目录
深度优先搜索(Depth-First Search, DFS)
广度优先搜索算法(Breadth-First Search,BFS)
概念:一个图中所有点之间至少存在一条路径(路径:一个点有一条路到达另一个点)的图
图片来自网图,涉及侵权请联系我删除
如果有遗漏的,请在评论区告诉我,会更新!
基本结构·头文件
#include<bits/stdc++.h>这是万能头文件, 只用写它,就可以了。
但如果你不想用万能头文件,下面几个常用头文件你一定要学会!
#include<iostream>//输入输出,类型有int,float,double,string等
#include<cmath>//涵盖了大量的数学公式,方便计算
#include<algorithm>//求最大值 "max()" , 求最小值 "min()" ,排序函数 "sort()" 等用途
基本结构·输入输出
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a;//定义变量
cin>>a;//输入变量
printf("%d",a);//输出变量
return 0;
}
注:cout也可以输出,scanf和printf要比cin和cout快一些
变量可以初始化,如果没有给变量设定初始值,变量将被初始化为默认值,比如:
| 数据类型 | 关键词 | 占位符 |
|---|---|---|
| 整型 | int | %d |
| 双精度浮点型 | double | %lf |
| 字符型 | char | %c |
int a; //没有初始化,变量a未定义
int b=0; //初始化为 0
double c=1.5; //初始化为1.5
char d='a'; //初始化为字符'a'判断
if语句:if语句由一个布尔表达式后跟一个或多个语句组成。如果布尔表达式为true,则if语句内的代码块将被执行。如果布尔表达式为false,则if语句结束后的第一组代码(闭括号后)将被执行。C语言把任何非零和非空的值假定为true,把零或null假定为false。
if…else语句:一个if语句后可跟一个可选的else语句,else语句在布尔表达式为假时执行。如果布尔表达式为true,则执行if块内的代码。如果布尔表达式为false,则执行else块内的代码。
switch语句:switch语句用于测试多种条件。它的语法格式为:switch(表达式){ case值1: 当表达式的值等于值1时,执行这里的代码;case值2: 当表达式的值等于值2时,执行这里的代码;default: 如果表达式的值与所有case都不匹配,则执行这里的代码。
三目运算符:结果=(条件)?表达式1:表达式2; 如果条件为真,返回表达式1的值;如果条件为假,则返回表达式2的值。
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin>>n;
if(n%2==0)
{
cout<<n<<"是偶数";
}
else
{
cout<<n<<"是奇数";
}
return 0;
}这就是一个判断奇偶数的代码
一维数组·循环
while循环:
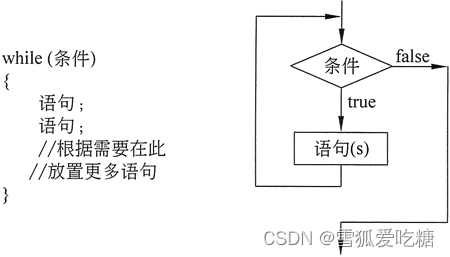
while(循环条件(注意不是终止条件))
{
循环内容;
}比如我们可以这样使用:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int i=1;
while(i<=10)
{
if(i<10)
{
cout<<"作者正在疯狂更新";
}
else if(i==10)
{
cout<<"作者停止爆肝了";
}
}
return 0;
}输出结果为:
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者正在疯狂更新
作者停止爆肝了
for循环:
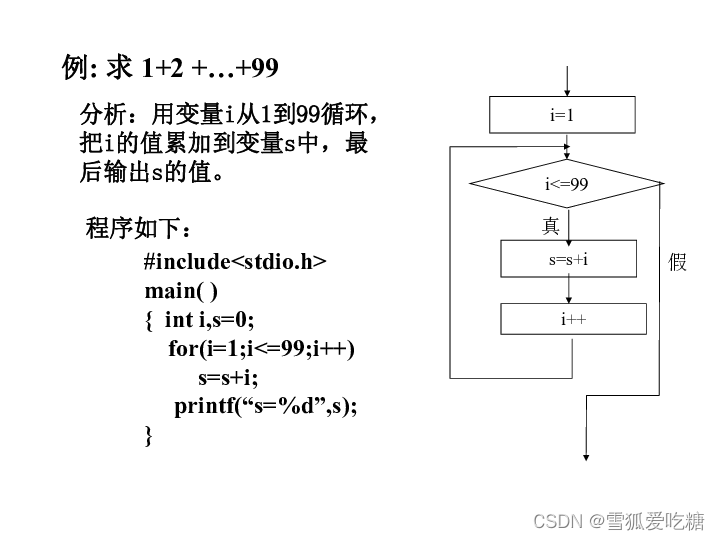
for(单次表达式;条件表达式;末尾循环体)
{
循环体
}
#include<bits/stdc++.h>
using namespace std;
int main()
{
for(int i=1;i<=10;i++)
{
if(i<10)
{
cout<<"作者正在疯狂更新";
}
if(i==10)
{
cout<<"作者停止爆肝了";
}
}
return 0;
}for与while不同,for会执行完所有代码,而while不会。
数组:
变量仅能存放一个数据,而数组能存放多个数据。
而且数组可以通过下标来访问相关数据,在C++中,我们常常用循环来遍历数组元素。
怎么定义?
