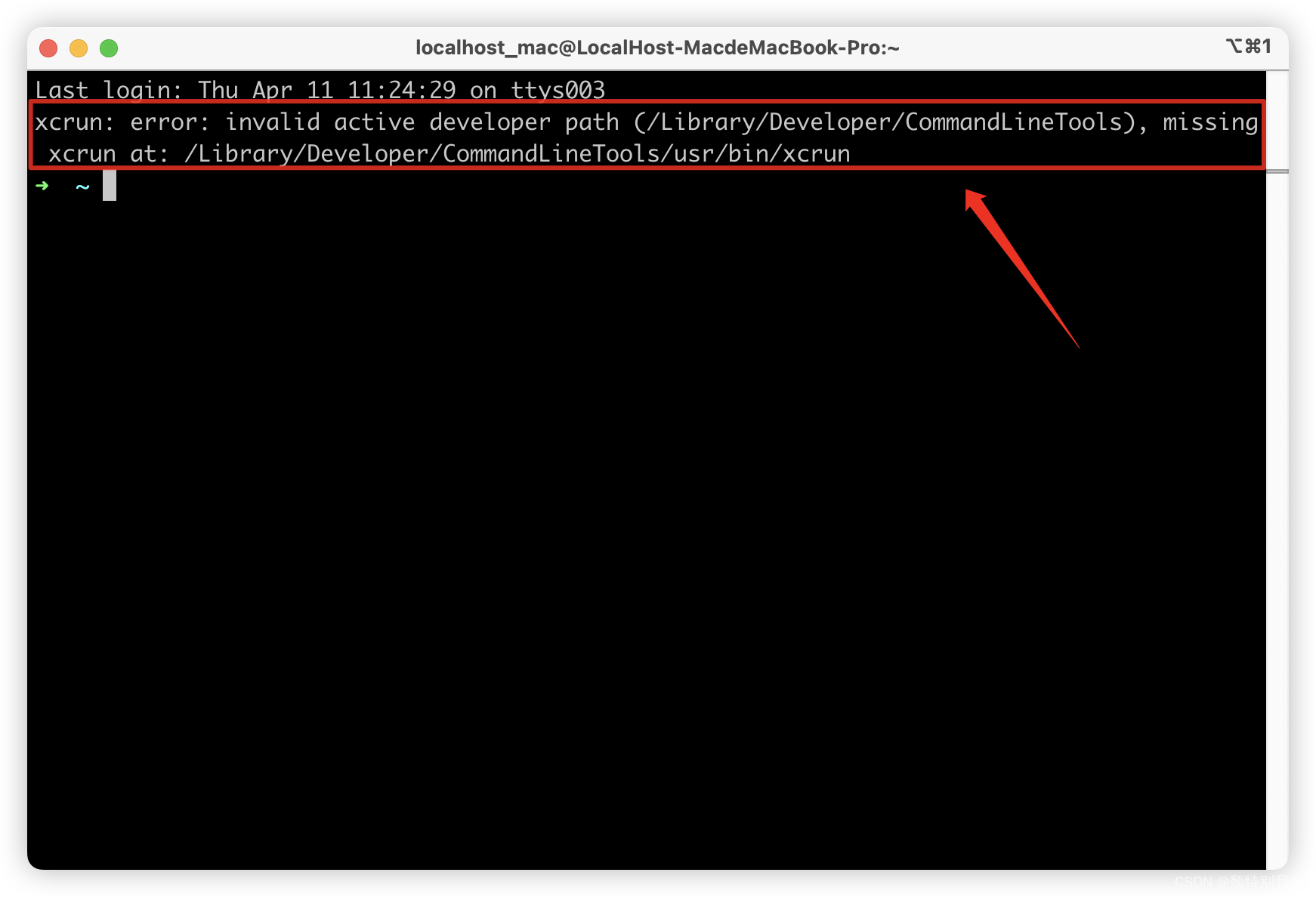
模型论文:https://arxiv.org/pdf/2309.07597
模型数据:https://data.baai.ac.cn/details/BAAI-MTP
训练数据
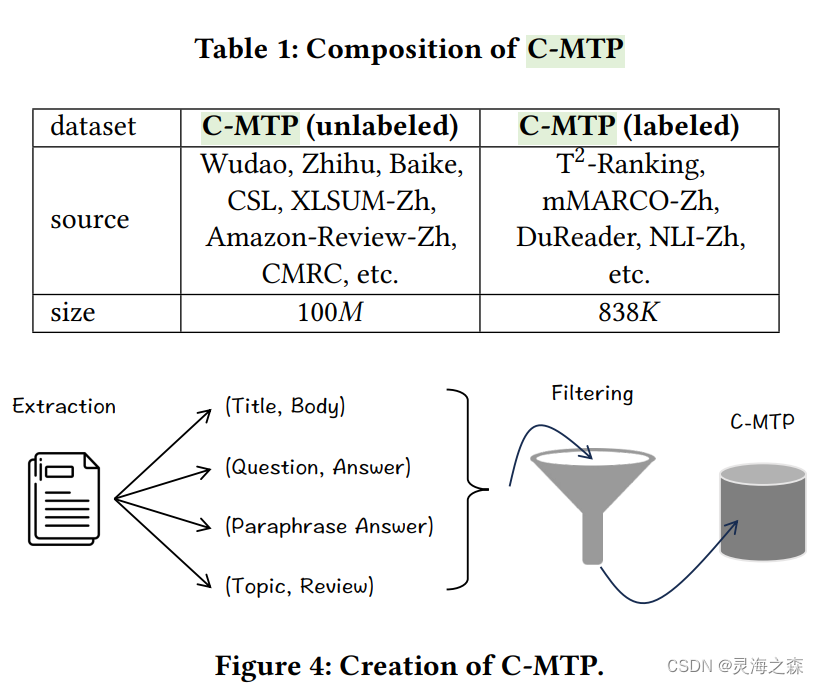
由无标签数据和有标签数据组成。
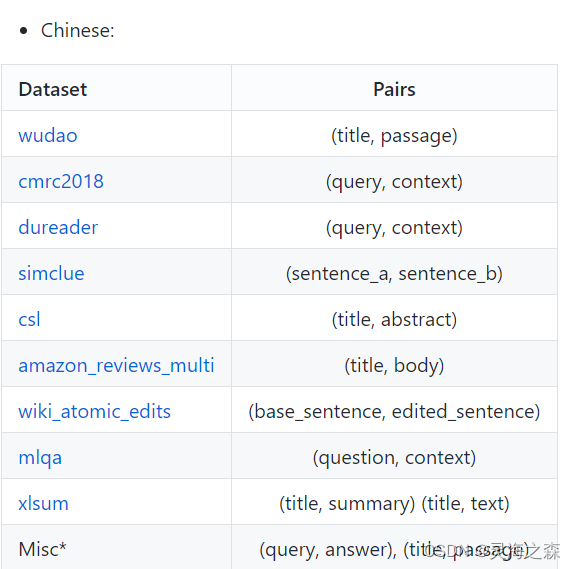
无标签数据使用了悟道等数据集,有标签数据使用了dureader等数据集。
都是文本对,对于无标签数据还使用Text2Vec-Chinese过滤掉得分低于0.43的pair。
有标签数据直接来自于下游任务的标注数据集,包括DuReader、mMARCO、NLI-Zh等,涵盖retrieval、ranking、similarity comparison等任务。

模型训练
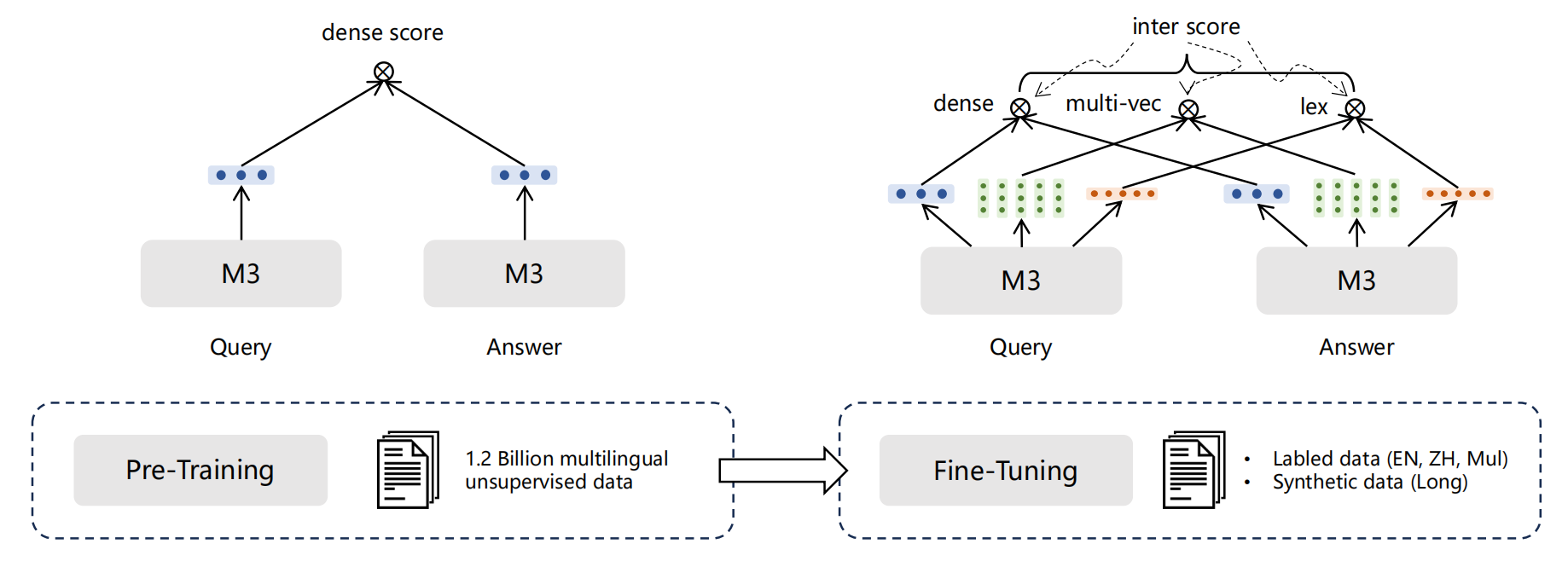
 BGE是一个类BERT的模型。
BGE是一个类BERT的模型。
是一个三阶段的训练过程。
1.Pre-Training
