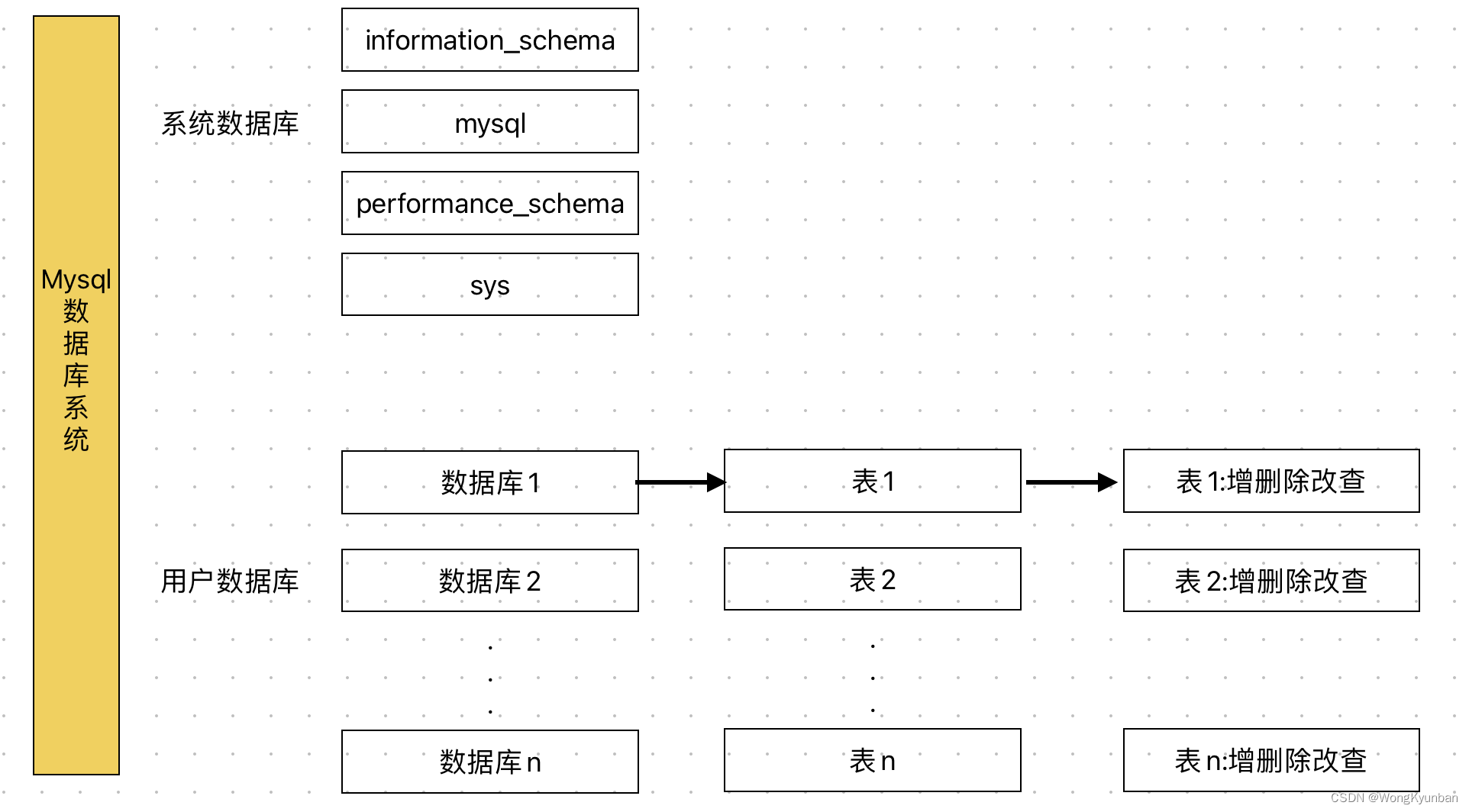
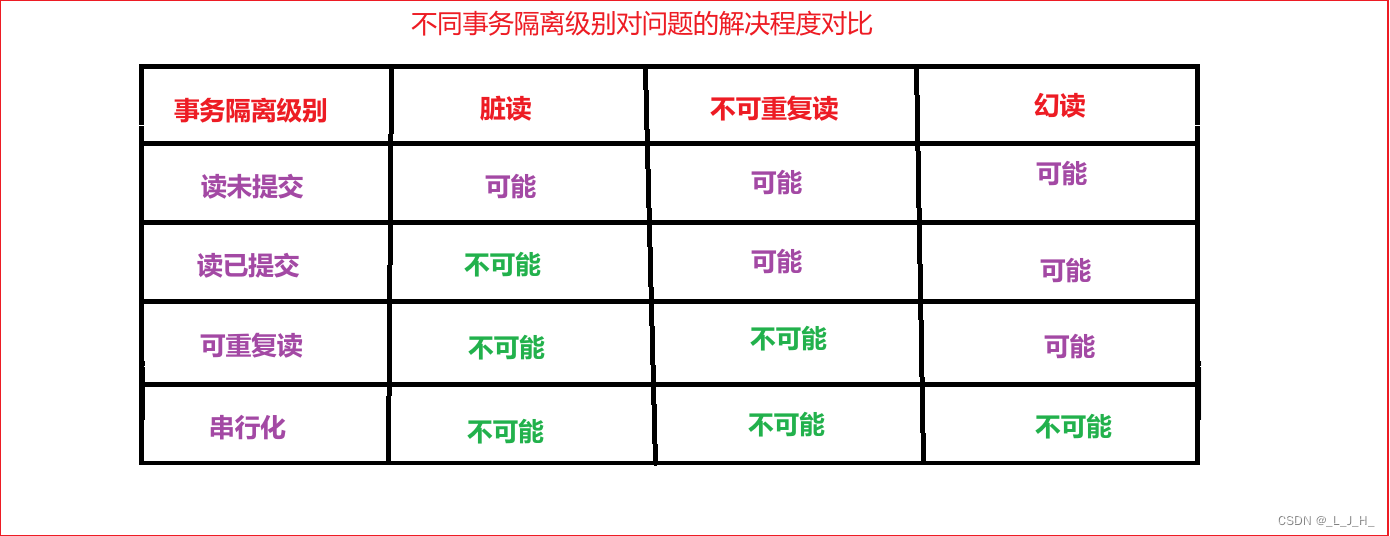
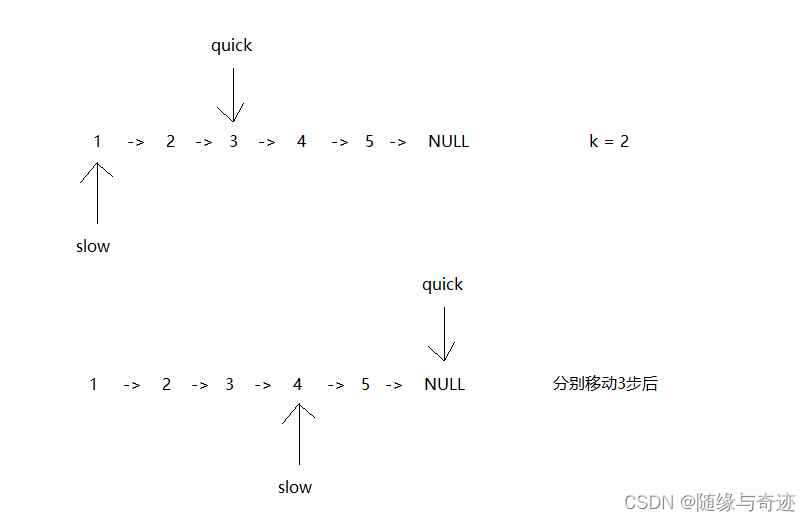
文章目录
参考:
200+ 特征提取匹配方案
深度学习论文:Local Feature Matching Using Deep Learning: A Survey
论文信息
- 论文题目:Local Feature Matching Using Deep Learning: A Survey
- 论文地址:https://arxiv.org/pdf/2401.17592
- 发表期刊:Information Fusion 2024
- 开源代码:https://github.com/vignywang/Awesome-Local-Feature-Matching
论文概述
- 论文评价
- 可创新点
论文翻译
1.摘要
局部特征匹配在计算机视觉领域有着广泛的应用,包括图像检索、3D重建和物体识别等领域。然而,由于视点和光照变化等因素,在提高匹配的准确性和鲁棒性方面仍然存在挑战。近年来,深度学习模型的引入引发了对局部特征匹配技术的广泛探索。这一努力的目标是提供一个全面的局部特征匹配方法概述。这些方法根据检测器的存在分为两个关键部分。基于检测器的类别包括检测-然后描述、联合检测和描述、描述-然后检测以及基于图的技术。相比之下,无检测器类别包括基于CNN的,基于变压器的和基于CNN的方法。我们的研究超越了方法学分析,纳入了对流行数据集和指标的评估,以促进对最先进技术的定量比较。本文还探讨了局部特征匹配在运动结构、遥感图像配准和医学图像配准等领域的实际应用,强调了局部特征匹配在各个领域的通用性和重要性。最后,我们努力概述当前在该领域面临的挑战,并提出未来的研究方向,从而为参与局部特征匹配及其相互关联领域的研究人员提供参考。本调查中全面的研究列表可在https://github.com/vignywang/Awesome-Local-Feature-Matching上获得。
2.引言
在图像处理领域,低局部特征匹配任务的核心目标是在不同图像之间建立精确的特征对应关系。这包含了各种类型的图像特征,如关键点、特征区域、直线和曲线等。建立不同图像中相似特征之间的对应关系是许多计算机视觉任务的基础,包括图像融合[1,2,3,4,5],视觉定位[6,7,8,9],运动结构(SfM)[10,11,12,13],同时定位和映射(SLAM)[14,15,16],光流估计[17,18,19],图像检索[20,21,22]等。
由于尺度变换、视点多样性、光照变化、模式递归和纹理变化等影响,在不同图像中对相同物理空间的描述可能会表现出实质性的差异。例如,图1提供了用于局部图像匹配任务的几种流行深度学习模型的性能的视觉表示。然而,保证在不同图像之间建立精确的对应关系需要克服由上述因素产生的多种困惑和挑战。因此,对局部特征匹配的准确性和可靠性的追求仍然是一个充满复杂性的艰巨问题。
在传统的图像匹配管道中,该过程可以分解为四个基本步骤:特征检测、特征描述、特征匹配和几何变换估计。在深度学习出现之前[23,24,25],许多著名的算法都是专门针对该管道中的一个或几个阶段进行定制的。各种技术致力于特征检测的过程[26,27,28,29],而其他技术则致力于局部执行特征描述的任务[30,31,32]。此外,已经设计了某些算法来同时满足特征检测和描述[33,34,35,36,37,38]。出于特征匹配的目的,传统的方法通常依赖于最小化或最大化特定的既定指标,如平方差或相关性的总和。在几何变换估计阶段,算法通常基于类似RANSAC[39]的技术来估计潜在的极缘几何或同形异构词。传统的手工方法和以学习为中心的方法都是基于梯度和灰度序列等低级图像特征构建的。尽管理论上对某些形式的转换具有弹性,但这些技术本质上受到研究人员对其任务施加的固有先验知识的限制。
近年来,在解决与局部特征匹配相关的挑战方面取得了实质性进展[40,41,42],特别是那些由尺度变化、观点转变和其他形式的多样性所带来的挑战。基于检测器的方法依赖于稀疏分布的关键点的检测和描述,以建立图像之间的匹配。这些方法的有效性很大程度上取决于关键点检测器和特征描述符的性能,因为它们在过程中起着重要的作用。相比之下,无检测器方法通过利用图像中普遍存在的丰富上下文信息,避免了单独的关键点检测和特征描述阶段的必要性。这些方法支持端到端图像匹配,从而提供了一种独特的机制来处理任务。
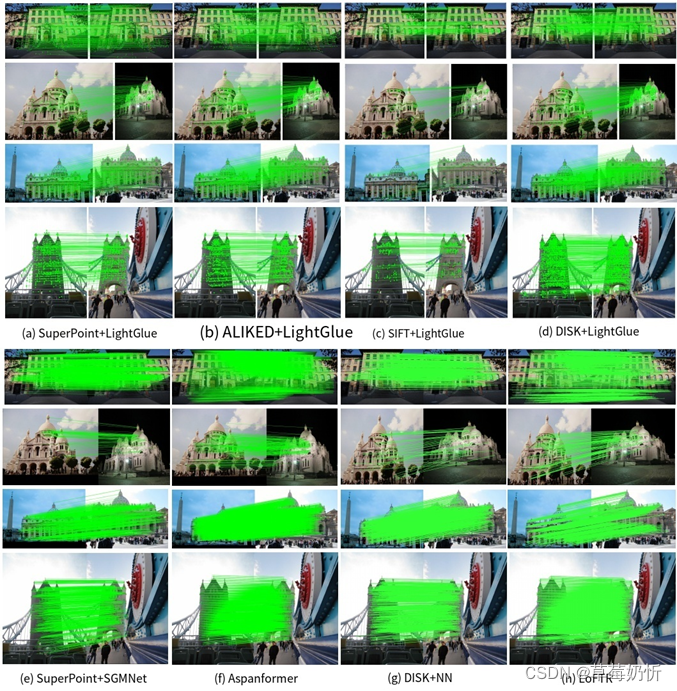
图1:户外图像的匹配结果。可以观察到,对于视点和光照条件变化明显的图像,匹配任务遇到了相当大的挑战。
图像匹配在图像配准领域中起着关键作用,它通过一组可靠的特征匹配来实现变换函数的精确拟合。这一功能将图像匹配定位为图像融合更广泛背景下的一个关键研究领域[43]。为了连贯地概括局部特征匹配领域的发展并激发创新的研究途径,本文对局部特征匹配的最新进展进行了详尽的回顾和彻底的分析,特别强调了深度学习算法的使用。此外,我们重新审视了相关的数据集和评估标准,并对关键方法进行了详细的比较分析。我们的研究解决了传统手工方法和现代深度学习技术之间的差距和潜在的桥梁。我们通过分析传统手工方法和深度学习技术的最新发展,强调这两种方法之间的持续相关性和协作性。此外,我们解决了对多模态图像的新兴关注。这包括专门为多模态图像分析量身定制的方法的详细概述。我们的调查还确定并讨论了现有数据集在评估局部特征匹配方法方面的差距和未来需求,强调了适应多样化和动态场景的重要性。为了与当前趋势保持一致,我们研究了大型基础模型在特征匹配中的作用。这些模型代表了传统语义分割模型的重大转变[44,45,46,47,48],为广泛的场景和对象提供了卓越的泛化能力。
综上所述,本调查的一些关键贡献可以总结如下:
- 本调查广泛涵盖了当代局部特征匹配问题的文献,并对2018年以来提出的各种局部特征匹配算法进行了详细概述。根据流行的图像匹配管道,我们主要将这些方法分为两大类:基于检测器的和无检测器,并对采用深度学习的匹配算法进行了全面的回顾。
- 我们仔细研究了这些方法在无数现实世界场景中的部署,包括SfM、遥感图像配准和医学图像配准。本研究突出了局部特征匹配技术固有的多功能性和广泛适用性。
- 我们从相关的计算机视觉任务开始,回顾局部特征匹配中涉及的主要数据集,并根据不同的任务对其进行分类,以深入研究每个领域内的具体研究需求。
- 我们分析了用于性能评估的各种指标,并对关键的局部特征匹配方法进行了定量比较。
- 我们提出了一系列挑战和未来的研究方向,为该领域的进一步发展提供了有价值的指导。
值得注意的是,最初的调查[49,50,51]主要集中在手工方法上,因此它们没有为围绕深度学习的研究提供足够
的参考点。尽管最近的调查[52,53,54]纳入了可训练的方法,但它们未能及时总结过去五年中出现的大量文献。此外,许多研究都局限于该领域内图像匹配的特定方面,例如一些文章只介绍了局部特征的特征检测和描述方法,而不包括匹配[52],一些文章特别关注文化遗产图像的匹配[55],还有一些只专注于医学图像配准[56,57,58]、遥感图像配准[59,60]等。在本调查中,我们的目标是通过评估现有的图像匹配方法,特别是最先进的基于学习的方法,提供最新和全面的概述。重要的是,我们不仅讨论了服务于自然图像应用的现有方法,而且还讨论了特征匹配在SfM、遥感图像和医学图像中的广泛应用。我们通过对多模态图像匹配的详细讨论,说明了本研究与信息融合领域的密切联系。此外,我们对最近的主流方法进行了彻底的检查和分析,这些讨论在现有文献中显然是缺失的。图2展示了局部特征匹配方法的代表性时间表,它提供了对这些方法的演变及其对该领域前沿进展的关键贡献的见解。
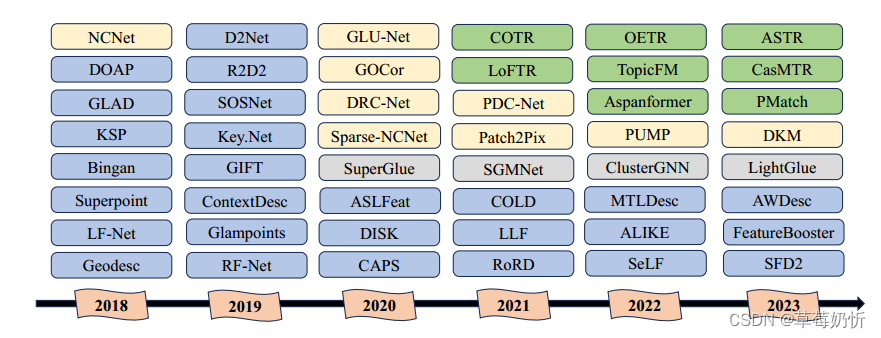
图2:具有代表性的局部特征匹配方法。蓝色和灰色表示基于检测器的模型,其中灰色表示基于图的方法。黄色和绿色块分别表示无检测器模型中的CNN基于和Transformer基于方法。2018年,Superpoint[61]率先在单个网络内计算关键点和描述符。随后,许多作品如D2Net[62]、R2D2[63]等都试图将关键点检测和描述结合起来进行匹配。同时,NCNet[64]方法将四维代价体积引入局部特征匹配,开创了利用基于关联或基于代价体积的卷积神经网络进行无检测器匹配研究的趋势。在这一趋势的基础上,出现了诸如Sparse-NCNet[65]、DRC-Net[66]、GLU-Net[67]和PDC-Net[68]等方法。2020年,SuperGlue[69]将该任务框定为涉及两组特征的图匹配问题。在此之后,SGMNet[70]和ClusterGNN[71]专注于通过解决匹配的复杂性来改进图匹配过程。2021年,LoFTR[72]和Aspanformer[73]等方法成功地将Transformer或Attention机制纳入了无检测器匹配过程。他们通过采用交错的自我和交叉注意模块实现了这一目标,显著扩展了接受野,并进一步推进了基于深度学习的匹配技术。
3.基于检测器的模型
在相当长的一段时间里,基于检测器的方法一直是局部特征匹配的主流方法。许多成熟的手工作品,包括SIFT[33]和ORB[35],已被广泛采用于3D计算机视觉领域的各种任务[74,75]。这些传统的基于检测器的方法通常包括三个主要阶段:特征检测、特征描述和特征匹配。首先,从图像中提取一组稀疏的关键点。随后,在特征描述阶段,使用高维向量对这些关键点进行表征,通常设计为封装这些点周围区域的特定结构和信息。最后,在特征匹配阶段,通过最近邻搜索或更复杂的匹配算法等机制建立像素级的对应关系。其中值得注意的是Bian等人的GMS(基于网格的运动统计)[76]和Zhang等人的OANET(顺序感知网络)[77]。GMS使用基于网格的运动统计来提高特征对应质量,简化和加速匹配,而OANET通过集成空间上下文来优化双视图匹配,以实现精确的对应和几何估计。这通常是通过比较不同图像之间关键点的高维向量和基于相似性水平识别匹配来完成的-通常由向量空间中的距离函数定义。
然而,在深度学习时代,数据驱动方法的兴起使得LIFT[78]等方法变得流行起来。这些 方法利用cnn提取更鲁棒和判别性更强的本地关键点描述符,在处理大视点变化和局部特征光照变化方面取得了重大进展。目前,基于检测器的方法可以分为四大类:1.基于检测器的方法;检测-然后描述法;2. 联合检测与描述方法;3. 描述-然后检测方法;4. 基于图的方法。此外,我们进一步将基于监督学习类型的检测-然后描述方法细分为完全监督方法、弱监督方法和其他形式的监督方法。这种分类在图3中有直观的描述。
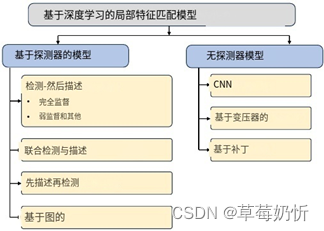