其实非常简单!首先先确定数组是什么类型(如bool,void,int,long,long long等)
然后确定数组名,在数组名后加一个[ ]就行了,接下来就必须确定长度了,在题目中,一般会给出数据范围等提示,我一般会在给定范围加一个5,这样能确保数组不会爆!
接下来,我来为大家演示正确定义方式:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[10005];
return 0;
}P.S.:[ ]里可以不用写数字!不会报错,但要加上赋值!
需制空是因为数组未定义时,里面是随机数,会出错,但是制空了就没事了
制空有2种常用的方法!
法1:定在全局,优点:
设在全局,自动制空
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[10005];
return 0;
}法2:优点:可以定义数组内的数
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[10005]={};
return 0;
}遍历
其实很简单,用for循环就行,请看我演示:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[100005],n;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
}
return 0;
}输出把cin换成cout就行注意事项:
1.不能把一个数组直接赋值给另一个数组,比如这样:arr2 = arr;
2.不能使用一个数组初始化另一个数组,比如:int arr2[] = arr;
3.数组过大,无法通过编译
4.允许定义数组的指针及数组的引用,但不存在引用的数组快速排序
稳定排序,不稳定排序是什么?时间复杂度是什么?
如果 a 原本在 b 的前面(a==b)排序之后 a 仍然在 b 的前面,则称为稳定排序
反之,为不稳定排序。如选择排序,希尔排序等均为不稳定排序
时间复杂度:一个算法执行所用的时间
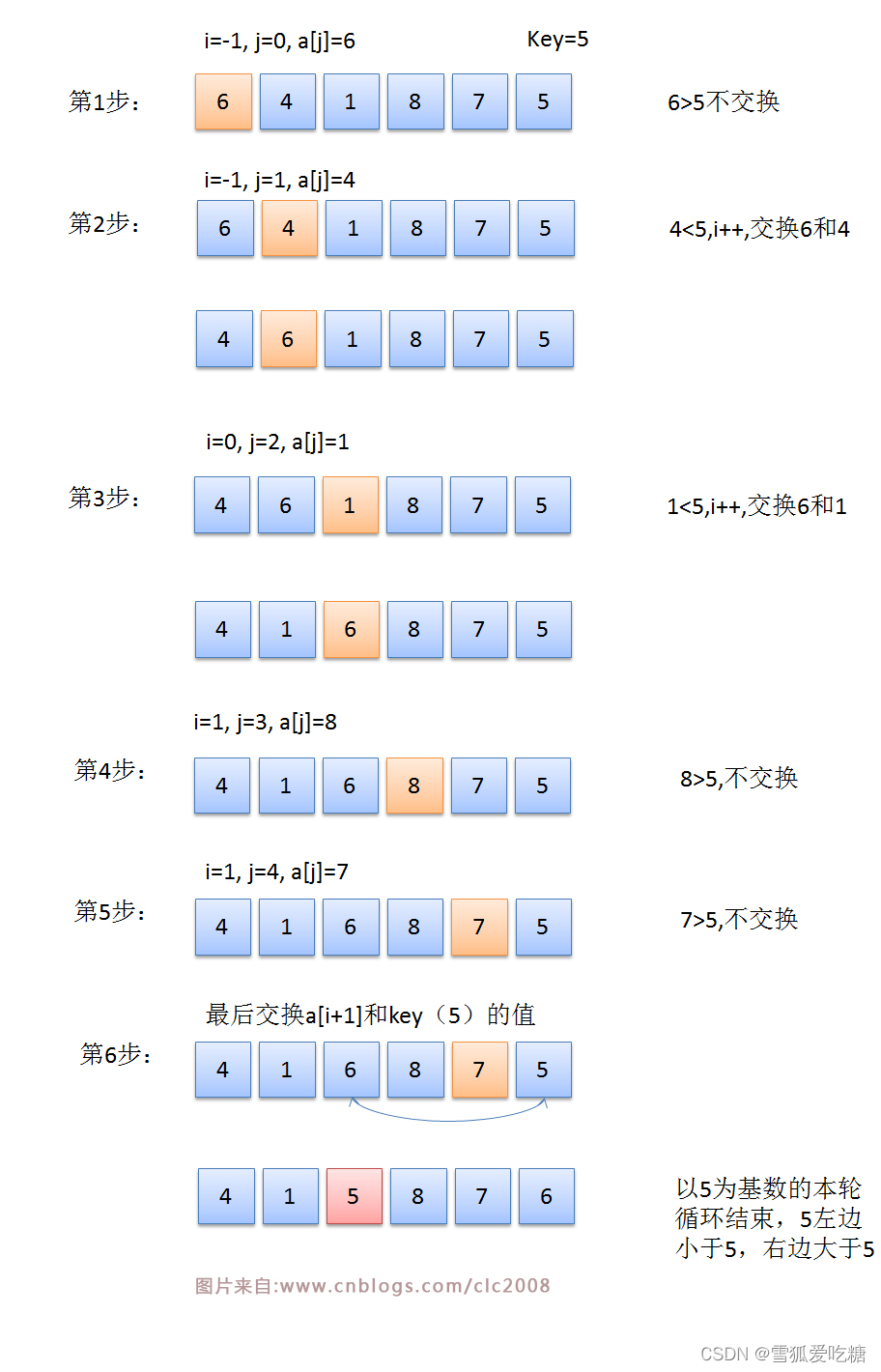
快速排序简称快排,时间复杂度:O(nlogn) 、空间复杂度:O(logn)
性质:不稳定排序,最坏情况下快排可能会退化到O(n2)
一个补充:代码中的return x<y意思是从小到大,return x>y是从大到小
代码(函数sort版):
#include<bits/stdc++.h>
using namespace std;
bool cmp(int x,int y)//注意注意,不要写成int x,y 会报错!
