文章目录
一、 什么是sql注入
SQL注入是一种常见的网络安全漏洞,它允许攻击者通过向应用程序的输入字段插入恶意SQL代码来执行未经授权的数据库操作。这种攻击通常发生在使用SQL数据库的网站或应用程序中。攻击者可以利用这个漏洞来获取敏感数据、修改数据、甚至完全控制数据库。
SQL注入的原理是利用应用程序在处理用户输入时未正确过滤或转义数据的漏洞。通过在输入字段中插入SQL代码片段,攻击者可以改变SQL查询的逻辑,从而执行意外的数据库操作。这种攻击可能会导致严重的安全问题,包括数据泄露、数据损坏和系统崩溃。
为了防止SQL注入攻击,开发人员应该使用参数化查询或预编译语句等安全的数据库访问方法,并对用户输入进行适当的验证和过滤。另外,定期对应用程序进行安全审计和漏洞扫描也是很重要的。
二、 sql注入的例子
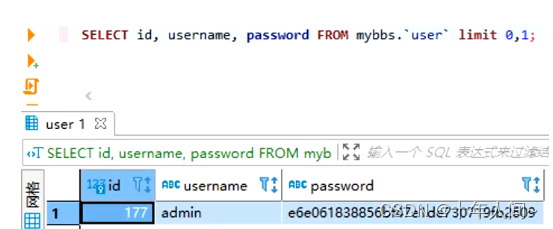
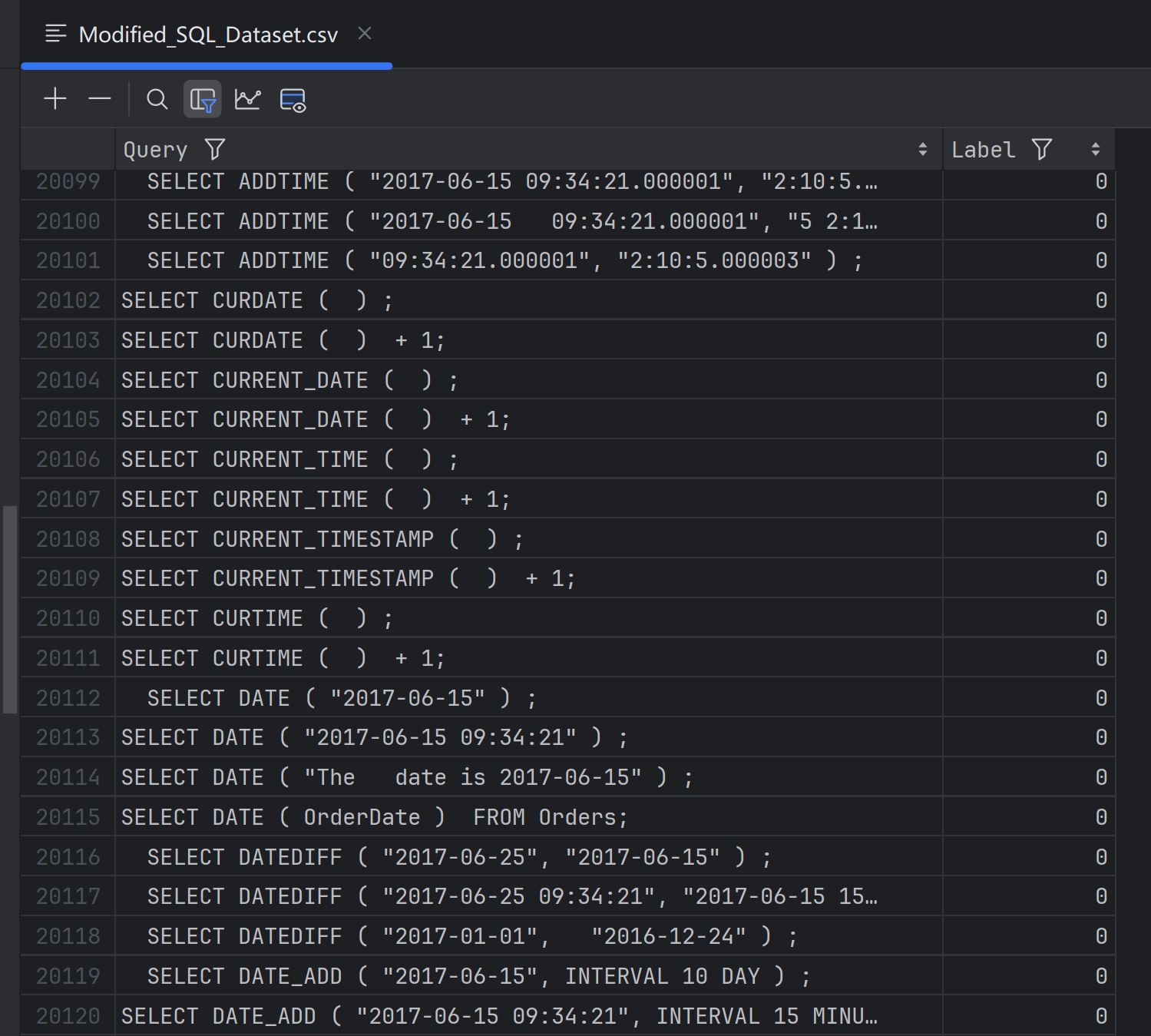
在这个数据集中,第一列就是sql语句,Label列是1就表示这个sql语句是非正常的sql注入:
