一、PCA数学原理
1.数据标准化
首先,需要对原始数据进行标准化处理,使得每个特征的均值为0,方差为1。假设有一个的数据矩阵X,其中每一列是一个样本,每一行是一个特征。
标准化公式如下:
其中,是原始数据矩阵
X中的元素,是第
j个特征的均值, 是第
j个特征的标准差,是标准化后的数据。
2.计算协方差矩阵
接下来,我们需要计算标准化后数据矩阵的协方差矩阵。协方差矩阵是一个对称矩阵,它描述了数据中不同特征之间的线性关系。
协方差矩阵的计算公式如下:
复制
其中,n 是样本数量, 是标准化后的数据矩阵,
是
的转置。
3.计算特征值和特征向量
协方差矩阵的特征值和特征向量可以通过求解特征方程得到:
其中, 是特征值,
是单位矩阵。
对于每个特征值,我们可以找到对应的特征向量
,满足:
4.选择主成分
特征值的大小代表了对应特征向量方向上的方差大小。我们通常选择最大的几个特征值对应的特征向量作为主成分,因为它们包含了数据中的大部分信息。
在这个例子中,我们想要将数据降维到3x1,所以我们只需要选择一个主成分,即选择最大的特征值对应的特征向量。
5.数据投影
最后,我们将原始数据矩阵X投影到选定的主成分上,得到降维后的数据矩阵。
投影公式如下:
其中, 是降维后的数据矩阵,
是最大的特征值对应的特征向量。
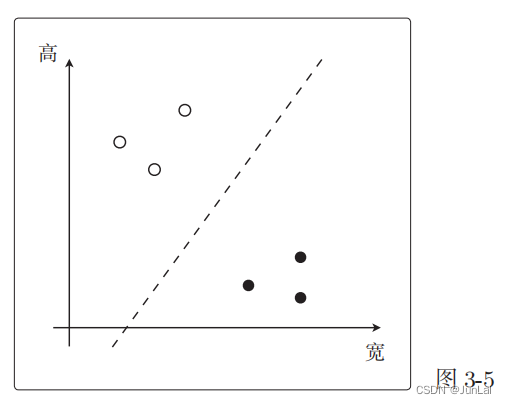
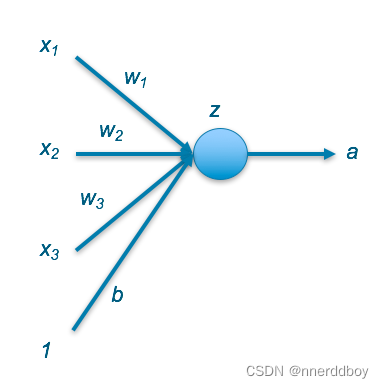
二、SVM数学原理
























![[图解]SysML和EA建模住宅安全系统-02](https://img-blog.csdnimg.cn/direct/f656beefe0d24490b599f3b71a9d7922.png)
![[windows系统安装/重装系统][step-1]U盘启动盘制作,微软官方纯净系统镜像下载](https://img-blog.csdnimg.cn/img_convert/54d0ccb46bbdd82c0506ff4767a7d257.png)