使用纯文本的悟道语料,不是文本对。目的是得到更强大的表征能力。做法是采用RetroMAE的训练策略:先对text X进行随机Mask,然后进行encoding,再额外训练一个light-weight decoder(如单层transformer)进行重构。通过这一过程,强迫encoder学习到良好的embedding。作者认为,解码器结构简单,只有单层transformer,而且输入句子的掩码率很高,会使得解码变得具有挑战性,可以迫使生成高质量的句子嵌入,以便可以以良好的保真度恢复原始输入。
2.general-purpose fine-tuning
预训练模型通过对 C-MTP(无标签)进行对比学习进行微调,以区分配对文本与其负样本。
对比学习的一个关键因素是负样本。没有特意挖掘难负样本,而是纯粹依赖批内负样本,并借助大批次(高达 19,200)来提高嵌入的区分性。
3.Task-specific fine-tuning
BGE适合各种类型的任务,如检索、摘要等等。它们包含的任务类型各异,可能会相互影响。
为了将通用的也能在各类任务中有优异表现,采用了以下两个方法:
- 基于指令的微调: 输入数据会被区分,以帮助模型适应不同任务。对于每个文本对 (p,
q),会在查询侧附加一个特定任务的指令。指令是一个言语提示,明确了任务的性质,例如“为这个句子生成表示以用于检索相关文章:”。 - 负样本更新:除了批内负样本,每个文本对 (p, q) 还会挖掘一个难负样本 q’。难负样本从任务的原始语料库中挖掘,遵循了ANN
风格的采样策略。难负样本通常与目标文本相似,但并不匹配,从而增加了模型的训练难度,提升了模型的区分能力。
自定义微调
官方提供了挖掘难负样本的脚本,是从query召回的top2-100中随机抽取,正样本是top1。
构造好数据集后,就可以继续做特定任务上的微调了。
https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
也可以使用llama_index微调,可以参考我的http://t.csdnimg.cn/EYs91
微调在 Embeding 模型和 Reranker 模型上使用同类型的数据集,并将语义相关性任务视为二分类任务。使用二分类交叉熵损失(BCE)来训练模型,使其能够在语义相关性任务中区分正负样本。
参考:
1.https://zhuanlan.zhihu.com/p/690856333
2.https://zhuanlan.zhihu.com/p/669596130
3.https://zhuanlan.zhihu.com/p/670277586
4.https://zhuanlan.zhihu.com/p/578747792