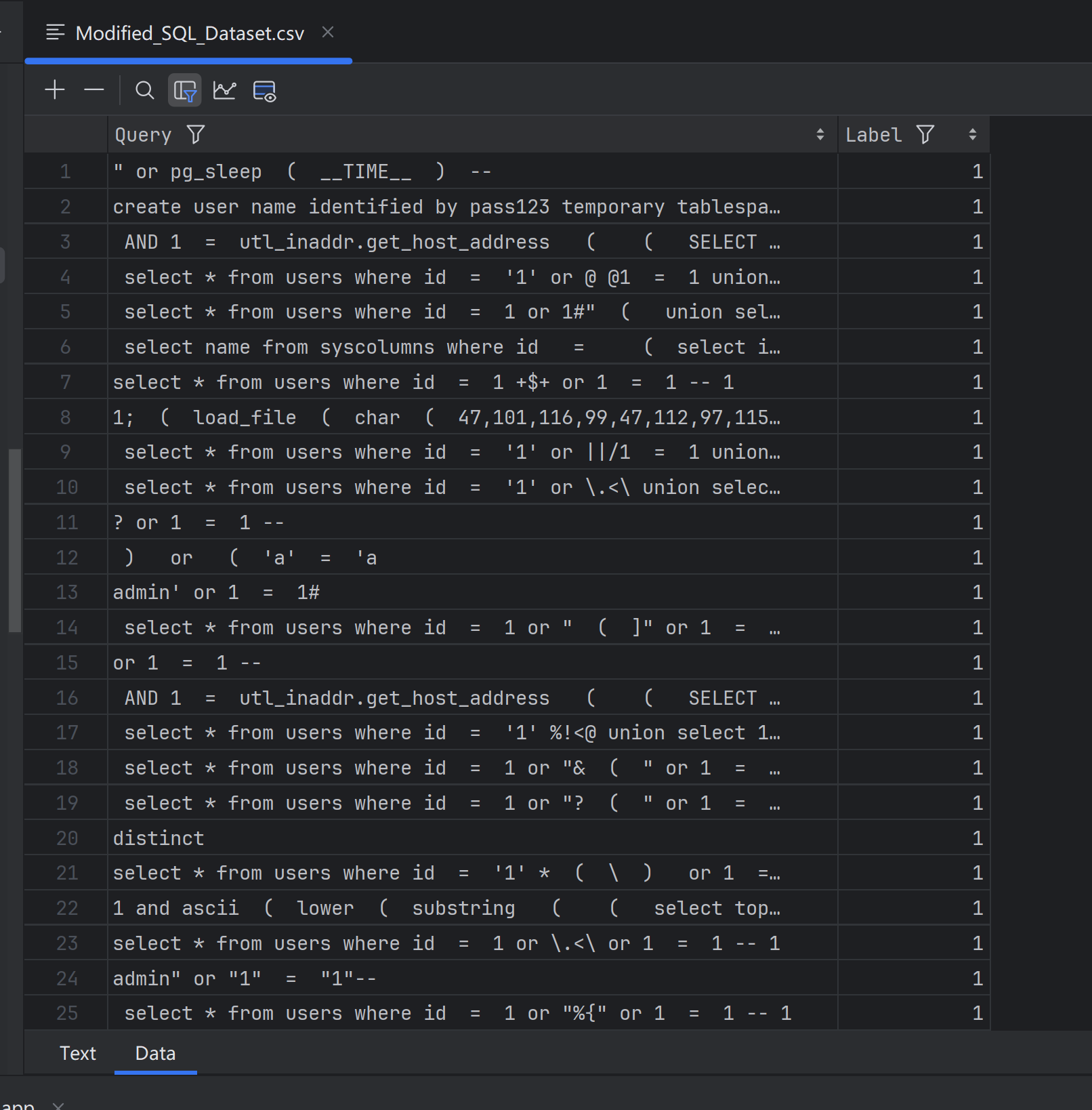
Label列是0就表示这个sql语句是正常的sql语句:
三、 深度学习模型
3.1. SQL注入识别任务
任务目标:输入sql字符串,模型判断出是正常sql语句还是不正常的sql语句。是个分类问题。
3.2. 使用全连接神经网络来做分类
这是部分代码:
# 使用 TF-IDF 权重来转换文本特征为数值特征
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(X_text)
# 对标签进行编码和one-hot编码
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
onehot_encoder = OneHotEncoder(sparse_output=False)
y_onehot = onehot_encoder.fit_transform(y_encoded.reshape(-1, 1))