图3:局部特征匹配模型概述和最相关方法的分类。
2.1. Detect-then-Describe
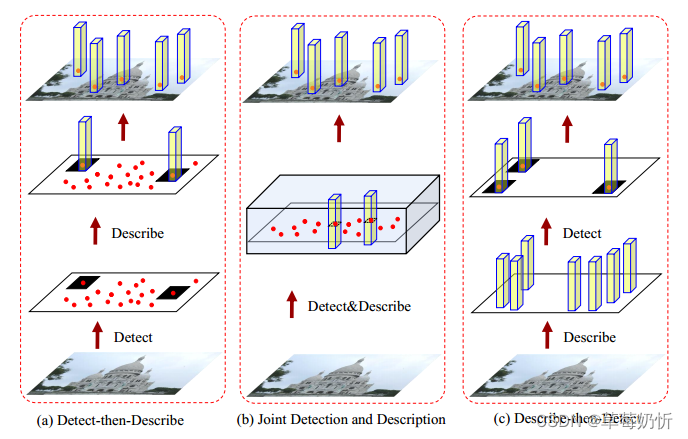
在特征匹配方法中,采用稀疏到稀疏的特征匹配是相当普遍的。这些方法遵循“检测-然后描述”的范式,其中第一步涉及关键点位置的检测。检测器随后从以每个检测到的关键点为中心的补丁中提取特征描述符。然后将这些描述符转发到特征描述阶段。这个过程通常使用度量学习方法进行训练,其目的是学习一个距离函数,其中相似点在特征空间中很近,不相似点在特征空间中很远。为了提高效率,特征检测器通常关注小图像区域[78],通常强调低层次结构,如角[26]或blobs[33]。另一方面,描述符的目标是在包含关键点的更大的补丁中捕获更细微、更高层次的信息。这些描述符提供了冗长和独特的细节,作为匹配目的的定义特征。图4(a)说明了检测-然后描述管道的通用结构。
2.1.1. Fully-Supervised
局部特征匹配领域已经发生了显著的转变,这主要是由带注释的补丁数据集[79]的出现和深度学习技术的集成所驱动的。这一转变标志着从传统的手工制作方法转向更多的数据驱动方法,重塑了特征匹配的格局。本节旨在追溯这些变化的历史发展,强调各种全监督方法的顺序推进和相互关联的本质。CNNs 站在了这场进化的最前沿,它在互联网革命中发挥了关键作用局部特征匹配领域已经发生了显著的转变,这主要是由带注释的补丁数据集[79]的出现和深度学习技术的集成所驱动的。这一转变标志着从传统的手工制作方法转向更多的数据驱动方法,重塑了特征匹配的格局。本节旨在追溯这些变化的历史发展,强调各种全监督方法的顺序推进和相互关联的本质。cnn站在了这场进化的最前沿,它在互联网革命中发挥了关键作用。
在cnn的支持下,向这些数据驱动方法的转变,不仅提高了局部特征匹配的准确性和效率,而且为这一领域的研究和创新开辟了新的途径。当我们探索这一领域的时间顺序进展时,我们观察到一个清晰的增长和改进轨迹,从传统到现代,每种方法都建立在其前辈的成功基础上,同时引入新的概念和技术。OriNet[81]提出了一种使用cnn对图像中特征点的规范方向进行签名的方法,增强了特征点的匹配。他们引入了一种Siamese网络[82]训练方法,该方法消除了对预定义方向的需求,并提出了一种新的GHH激活函数,在多个数据集的特征描述符中显示出显著的性能改进。基于L2Net的架构原则,HardNet[83]通过关注度量学习和消除对辅助损失项的需求,简化了学习过程,为后续模型简化学习目标树立了先例。DOAP[84]将重点转移到学习到排名的公式上,为最近邻匹配优化了局部特征描述符,这种方法在特定的匹配场景中取得了成功,并影响了后来的模型考虑基于排名的方法。KSP[85]方法以其引入子空间池化方法而闻名,该方法利用cnn来学习不变和判别描述符。DeepBit[86]提供了一个无监督的深度学习框架来学习紧凑的二元描述符。它将局部描述符的旋转、平移和尺度不变性等关键属性编码为二进制表示。Bingan[87]提出了一种使用正则化生成对抗网络(GANs)学习紧凑二值图像描述符的方法。GLAD[88]通过考虑来自人体的局部和全局线索来解决个人再识别任务。实现了一个四流CNN框架来生成判别和鲁棒描述符。Geodesc[89]通过整合SfM算法中的几何约束,推进了描述子计算。该方法强调两个方面:首先,使用几何信息构建训练数据来测量样本硬度,其中硬度由相同3D点的像素块之间的可变性和不同点的均匀性来定义。其次,设计几何相似度损失函数,促进相同3D点对应的像素块之间的紧密度。这些创新使Geodesc能够显着提高描述符在3D重建任务中的有效性。对于GIFT[90]和COLD[91],前者强调了结合来自群体特征的潜在结构信息来构建有效描述符的重要性。通过使用群卷积,GIFT生成密集的描述子,这些描述子对变换群既具有独特性又具有不变性。相比之下,COLD通过多层次特征蒸馏网络架构引入了一种新的方法。该架构利用Ima-geNet预训练卷积神经网络的中间层来封装分层特征,最终提取高度紧凑和鲁棒的局部描述符。
推进叙述,我们的探索扩展到完全监督方法的最新进展,构成了值得注意的本地特征匹配能力的扩充。这些开创性的方法,建立在前面阐述的基本框架之上,协同提升和优化了支撑该领域的方法。延续增强描述符鲁棒性的趋势,sosnet[92]通过引入用于描述符学习的二阶相似正则化项扩展了HardNet。这种增强包括将二阶相似性约束集成到训练过程中,从而增强了学习鲁棒描述符的性能。术语“二阶相似性”表示评估训练批中描述符对之间相对距离一致性的度量。它不仅直接测量描述符对之间的相似性,而且还考虑它们与同一批内其他描述符对的相对距离。Ebel等人[93]提出了一种基于对数极坐标采样方案的局部特征描述符,以实现尺度不变性。这种独特的方法允许关键点在不同尺度上匹配,并且对遮挡和背景运动的敏感性较低。因此,它有效地利用了更大的图像区域来提高性能。为了设计一个更好的损失函数,HyNet[94]引入了一种混合相似度量,用于三重边缘损失,并实现了一个正则化项来约束描述符规范,从而建立了一个平衡而有效的学习框架。CNDesc[95]还研究了L2归一化,提出了一种创新的密集局部描述符学习方法。它使用一种特殊的交叉归一化技术代替L2归一化,引入了一种新的特征向量归一化方法。键。Net[96]提出了一个关键点检测器,它结合了手工制作和学习的CNN特征,并在网络中使用尺度空间表示来提取不同层次的关键点。为了解决关键点检测方法的不可微性问题,ALIKE[97]提供了基于分数图的可微关键点检测(DKD)模块。与依赖非最大抑制(NMS)的方法相反,DKD可以反向传播梯度并产生亚像素级的关键点。这使得关键点位置可以直接优化。S-TREK[98]引入了一种先进的局部特征提取器,它将平移和旋转等变关键点检测器与轻量级描述符提取器相结合。通过强化学习启发的框架来优化关键点的可重复性,S-TREK在多个基准测试中实现了卓越的可重复性和姿势恢复性能,特别是在平面内旋转的场景中表现出色。Zip-pyPoint[99]是基于KP2D[100]设计的,引入了一整套加速提取和匹配技术。该方法建议使用二进制描述符归一化层,从而能够生成唯一的、长度不变的二进制描述符。
从而建立了一个平衡而有效的学习框架。CNDesc[95]还研究了L2归一化,提出了一种创新的密集局部描述符学习方法。它使用一种特殊的交叉归一化技术代替L2归一化,引入了一种新的特征向量归一化方法。键。Net[96]提出了一个关键点检测器,它结合了手工制作和学习的CNN特征,并在网络中使用尺度空间表示来提取不同层次的关键点。为了解决关键点检测方法的不可微性问题,ALIKE[97]提供了基于分数图的可微关键点检测(DKD)模块。与依赖非最大抑制(NMS)的方法相反,DKD可以反向传播梯度并产生亚像素级的关键点。这使得关键点位置可以直接优化。S-TREK[98]引入了一种先进的局部特征提取器,它将平移和旋转等变关键点检测器与轻量级描述符提取器相结合。通过强化学习启发的框架来优化关键点的可重复性,S-TREK在多个基准测试中实现了卓越的可重复性和姿势恢复性能,特别是在平面内旋转的场景中表现出色。Zip-pyPoint[99]是基于KP2D[100]设计的,引入了一整套加速提取和匹配技术。该方法建议使用二进制描述符归一化层,从而能够生成唯一的、长度不变的二进制描述符。
从而建立了一个平衡而有效的学习框架。CNDesc[95]还研究了L2归一化,提出了一种创新的密集局部描述符学习方法。它使用一种特殊的交叉归一化技术代替L2归一化,引入了一种新的特征向量归一化方法。键。Net[96]提出了一个关键点检测器,它结合了手工制作和学习的CNN特征,并在网络中使用尺度空间表示来提取不同层次的关键点。为了解决关键点检测方法的不可微性问题,ALIKE[97]提供了基于分数图的可微关键点检测(DKD)模块。与依赖非最大抑制(NMS)的方法相反,DKD可以反向传播梯度并产生亚像素级的关键点。这使得关键点位置可以直接优化。S-TREK[98]引入了一种先进的局部特征提取器,它将平移和旋转等变关键点检测器与轻量级描述符提取器相结合。通过强化学习启发的框架来优化关键点的可重复性,S-TREK在多个基准测试中实现了卓越的可重复性和姿势恢复性能,特别是在平面内旋转的场景中表现出色。Zip-pyPoint[99]是基于KP2D[100]设计的,引入了一整套加速提取和匹配技术。该方法建议使用二进制描述符归一化层,从而能够生成唯一的、长度不变的二进制描述符。
2.1.2. 弱监督和其他
弱监督学习为模型提供了在不需要密集标注标签的情况下学习鲁棒特征的机会,为训练深度学习模型的最大挑战之一提供了解决方案。已经出现了几种弱监督的局部特征学习方法,利用从相机姿势中容易获得的几何信息。仿射网[109]代表了弱监督局部特征学习的关键进步,专注于局部特征仿射形状的学习。该方法挑战了传统对几何可重复性的强调,表明它不足以实现可靠的特征匹配,并强调了基于描述符的学习的重要性。仿射网引入了一个硬负常数损失函数来提高仿射区域的匹配性和几何精度。这已被证明在增强仿射协变检测器的性能方面是有效的,特别是在宽基线匹配和图像检索方面。该方法强调需要考虑描述符匹配能力和可重复性,以开发更有效的局部特征检测器。GLAMpoints[110]提出了一种半监督的关键点检测方法,创造性地从强化学习损失公式中汲取见解。在这里,奖励用于根据最终对齐的质量计算检测关键点的重要性。这种方法已经被注意到会显著影响最终图像的匹配和配准质量。CAPS[111]引入了一种弱监督学习框架,该框架利用图像对之间的相对相机姿势来学习特征描述符。通过采用极缘几何约束作为监督信号,他们设计了可微的匹配层和从粗到细的架构,从而生成了密集的描述符。DISK[112]最大限度地发挥了强化学习的潜力,利用策略梯度将弱监督学习集成到基于检测器的端到端管道中。这种弱监督与强化学习的集成方法可以提供更鲁棒的学习信号,并实现有效的优化。[113]提出了一种利用群等变cnn功能的群对齐方法。这些CNNs在提取判别旋转不变性局部描述符方面是有效的。作者使用自监督损失进行更好的方向估计和高效的局部描述子提取。使用相机姿态监督和其他技术的弱监督和半监督方法为解决训练鲁棒局部特征方法的挑战提供了有用的策略,并可能为该领域更有效和可扩展的学习方法铺平道路。
2.2. 联合检测与描述