{
return x<y;//从小到大,从大到小为return x>y
}
int main()
{
int a[5]={4,7,2,1};
sort(a,a+n,cmp);//如第一个要填a[2]等具体数组位,要用&号
return 0;
}那么不用sort的方法怎么做?请看下面:
int p(int arr[], int left, int right)
{
int pi=arr[left];
int i=left+1;
int j=right;
while(1)//死循环
{
//向右遍历扫描
while(i<=j&&arr[i]<=pi) i++;
//向左遍历扫描
while(i<=j&&arr[j]>=pi) j--;
if(i>=j)
break;
//交换
int temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;//可以用交换函数swap
}
//把arr[j]和主元交换
arr[left]=arr[j];
arr[j]=pi;
return j;
}函数
定义:
C++中的函数,是一段可重用的代码,用于执行特定的任务。它由一个函数头和一个函数主体组成,函数头包括函数名称和参数列表,函数主体包含定义函数执行任务的语句。函数可以返回一个值,这个值的数据类型由返回类型指定,如果没有返回值,则返回类型是关键字void。函数可以被多次调用,并且在程序中被调用时,会执行其内部的代码块。
C++中的函数可以分为库函数和自定义函数两种。库函数是C++标准库或其他系统库中提供的函数,可以直接使用。自定义函数是由开发者自行编写的函数,用于实现特定的功能。自定义函数的定义可以在main函数之前或之后,只要在使用函数之前有函数声明即可。
函数的声明和定义可以分别在不同的源文件中实现,这种方式可以方便地实现模块化编程和代码复用。函数的声明通常包括函数名、参数列表和返回类型,它告诉编译器这个函数的存在和类型,以便编译器在调用该函数时能够正确地生成调用代码。函数的定义是提供函数实际执行的代码块。
(来源于百度)
定义方式:

#include<bits/stdc++.h>
using namespace std;
bool f(int x,int y)//有参函数
{
if(x>y)
{
return x;
}
return y;
}
int main()
{
int n,m;
cin>>n>>m;
cout<<f(n,m);
return 0;
}我们可以这样写,调用函数的结构:
函数名(参数,参数)【可以有多个参数甚至没有参数】
C++自带的好用&常见函数
sqrt(x) //计算x的平方根
pow(x,n)//计算x的n次幂
abs(x) //计算x的绝对值
ceil(x) //对x进行向上取整操作
floor(x)//对x进行下取整操作
深度优先搜索(Depth-First Search, DFS)
深度优先搜索是一种递归的搜索算法,它从一个节点开始,沿着一条路径一直搜索到底,直到没有未访问的节点,然后回溯到上一个节点,继续搜索其他路径。
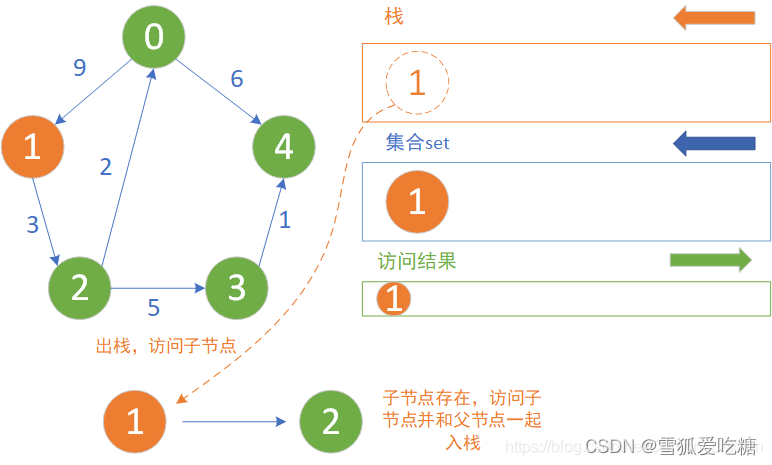
题目
现有m个球放在一个盒子里,球的编号依次为1,2,3,4,5……m, 现在要从盒子里摸出一个球查看编号后放回盒子里,一共要摸n次 输出所有查看的情况。
输入格式
输入两个正整数m n
输出格式
输出所有的摸球情况
每种情况可以组成一个数字,也可以看成是字符串,输出时按照字典序从小到大输出
1≤n≤m≤7
样例 #1
样例输入 #1
3 2
样例输出 #1
11
12
13
21
22
23
31
32
33
#include<bits/stdc++.h>
using namespace std;
int q[10];
int m,n;
void dfs(int k)
{
if(k>n)
{
for(int i=1;i<=n;i++)
{
printf("%d",q[i]);
}
printf("\n");
return;
}
for(int i=1;i<=m;i++)
{
q[k]=i;
dfs(k+1);
}
}
int main()
{
cin>>m>>n;
dfs(1);
return 0;
}提示
3个球 摸两次 摸完查看之后可以放回
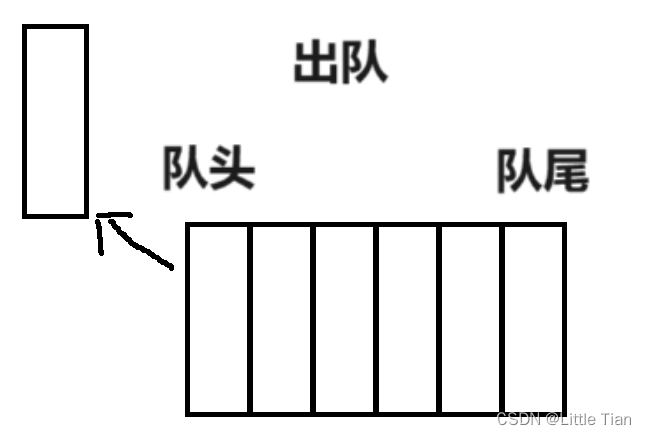
队列
在C++中,队列是一种线性数据结构,遵循先进先出(FIFO)原则
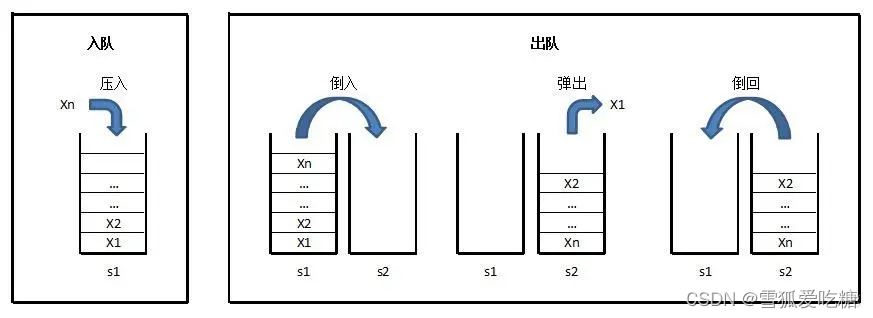
queue<int> que;//创建队列
que.push(x); //入队
que.pop(); //出队
que.front(); //返回队头
que.back(); //返回队尾
que.empty(); //队列是否为空
que.size(); // 队列长度
广度优先搜索算法(Breadth-First Search,BFS)
它是一种盲目搜寻法,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
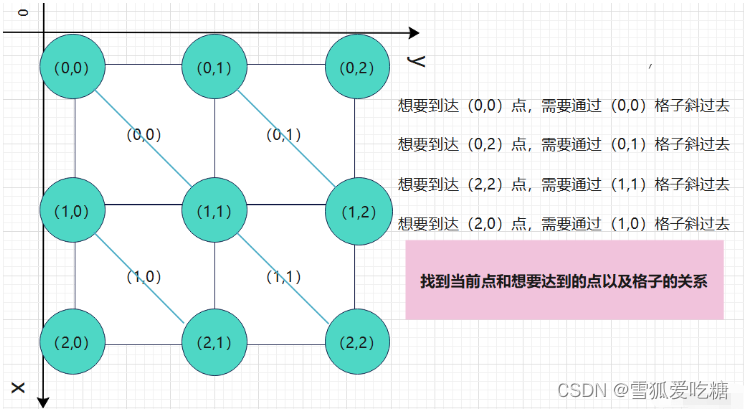
例题
小A住的小区是长方形的,被划分成一个个格子。小A想从家里去学校上课,小A每次可以走到他前后左右四个格子中的其中一个,但不能斜着走,也不能走出街道。
现在给出地图:
S:代表小A的家
T:代表学校
.:代表道路
X:代表墙壁
小A不能穿过墙壁。
输入格式
一行输入n(1<=n<=500),m(1<=m<=500)代表城市的长和宽,接下来n行每行m个字符,描述城市中的每个格子。
输出格式
如果小A能到达学校,输出走到此处的最短步数,否则输出-1。
样例
输入样例1
10 10
XSXXXXXX.X
......X..X
.X.XX.XX.X
.X........
XX.XX.XXXX
....X....X
.XXXXXXX.X
....X.....
.XXXX.XXX.
....X...TX
输出样例1
23代码:
#include<bits/stdc++.h>
using namespace std;
const int N=505;
char mat[N][N];//表示地图
bool vis[N][N];// vis[x][y] 表示第x行第y列有没有走过
int step[N][N];//step[x][y] 表示起点到达第x行第y列的最少步数
int n,m;
struct node{
int x,y;
};
void bfs(int sx,int sy)//起点的行列数
{
queue<node> que;//创建结构体队列
step[sx][sy]=0;//起点的最少步数
vis[sx][sy]=true;//起点走过了
que.push((node){sx,sy});//强制将sx,sy转换为node类型,入队
while(!que.empty())//队列不为空
{
node now=que.front();
que.pop();
if(mat[now.x][now.y]=='T')
{
printf("%d",step[now.x][now.y]+1);
return;
}
int dx[]={0,0,-1,1};
int dy[]={-1,1,0,0};
for(int i=0;i<4;i++)
{
int tx=now.x+dx[i];
int ty=now.y+dy[i];
if(tx<1||tx>n||ty<1||ty>m||mat[tx][ty]=='X'||vis[tx][ty])
{
continue;
}
step[tx][ty]=step[now.x][now.y]+1;
vis[tx][ty]=true;
que.push((node){tx,ty});
}
}
printf("-1");
}
int main()
{
cin>>n>>m;
int sx,sy;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
cin>>mat[i][j];
if(mat[i][j]=='S')
{
sx=i;
sy=j;
}
}
}
bfs(sx,sy);
return 0;
}栈·基本操作
//stack<int> sta;//创建一个栈
//sta.push(a);//入栈
//int a=sta.top();//返回栈顶元素
//sta.pop();//出栈
//sta.empty();//判断栈是否为空 1为空,0为非空
//sta.clear();//清空二分查找·仅用于排序的序列
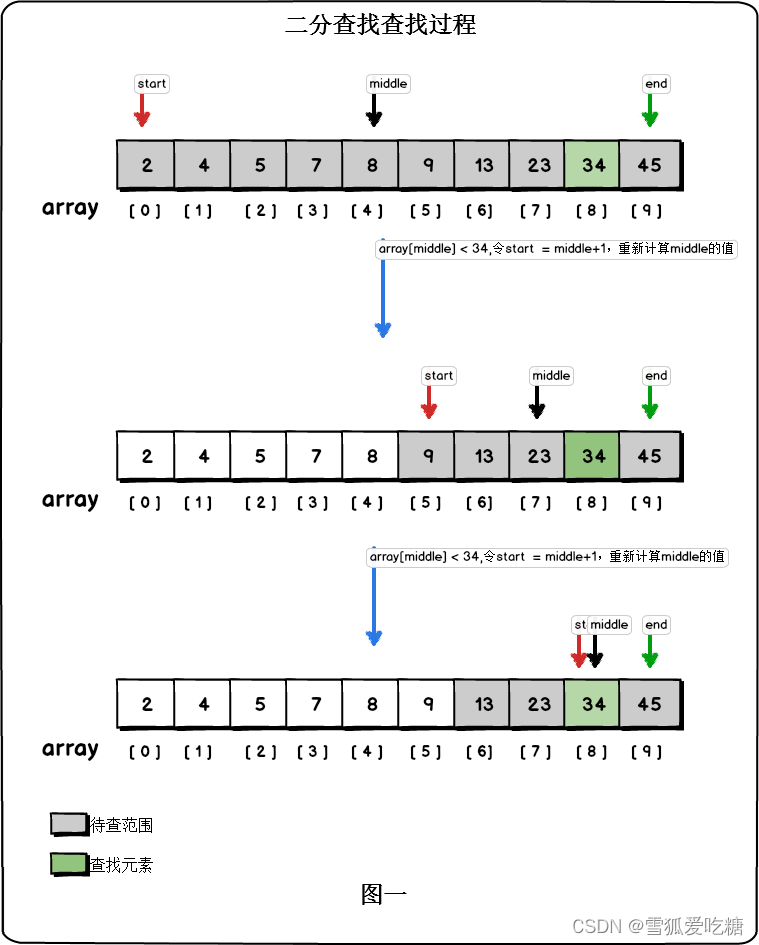
步骤:
1.确定区间
2.若不存在,返回false
3.每次取中间值,用(左元素+右元素)/2
模板:
int erfen(int c[],int b,int g){
int tou=0,wei=b-1;
while(tou<=wei){
int mid=(tou+wei)/2;
if(c[mid]>=g){
wei=mid-1;
}else if(c[mid]<g){
tou=mid+1;
}
}
if(c[tou]==g){
return tou+1;
}
return false;
}
字符串(string)基本使用
基本定义
string 字符串名;
初始化
string 字符串名 = "赋值内容";
基本输入
1、不带空格输入 cin >> 字符串名;
2、带空格输入 getline(cin,字符串名);
基本输出
cout << 字符串 ;
基本函数
1、+ += > < == != >= <=
2、求string的长度 字符串名.size();
删除子串
string s1 = "Real Steel";
s1.erase(1, 3); //删除从位置1开始后面的3个字符,此后 s1 = "R Steel"
插入子串
string s1 = "Limitless", s2="00";
s1.insert(2, "123"); //在下标 2 处插入字符串"123",s1 = "Li123mitless"
查找子串
string s1 = "apple people";
s1.find("ple"); //查找 "ple" 出现的位置 返回值为子串第一次出现的下标返回值为2
s1.find("ple",5); //从下标为5的地方查找"ple"的位置,返回值为9
s1.find("orange"); //查找"orange"的位置,没有查找到,所以返回-1
遍历字符串
string str;
cin >> str;
int len = str.size();
for(int i=0;i<len;i++)
{
printf("%c",str[i]);
}
特别注意
字符串的整体输入输出不能使用scanf()和printf()
字符数组
#include<bits/stdc++.h>
//#include<cstring>为字符串头文件
using namespace std;
int main(){
char a[10]="abc";
char b[10]="123";
strcpy(b,a); //复制
//cout<<b<<endl;
strcat(b,a); //拼接
//cout<<b<<endl;
//cout<<strcmp(a,b);//比较(a==b返回0,a>b返回1,a<b返回-1)
strlen(a); //获取长度
return 0
}
特别提醒:可以使用整体输入或输出(cin,cout)
字符数组类型转换
#include<bits/stdc++.h>
using namespace std;
int main(){
char b[10]="3.14";
double a=atof(b); //字符串数组char转double
//cout<<a+0.1<<endl;
char b1[10]="114514";
int c=atoi(b1); //字符串数组char转int
//cout<<c-4<<endl;
char b2[20]="12345678912345";
long long d=atoll(b2); //字符串数组char转long long
//cout<<d+1<<endl;
char b3[20]="114514";
char *p;
int e=strtoll(b3,&p,10);
//cout<<e;
return 0;
}
基本操作:
#include<bits/stdc++.h>
using namespace std;
int main(){
string s;
cin>>s; //不能获取空格
getline(cin, s); //能获取带空格的字符串
s.length(); //获取长度
cout<<s.substr(3, 4); //截取子串 参数1:字串起始位置,参数2:字串的长度
cout<<s.find("12"); //查找字串,输出字串的起始位置
s.clear(); // 清空字符串
return 0;
}
双端队列是什么
双端队列就是一个两端都是结尾的队列,队列的每一端都可以插入数据和移除数据
双端队列是限定插入和删除操作在表的两端进行的线性表,是一种具有队列和栈的性质的数据结构
可以用一个铁道转轨网络来比喻双端队列,在实际使用中,还可以有输出受限的双端队列(即一个端点允许插入和删除,另一个端点只允许插入的双端队列),和输入受限的双端队列(即一个端点允许插入和删除,另一个端点只允许删除的双端队列),而如果限定双端队列从某个端点插入的元素只能从该端点删除,则该双端队列就蜕变为两个栈底相邻的栈了
双端队列怎么用
基本操作与普通队列没啥区别,只不过两边都能进或出罢了
deque<int> que;//创建一个双端队列 que
队名.push_front(5);//向前插入5
队名.push_back(4);//向后插入4
队名.pop_back();//删除队尾
队名.pop_front();//删除队头
队名.front();//查看队头
队名.back();//查看队尾
队名.size();//队列元素个数
队名.empty();//队列是否为空
!队名.empty();//队列不为空
以上为用法,头文件为#include<deque>
【电子学会六级·双端队列】

这道题是一个基本双端队列操作问题,只需跟着题目意思做就行了
#include<bits/stdc++.h>//万能头文件
using namespace std;
int main()
{
int n;//代表测试数据的组数
int type,c,x,n1;
cin>>n;
deque<int> que;//创建双端队列
for(int i=1;i<=n;i++)
{
cin>>n1;//操作次数
for(int j=1;j<=n1;j++)
{
cin>>type;
if(type==1)//type=1,进队操作
{
cin>>x;
que.push_back(x);
}
else//type=2,出队操作
{
cin>>c;
if(!que.empty())//队列不为空的情况下
{
if(c==0)//c=0代表从队头出队
{
que.pop_front();
}
else//c=1代表从队尾出队
{
que.pop_back();
}
}
}
}
if(!que.empty())//队列不为空的情况下
{
while(!que.empty())
{
cout<<que.front()<<" ";//从对头出队
que.pop_front();//删除此项
}
}
else//队列为空
{
cout<<"NULL";
}
cout<<endl;
}
return 0;
}怎么样,你写对了吗?
那么,来一道题练练手吧:

二叉堆(优先队列)是什么
二叉堆分为两个类型:
- 大顶堆:
最大堆的任何一个父节点的值,都大于或等于它左、右孩子节点的值 - 小顶堆
最大堆的任何一个父节点的值,都小于或等于它左、右孩子节点的值
二叉堆注意事项:
一.调整一个二叉堆,变化如下图:
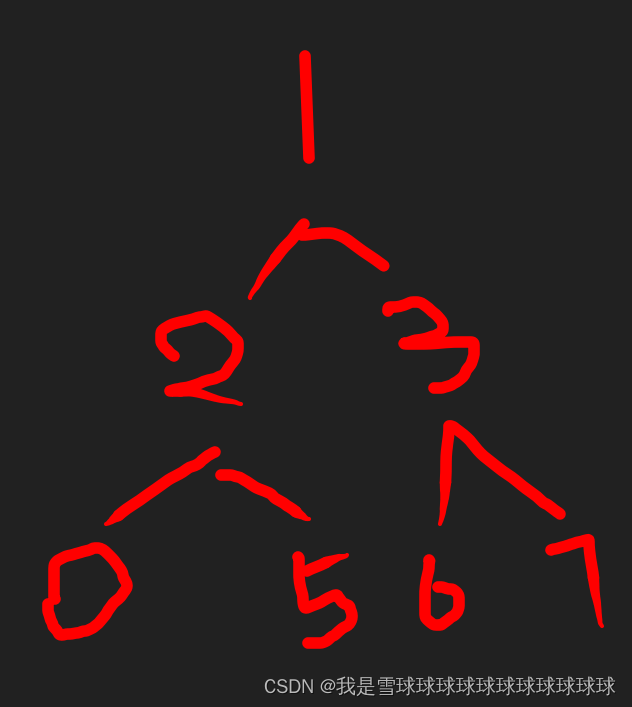
现在这个最小堆明显不符合要求,该怎么调整呢?
如下图:
1.不满足,“上浮”后:
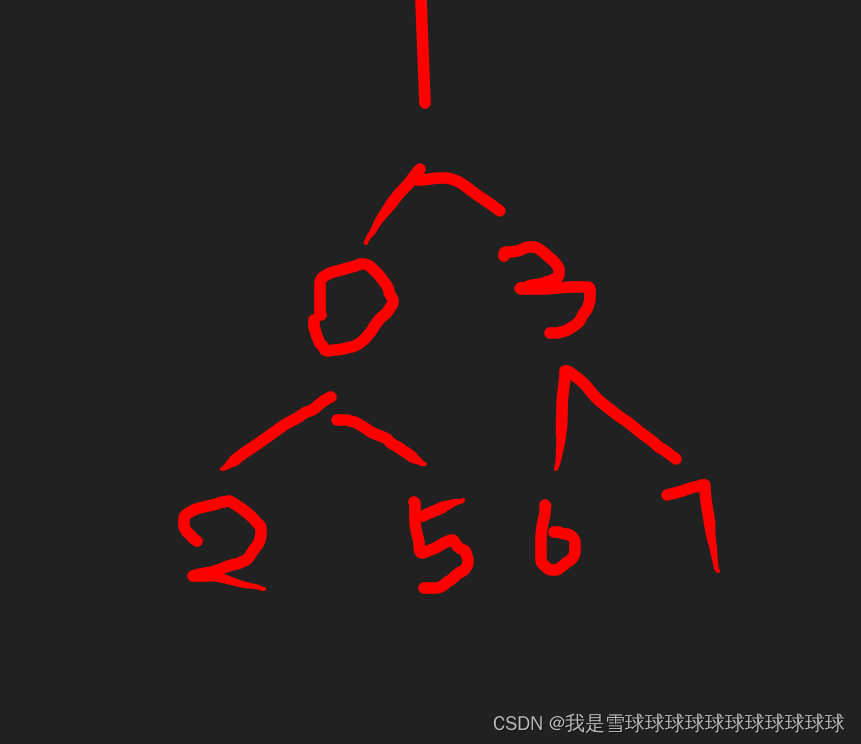
2.依然不满足,继续“上浮”
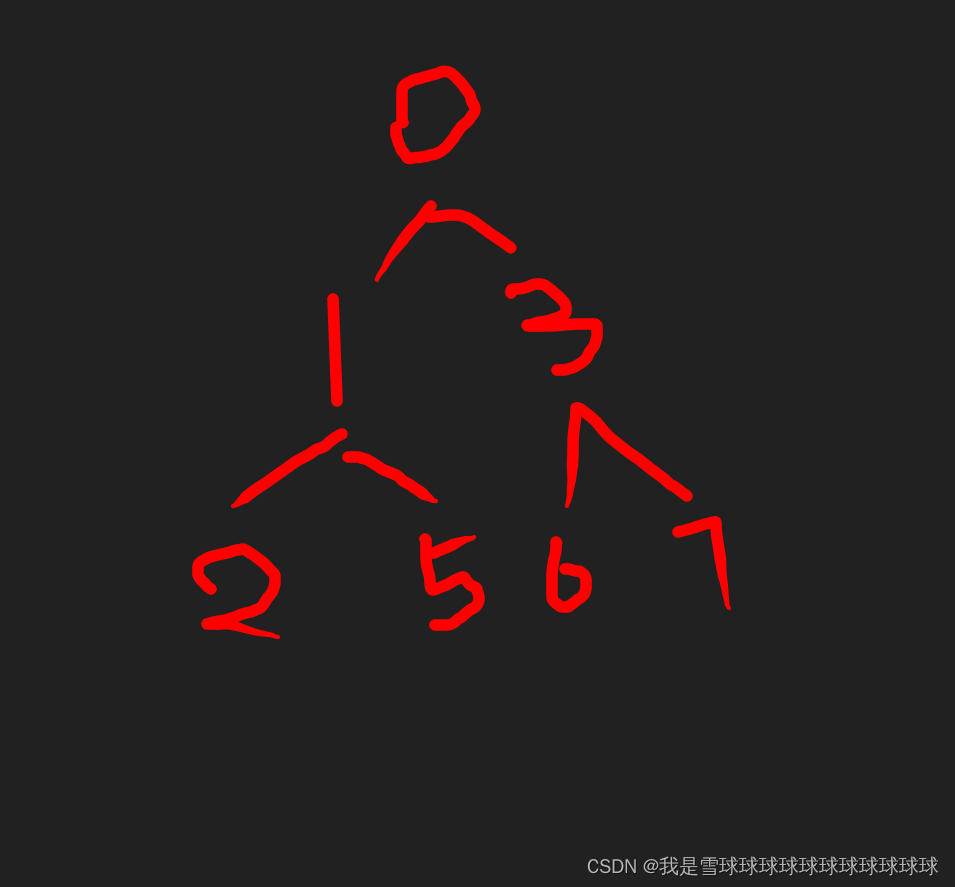
3.还是不满足,2的位置不对,与3调换位置
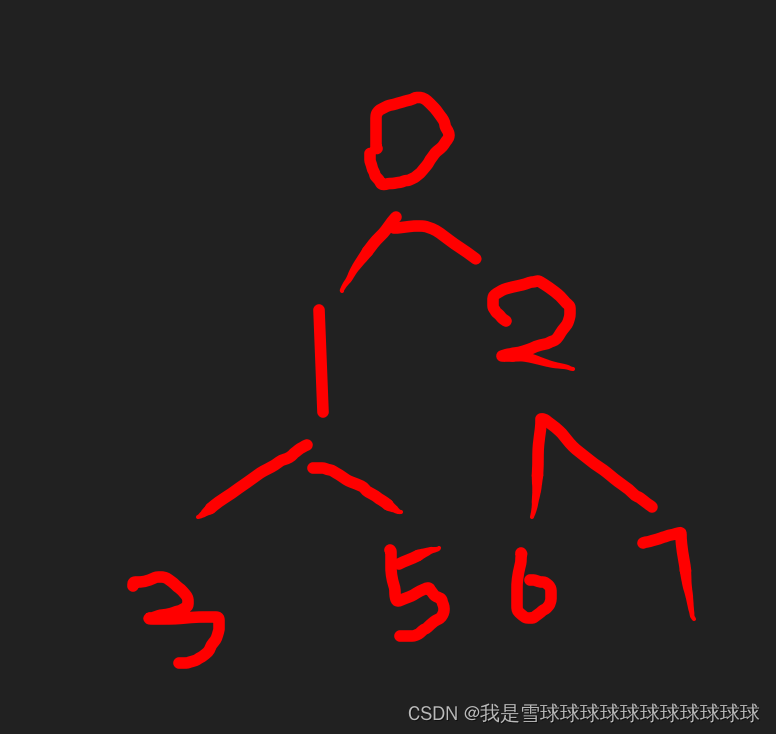
4.满足
二.
