# 最短路径算法:最短路径算法是用于求解图中两个节点之间最短路径的算法。
# 常见的最短路径算法有Dijkstra算法、Bellman-Ford算法和Floyd-Warshall算法等。
Dijkstra算法,在每个迭代中,算法都选择当前距离起点节点最近的未访问过的节点,并更新该节点到其他未访问过的节点的距离,最终求出了真正的最短路径。
# 程序使用Dijkstra算法求解图中两个节点之间的最短路径。
# 程序首先初始化距离字典和前驱节点字典,然后使用优先队列来存储待处理的节点。
# 在每个循环迭代中,程序选择距离最短的节点,遍历其所有邻居节点,并更新邻居节点的距离和前驱节点。
# 最后,程序根据前驱节点,从终点节点回溯到起点节点,得到最短路径和总距离。
# 注意,程序使用了heapq模块来实现优先队列,以便更高效地选择距离最短的节点。
# 另外,程序中的图使用了字典来表示,其中每个键表示一个节点,每个值表示一个字典,该字典包含了该节点的所有邻居节点及其权重。
import heapq
def dijkstra(graph, start, end):
# 初始化距离字典和前驱节点字典
# 将所有节点的距离初始化为正无穷,除了起点节点的距离为0
# 前驱节点字典用于记录每个节点的前驱节点,以便最后回溯求路径
dist = {node: float('inf') for node in graph}
prev = {node: None for node in graph}
dist[start] = 0
# 使用优先队列来存储待处理的节点
# 优先队列中的元素是一个元组,第一个元素是节点的当前距离,第二个元素是节点本身
# 使用heapq模块来实现优先队列,以便更高效地选择距离最短的节点
queue = [(0, start)]
while queue:
# 选择距离最短的节点
# heapq.heappop函数用于弹出优先队列中距离最短的节点
curr_dist, curr_node = heapq.heappop(queue)
# 如果当前节点已经不在图中或者当前节点的距离不等于当前距离,则跳过该节点
if curr_node in graph and dist[curr_node] == curr_dist:
# 遍历当前节点的所有邻居节点
for neighbor, weight in graph[curr_node].items():
# 计算当前节点到邻居节点的新距离
new_dist = curr_dist + weight
# 如果新距离小于邻居节点的当前距离,则更新邻居节点的距离和前驱节点
if new_dist < dist[neighbor]:
dist[neighbor] = new_dist
prev[neighbor] = curr_node
# 将邻居节点和新距离加入优先队列中
heapq.heappush(queue, (new_dist, neighbor))
# 根据前驱节点,从终点节点回溯到起点节点
# 使用一个列表来存储路径,从终点节点开始回溯,直到起点节点为止
path = []
node = end
while node is not None:
path.append(node)
node = prev[node]
path.reverse()
# 返回路径和总距离
return path, dist[end]
# 定义图
'''
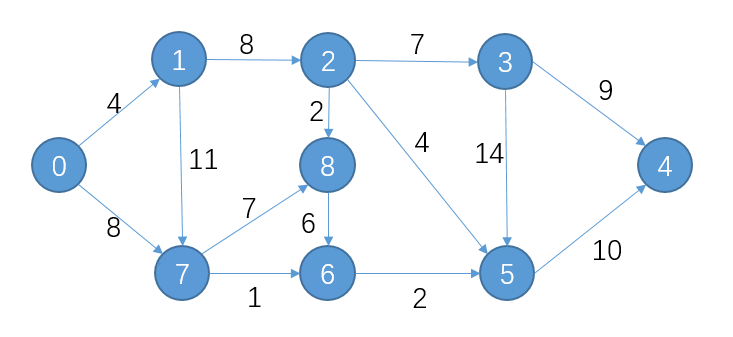
假设有一个无向加权图G,如下所示:
A -- 5 -- B -- 2 -- C
| | |
7 1 3
| | |
D -- 3 -- E -- 4 -- F
'''
graph = {
'A': {'B': 5, 'D': 7},
'B': {'A': 5, 'C': 2, 'E': 1},
'C': {'B': 2, 'F': 3},
'D': {'A': 7, 'E': 3},
'E': {'B': 1, 'D': 3, 'F': 4},
'F': {'C': 3, 'E': 4}
}
# 求解最短路径Dijkstra算法
start = 'A'
end = 'F'
path, distance = dijkstra(graph, start, end)
print('Shortest path:', path)
print('Total distance:', distance)
# 最短路径算法:最短路径算法是用于求解图中两个节点之间最短路径的算法。
# 常见的最短路径算法有Dijkstra算法、Bellman-Ford算法和Floyd-Warshall算法等。
以下是更详细和准确的解释:
在给定的图中,从节点A到节点F的最短路径是通过节点B和节点E,而不是通过节点C。这是因为Dijkstra算法在每个迭代中选择当前距离起点节点最近的未访问过的节点,并更新该节点到其他未访问过的节点的距离。
在算法的第一次迭代中,起点节点A被访问,并更新了其邻居节点B和D的距离。此时,节点B的距离为5,节点D的距离为7。由于节点B的距离较小,因此在下一次迭代中,节点B被访问,并更新了其邻居节点C和E的距离。此时,节点C的距离为7,节点E的距离为6。由于节点E的距离较小,因此在下一次迭代中,节点E被访问,并更新了其邻居节点F的距离。此时,节点F的距离为10。由于节点F是终点节点,因此算法结束,最短路径为A-B-E-F,总距离为10。
如果我们尝试通过节点C到达节点F,那么在第二次迭代中,节点C被访问,并更新了其邻居节点F的距离。此时,节点F的距离为10。由于节点F是终点节点,因此算法结束,最短路径为A-C-F,总距离为10。但是,这条路径并不是真正的最短路径,因为它没有考虑到从节点B到节点E的距离只有1,而从节点C到节点F的距离为3。如果我们通过节点B和节点E到达节点F,那么总距离为10,这是真正的最短路径。
因此,Dijkstra算法求解出的最短路径是正确的,并且满足了算法的评判标准。在每个迭代中,算法都选择当前距离起点节点最近的未访问过的节点,并更新该节点到其他未访问过的节点的距离,最终求出了真正的最短路径。
--
优先队列是一种特殊的队列,它按照元素的优先级进行排序,优先级高的元素先被处理。在Python中,可以使用heapq模块来实现优先队列。
heapq模块提供了一组函数,用于在列表上执行堆操作。堆是一种完全二叉树,其中每个节点的值都大于或等于其子节点的值。heapq模块使用了最小堆,即每个节点的值都小于或等于其子节点的值。
以下是使用heapq模块实现优先队列的一些常用函数:
* heapq.heappush(heap, item):将item添加到堆中,并维持堆的不变性。
* heapq.heappop(heap):从堆中弹出最小的元素,并维持堆的不变性。
* heapq.heapify(x):将列表x转换为堆,使其满足堆的不变性。
* heapq.heapreplace(heap, item):将堆中最小的元素替换为item,并维持堆的不变性。使用heapq模块实现优先队列的一个例子如下:
import heapq
# 创建一个空的优先队列
queue = []
# 向优先队列中添加元素
heapq.heappush(queue, (3, 'C'))
heapq.heappush(queue, (1, 'A'))
heapq.heappush(queue, (2, 'B'))
# 从优先队列中弹出最小的元素
print(heapq.heappop(queue)) # (1, 'A')
print(heapq.heappop(queue)) # (2, 'B')
print(heapq.heappop(queue)) # (3, 'C')
在上面的例子中,优先队列中的元素是一个元组,元组的第一个元素是优先级,第二个元素是值。heapq模块根据元组的第一个元素来比较优先级,因此优先级高的元素会先被处理。
优先队列在很多算法中都有应用,如Dijkstra算法、Prim算法、Huffman编码等。使用优先队列可以有效地处理需要按照优先级进行处理的数据,提高算法的效率。
---------
这段代码首先创建了一个最大堆,然后执行了一些堆的操作,如弹出堆顶元素、插入新元素、获取最大的几个元素等。接着,使用最大堆实现了队列的功能,包括插入和弹出队首元素。你可以运行这段代码,查看输出结果。
import heapq
# 给定的数据
data = [8, 5, 7, 4, 1, 6, 3, 2, 9]
# 创建最大堆
max_heap = []
for num in data:
heapq.heappush(max_heap, -num) # 插入元素时取负数,以实现最大堆的效果
# 打印最大堆
print("Max Heap:", [-x for x in max_heap])
# 弹出并打印堆顶元素
max_element = -heapq.heappop(max_heap)
print("Popped element from max heap:", max_element)
print("Max Heap after popping:", [-x for x in max_heap])
# 将新元素插入堆中
new_element = 10