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.3, random_state=42)
# 转换为PyTorch张量
X_train_tensor = torch.tensor(X_train.toarray(), dtype=torch.float32)
X_test_tensor = torch.tensor(X_test.toarray(), dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)
# 定义神经网络模型
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, output_size)
self.dropout = nn.Dropout(0.5)
self.init_weights()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
# 初始化参数,kaiming初始化
def init_weights(self):
for m in self.modules():
if type(m) == nn.Linear:
nn.init.kaiming_normal_(m.weight)
m.bias.data.fill_(0.01)
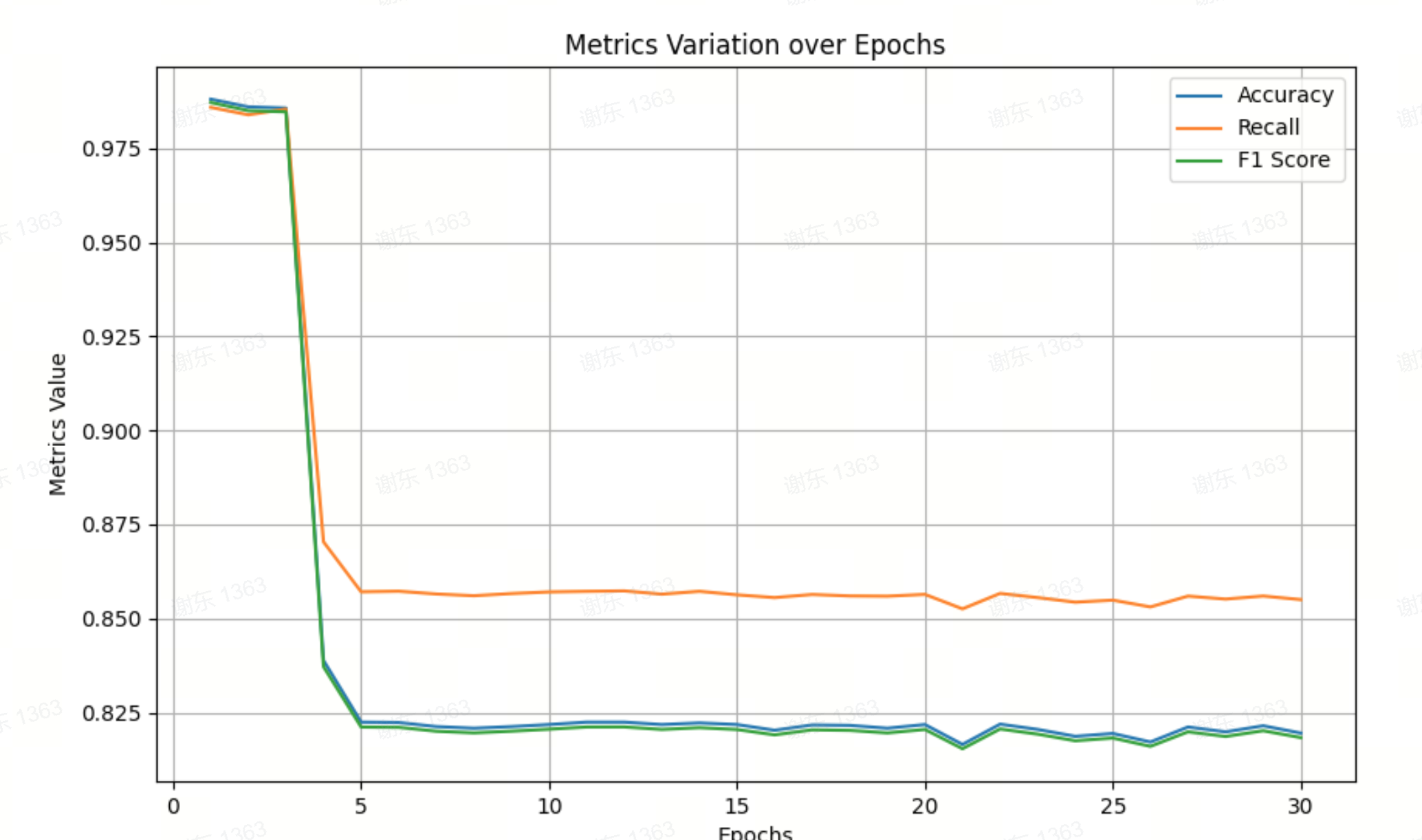
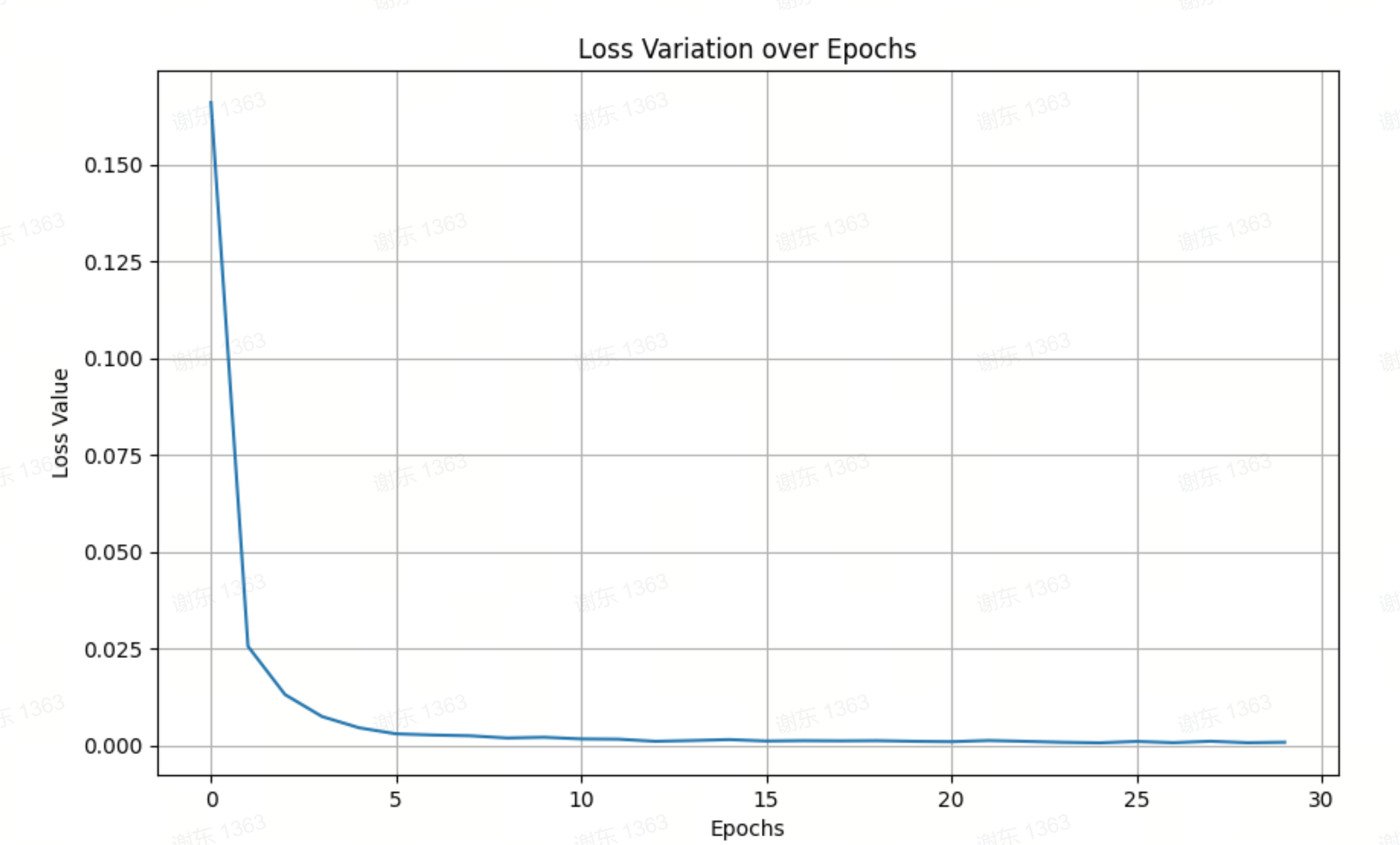
全连接神经网络来做分类在这个任务中是不可以的,原因是会过拟合,一开始的TfidfVectorizer不可取,下面是指标图和损失变化图,可以看出,这个模型是不行的。
3.3. 使用bert来做sql语句分类
这是部分代码:
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=len(label_encoder.classes_))
model.to(device)
# 设置优化器和学习率调度器
optimizer = AdamW(model.parameters(), lr=4e-6)