在二叉堆里我们要求:
最小的元素在顶端(最大的元素在顶端)
每个元素都比它的父节点小(大),或者和父节点相等。
三.
删除元素的过程类似添加元素,只不过添加元素是"向上冒",而删除元素是"向下沉":删除位置1的元素,把最后一个元素移到最前面,然后和它的两个子节点比较,如果两个子节点中较小的节点小于该节点,就将它们交换,直到两个子节点都比此顶点大。
计算两个子节点的位置的公式:左子节点:2K+1、右子节点:2K+2(注:这里针对的是根节点为零的情况,若根为1,则左右分别为2K与2K+1
四.
和添加元素完全一样的过程,只是要注意被修改的元素在二叉堆中的位置
二叉堆如何使用
priority_queue<int,vector<int>,less<int> > heap;//大顶堆
priority_queue<int,vector<int>,greater<int> > heap;//小顶堆
堆名.push(x);//将x加入到堆中
堆名.pop();//删除堆顶
堆堆.top();//查看堆顶
堆名.size();//查看堆中元素个数
堆名.empty();//堆是否为空注意!这里需要用到vector!
明白了原理,让我们来做题吧
[NOIP2004 提高组] 合并果子

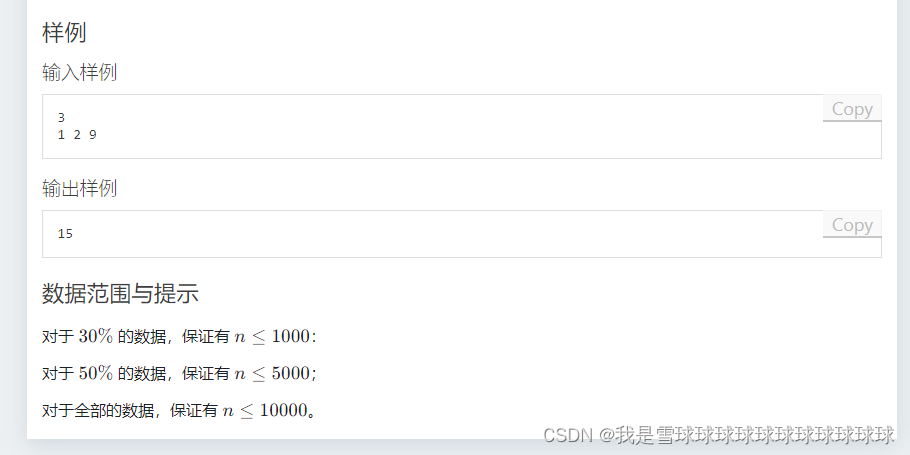 这道题明显是最小堆,代码来咯:
这道题明显是最小堆,代码来咯:
#include<bits/stdc++.h>
using namespace std;
int main()
{
priority_queue<int,vector<int>,greater<int>> heap;//创建一个小顶堆
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
int x;
cin>>x;
heap.push(x);//将x加入到堆中
}
int res=0;
while(heap.size()!=1)
{
int x=heap.top();
heap.pop();
int y=heap.top();
heap.pop();
res+=x+y;
heap.push(x+y);
}
cout<<res;
return 0;
}
小复习
图(关系结构)
由点和边构成的集合
- 无向图
- 有向图
带权图
度
出度:从一个点出去的边的数量
入度:进入一个点的边的数量
连通图
概念:一个图中所有点之间至少存在一条路径(路径:一个点有一条路到达另一个点)的图
无向图:连通图
有向图
弱连通图:将此图转换为无向图后,是连通状态,即为若连通
强连通图:有向图中任意一点都存在一条到达其余所有点的路径
完全图
一张图中,任意两点之间均有着一条直接连接的边
树
概念:只有n-1(n为点的数量)条边的连通图
点和点之间的关系
- 父子
- 兄弟
- 祖孙
度:一个点的子节点数量
节点类型
- 根结点
- 分支节点
- 叶子节点
完全二叉树
概念:按照每一层节点依次填充的顺序的二叉树,是完全二叉树
特性:
- n层的二叉树,最多共有** 2n−12n−1个节点**
- 二叉树第n层,最多有个2n−12n−1节点