在各种成像条件下,稀疏局部特征匹配确实是非常有效的。然而,在昼夜变化[114]、不同季节[115]或弱纹理场景[116]等极端变化下,这些特征的性能可能会显著恶化。这些限制可能源于关键点检测器和局部描述符的性质。关键点检测通常涉及关注图像的小区域,并且可能严重依赖于低级信息,例如像素强度。这一过程使得关键点检测器更容易受到低层图像统计数据变化的影响,而低层图像统计数据通常会受到光照、天气和其他环境因素变化的影响。此外,当尝试单独学习或训练关键点检测器或特征描述符时,即使在仔细优化了单个组件之后,将它们集成到特征匹配管道中仍然可能导致信息丢失或不一致。这是因为单个组件的优化可能没有充分考虑组件之间的依赖关系和信息共享。为了解决这些问题,提出了联合检测和描述的方法。在这种方法中,关键点检测和描述的任务被集成并在单个模型中同时学习。这可以使模型在优化过程中融合来自两个任务的信息,更好地适应特定的任务和数据,并允许通过cnn进行更深层次的特征映射。这种统一的方法可以让检测和描述过程受到更高层次信息的影响,比如图像的结构或形状相关特征,从而使任务受益。此外,密集描述符涉及更丰富的图像上下文,这通常会带来更好的性能。图4 (b)展示了联合检测和描述管道的常见结构。
基于图像的描述符方法,将整个图像作为输入,并利用全卷积神经网络[117]来生成密集的描述符,近年来取得了实质性的进展。这些方法通常将检测和描述的过程合并在一起,从而提高了这两个任务的性能。SuperPoint[61]采用自监督方法同时确定像素级的关键点位置及其描述符。最初,该模型通过应用随机同形异义词在合成形状和图像上进行训练。该方法的一个关键方面在于它对真实图像的自注释过程。这个过程包括调整同形异义词来增强模型与真实世界图像的相关性,并且使用MS-COCO数据集进行额外的训练。通过各种同形变换生成这些图像的Groundtruth关键点,并使用MagicPoint模型进行关键点提取。该策略涉及聚合多个关键点热图,确保了在真实图像上精确确定关键点位置。受Q-learning的启发,LF-Net[118]使用现有的SfM模型预测匹配图像对之间的几何关系,如相对深度和相机姿势。它采用不对称梯度反向传播来训练一个网络,用于检测图像对,而不需要手动注释。在LF-Net的基础上,RF-Net[119]引入了一个基于接受场的关键点检测器,并设计了一个通用的损失函数项,称为“邻居掩码”,这有助于patch选择的训练。强化SP[120]采用强化学习的原理来处理关键点选择和描述符匹配中的离散性。它将特征检测器集成到完整的视觉管道中,并以端到端方式训练可学习的pa参数。R2D2[63]使用密集版本的L2-Net架构将网格峰值检测与描述符的可靠性预测相结合,旨在产生稀疏、可重复和可靠的关键点。D2Net[62]采用联合检测-描述方法进行稀疏特征提取。与Superpoint不同的是,它共享检测和描述过程之间的所有参数,并使用同时优化两个任务的联合公式。他们方法中的关键点被定义为深度特征图通道内和跨通道的局部最大值。这些技术优雅地说明了在统一模型中检测和描述任务的集成如何在不同成像条件下为局部特征提取带来更有效的学习和卓越的性能。
RoRD[121]提出了一种带有对应集合的双头D2Net模型,通过结合香草和旋转鲁棒特征对应来解决极端视点变化。HDD-Net[122]设计了一个交互式可学习的检测器和描述符融合网络,独立处理检测器和描述符组件,并在学习过程中关注它们的相互作用。MLIFeat[123]设计了两个轻量级模块,用于关键点检测和描述子生成,多级信息融合用于联合检测关键点和提取描述子。LLF[124]提出利用低级特征来监督关键点检测。它从描述符主干扩展单个CNN层作为检测器,并与描述符共同学习,以最大化描述符匹配。feature - booster[125]在传统的特征匹配管道中引入了一个描述符增强阶段。它建立了一个通用的轻量级描述符增强框架,该框架将原始描述符和关键点的几何属性作为输入。该框架采用基于MLP的自增强和基于变压器的交叉增强[126]来增强描述符。ASLFeat[127]利用多层次特征映射上的通道和空间峰值改进了D2Net。它引入了精确的检测器和不变描述符,以及多层次连接和可变形卷积网络。密集预测框架采用可变形卷积网络(DCN)来缓解从低分辨率特征图中提取关键点所带来的限制。SeLF [128]构建在Aslfeat架构上,利用来自预训练的语义分割网络的语义信息,用于学习语义感知的特征映射。因此,它将学习到的对应感知特征描述符与语义特征相结合,增强了长期定位的局部特征匹配的鲁棒性。最后,SFD2[129]提出通过隐式地将高级语义嵌入到检测和描述过程中,从全局区域(例如建筑物、交通车道)中提取可靠特征,同时抑制不可靠区域(例如天空、汽车)。这使得该模型能够从单个网络中端到端提取全局可靠特征。构建在Aslfeat架构上,利用来自预训练的语义分割网络的语义信息,用于学习语义感知的特征映射。因此,它将学习到的对应感知特征描述符与语义特征相结合,增强了长期定位的局部特征匹配的鲁棒性。最后,SFD2[129]提出通过隐式地将高级语义嵌入到检测和描述过程中,从全局区域(例如建筑物、交通车道)中提取可靠特征,同时抑制不可靠区域(例如天空、汽车)。这使得该模型能够从单个网络中端到端提取全局可靠特征。
2.3. Describe-then-Detect
局部特征提取的一种常见方法是描述-然后检测管道,首先使用特征描述符对局部图像区域进行描述,然后基于这些描述符检测关键点。图4 ©显示了描述-然后检测管道的标准结构。
D2D[130]提出了一种新的关键点检测框架,称为描述到检测(D2D),突出了特征描述阶段固有的丰富信息。该框架涉及生成大量密集特征描述符的集合,然后从该数据集中选择关键点。D2D引入了局部深度特征图的相对和绝对显著性测量来定义关键点。由于弱监督无法区分检测和描述阶段之间的损失所带来的挑战,PoSFeat[131]在专门为弱监督局部特征学习设计的描述-检测管道中提出了一种解耦训练方法。该管道将描述网络从检测网络中分离出来,利用相机姿态信息进行描述符学习,从而提高性能。通过一种新颖的搜索策略,描述符学习过程更熟练地利用了相机姿态信息。ReDFeat[132]使用相互加权策略将多模态特征学习的检测和描述方面结合起来。SCFeat[133]提出了一种用于弱监督局部特征学习的共享耦合桥策略。通过共享耦合桥和交叉归一化层,该框架确保了描述网络和检测网络的个性化、最优训练。这种隔离增强了描述符的鲁棒性和整体性能。
2.4. Graph Based
在传统的特征匹配管道中,通过特征描述符的最近邻(NN)搜索建立对应关系,并根据匹配分数或相互NN验证来消除异常值。近年来,基于注意力的图神经网络(gnn)[134]已经成为获得局部特征匹配的有效手段。这些方法创建以关键点为节点的gnn,并利用变形金刚的自关注层和交叉关注层在节点之间交换全局视觉和几何信息。这种交换克服了仅仅局限于局部特征描述符所带来的挑战。最终的结果是基于软赋值矩阵生成匹配。图5提供了基于图的匹配的基本架构的全面描述。
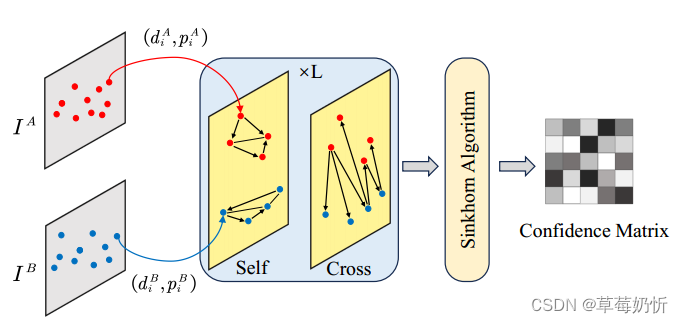
图5:通用GNN匹配模型架构。首先,关键点位置pi及其视觉描述符di被映射到单独的向量中。随后,自注意层和交叉注意层在图神经网络中交替应用L次,以创建增强的匹配描述符。最后,利用Sinkhorn算法来确定最优的部分分配。
超级胶水[69]采用注意力图神经网络和最优传输方法来解决部分分配问题。它处理两组兴趣点及其描述符作为输入,并利用自我和交叉注意在两组描述符之间交换消息。这种方法的复杂性随着关键点的数量呈二次增长,这促使了后续工作的进一步探索。SGMNet[70]建立在超级胶水的基础上,并添加了一个播种模块,该模块只处理匹配点的子集作为种子。对于稀疏连接图,放弃了完全连接图。然后设计一个带有注意力机制的种子图神经网络来聚合信息。关键点通常只与几个点表现出很强的相关性,导致大多数关键点形成稀疏连接的邻接矩阵。因此,ClusterGNN[71]利用图节点聚类算法将图中的节点划分为多个聚类。该策略利用具有聚类的注意力GNN层学习两组关键点及其相关描述符之间的特征匹配,从而训练子图以减少冗余信息传播。MaKeGNN[135]在稀疏关注GNN架构中引入了双边上下文感知采样和关键点辅助上下文聚合。
受超级胶水的启发,GlueStick[136]将点和线描述符合并到一个联合框架中,用于联合匹配,并利用点对点关系连接匹配图像中的线。LightGlue[137]为了使Super-Glue在计算复杂度上具有适应性,提出了基于每个图像对之间的匹配难度动态改变网络深度和宽度的方法。它设计了一个轻量级的置信度分类器来预测和磨练状态标记。DenseGAP[138]设计了一种图结构,利用锚点作为图像间和图像内上下文的稀疏但可靠的先验。它通过有向边将该信息传播到所有图像点。HTMatch[139]和Paraformer[140]研究了注意力在交互中的应用尝试混合和探索在效率和效果之间取得平衡的架构。ResMatch[141]提出了残差注意学习的思想,用于特征匹配,将自注意和交叉注意重新表述为相对位置参考和描述符相似度的习得残差函数。它旨在弥合可解释匹配和过滤管道与基于注意力的特征匹配网络之间的鸿沟,这些网络通过经验手段固有地具有不确定性。
3. Detector-free Models
虽然特征检测阶段可以减少匹配的搜索空间,但处理极端情况,例如涉及大量视点变化和无纹理区域的图像对,在使用基于检测的方法时被证明是困难的,尽管有完美的描述子和匹配方法[142]。另一方面,无检测器方法消除了特征检测器,并直接在分布在图像上的密集网格上提取视觉描述符,以产生密集匹配。因此,与基于检测器的方法相比,这些技术可以捕获跨图像对可重复的关键点。
3.1. CNN Based
在早期阶段,无检测匹配方法通常依赖于使用相关性或成本量来识别潜在邻域一致性的cnn[142]。图6展示了4D对应体的基本架构。
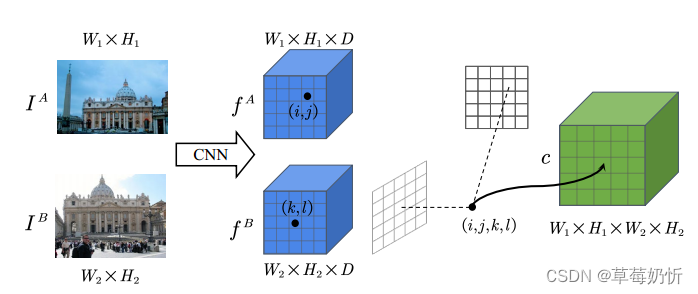
图6:四维通信卷概览。使用卷积神经网络从图像IA和IA中提取密集特征映射,记为f A和f B。每个单独的特征匹配fijA和f klB对应于匹配的(i, j, k, l)坐标。最终形成4D相关张量c,其中包含一对图像之间所有点的分数,这些点可能是对应的点。随后,通过分析四维空间中对应点的属性,获得匹配对。
NCNet[64]分析了一对图像之间所有可能对应点在四维空间中的邻域一致性,无需全局几何模型即可获得匹配。sparse - ncnet[65]利用稀疏相关张量上的4D卷积神经网络,并利用子流形稀疏卷积来显著降低内存消耗和执行时间。DualRC-Net[66]引入了一种创新的方法,以粗到细的方式在图像对之间建立密度像素对应关系。该方法利用具有类似特征金字塔网络(FPN)骨干的双分辨率策略,从粗分辨率特征图生成4D相关张量,并通过可学习的邻域共识-共识模块对其进行细化,从而提高匹配可靠性和低化精度。GLU-Net[67]引入了一种全局-局部通用网络,适用于估计几何匹配、语义匹配和光流的密集对应。它以一种自监督的方式训练网络。GO-Cor[143]提出了一个完全可微的密集匹配模块,它预测了两个深度特征图之间的全局优化匹配置信度,可以集成到最先进的网络中,直接替换特征相关层。DCFlow[144]利用立体匹配中使用的方法,利用四维成本体积增强光流估计。通过应用学习特征嵌入和适应四维半全局匹配,DCFlow解决了传统上与这种广泛方法相关的计算障碍。它在构建和处理成本体积方面的效率,加上保持精度,标志着集成光流和立体估计技术的改进。在这些概念进步的基础上,RAFT[145]进一步完善了密集对应估计的方法。RAFT通过提取每像素特征并为所有像素对构建多尺度四维相关体,引入循环处理单元,迭代细化流场。这种创新策略有效地解决了以前方法的几个局限性,例如粗分辨率下的误差传播和忽略小的、快速移动的物体,从而提高了流量估计的精度和可靠性。在这些基础方法的基础上,PDC-Net[68]提出了一种概率深度网络,用于估计密集的图像到图像对应及其相关的置信度估计。它引入了一种架构和一种改进的自监督训练策略,以实现可泛化的鲁棒不确定性预测。PDC-Net+[146]引入了一种概率深度网络,用于估计密集图像到图像的对应关系及其相关的置信度估计。他们采用约束混合模型来参数化预测分布,增强了处理离群值的建模能力。PUMP[147]将无监督损失与标准自监督损失相结合,以增强合成图像。通过利用4D相关体积,它利用了DeepMatching[148]的非参数金字塔结构来学习无监督描述符。DFM[149]利用预训练的VGG架构作为特征提取器,在不需要额外训练策略的情况下捕获匹配,从而展示了从VGG网络的最深层提取特征的强大功能。
3.2. Transformer Based
CNN的密集特征接受场在处理低纹理区域或识别具有相似特征表示的关键点方面可能存在局限性。相比之下,人类倾向于同时考虑局部和全局信息当在这些区域进行匹配时,会考虑局部和全局信息。鉴于变形金刚在图像分类[150]、目标检测[151]和语义分割[152,153,154,155,156]等计算机视觉任务中的成功,研究人员探索了将变压器的全局接受场和远程依赖关系整合到局部特征匹配中。将变压器集成到特征提取网络中进行局部特征匹配的各种方法已经出现。
鉴于稀疏匹配和密集匹配的唯一区别是要查询的点的数量,COTR[157]结合了两种方法的优点。它结合自关注共同学习两张匹配的图像,使用一些关键点作为查询,并通过相应的神经网络递归地提炼另一张图像中的匹配。这种整合将两个匹配组合成一个参数优化问题。ECO-TR[158]致力于开发一种端到端模型,通过智能连接多个变压器块,并在共享的多尺度特征提取网络上以从粗到精的方式逐步细化预测坐标,从而加速COTR。LoFTR[72]是开创性的,因为它创建了一个以关键点为节点的GNN,利用自关注层和相互关注层获得两幅图像的特征描述符,并在低纹理区域生成密集匹配。为了克服LoFTR中缺乏局部注意交互的问题,Aspanformer[73]提出了一种基于流量预测概率建模的不确定性驱动方案,该方案自适应地改变局部注意广度,为不同位置分配不同的上下文大小。与S-TREK[98]的检测-然后描述策略相反,S-TREK[98]利用平移和旋转等变关键点检测器与轻量级描述符提取器配对,SE2-LoFTR[159]采用无检测器范式,无缝提取图像对之间的像素级对应关系,而不需要关键点检测的初步步骤。该模型通过加入可导向CNN来增强原始的LoFTR框架,从而实现平移和旋转的固有等方差。这种修改显著提高了模型对旋转方差的弹性,展示了该模型通过直接图像对应对特征匹配领域的独特贡献。SE2-LoFTR的方法体现了无探测器模型在处理复杂图像匹配场景中的多功能性和效率,特别是那些涉及重大旋转运动的图像匹配场景。
为了解决密集匹配方法中存在大量相似点所带来的挑战以及线性变压器本身性能的限制,最近的一些工作提出了新的方法。四叉树[160]引入了四叉树注意力,以便在更精细的层次上快速跳过不相关区域的计算,从而降低了从二次到线性的视觉转换的计算复杂性。OETR[161]引入了重叠回归方法,该方法使用Transformer解码器来估计图像中边界框之间的重叠程度。它整合了一个对称的中心一致性损失,以确保重叠区域的空间一致性。OETR可以作为预处理模块插入到任何局部特征匹配管道中。MatchFormer[162]设计了一个分层变压器编码器和一个轻量级解码器。在高层次结构的每个阶段,交叉关注模块和自关注模块相互交错,提供最优组合路径,增强了多尺度特征。CAT[163]提出了一种基于自注意机制的上下文感知网络,其中可以沿空间维度应用注意层以获得更高的效率,也可以沿通道维度应用注意层以获得更高的精度并减少存储负担。TopicFM[164]利用主题建模方法对图像中的高级上下文进行编码。这通过关注图像中语义相似的区域来提高匹配的鲁棒性。ASTR[165]引入了一个Adaptive Spot-guided Transformer,其中包括一个点引导聚合模块,允许大多数像素避免不相关区域的影响,同时使用计算的深度信息在细化阶段自适应调整网格的大小。DeepMatcher[142]引入了Feature transform - Module,以确保从cnn中提取的局部聚合特征平滑过渡到从Transformers中提取的具有全局接受域的特征。它还提出了Slim-Former,它构建了深度网络,采用分层策略,使网络能够自适应地吸收残块内的信息交换,模拟类似人类的行为。OAMatcher[166]提出了重叠区域预测模块(overlap Areas Prediction Module)来捕获共可见区域中的关键点,并在其中进行特征增强,模拟人类如何将焦点从整个图像转移到重叠区域。他们还提出了一种匹配标签权重策略(Matching Label Weight Strategy)来生成用于评估真实匹配标签可靠性的系数,使用概率来确定匹配标签是否正确。CasMTR[167]提出通过结合级联匹配和NMS检测的新阶段来增强基于变压器的匹配管道。
PMatch[168]通过使用LoFTR模块,使用配对掩膜图像建模借口任务,对变压器模块进行预训练,增强了几何匹配性能。为了有效地利用几何先验,SEM[169]引入了结构化特征提取器,该提取器对像素和高度自信的锚点之间的相对位置关系进行建模。它还结合了外极注意和匹配技术,以过滤掉基于外极约束的不相关区域。DKM[170]通过设计密集特征匹配方法来解决双视图几何估计问题。DKM提供了一个具有核回归器和嵌入式解码器的鲁棒全局匹配器,包括通过应用于堆叠特征映射的大深度核进行warp细化。在此基础上,RoMa[171]通过应用马尔可夫链框架来分析和改进匹配过程,代表了密集特征匹配方面的重大进步。它引入了一种两阶段的方法:用于全局一致匹配的粗糙阶段和用于精确定位的细化阶段。该方法将初始匹配与细化过程分离,并采用鲁棒回归损失以获得更高的精度,导致匹配性能显着提高,优于当前的SotA。
3.3. Patch Based
基于补丁匹配方法通过匹配局部图像区域来增强点的对应性。它包括将图像划分为patch,为每个patch提取描述符向量,然后对这些向量进行匹配以建立对应关系。这种技术可以适应大位移,在各种计算机视觉应用中都很有价值。图7说明了基于补丁匹配方法的一般体系结构。
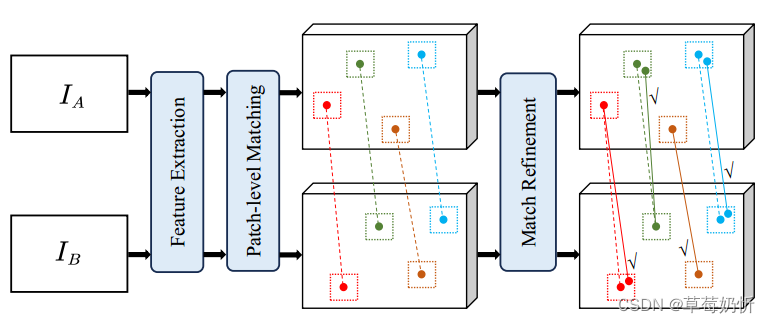
图7:基于补丁的管道示意图。在提取图像特征之后,对从patch级匹配中获得的匹配区域执行Match细化过程,从而得到精细化的点匹配。
Patch2Pix[172]提出了一种弱监督方法来学习与图像对之间的极端几何变换相一致的对应关系。它采用两阶段检测-细化策略进行对应预测,其中第一阶段捕获语义信息,第二阶段处理局部细节。它引入了一种新的细化网络,该网络利用极端几何变换的弱监督,并输出匹配位置和异常值拒绝的置信度,从而实现几何上一致的对应预测。AdaMatcher[173]解决了因在补丁级匹配中应用一对一分配准则而导致的几何不一致问题。它自适应地标记补丁级匹配,同时估计图像之间的尺度,以提高极端情况下密集特征匹配方法的性能。PATS[174]提出了分段Patch Area Transportation with Subdivision (PATS),以自我监督的方式学习尺度差异。它可以处理多对多的关系,而不像二部图匹配,只处理一对一的匹配。SGAM[175]提出了一个分层的特征匹配框架,它首先基于语义线索执行区域匹配,将特征匹配搜索空间缩小到图像之间具有显著语义分布的区域匹配。然后通过几何一致性对区域匹配进行细化,以获得精确的点匹配。
4. Local Feature Matching Applications
4.1. Structure from Motion
SfM代表了一种基础的计算视觉过程,对于从一系列不同的场景图像中推断相机方向、内在参数和体积点云是必不可少的。这一过程证实了诸如
视觉定位、多视角立体和创新视角合成等方面的努力。广泛的学术研究强调了SfM的发展轨迹,产生了牢固建立的方法、复杂的开源框架,如Bundler[176]和COLMAP[12],以及先进的专有软件解决方案。这些框架经过精心定制,以确保在处理扩展场景时的精确性和可扩展性。
传统的SfM方法依赖于分散在多个视角上的稀疏特征点的识别和关联。尽管如此,这种方法在缺乏纹理特征的地区遇到了巨大的挑战,在这些地区,关键点的识别成为一项令人烦恼的工作。Lindenberger等人[177]通过精心细化初始关键点,并在后处理期间对点和相机时代方向进行后续调整,改善了这一困境。所提出的方法战略性地平衡了初始的基本估计与稀疏的局部特征和随后的微调,通过局部精确的密集特征,从而提高了具有挑战性条件下的精度。最近SfM的进展已转向整体方法,即直接回归摆位[178,179]或采用差分束调整[180,181]。这些方法绕过了明确的特征相关性,回避了与次优特征匹配相关的挑战。他等人[182]引入了一种创新的无检测器SfM范式,利用无检测器的匹配器来推迟关键点的确定。该策略巧妙地解决了无检测器匹配器中普遍存在的多视图不一致问题,相对于传统的以检测器为中心的系统,在纹理贫乏的场景中展示了优越的效果。
从传统的稀疏特征识别转向复杂的、偶尔的端到端、密集的匹配范式,SfM方法的进化轨迹可以看出。将这些开创性的方法吸收到现有的SfM工作流程中,可以提高精度和弹性,特别是在艰苦的场景中。然而,将这些方法无缝集成到当代SfM系统中仍然是一个复杂的挑战。
4.2. 遥感影像配准
在遥感领域,深度学习的出现预示着多模态遥感图像配准(MRSIR)的革命性时代[43,183,184,185],用基于学习的管道(LBP)增强传统的基于区域和特征的技术[186,187]。这种LBP分为几种开创性的方法:将深度学习与传统的配准方法相结合,通过模态转换弥补多模态鸿沟,并直接回归转换参数以获得全面的MR-SIR框架[60]。(伪)暹罗网络和生成对抗网络(gan)等技术在这一演变中发挥了关键作用,促进了几何扭曲和非线性辐射差异的管理[188,189]。例如,使用条件gan可以生成伪图像[190],从而提高了NCC[191]和SIFT[17]等现有方法的精度。
在LBP中,已经制定了许多创新的方法和架构。MUNet[184],一种用于学习转换参数的多尺度策略,以及用于特定尺度特征提取的全卷积网络是这一创新的典型例子,解决了非刚性MRSIR的挑战[192]。为了进一步丰富LBP,各种研究都集中在将cnn提取的中高级特征与经典描述符相结合,以克服传统方法的局限性。例如,Ye等人[193,184]设计了一种新的多光谱图像配准技术,采用CNN和SIFT合并,大大提高了配准效率。同样,Wang等人[194]开发了一种端到端深度学习架构,该架构可以识别图像补丁对与其匹配标签之间的映射函数,采用迁移学习来加速训练。Ma等人[195]引入了一种利用CNN和局部特征的粗到精配准方法,通过VGG-16实现了深度金字塔特征表示。Zhou等人[196]开发了一种基于深度学习的方法来匹配合成孔径雷达(SAR)和光学图像,专注于使用浅伪暹罗网络提取多尺度卷积梯度特征(MCGFs)。这种方法有效地捕获了SAR和光学图像之间的共性,超越了手工制作特征的限制,减少了对大量模型参数的必要性。Cui等人[197]介绍了MAP-Net,这是一个以图像为中心的卷积网络,集成了空间金字塔聚合池(SPAP)和注意机制,精通通过嵌入原始图像来提取高级语义信息并使用PCA来提高匹配精度,从而解决跨模态图像中的几何扭曲和辐射度量变化。
尽管取得了这些进步,但数据集构建和方法推广方面的挑战仍然存在,这主要是由于遥感图像的多样性和复杂性[184]。开发全面和具有代表性的训练数据集,再加上为遥感图像精心定制的创新方法,仍然是一个迫切的目标。此外,在雷达和光学图像的像素级融合方面缺乏有价值的研究,需要在未来的努力中给予更多的关注[198]。
4.3. 医学图像配准
随着复杂的深度学习技术的融合,医学图像配准领域发生了重大的发展,特别是在运动估计和2D-3D配准方面。这些进步不仅代表了技术上的飞跃,也为各种医疗应用开辟了新的前景。
医学成像中的运动估计是配准的一个关键方面,它已经通过深度学习得到了实质性的改进。正如Bian等人[199]、Ranjan等人[200]和Harley等人[201]等研究人员所阐述的那样,无监督光流和点跟踪技术解决了医学图像数据固有的复杂性,例如患者解剖结构的可变性以及通过微分同态和不可压缩性保持解剖完整性的需要。基于深度学习的方法在跨不同器官(从心脏到肺部)的运动估计中显示出有效性。例如,秦等人[202]所证明的基于变分自编码器的模型的应用,通过遍历生物力学上合理的变形流形来搜索给定心脏序列的最佳变换,可以获得更好的运动跟踪精度和更合理的心肌运动和应变估计,增强了运动估计的真实感和临床可靠性。DeepTag[203]和DRIMET[204]展示了跟踪内部tis-sue运动的复杂方法,特别是在Tagged-MRI的背景下。这些方法举例说明了通过医学成像中先进的无监督学习技术来估计密集3D运动场的能力。可变形医学图像配准的单次学习的最新进展在当代研究中得到了明显的体现,特别是在将单次学习应用于复杂的3D和4D医学数据集方面,从而提高了准确性,减少了对大型训练数据集的依赖,并拓宽了适用范围。Fechter等人[205]为3D和4D数据集中的深度运动跟踪引入了一种一次性学习方法,解决了需要大量训练数据的挑战。他们的方法利用具有粗到精策略的U-Net架构,将通道维度上不同阶段的图像连接在一起。这种方法允许同时计算3D数据集中的正变换和逆变换。Zhang等人[206]介绍了一种用于4D图像配准的一次性深度学习方法GroupRegNet。它采用隐式模板,有效地减少了偏差和累积误差。简单的GroupRegNet的网络设计和它的直接配准过程消除了对图像分区的需要,从而在计算效率和准确性显著提高。Ji等人[207]进一步推动了该领域的发展,提出了一种肺部4D-CT图像的时空配准方法。该方法集成了CNN-ConvLSTM混合架构,熟练地建模图像的时间运动,同时结合双流方法来解决周期性运动约束。基于混合范式的配准网络(Hybrid Paradigm-based Registration Network, HPRN)[208]引入了一种用于4D-CT肺部图像配准的无监督学习框架,可以在没有真实数据的情况下有效处理大变形。HPRN通过学习多尺度特征,结合先进的损失函数,避免了裁剪和缩放等预处理步骤,实现了优越的配准精度。
2D-3D配准是一个关键组成部分,特别是在介入手术中[209]。这一过程对于将2D图像(如x射线、超声或内窥镜图像)准确地叠加到3D术前CT或MR图像上至关重要。这里的关键挑战在于这些不同维度的精确几何对齐。传统的2D-3D配准方法依赖于基于图像强度的相似性度量的迭代优化方法[210]。然而,这些方法经常与问题的非凸性质作斗争,如果初始估计不接近实际解,可能导致收敛到不正确的解。再加上在2D图像上表示3D空间信息的固有困难,导致配准歧义。然而,最近的进展已经转向了基于深度学习的方法。与传统方法不同,这些方法不需要显式的功能映射,从而允许更健壮的解决方案来应对注册挑战[211]。在有关2D-3D医学图像配准的最新发展领域,Jaganathan等人[212]引入了一种用于x射线和CT图像融合的自监督范式。该方法利用模拟的x射线投影来促进深度神经网络的训练,最终显著提高了配准精度和成功率。同时,Huang等人[213]设计了一个为神经病学干预量身定制的两阶段框架。这种创新的方法将CNN回归与质心对齐相结合,在实时临床应用中表现出卓越的疗效。除了刚性2D-3D配准之外,人们对非刚性配准也越来越感兴趣,这在诸如头测量、放射治疗中的肺肿瘤跟踪和全髋关节置换术(THA)等应用中至关重要[214,215,216]。深度学习模型,如卷积编码器,已被用于解决非刚性配准的挑战[217,218]。
运动估计和2D-3D配准技术在医学图像配准中的融合解决了参数优化和模糊的关键挑战,提高了医学成像过程的速度和准确性。该领域的持续发展将彻底改变诊断和介入程序,使其更高效,以患者为中心,并以结果为中心。有兴趣的读者可以参考综合调查[58,57],了解基于深度学习的医学图像配准方法的详细概述。
5. 局部特征匹配数据集
局部特征匹配方法通常根据其在下游任务中的有效性进行评估。在本节中,我们将提供一些用于评估局部特征匹配的最广泛使用的数据集的摘要。我们将这些数据集分为五组:图像匹配数据集、相对姿态估计数据集、视觉定位数据集、光流估计数据集和运动结构数据集。对于每个数据集,我们将提供有关其包含的特征的详细信息。
5.1. 图像匹配数据集
HPatches[219]基准是图像匹配工作的重要标准。它包括116个由视点和亮度波动区分的场景序列。在每个场景中,有5对图像,以首幅图像作为参考点,序列中的后续图像的复杂性逐渐增强。该数据集分为两个不同的主体:视点,包括59个视点变化显著的序列,以及照明,包括57个光照变化显著的序列,涵盖自然和人工亮度条件。在每个测试序列中,一个参考图像与剩余的五个图像配对。值得注意的是,根据D2Net的评价方法,通常使用56个视点变化显著的序列和52个光照变化显著的序列来评价网络的性能。从SuperPoint[61]开始,HPatches数据集也被用于评估局部描述子在单应性估计任务中的性能。
Roto-360[113]是一个由360个图像对组成的评估数据集。这些对以10°的间隔在0°到350°的平面内旋转为特征。该数据集是通过随机选择和旋转10个HPatches图像生成的,这对于评估描述符在旋转不变性方面的性能很有价值。
ZEB[220]揭示了一个创新的零射击评估基准,精心设计,以解决在不同领域的图像匹配泛化的挑战。它协调了来自8个真实世界和4个模拟数据集的数据,封装了广泛的图像分辨率、环境条件和视角。这种融合最终形成了一个强大的基准,其中包含46,000个评估图像对,通过五种不同的图像重叠比率进行策划,范围从10%到50%,通过可验证的地面真实姿势和深度图确定。ZEB的全面和扩展的数据集在范围和多样性方面是无与伦比的,明显超过了传统的1500个域内图像对,在评估图像匹配模型的跨域泛化能力方面取得了巨大进步。ZEB通过其严格的装配,不仅阐明了现有领域特定模型在非受控场景下的泛化差异,而且为衡量图像匹配算法在现实世界逆境中的弹性和通用性建立了一个新的基准。
2019年启动的图像匹配挑战(IMC)系列,通过精心策划的数据集和全面的基准评估框架,不断突破局部特征匹配方法的界限。每年,IMC都会引入新的挑战和数据集,反映现实世界图像匹配场景中遇到的不断变化的复杂性和多样性。从利用大量图像进行密集的3D重建,到探索摄影旅游、城市景观的细微差别,以及无人机和单反相机捕捉的复杂细节,IMC系列为推进图像匹配技术提供了一个强大的平台。IMC 2020[221]数据集围绕使用现成的SfM技术(如Colmap)从大量图像集合中生成密集而准确的3D重建而展开。该挑战提出了摄影旅游数据集,该数据集来自著名地标的摄影旅游图像集合,用于评估和基准不同的图像匹配方法,以伪地面真实姿势和深度图。训练数据包括图像、姿势、深度图和共可见性估计,并有一个验证集可用于提交前的方法微调。在IMC 2020基础工作的基础上,IMC 2021[222]扩大了视野,引入了三个数据集:“Phototourism”、“PragueParks”和“GoogleUrban”,每个数据集都展示了图像匹配技术的独特挑战。“摄影旅游”延续了2020年挑战赛的内容,“布拉格公园”介绍了用现代智能手机拍摄的视频序列图像,“谷歌城市”则侧重于利用从全球不同手机收集的图像评估定位算法。对于IMC 2022[223]和IMC 2023[224],鼓励参与者探索Kaggle官方网站以获取有关数据集和基准的详细信息。IMC 2023特别引入了三个新的数据集——“遗产”、“海波”和“城市”——每个数据集都提出了独特的挑战,如无人机对地成像、昼夜变化、重复模式、钢丝物体和规模变化。这些数据集旨在测试当前图像匹配算法的局限性,并促进能够解决现实世界图像匹配场景复杂挑战的新颖解决方案的开发。 (数据集换成英语)
5.2. 相对姿态估计数据集
ScanNet[225]是一个大规模的室内数据集,具有定义良好的训练、验证和测试分割,包括来自1613个场景的大约2.3亿个定义良好的图像对。与Hpatches数据集相比,该数据集包括地面真值和深度图像,并且包含更多具有重复和弱纹理的区域,因此提出了更大的挑战。
YFCC100M[226]是一个庞大的数据集,收集了各种旅游地标的互联网图像。它包含1亿个媒体对象,其中约9920万是照片,80万是视频,每个媒体对象由几个元数据块表示,如Flickr标识符、所有者姓名、相机信息、标题、标签、地理位置和媒体来源。通常,使用YFCC100M的一个子集进行评估,该子集由四个流行的地标图像集组成,每个图像集有1000对图像对,因此测试集总共有4000对,并遵循[77,69,70,73]中使用的惯例。
MegaDepth[227]是一个数据集,旨在解决极端视点变化和重复模式下的匹配挑战任务。它包含来自196个不同户外场景的100万张图像对,每个图像对都有已知的姿势和深度信息,可用于验证户外场景中姿势估计的有效性。作者还提供了使用COLMAP[12]进行稀疏重建和多视点立体计算生成的深度图。
EVD(极端视点数据集)[228]是一个精心策划的数据集,专门用于评估极端视点变化情况下的双视点匹配算法。它合并了来自各种可公开访问的数据集的图像对,这些数据集以其复杂的几何配置而区分开来。EVD的产生是由于有必要评估匹配方法在视点明显变化的情况下的弹性。
WxBS(宽多基线立体)[229]解决了宽基线立体匹配领域的一个更广泛的挑战,包括图像获取的多个方面的差异,如视点、照明、传感器类型和视觉变化。该数据集包括37对图像,具有城市和自然环境的混合特征,并根据各种复杂因素的存在进行系统分类。WxBS的地面真值是通过手动选择对应的集合来建立的,捕获在两幅图像中可见的场景片段。WxBS是在一系列苛刻条件下为图像匹配量身定制的算法评估的关键工具。
5.3. 视觉定位数据集
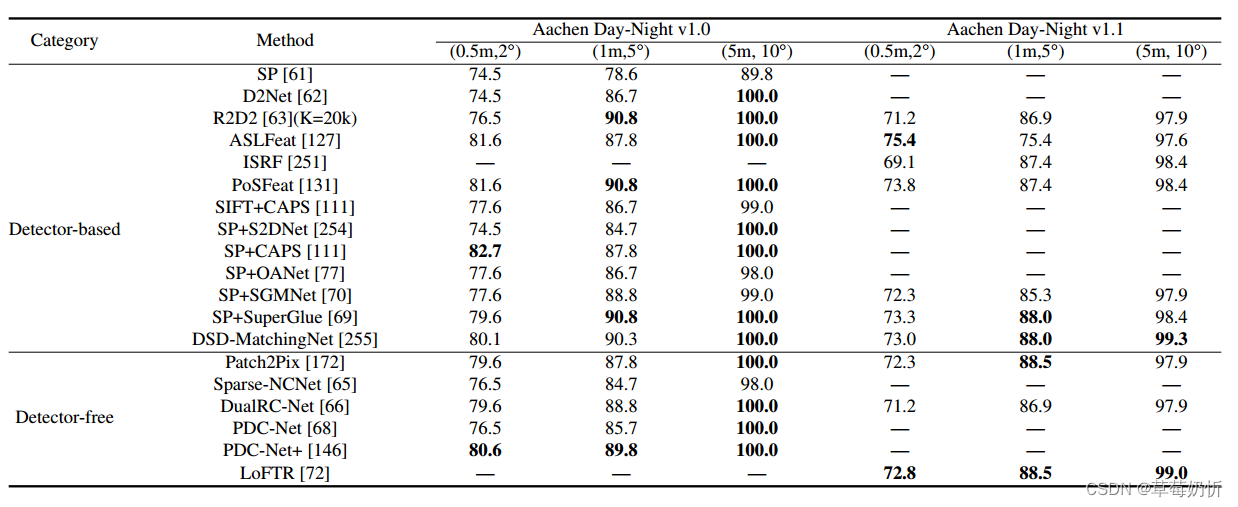
亚琛昼夜[230]是一个由4328张白天图像和98张夜间图像组成的数据集,用于低化任务。这个基准测试挑战了白天和夜间图像之间的匹配,使其成为一个具有挑战性的数据集。亚琛昼夜v1.1[9]是亚琛昼夜数据集的更新版本,包含6697张白天图像和1015张查询图像(824张白天图像和191张夜晚图像)。大照度和视点变化的存在使其成为一个具有挑战性的数据集。
InLoc[116]是包含9972张RGBD图像的室内数据集;其中329张RGB图像被用作查询,用于测试长期室内视觉定位算法的性能。由于其庞大的尺寸(约10k图像覆盖两栋建筑),数据库和查询图像之间的视点和/或照明存在显着差异,以及场景中的时间变化,该数据集提供了各种挑战。除此之外,InLoc数据集还提供了大量来自3D扫描仪的深度图。
RobotCar-Seasons (RoCaS)[231]是一个具有挑战性的数据集,它包含26121张参考图像和11934张查询图像。该数据集呈现了各种环境条件,包括雨、雪、黄昏、冬季和郊区照明不足。这些因素使得特征匹配和视觉定位的任务变得困难。
LaMAR[232]解决了增强现实(AR)中低定位和映射的基础技术,为现实AR场景引入了新的基准。数据集是使用AR设备在不同的环境中捕获的,包括室内和室外场景的动态物体和不同的照明。它具有来自HoloLens 2和iphone / ipad等设备的多传感器数据流(图像、深度、IMU等),覆盖面积超过45,000平方米。LaMAR的地面真相管道将AR轨迹与激光扫描自动对齐,以快速处理来自异构设备的数据。该基准对于评估AR特定的定位和地图绘制方法至关重要,强调了考虑AR设备中的无线电信号等其他数据流的重要性。LaMAR为AR提供了一个真实而全面的数据集,指导了未来视觉定位和地图绘制的研究方向。
5.4. 光流估计数据集
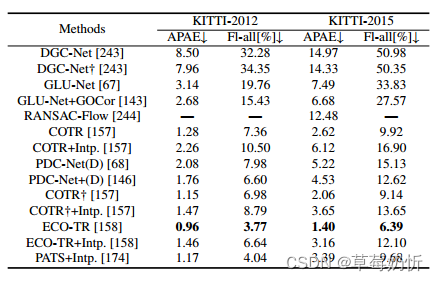
KITTI[233]是在城市交通场景中收集的图像匹配数据集,有2012年和2015年两个版本。KITTI-2012包含194对训练图像对和195对分辨率的测试图像对1226×370, KITTI-2015包含200对分辨率的训练图像对和200对测试图像对1242×375。该数据集包括使用激光扫描仪获得的稀疏地面真值差异。KITTI-2012中的场景相对简单,而KITTI-2015数据集由于其动态场景和复杂场景而面临挑战。
5.5. 来自Motion Datasets的结构
SUN3D[234]提供了一个全面的RGB-D视频数据库,精心注释以捕捉各种室内环境的完整3D范围。它包含41座建筑物内254个空间的415个序列,为SfM评估提供了丰富的资源。利用华硕Xtion PRO LIVE传感器,SUN3D模拟了人类的视觉视角,促进了直观标记和广义束调整的创新结合,以增强语义分割和相机姿态精度。这种方法不仅解决了重建错误,而且还通过详细的3D对象模型、点云和语义地图丰富了数据集,使其成为推进局部特征匹配、场景理解和3D重建研究的宝贵资产。
DTU[235]是致力于推进多视点立体(MVS)领域的详尽资源。DTU数据集包括来自49或64个精确相机位置的80个精心记录的场景,在七种不同的照明场景下,引入了各种各样的挑战,包括镜面反射,纹理差异和几何复杂性。它提供了一个严格控制的环境,以1200 x 1600像素的分辨率捕获图像,并辅以一丝不苟的精确结构光扫描,用于基准测试和评估目的。该数据集对于深入研究3D重建中平衡精度和完整性的细微差别,导航网格生成的复杂性以及评估照明条件对MVS效率的影响至关重要。
坦克与寺庙[236]是用于评估基于图像的3D重建管道的基准测试工具。它包含了在现实条件下捕获的各种室外景观和室内设置。地面真实数据通过工业激光扫描仪获取,提供高分辨率视频序列作为输入。数据集被分层为中级和高级层,包含大量车辆、建筑结构和复杂的几何配置,以挑战当前的重建管道。《坦克与寺庙》由14个场景组成,从单一物体到广阔的室内和室外景观,通过精心策划的地面真实点云和从4K视频序列中推断出来的相机姿势,推动了3D重建的界限。该数据集是优化和评估擅长遍历大规模场景重建中固有复杂性的算法的关键,为增强基于图像的3D重建方法的弹性和准确性提供了不可或缺的资产。
ETH[237]是一个数据集,旨在通过从一组可用的2D图像中构建3D模型来评估SfM任务的描述符。继D2Net之后,评估了三个中等规模的数据集:马德里大都会、宪兵市场和伦敦塔[238]。ETH数据集包括各种摄像机和条件,为比较不同方法的性能提供了具有挑战性的基准。
ETH3D[239]是多视角立体算法的综合基准。该数据集涵盖了室内和室外的各种场景,通过高分辨率数码单反相机和同步的低分辨率立体视频捕获。这个数据集的独特之处在于它结合了高空间和时间分辨率。从自然环境到人造环境的场景,它为详细的3D重建带来了新的挑战,特别关注手持移动设备在立体视觉场景中的应用。ETH3D提供多种评估协议,以满足高分辨率多视图立体,低分辨率多视图视频数据和双视图立体。因此,它是推进密集3D重建领域研究的宝贵资产。
ENRICH[240]提出了一个综合的、通用的数据集,专门用于评估和比较摄影测量和计算机视觉技术,重点是SfM和MVS方法。它包括三个不同的子集- enrich - aerial, ENRICH-Square和enrich - statue -每个子集都提供了在各种照明条件下渲染的高分辨率图像集合,相机方向,比例和视点,以密切模仿现实世界的复杂性。根据真实物体的3D模型创建,以确保真实的纹理和几何形状,ENRICH采用仿照尼康D750数码单反相机的虚拟相机时代来捕捉无失真的图像。除了作为SfM和MVS算法评估的严格平台外,ENRICH还提供了大量的地面真实数据,包括GCP坐标、深度图和3D模型。这个丰富的数据集具有从鸟瞰图到地面场景的质量和规模多样性,是推动遥感、摄影测量和计算机视觉研究边界的关键资产,促进了包括图像匹配和单目深度估计在内的广泛应用。
5.6. 数据集差距和未来需求
尽管上述数据集为评估局部特征匹配方法提供了宝贵的资源,但仍存在需要解决的重大差距。
一个主要的差距是缺乏模拟极端环境条件的数据集。虽然像RoCaS[231]这样的数据集的存在提供了一些环境条件的可变性,包括不同的天气场景和照明条件,但需要专门关注大雨、雾或雪等具有挑战性的天气场景的数据集。这些条件在特征匹配方面提出了独特的挑战,对于气候敏感地区的应用至关重要。另一个差距是高度动态环境的有限表征。目前的数据集,包括广泛使用的HPatches[219],虽然全面检查了视点和照明的变化,但不能充分捕捉拥挤的城市地区或快速移动场景的复杂性。这一限制对于需要在人口密集地区进行实时监测和监视的应用来说是非常重要的。能够模拟此类环境动态的数据集对于在这些环境中推进特征匹配技术至关重要。此外,明显缺乏针对特定应用领域(如水下或航空图像)量身定制的数据集。这些领域具有独特的特征和挑战,而像ETH[237]或Aachen Day-Night[230]这样的数据集并没有解决这些问题。这些领域的专业数据集对于海洋生物学或基于无人机的监测等领域的研究和开发将是非常宝贵的。
综上所述,虽然现有数据集对局部特征匹配领域做出了重大贡献,但显然需要更专业的数据集。这些数据集的目标应该是填补现有的空白,满足各种应用领域不断发展的需求,从而使局部特征匹配技术取得进一步的进步。
6. Performance Review
6.1. 匹配模型的度量
6.1.1. 图像匹配
重复性[241,52]。比较两幅图像的可重复性度量是这样计算的:取图像之间发现的匹配特征区域的计数,并将其除以两幅图像中发现的较小的特征区域计数,随后乘以100以百分比表示结果。这种定量评估对于在遭受不同几何变化时衡量特征检测器的一致性至关重要:
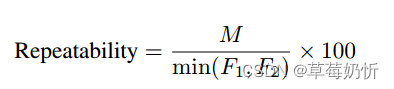
其中,M表示两幅图像之间匹配的特征区域的数量,F1表示在第一幅图像中检测到的特征区域的总数,F2是在第二幅图像中检测到的特征区域的总数。
匹配分数(M-score)[61,78]。M-Score通过计算在两幅图像的重叠区域中正确匹配的特征与检测到的总特征的平均比率来量化特征检测和描述管道的有效性。平均匹配精度(Mean Matching Accuracy, MMA)[62]用于衡量在考虑多像素误差阈值的情况下图像对之间的特征匹配执行得有多好。它表示考虑多个像素误差阈值的图像对中正确匹配的平均百分比。该度量只考虑最近邻匹配,如果使用提供的单应性估计的重投影误差低于给定的匹配阈值,则认为匹配是正确的。特征和Matches[62]评估特征描述符的性能。feature表示每张图像检测到的特征的平均数量,Matches表示匹配成功的特征的平均数量。正确关键点百分比(Percentage of Correct Keypoints, PCK)[111]度量标准通常用于衡量密集匹配的性能。它涉及从图像网格上的第一张图像中提取关键点,并在完整的第二张图像中找到它们最近的邻居。如果查询点的预测匹配落在地面真值匹配的某个像素阈值内,则认为它们是正确的。
6.1.2. 同形估计
角度正确性度量通常用于评估特征匹配算法的性能。该度量涉及估计两幅图像之间的单应性变换H -,并将变换后的角与使用基真单应性变换H[61]计算的角进行比较。为了确保在产生不同匹配数的方法之间进行公平的比较,基于H -和H -扭曲的图像之间的角误差计算正确性标识符。如果四个角的平均误差小于指定的像素阈值ε,通常范围为1到10像素,则认为估计的单应性是正确的。一旦确定了估计的单应性的正确性,使用曲线下面积(AUC)度量来评估图像之间的角度误差。该度量在各种阈值下计算误差积累曲线下的面积,量化匹配的准确性和稳定性。AUC值代表整体匹配性能,值越高表示性能越好。
6.1.3. 相对姿势估计
在评估估计的相机姿势时,典型的方法包括测量旋转和平移中的角度偏差[242]。在这种方法中,如果角度偏差小于某个阈值,则认为旋转或平移是正确估计的,并报告该阈值下的平均精度。帧之间的间隔用dframe表示,其中较大的值表示更具有挑战性的图像对进行匹配。对于不同阈值下的姿态误差。最常见的指标包括AUC、匹配精度、匹配分数。其中,平移误差和角度误差的最大值通常记为姿态误差。
6.1.4. 视觉定位
评估过程通常遵循视觉定位基准2中概述的通用评估协议。使用Cus-tom特征作为系统的输入,然后使用COLMAP[12]等框架执行图像配准过程。最后,计算在预定义容差范围内成功定位的图像的百分比。为了报告评估方法的性能,通常使用不同阈值下位姿误差的累积AUC。
6.1.5. 光流估计
用于光流估计的评估指标包括平均终点误差(AEPE)、流量异常值比(Fl)和正确关键点百分比(PCK)[243,67]。AEPE的特征是估计真值与地面真值对应图之间的平均欧几里得分离。具体来说,它量化了预测流场和实际流场之间的欧几里得差距,计算为目标图像内有效像素的平均值。Fl评估所有像素上异常值的平均百分比,其中异常值被定义为流量误差超过3个像素或5%的地面真实流量。PCK阐明了与相应的地面真值点xi在指定阈值(以像素为单位)内的适当匹配的估计点xˆi的百分比。
6.1.6. 来自运动的结构
正如ETH[237]规定的评估框架所描述的那样,采用了一套关键指标来严格评估重建过程的保真度。这些指标包括注册图像的数量,这是重建全面性的一个指标,以及稀疏点指标,它提供了对场景描绘的深度和复杂性的见解。此外,图像度量中的总观测值对于摄像机的校准和三角测量过程至关重要,它表示稀疏点的确认图像投影。平均特征轨迹长度表示每个稀疏点验证图像观测值的平均计数,在确保精确校准和鲁棒三角测量中起着至关重要的作用。最后,平均重投影误差是衡量重建精度的关键指标,它封装了在束平差中观察到的累积重投影误差,并受到输入数据的彻彻性和关键点检测精度的影响。
ETH3D[239]中的关键指标对于评估各种SfM方法的有效性至关重要。利用姿态误差在不同阈值下的AUC来评估多视角相机姿态估计的精度。该度量反映了估计的相机姿态相对于地面真值的精度。在不同距离阈值下的精度和完整性百分比评估了3D三角测量任务。准确性是指重建点在距离真实点一定距离内的比例,完整性是指重建点云中真实点的比例。
6.2. 定量性能
在本节中,我们根据6.1节提供的评估分数来分析几种关键方法的性能,其中包括前面讨论的各种算法和附加方法。我们将它们在流行基准上的表现汇编成表格,其中的数据要么来自原作者,要么来自其他作者在相同评估条件下的最佳报告结果。此外,一些出版物可能会报告在非标准基准/数据库上的性能,或者只涉及流行基准测试集的某些子集。我们没有给出这些方法的性能。
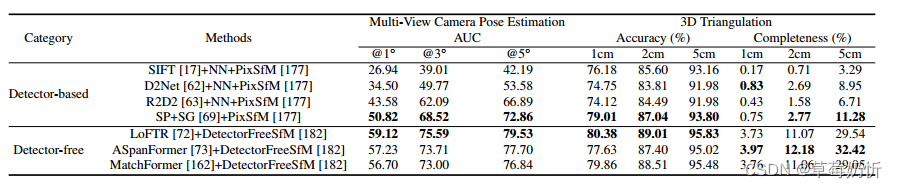
下表提供了几种主要的基于dl的匹配模型在不同数据集上的性能总结。表1突出显示了HPatches[219]测试集,采用LoFTR方法[72]使用的评估协议。性能指标基于角误差距离的AUC,最高可达3、5和10像素。表2关注的是ScanNet[225]测试集,遵循SuperGlue[69]测试方案。报告的度量是位姿AUC误差。Ta-ble 3以YFCC100M[226]测试集为中心,采用基于RANSAC-Flow[244]的协议。此外,还报告了姿态mAP (mean Average Precision)值。如果一个姿态估计在平移或旋转中的最大度误差超过阈值,那么它就被认为是一个离群值。表4突出显示了MegaDepth[227]测试集。根据SuperGlue[69]评估方法,报告了位姿估计AUC误差。表5和表6分别在局部特征评估轨迹和全视觉定位轨迹中强调了Aachen Day-Night v1.0[230]和v1.1[9]测试集。表7重点介绍了InLoc[116]测试集。报告的指标包括在特定错误阈值下正确本地化查询的百分比,遵循HLoc[245]管道。表8强调了KITTI[233]测试集的大小。2012年和2015年版本的KITTI数据集都报告了AEPE和流量异常值比Fl。表9侧重于ETH3D[239],给出了DetectorFreeSfM[182]中报道的各种SfM方法的详细评估。该评估通过三个关键指标彻底检查了这些方法的有效性:AUC、准确性和完整性。
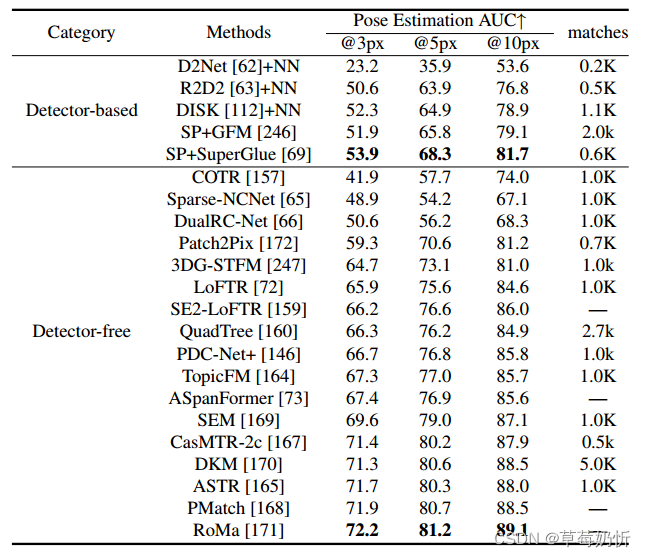
表1:HPatches对单应性估计的评价[219]。我们比较了两组方法,基于检测器的方法和无检测器的方法。
7. 挑战与机遇
深度学习为基于图像的局部特征匹配带来了显著的优势。然而,仍有几个挑战有待解决。在接下来的章节中,我们将探索潜在的研究方向,我们认为这些方向将为基于图像的局部特征匹配算法的进一步发展提供有价值的动力。
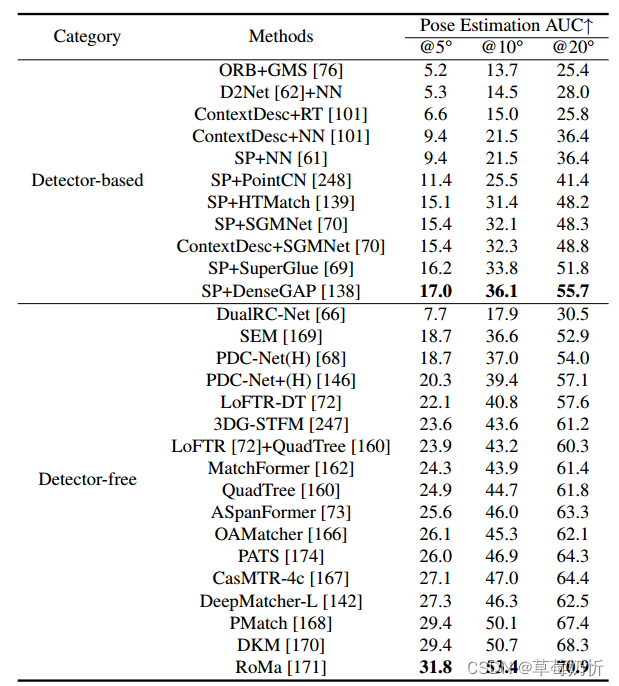
表2:ScanNet [225] Two-View Camera Pose Estimation。我们比较了两组方法,Detector-based方法和Detector-free方法。
7.1. Efficient Attention and Transformer
对于局部特征匹配,可以考虑将变压器集成到GNN模型中,将任务框架为涉及两组特征的图匹配问题。为了增强更好的匹配器的构建,通常使用变压器内部的自注意层和交叉注意层来交换节点之间的全局视觉和几何信息。除了由匹配检测器生成的稀疏描述符外,还探索了将自注意和交叉注意直接应用于cnn提取的特征图,并以粗到细的方式生成匹配[69,72]。然而,在处理大量的关键点时,变压器中基本矩阵乘法的计算成本仍然很高。近年来,人们一直在努力提高变压器的效率,并尝试并行计算这两类注意力,在保持性能的同时不断降低复杂性[70,71,141,140]。未来的研究将进一步优化注意机制和变压器的结构,旨在在降低计算复杂度的同时保持较高的匹配性能。这将使局部特征匹配方法在实时和资源受限的环境中更加高效和适用。
7.2. Adaptation strategy
近年来,局部特征匹配中的适应性研究取得了重大进展[137,165,173,174,73]。对于延迟敏感的应用,可以在匹配过程中加入自适应机制。这允许基于视觉重叠和外观变化等因素调制网络深度和宽度,从而实现对匹配任务难度的细粒度控制。此外,研究人员提出了各种创新方法来解决规模变化等问题。其中一个关键挑战是如何根据图像尺度变化自适应调整裁剪网格的大小,以避免匹配失败。补丁级特征匹配中的几何不一致性也可以通过自适应分配策略得到缓解,并结合自适应补丁细分策略,在匹配过程中从粗到细逐步提高对应质量。另一方面,可以根据匹配难度自适应调整注意广度,在不同位置实现可变大小的自适应注意区域。这使得网络在捕捉上下文信息的同时,能够更好地适应不同位置的特征,从而提高匹配性能。
综上所述,局部特征匹配中的适应性研究为未来的发展提供了广阔的前景和机会,同时在内存和计算方面提高了效率。随着各个领域出现更多的需求和挑战,预计自适应机制将在局部特征匹配中发挥越来越重要的作用。未来的研究可以进一步探索更细粒度的自适应策略,以实现更高效、更准确的匹配结果。
7.3. 弱监督学习
局部特征匹配不仅在完全监督环境下取得了重大进展,而且在弱监督学习领域也显示出潜力。传统的完全监督方法依赖于密集的地基真值对应标签。近年来,研究人员将注意力转向自监督和弱监督学习,以减少对精确标注的依赖。像SuperPoint[61]这样的自监督学习方法在通过虚拟单应变换生成的成对图像上进行训练,产生了有希望的结果。然而,这些简单的几何变换在复杂的场景下可能无法有效地工作。弱监督学习已经成为局部特征学习领域的一个研究热点[111,112,172,131,133]。这些方法通常将弱监督学习与描述-检测管道相结合,但直接使用弱监督损失会导致明显的性能下降。一些方法仅依赖于涉及相对相机姿势的解决方案,通过epipo-lar损失来学习描述符。弱监督方法的局限性在于它们难以区分描述符和关键点引入的错误,也难以准确区分不同的描述符。为了克服这些挑战,出现了精心设计的去耦合训练管道,其中描述网络和检测网络分别进行训练,直到获得高质量的描述符。Chen等人[256]提出了使用卷积神经网络进行特征形状估计、方向分配和描述符的创新方法学习。他们的方法为每个特征建立了一个标准的形状和方向,通过消除对已知特征匹配关系的需求,实现了从监督学习到自监督学习的过渡。他们还在描述符学习中引入了一个“弱匹配查找器”,增强了特征的外观可变性,提高了描述符的不变性。这些进步标志着弱监督学习在特征匹配方面取得了重大进展,特别是在涉及大量视点和观看方向变化的情况下。
表3:对YFCC100M[226]进行户外姿态估计的评价。我们比较了两组方法,基于检测器的方法和无检测器的方法。
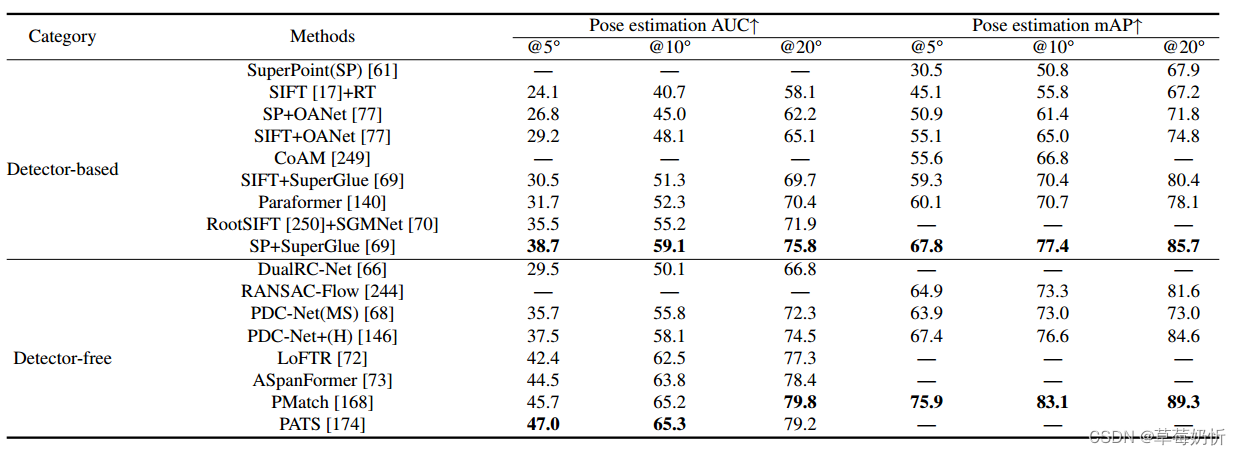
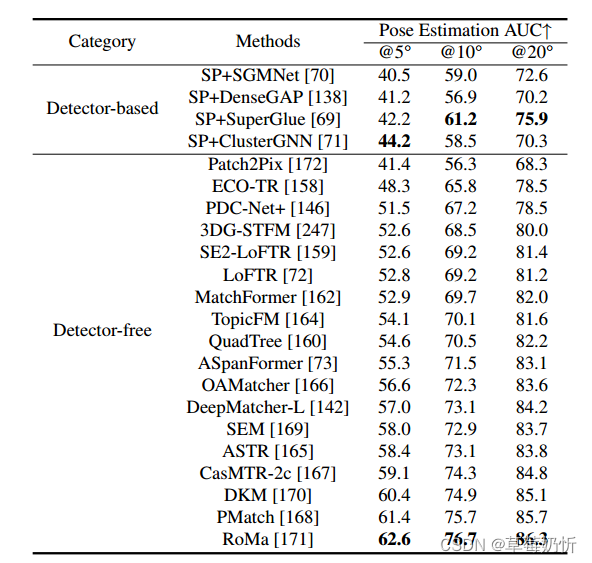
表4:MegaDepth[227]双视角相机姿态估计。我们比较了两组方法,基于检测器的方法和无检测器的方法。
这些弱监督方法为局部特征学习开辟了新的前景和机会,允许模型在更大、更多样化的数据集上进行训练,从而获得更广义的描述符。然而,这些方法仍然面临挑战,例如有效利用弱监督信号,解决描述子和关键点的不确定性。未来,弱监督学习在局部特征匹配领域的发展可能会集中在更精细的损失函数设计、更好地利用弱监督信号和更广泛的应用领域上。结合传统的完全监督方法探索弱监督学习的机制,有望在复杂场景中提高低局部特征匹配的性能和泛化能力。
7.4. 基础分割模型
通常,在cityscape[257]和MIT ADE20k[258]等数据集上训练的语义分割模型提供了基本的语义信息,并在增强特定环境的检测和描述过程中发挥了至关重要的作用[128,129]。
然而,SAM[259]、DINO[260]、DINOv2[261]等大型基础模型的出现,标志着人工智能进入了一个新时代。虽然传统的分割模型在其特定领域表现出色,但这些基础模型引入了更广泛、更通用的方法。它们在海量、多样的数据集上进行了广泛的预训练,使它们具备了非凡的零射击泛化能力,使它们能够适应广泛的场景。例如,SAM- feat[42]演示了SAM,一个擅长在“任何场景”中分割“任何东西”的模型,如何利用其丰富的、与类别无关的语义知识来指导局部特征学习。通过提炼细粒度的语义关系并专注于边缘检测,SAMFeat展示了在低局部特征描述和准确性方面的显著增强。类似地,SelaVPR[262]演示了如何使用轻量级适配器有效地调整DINOv2模型,通过熟练匹配局部特征来解决视觉位置识别(VPR)中的挑战,而无需进行广泛的空间验证,从而简化检索过程。
展望开放世界的场景,这些大型基础模型提供的多功能性和鲁棒泛化呈现出令人兴奋的前景。它们理解和解释大量场景和物体的能力远远超过了传统分割网络的范围,为跨越多样化和动态环境的特征匹配的进步铺平了道路。总之,虽然传统语义分割网络的贡献仍然是无价的,但大型基础模型的集成提供了一种互补和扩展的方法,对于推动特征匹配中可实现的界限至关重要,特别是在开放世界应用中。
表5:亚琛昼夜基准v1.0[230]和v1.1[9]的视觉定位评价。报告了在全视觉定位轨道上的评估结果。我们比较了两组方法,基于检测器的方法和无检测器的方法。
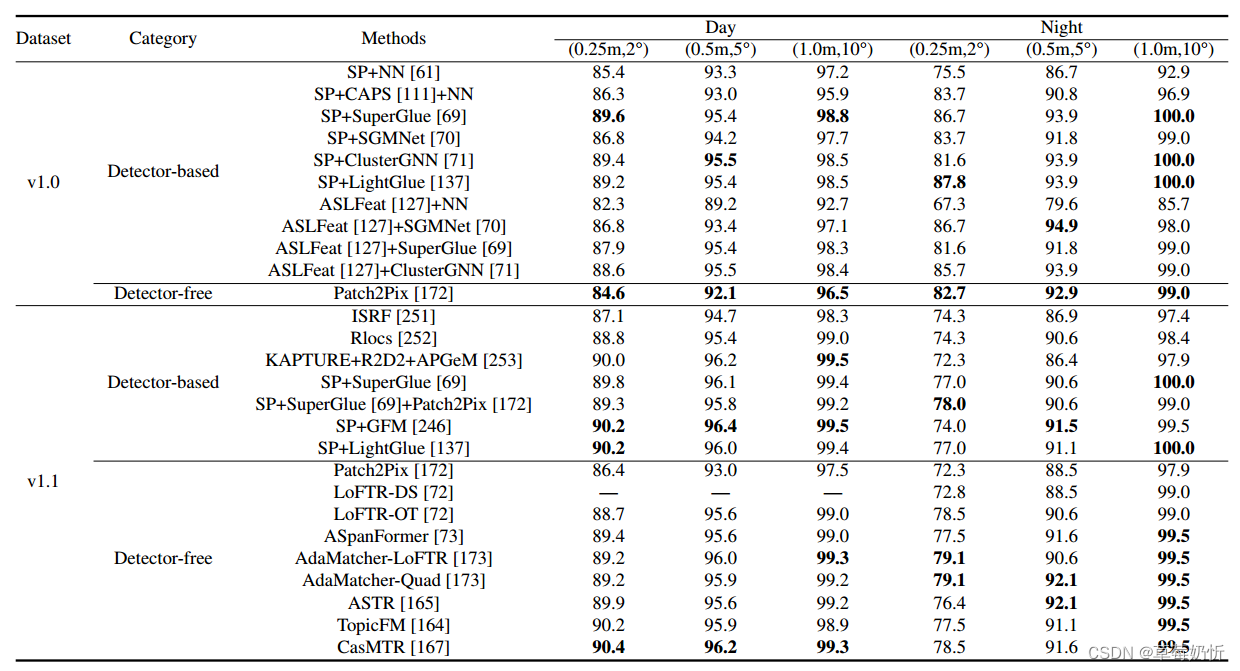
表6:亚琛昼夜基准v1.0[230]和v1.1[9]的视觉定位评价。报告了局部特征评价轨道上的评价结果。我们比较了两组方法,基于检测器的方法和无检测器的方法。
7.5. Mismatch Removal
图像匹配,涉及在描绘共享物体或场景的两幅图像之间建立可靠的连接,由于该过程的组合性质和异常值的存在,带来了复杂的挑战。直接匹配方法,如点集配准和图匹配,经常面临巨大的计算需求和不稳定的性能。因此,从利用SIFT、ORB和SURF[33,35,34]等特征描述符进行初步匹配构建开始,再应用局部和全局几何约束的分叉方法已成为一种流行的策略。然而,这些方法遇到了限制,特别是当面对多模态图像或视点和光照的实质性变化时[263]。
表7:InLoc基准上的视觉定位[116]。我们比较了两组方法,基于检测器的方法和无检测器的方法。
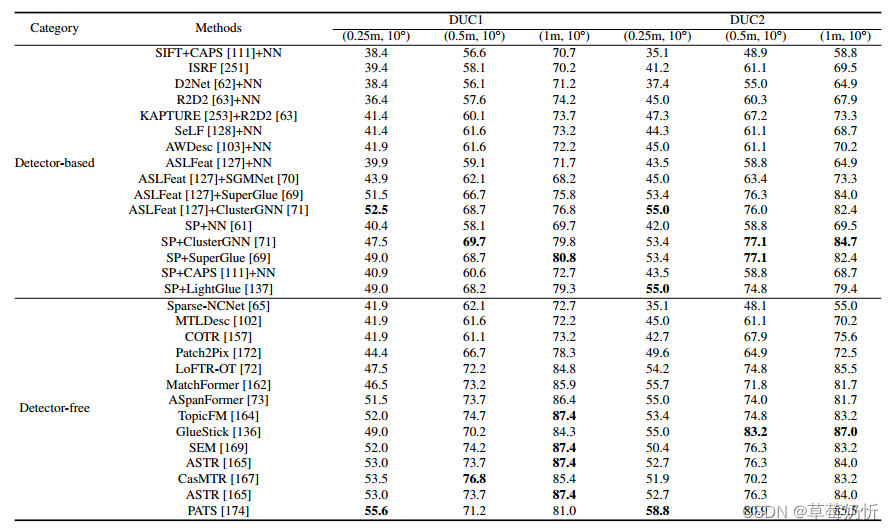
表8:KITTI训练分割的光流结果[233]。下面[157,158],(“+intp”)表示对模型的输出进行插值,得到每像素对应的关系。†表示用GLU-Net作者提供的Dense-Matching工具对其进行评估。这部分包含通用匹配网络。
正如马等人【264】所强调的那样,异常值剔除方法的发展对于克服错配消除的挑战至关重要。以ran sac【39】及其变体(如USAC【265】和mag sac ++【266】)为代表的传统方法显著提高了异常值剔除的效率和准确性。尽管如此,这些方法受限于计算时间约束及其对非刚性环境的适用性。针对非刚性场景的技术(如ICF【267】)在解决几何失真方面表现出了功效。错配消除中学习驱动策略的出现将深度学习集成到错配消除中为增强特征匹配开辟了新的途径。Yi等人【248】引入了上下文归一化(CNe),这是一个突破性的概念,通过有效区分内点和外点改变了宽基线立体对应。在此基础上,Sun等人【268】开发了attention Context Networks(ACNe),通过Attentive Context Normalization改进了置换等变数据的管理,从而在相机姿态估计和点云分类方面取得了重大进展。Zhang等人【77】提出了OANet,这是一种新的方法,可以精确确定两个视图的对应关系,并使用分层聚类方法支持几何估计。Zhao等人【269】介绍了NM-Net,这是一种分层网络,专注于通过特定兼容性挖掘选择特征对应关系,在各种设置中表现出出色的性能。shape-Former【270】创新地解决了多模态和多视图图像匹配的挑战,专注于通过混合神经网络实现鲁棒的错配消除。利用CNN和Transformers,Shape-Former为稀疏匹配学习引入了ShapeConv,在异常值估计和共识表示方面表现出色,同时展示了出色的性能。鉴于RANSAC是匹配管道中不可或缺的一部分,最近的创新大大增强了其与深度学习方法的集成,以提高性能。DSAC【271】通过使RANSAC可区分引入了一种范式转变,采用了一种概率选择机制来促进其集成到端到端可训练的深度学习管道中。这种创新方法不仅保持了传统RANSAC的鲁棒性,还利用深度学习直接将预期损失降至最低。另一方面,CA-RANSAC【272】通过一个新颖的注意力层引入了一种自适应共识机制,从而发展了ran sac框架。该机制基于累积残差动态细化每点估计状态,从而增强模型细化和样本选择。最近的发展,如lsva Net【273】、LGSC【263】和HCA-Net【185】,已经显示出更有效地识别离群值和内值的前景。这些方法利用深度学习模块进行几何估计和特征对应分类,标志着比传统方法的进步。
表9:ETH3D【239】上的SfM方法评估,用于多视图相机姿态估计和3D三角测量。该表将方法分为基于检测器和无检测器两类。结果来自检测器树FM【182】。
首先,必须开发更通用、更强大的基于学习的方法,能够处理各种场景,包括非刚性变换和多模态图像。其次,有必要采用融合传统几何方法和当代学习技术优点的方法。这种混合方法通过利用两种范例的优势,有可能提供卓越的性能。最后,探索创新的学习架构和为消除错配而定制的损失函数可以揭示特征匹配的新前景,提高计算机视觉系统的整体弹性和精度。总之,消除不匹配仍然是局部特征匹配的一个关键而强大的方面。传统方法和基于学习的方法的不断发展展现了解决现存限制和释放计算机视觉应用新潜力的前景
7.6. 深度学习和手工类比
图像匹配领域正在见证深度学习和传统手工制作技术的独特融合。在最近的半密集、无探测器的方法中,采用了经典方法的基础元素,例如“SIFT”管道,这种融合是显而易见的。这一趋势的著名例子包括Bellavia等人[274]、HarrisZ+[275]和Slime[276]的混合管道(Hybrid Pipeline, HP),它们都展示了与最先进的深度方法相结合的竞争力。HP方法集成了手工制作和基于学习的方法,为摄影测量调查保持了关键的旋转不变性。它以新颖的关键点过滤覆盖(KFC)模块为特色,提高了整个管道的准确性。HarrisZ+代表了经典哈里斯角探测器的演变,优化了与现代图像匹配组件的协同作用。它产生了更多的判别性和准确放置的关键点,与当代深度学习模型的结果紧密一致。Slime采用了一种新颖的策略,用局部重叠平面对场景进行建模,将局部仿射近似原理与全局匹配约束相结合。这种混合方法与传统的图像匹配过程相呼应,挑战了深度学习方法的性能。同时,在图像匹配的最新进展中,重要的是要强调深度学习方法和传统手工制作检测器之间的关键区别:旋转等方差。尽管现代方法具有出色的匹配性能,但它们在处理平面内旋转方面往往存在不足——这是手工制作检测器固有的一个基本特征。这种疏忽揭示了旋转变换下的性能差距,强调了设计或训练深度学习模型以明确解决这一挑战的重要性。通过关注旋转等变方法的发展,如SE2-LoFTR[159]和S-TREK[98]所示,该领域更接近于弥补这一差距,将深度学习的精度与手工制作的检测器对方向变化的鲁棒性相结合。
这些进步表明,尽管LoFTR和SuperGlue等深度学习方法取得了重大进展,但手工制作技术的基本原则仍然至关重要。经典概念与现代计算能力的集成,如在HP、HarrisZ+、Slime、SE2LoFTR和S-TREK中所见,带来了强大的图像匹配解决方案。这些方法为未来的研究提供了潜在的途径,融合了不同的方法,弥合了图像匹配中传统和现代方法之间的差距。
7.7. 利用几何信息
当面对无纹理、遮挡和重复图案等挑战时,传统的局部特征匹配方法可能表现不佳。近年来,研究人员开始关注在这些挑战面前,如何更好地利用几何信息来增强局部特征匹配的有效性。一些研究[169,170,146,168]表明,利用几何信息在局部特征匹配中具有巨大的潜力。通过更准确地捕获像素之间的几何关系,并将几何先验与图像外观信息相结合,这些方法可以增强复杂场景中匹配的鲁棒性和准确性。然而,这一方向为未来的发展带来了无数的机遇和挑战。首先,如何更深刻地建模几何信息,以更好地解决涉及大位移、闭塞和无纹理区域的场景仍然是一个关键问题。其次,提高置信度估计的性能以产生更可靠的匹配结果也是一个值得研究的方向。
几何先验的引入将特征匹配从单纯的外观相似性扩展到从不同的角度考虑对象的行为。这一趋势表明,密集匹配方法有望解决大位移和外观变化带来的挑战。这也意味着几何匹配领域的未来发展可能会越来越多地关注密集特征匹配,利用几何信息和先验知识边缘来增强匹配性能。
7.8. 推进文化遗产保护
将深度学习融入历史图像匹配领域,预示着文化遗产保护进入了一个新时代,提供了无与伦比的机遇,同时也带来了独特的挑战。来自最近研究的见解强调了先进深度学习方法克服传统技术局限性的潜力[277]。这些方法对困扰历史和当代图像匹配的固有的反射率和几何差异表现出了显著的弹性,从而促进了多时间场景的准确共同配准。SuperGlue[69]、LoFTR[72]和DISK[112]等技术被认为是特别有效的,通过对强烈照明和视点转换实现更高的鲁棒性,超越了经典方法。这一进步能够更准确地重建历史遗址和文物[278],从而通过虚拟和增强现实等沉浸式技术加强知识转移和文化遗产推广。
然而,在这一领域充分利用深度学习能力的旅程并非没有障碍。在管理广泛的图像旋转和尺度变化方面仍然存在挑战,这在历史数据集[55]中很常见。此外,处理高分辨率图像所需的计算强度提出了一个重大障碍,特别是针对web和VR/AR平台中的实时应用[279]。这些技术挑战强调了持续研究和开发的必要性,以改进深度学习算法并针对文化遗产应用的特定需求对其进行优化。
此外,深度学习的动态性为不断提高历史图像匹配过程的准确性和效率提供了机会。随着算法的发展和新方法的出现,有可能出现更复杂的特征检测、提取和匹配方法,从而进一步彻底改变该领域。对这些新策略的探索,以及对当前方法进行调整以适应历史图像的独特特征,对于提高我们数字化保存和探索文化遗产的能力至关重要。总之,深度学习与历史图像匹配的融合为弥合过去与现在之间的差距提供了一条有希望的途径。未来的研究可以为文化遗产的保存、理解和传播开启新的可能性,使其更容易被子孙后代所接受和参与。
8. 结论
在过去的五年里,我们研究了基于深度学习模型的各种与局部特征匹配相关的算法。这些算法在各种局部特征匹配任务和基准测试中表现出了令人印象深刻的性能。它们可以大致分为基于检测器的模型和无检测器模型。特征检测器的应用减小了匹配的范围,依赖于关键点检测和特征描述的过程。另一方面,无检测器方法直接从原始图像中捕获更丰富的上下文以生成密集匹配。随后,我们讨论了现有局部特征匹配算法的优缺点,介绍了流行的数据集和评估标准,并总结了这些模型在HPatches、ScanNet、YFCC100M、MegaDepth和Aachen Day-Night数据集等一些常见基准上的定量性能分析。最后,我们探讨了局部特征匹配领域在未来几年可能遇到的开放挑战和潜在的研究途径。我们的目标不仅是提高研究人员对局部特征匹配的理解,而且还可以启发和指导该领域未来的研究工作。