total_steps = len(train_loader) * 20 # 5 个周期
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
# 初始化指标存储字典
metrics_dict = {'accuracy': [], 'recall': [], 'f1_score': [], 'loss': []}
# 训练模型
model.train()
for epoch in range(20): # 5 个周期
total_loss = 0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1}", unit="batch"):
input_ids, attention_mask, labels = tuple(t.to(device) for t in batch)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_loss += loss.item()
loss.backward()
optimizer.step()
scheduler.step()
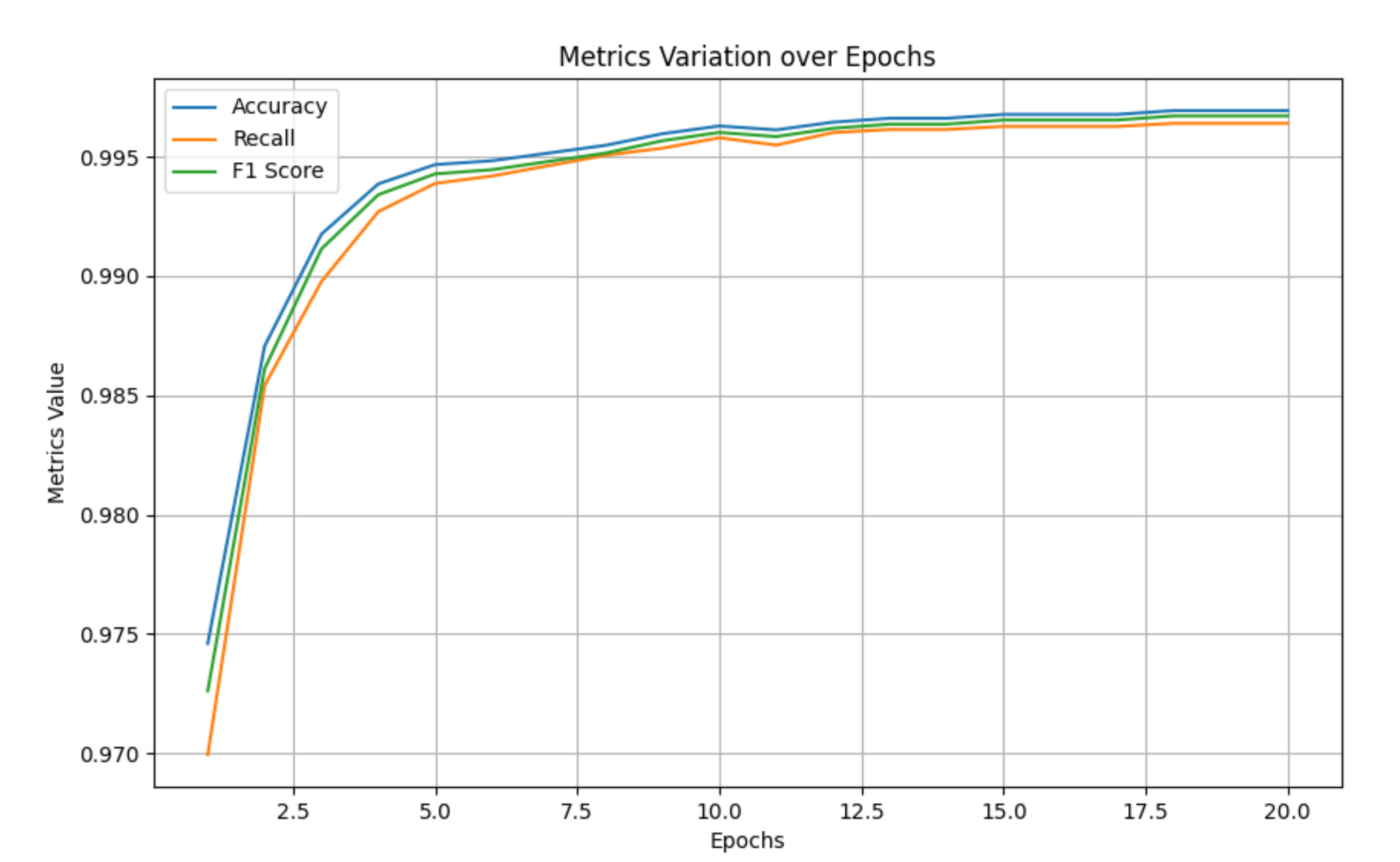
bert是可取的方法,相当于做字符串的分类,下面是bert的训练结果:
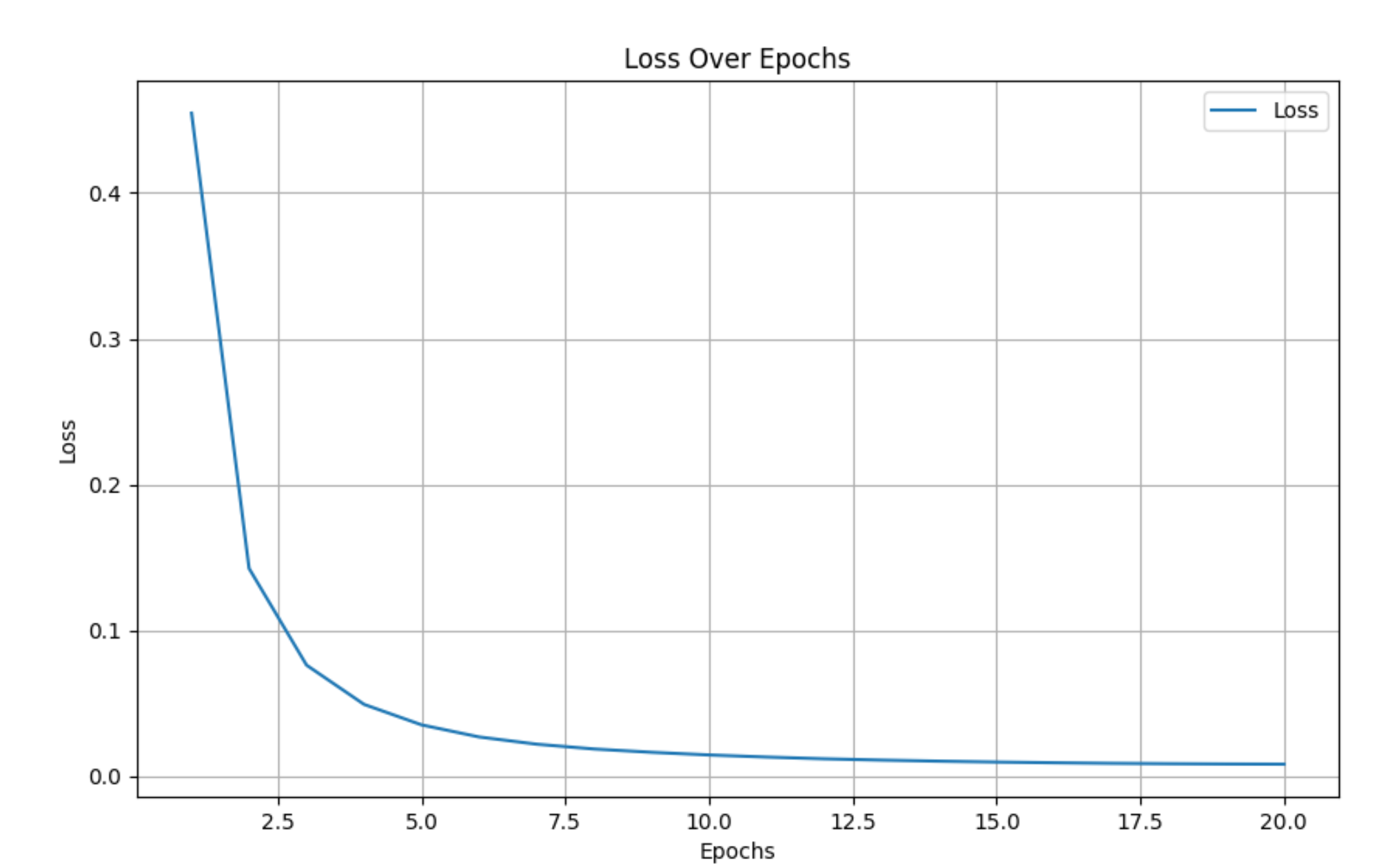
四、 深度学习模型的算法推理和部署
模型训练后保存为模型文件,部署就是直接用训练好的模型文件进行算法服务。
深度学习模型的算法推理指的是使用预训练的BERT模型对输入的SQL查询进行分类预测,判断其是否存在SQL注入的风险。下面我来解释一下代码中的主要步骤以及如何进行算法推理:
加载预训练模型和tokenizer:
- 使用
BertTokenizer.from_pretrained加载预训练的BERT模型的tokenizer,用于将输入的文本编码为模型可以理解的格式。 - 使用
BertForSequenceClassification.from_pretrained加载预训练的BERT模型,这是一个针对文本分类任务进行微调的模型。
- 使用
定义预测函数
predict:- 输入参数为需要进行分类预测的文本字符串。
- 使用tokenizer对输入文本进行编码,并确保与训练时使用的最大长度一致。
- 将编码后的文本数据移动到模型所在的设备(GPU或CPU)。
- 使用
model进行预测,并获取预测结果的类别和概率。 - 将预测结果格式化为易于理解的字符串形式,并返回包含预测结果和每个类别概率的字典。
示例使用模型进行预测:
- 给定一个SQL查询文本作为输入,调用
predict函数进行分类预测。 - 打印输出预测结果,包括预测的类别和其对应的概率。
- 给定一个SQL查询文本作为输入,调用
在这个过程中,模型的算法推理是指模型根据输入的文本数据,利用预训练好的权重和网络结构,计算出对应的预测结果。
结合gradio和fatapi,可以开启web界面和接口,运行代码后,web界面如下,可以输入一个sql字符串,然后模型判断这个字符串的类别:
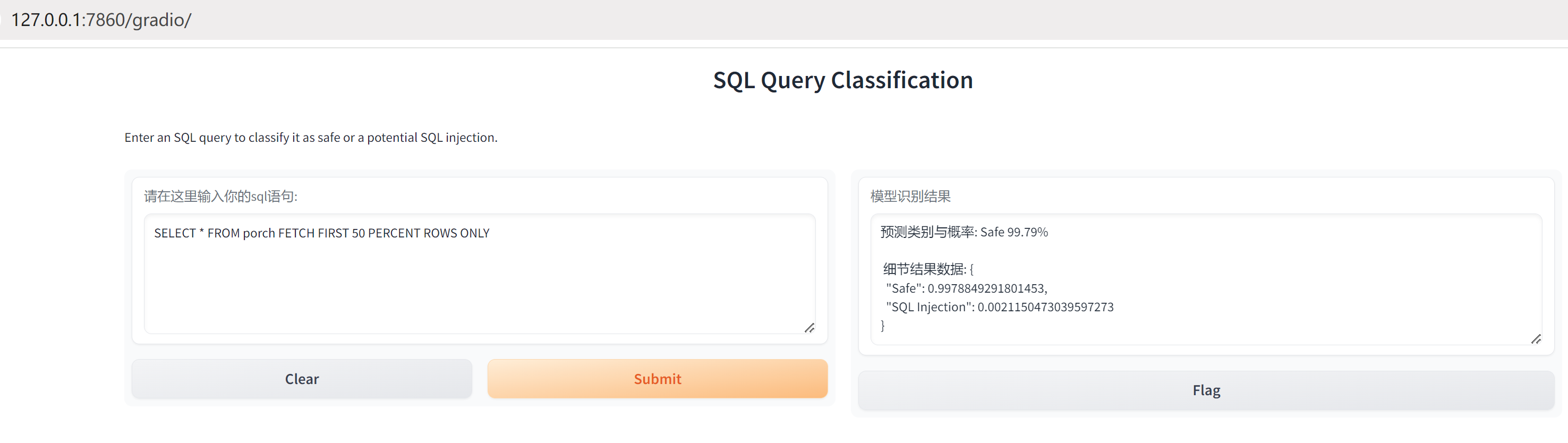
接口访问也是可以的,比如这样访问算法服务接口:
import requests
url = "http://127.0.0.1:7860/predict" # 确保这与您的FastAPI服务地址匹配
# 准备请求的数据
data = {
"text": "SELECT * FROM porch FETCH FIRST 50 PERCENT ROWS ONLY"
}
# 发送POST请求
response = requests.post(url, json=data)
# 处理响应
if response.status_code == 200:
result = response.json()
print("预测结果:", result)
else:
print(f"请求失败,状态码:{response.status_code}, 错误信息:{response.text}")
五、代码获取
这里获取:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
代码内容如下: