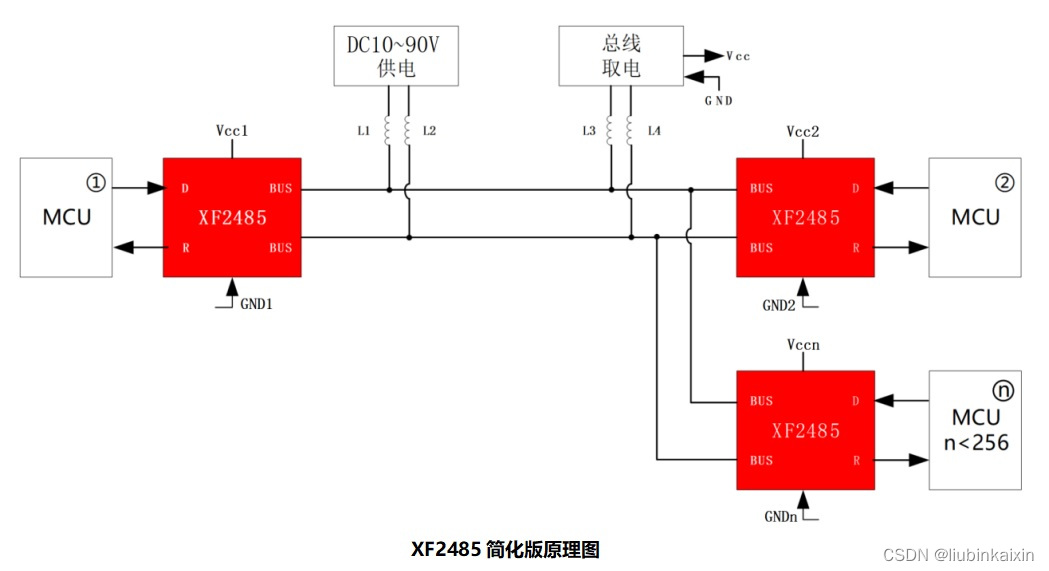
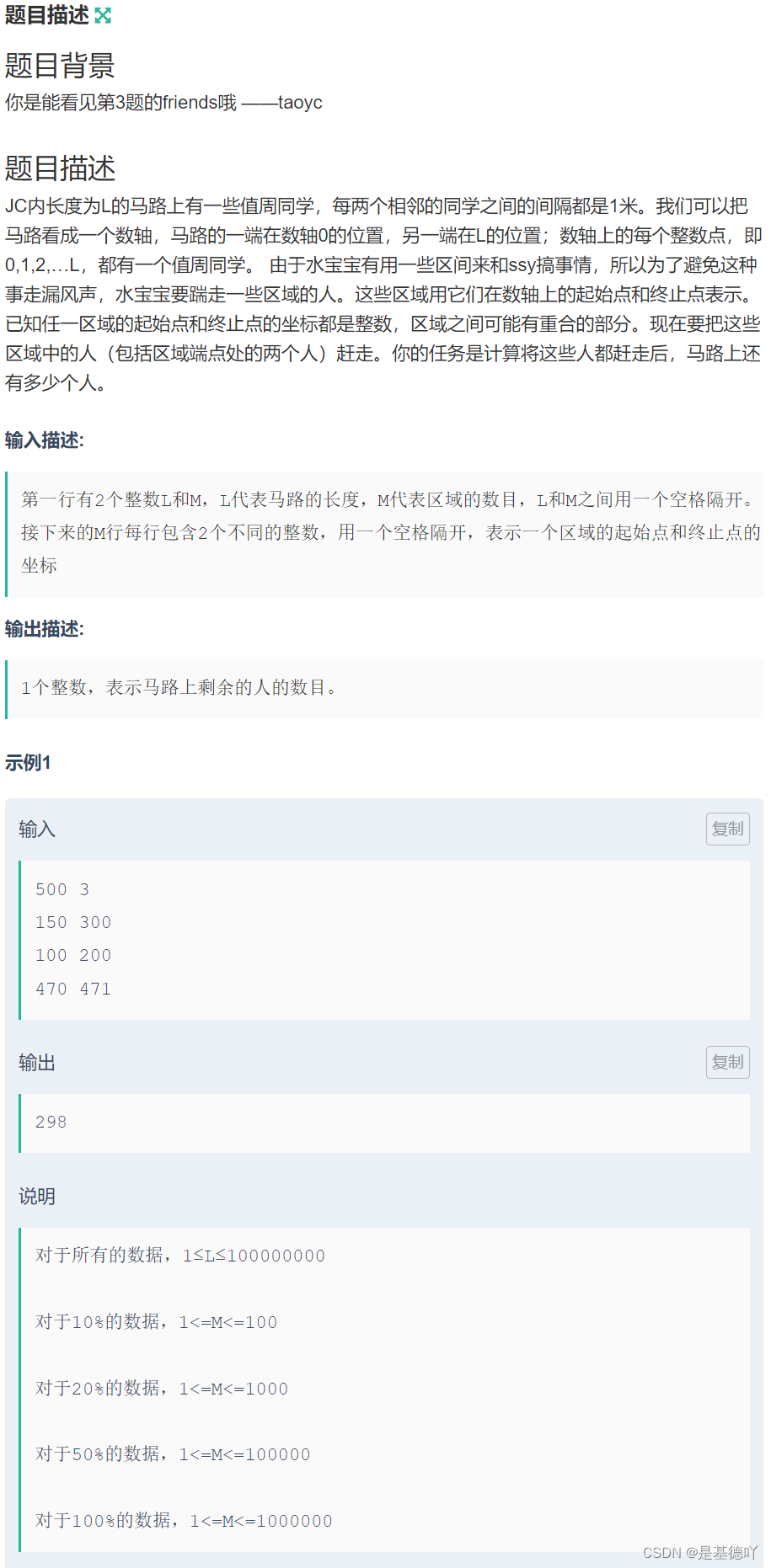
1.预配置
Local_rank:当前机子上的第几块GPU。这里设置为-1,后续多线程自动分配显卡。
Cuda_visible_devices:指定分配资源到几块显卡上,这里‘0,1,2,3’就是这四张gpu的id。
os.environ['LOCAL_RANK'] = '-1'
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'2.初始化
其实是一个多线程的过程,开3张GPU就是开了三个进程,每一个进程各自独立。
这块代码就是一个线程:
1-2行:自动获得当前线程gpu的id,并配置到cuda中。
3-4行:初始化分布式训练,nccl是后端通信方式。
因为是单机,init_process_group()中其他不需要了,写多了容易端口冲突报错。
5: 获得当前线程的gpu的id。
6: 不同进程之间的同步,同步后运行后面的程序。
gpu = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(gpu)
dist_backend = 'nccl'
torch.distributed.init_process_group(backend=dist_backend)
device_id = torch.distributed.get_rank()
torch.distributed.barrier()3.模型分配
三个线程每一个线程都有一个模型,将模型分配到当前线程的gpu_id。
broadcast_buffers=False:这里设置缓冲区不同步,
因为在后面每一个epoch结束后用了torch.distributed.barrier()来同步各个进程。
find_unused_parameters=True:减少无用梯度计算。
model = model.to(device_id)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device_id], broadcast_buffers=False, find_unused_parameters=True)4.数据分配
1.创建数据samper
num_replicas=num_tasks:共有三张GPU,三个进程三份副本。
rank=device_id:当前分配的gpu_id。
2.创建dataloader
pin_memory=True:数据转移到GPU中速度就会快一些,吃显存。
num_workers=[3]:加速数据装载,吃内存。
num_tasks = torch.distributed.get_world_size()
sampler = torch.utils.data.DistributedSampler(dataset, num_replicas=num_tasks, rank=device_id, shuffle=shuffle)
loader = DataLoader(
dataset,
batch_size=bs,
num_workers=[4],
pin_memory=True,
sampler=sampler,
shuffle=shuffle,
collate_fn=[None],
drop_last=drop_last,
) 5.训练
每训练完一轮迭代同步一下。
for e in epochs:
....
torch.distributed.barrier()最后,在terminal运行。nproc_per_node=4就是有四张gpu。
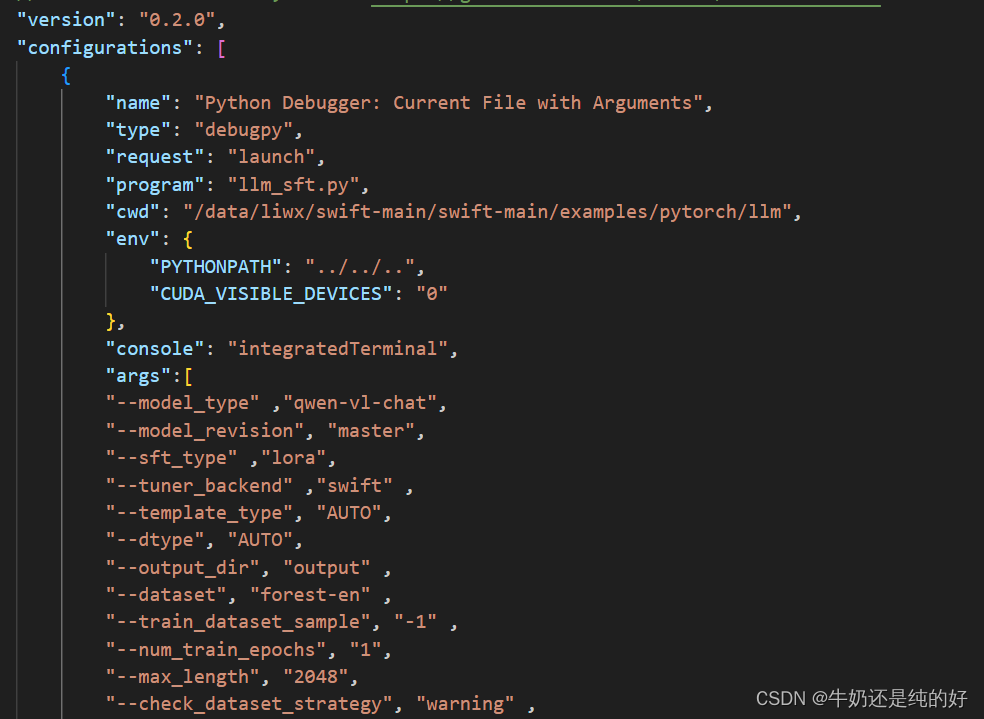
python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py6.debug的vscode下的launch.json内容
比如我的训练指令为:
python -m torch.distributed.launch --nproc_per_node=3 --use_env dark.py --sim --experiment dark_img注:其中训练用3张GPU, dark.py 是运行程序,而--sim 和--experiment dark_img是要传入的2个参数,下面的dark.py在darkening文件夹下,darkening文件夹是.vscode的统计文件夹,则完整launch.json内容如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python 调试程序: debug",
"type": "python",
"request": "launch",
"program": "/opt/conda/lib/python3.8/site-packages/torch/distributed/launch.py",
"args": [
"--nproc_per_node=3",
"--use_env",
"${workspaceFolder}/darkening/dark.py",
"--sim",
"--experiment", "dark_img"
],
"console": "integratedTerminal",
"justMyCode": true,
"cwd": "${workspaceFolder}",
}参考: