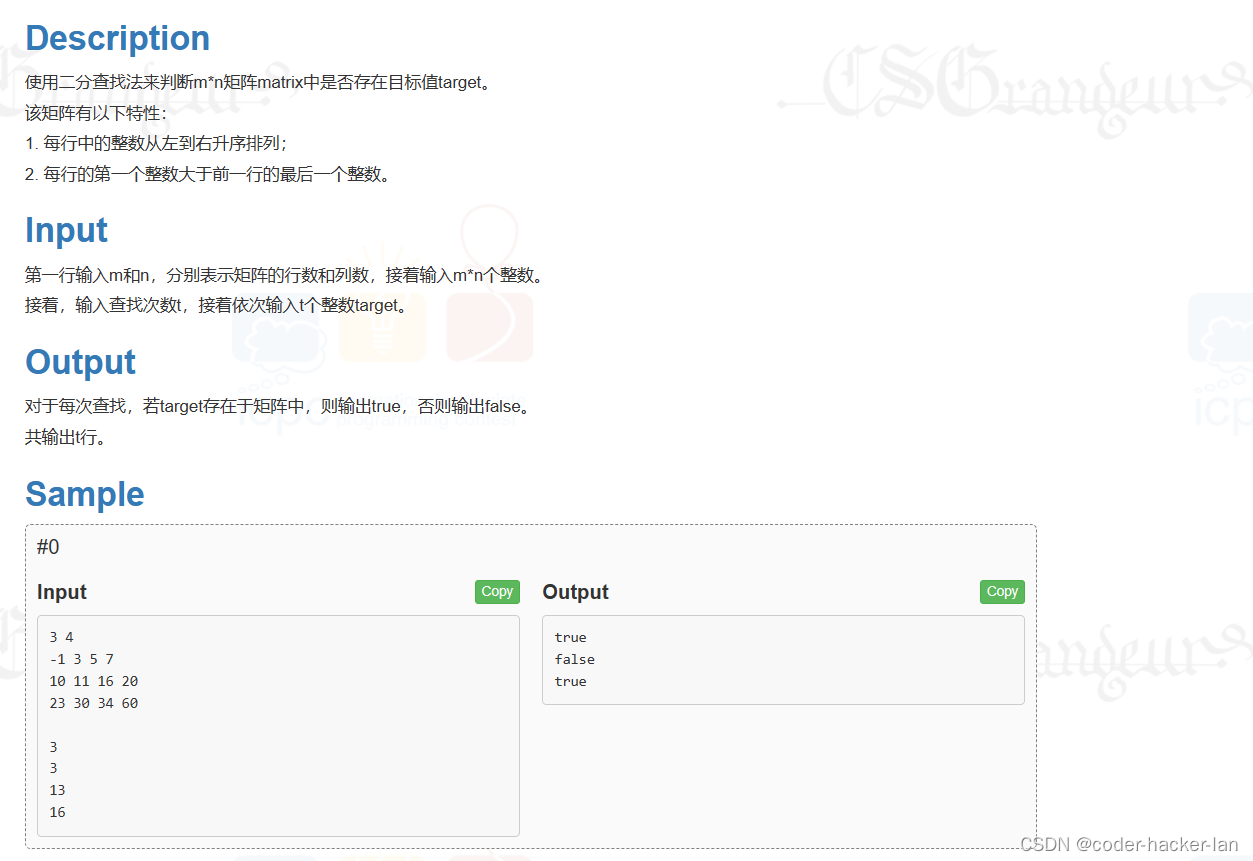

























![[前后端基础]图片详解](https://img-blog.csdnimg.cn/direct/72eed367aa1c49ebb41a27ead3f60b24.png)