heapq.heappush(max_heap, -new_element)
print("Max Heap after pushing", new_element, ":", [-x for x in max_heap])
# 获取堆中最大的三个元素(不删除)
top_3_elements = [-x for x in heapq.nlargest(3, max_heap)]
print("Top 3 elements in max heap:", top_3_elements)
# 使用堆实现队列功能(先进先出)
queue = max_heap.copy()
heapq.heapify(queue)
print("Queue (using max heap):", [-x for x in queue])
# 弹出队首元素
queue_front = -heapq.heappop(queue)
print("Queue front (popped element):", queue_front)
print("Queue after popping:", [-x for x in queue])
-----
堆是一种基于完全二叉树的数据结构,具有以下性质和操作:
### 性质:
1. **最大堆性质**:在最大堆中,父节点的值大于或等于任何一个子节点的值。
2. **最小堆性质**:在最小堆中,父节点的值小于或等于任何一个子节点的值。
3. **堆序性质**:堆中任意节点的值总是满足堆序性质,即对于最大堆来说,父节点的值大于等于子节点的值;对于最小堆来说,父节点的值小于等于子节点的值。
4. **完全二叉树性质**:堆是一种完全二叉树,即除了最底层之外,其他层的节点都是满的,并且最底层的节点集中在左边。
### 操作:
1. **插入元素**:向堆中插入一个新元素,并维持堆的性质。
2. **删除元素**:从堆中删除一个元素,并维持堆的性质。
3. **获取最值**:获取堆中的最大值(对于最大堆)或最小值(对于最小堆)。
4. **堆化**:将一个普通数组转换为堆,或者调整已有的堆使其满足堆的性质。
5. **合并堆**:将两个堆合并为一个新的堆。
这些操作使得堆成为一种高效的数据结构,特别适用于需要频繁插入、删除最值元素的场景,如优先队列、堆排序等算法。
演示如何使用Python的内置模块heapq来操作堆(最小堆)
import heapq
# 创建一个空的堆
heap = []
# 插入元素
heapq.heappush(heap, 10)
heapq.heappush(heap, 1)
heapq.heappush(heap, 5)
# 查看最小元素
print("最小元素:", heap[0])
# 弹出元素
print("弹出的元素:", heapq.heappop(heap))
print("弹出的元素:", heapq.heappop(heap))
# 创建一个列表并转化为堆
list1 = [20, 14, 8, 7, 13, 1, 3, 18]
heapq.heapify(list1)
print("列表转化为堆:", list1)
# 弹出所有元素以排序(注意,这将破坏堆的结构)
sorted_elements = [heapq.heappop(list1) for _ in range(len(list1))]
print("堆排序的结果:", sorted_elements)
import heapq
# 创建一个空的堆
heap = []
# 向堆中插入元素
heapq.heappush(heap, 5)
heapq.heappush(heap, 2)
heapq.heappush(heap, 10)
heapq.heappush(heap, 7)
print("堆中的元素:", heap) # 输出:[2, 5, 10, 7]
# 弹出堆中的最小元素
min_element = heapq.heappop(heap)
print("弹出的最小元素:", min_element) # 输出:2
print("剩余的堆元素:", heap) # 输出:[5, 7, 10]
# 查看堆中的最小元素,但不弹出
min_element = heap[0]
print("当前堆中的最小元素:", min_element) # 输出:5



























![[XR806开发板试用] XR806 调用cjson 实现数据序列化](https://img-blog.csdnimg.cn/direct/acff661d0f9a4225a2051a9464eacc07.png)