总体概述
数据概述:
金融和经济信息的情绪分析与企业高度相关,原因有几个,从市场洞察(对市场趋势、投资者信心和消费者行为获得有价值的见解)到风险管理(识别潜在的声誉风险)再到投资决策(衡量利益相关者、投资者和公众企业的情绪可以评估各种投资机会的潜在成功)。
FinancialPhraseBank数据集是一个全面的集合,从散户投资者的角度捕捉金融新闻标题的情绪。该数据集由两个关键列组成,即“情绪”和“新闻头条”,有效地将情绪分为负面、中性或正面。这个结构化数据集是分析和理解金融新闻领域复杂情绪动态的宝贵资源。自Malo,P.、Sinha,A.、Korhonen,P.、Wallenius,J.和Takala,P.于2014年发表在《信息科学与技术协会杂志》上的“好债务还是坏债务:检测经济文本中的语义取向”的工作中成立以来,它已被用于各种研究和研究举措。
技术概述:
分布式架构Accelerate
Accelerate 是 Hugging Face 提供的一个库,它的主要目的是简化在多种硬件配置上进行深度学习模型训练的过程。以下是关于 Accelerate 的一些关键点:
简化分布式训练:Accelerate 允许研究人员和开发人员在不同的硬件配置上(包括 CPU、单个 GPU、多 GPU、TPU
以及多节点设置)进行模型训练,而无需对原始代码进行大量修改。自动化混合精度训练:它支持自动混合精度(AMP)训练,这有助于提高训练效率和减少内存使用。
梯度累积支持:Accelerate 支持梯度累积技术,允许模型在内存受限的情况下使用更大的批次大小进行训练。
易用性:它提供了一个简单的 API,使得在 PyTorch 代码中实现多 GPU/TPU 训练变得容易,同时保持了原始 PyTorch
代码的可读性和简洁性。集成实验跟踪器:Accelerate 可以与实验跟踪器(如 Weights &
Biases)集成,使得在分布式训练中的实验跟踪和管理变得更加方便。日志记录和调试支持:它增强了分布式系统中的日志记录和跟踪,提供了方便的方法来在分布式设置中保存训练状态。
开源:Accelerate 是一个开源项目,可以在 GitHub 上找到其源代码和相关文档。链接
社区支持:作为一个流行的开源工具,Accelerate 拥有活跃的社区支持,用户可以通过社区获得帮助和分享经验。
适用于多种框架:虽然主要是与 PyTorch 配合使用,但 Accelerate 也支持 TensorFlow 等其他深度学习框架。
PTFT 参数高效微调
Hugging Face的PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是一个开源的模型调优工具包,它旨在高效地将预训练语言模型(PLM)适应到各种下游应用,而无需微调所有模型的参数。PEFT通过仅微调模型中的一小部分参数,显著降低了计算和存储成本,这对于大型PLM来说尤其重要,因为完整微调的代价可能非常高。
PEFT的主要特点包括:
- 高效性:PEFT方法仅需要对模型的一小部分参数进行微调,这样可以大大减少所需的计算资源和时间。
- 灵活性:PEFT支持多种主流模型架构,如BERT、RoBERTa、GPT等,并且可以与Hugging Face的Model Hub无缝集成,方便用户快速获取和使用预训练模型。
- 丰富的插件和扩展功能:除了基本的模型调优功能外,PEFT还提供了丰富的插件和扩展功能,包括自定义损失函数、自定义评估指标、自定义数据加载器等。
- 与Transformers库的兼容性:PEFT基于Hugging
Face的Transformers库,这意味着它可以利用Transformers库中的所有功能和模型。 - 支持多种微调方法:PEFT支持多种参数高效微调方法,如LoRA(Low-Rank
Adaptation),这些方法通过引入低秩矩阵来调整模型的权重,而不需要对整个模型进行微调。
代码实现
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["CUDA_VISIBLE_DEVICES"] = "0":此代码用于设置CUDA可见设备,将其设置为0表示使用第一个GPU设备进行计算。如果没有设置该环境变量,则通常会使用所有可用的GPU设备。os.environ["TOKENIZERS_PARALLELISM"] = "false":这行代码用于禁用tokenizers库的并行运算功能。该库是用于进行自然语言处理中词汇和文本处理的工具,通过禁用并行运算可以避免在某些情况下可能出现的性能问题或异常。
import warnings
warnings.filterwarnings("ignore")
代码导入警告;warnings.filterwarnings(“忽略”)导入警告模块并将警告筛选器设置为忽略。这意味着所有警告都将被抑制而不会显示。事实上,在训练过程中,有很多警告并不能阻止微调,但可能会分散注意力,让你怀疑自己是否做了正确的事情。
加载依赖
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
#trl库是一个全栈工具,用于使用监督微调步骤(SFT)、奖励建模(RM)和近端策略优化(PPO)以及直接偏好优化(DPO)等方法对转换器语言和扩散模型进行微调和对齐。
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_split
#设置使用CPU or GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"working on {device}")
拆分数据集
#文件地址
filename = "./sentiment-analysis-for-financial-news/all-data.csv"
#读取csv文档 并设置"sentiment", "text" 两列
#sentiment是具体的结果
df = pd.read_csv(filename,
names=["sentiment", "text"],
encoding="utf-8", encoding_errors="replace")
#创建训练集和测试集
X_train = list()
X_test = list()
#从观点中选取【"积极", "中立", "消极" 】 这三个种类便于对后续训练优化
for sentiment in ["positive", "neutral", "negative"]:
train, test = train_test_split(df[df.sentiment==sentiment],
train_size=300,#训练300个
test_size=300, #测试300个
random_state=42)
X_train.append(train)
X_test.append(test)
#`pd.concat(X_train)` 将训练集 X_train 合并为一个数据框(DataFrame),然后 `.sample(frac=1, random_state=10)` 是在这个数据框上执行随机抽样。
#`frac=1` 表示抽取整个数据框中的样本,`random_state=10` 是一个随机种子,用于确保每次运行代码时抽取的样本都是一样的。
X_train = pd.concat(X_train).sample(frac=1, random_state=10)
X_test = pd.concat(X_test)
#找出数据框(DataFrame)df 中不在训练集(X_train)和测试集(X_test)中的索引(index)
eval_idx = [idx for idx in df.index if idx not in list(X_train.index) + list(X_test.index)]
#抽取验证数据集
X_eval = df[df.index.isin(eval_idx)]
#对验证数据集 `X_eval` 进行分组,并对每个情感类别('sentiment')进行随机抽样。
X_eval = (X_eval
.groupby('sentiment', group_keys=False)#将 `X_eval` 数据集按照 'sentiment' 列进行分组。`group_keys=False` 参数意味着不需要保留分组键作为行标签,而是直接对分组后的数据集进行操作
.apply(lambda x: x.sample(n=50, random_state=10, replace=True)))#对每个分组后的数据集应用一个lambda函数,该函数使用 `sample` 方法从每个分组中随机抽取50个样本。`random_state=10` 参数确保了抽样的可重复性,而 `replace=True` 参数允许抽样时重复选择同一个样本。
#丢弃旧的索引
X_train = X_train.reset_index(drop=True)
#分析方括号内新闻标题的情绪,
#确定是肯定的、中性的还是否定的,并将答案返回为
#相应的情绪标签为“积极”或“中性”或“消极”。 【"positive" or "neutral" or "negative"】
#下面内容的意思表述 作用类似添加一个prompt
def generate_prompt(data_point):
return f"""
Analyze the sentiment of the news headline enclosed in square brackets,
determine if it is positive, neutral, or negative, and return the answer as
the corresponding sentiment label "positive" or "neutral" or "negative".
[{data_point["text"]}] = {data_point["sentiment"]}
""".strip()
def generate_test_prompt(data_point):
return f"""
Analyze the sentiment of the news headline enclosed in square brackets,
determine if it is positive, neutral, or negative, and return the answer as
the corresponding sentiment label "positive" or "neutral" or "negative".
[{data_point["text"]}] = """.strip()
# `X_train` 中的每一行应用 `generate_prompt` 函数,并将函数的返回结果整理成一个新的数据框,并命名为 "text" 的列
#这里实际类似添加一个prompt
X_train = pd.DataFrame(X_train.apply(generate_prompt, axis=1),
columns=["text"])
X_eval = pd.DataFrame(X_eval.apply(generate_prompt, axis=1),
columns=["text"])
#同上
y_true = X_test.sentiment
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])
train_data = Dataset.from_pandas(X_train)
eval_data = Dataset.from_pandas(X_eval)
查看数据集情况
print(train_data)
print(eval_data)
返回
Dataset({
features: [‘text’],
num_rows: 900
})
Dataset({
features: [‘text’, ‘__index_level_0’],
num_rows: 150 })
模型评估
接下来,创建一个函数来评估微调情绪模型的结果。该功能执行以下步骤:
将情绪标签映射到数字表示,其中2表示积极,1表示中性,0表示消极。
- 根据测试数据计算模型的准确性。
- 为每个情绪标签生成准确性报告。
- 为模型生成分类报告。
- 为模型生成混淆矩阵。
def evaluate(y_true, y_pred):
#标签转换
labels = ['positive', 'neutral', 'negative']
mapping = {'positive': 2, 'neutral': 1, 'none':1, 'negative': 0}
def map_func(x):
return mapping.get(x, 1)
#`np.vectorize` 函数的作用是将一个接受标量输入并返回标量输出的普通 Python 函数转换为一个可以对 NumPy 数组
y_true = np.vectorize(map_func)(y_true)
y_pred = np.vectorize(map_func)(y_pred)
# 计算 accuracy
accuracy = accuracy_score(y_true=y_true, y_pred=y_pred)
print(f'Accuracy: {accuracy:.3f}')
# 生成准确性报告
unique_labels = set(y_true) # 获取唯一标签
for label in unique_labels:
label_indices = [i for i in range(len(y_true))
if y_true[i] == label]
label_y_true = [y_true[i] for i in label_indices]
label_y_pred = [y_pred[i] for i in label_indices]
accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {label}: {accuracy:.3f}')
# 生成分类报告
class_report = classification_report(y_true=y_true, y_pred=y_pred)
print('\n分类报告:')
print(class_report)
# 生成混淆矩阵
conf_matrix = confusion_matrix(y_true=y_true, y_pred=y_pred, labels=[0, 1, 2])
print('\n混淆矩阵:')
print(conf_matrix)
模型加载
代码从Hugging Face Hub加载Llama-2语言模型。
代码从torch库中获取float16数据类型。这是将用于计算的数据类型。
创建一个具有以下设置的BitsAndBytesConfig对象:
load_in_4bit:以4位格式加载模型权重。
bnb_4bit_quant_type:使用“nf4”量化类型。4位NormalFloat(NF4)是一种理论上对于正态分布权重最优的信息的新数据类型。
bnb_4bit_compute_dtype:使用float16数据类型进行计算。bnb_4bit_use_double_quant:不使用双重量化(通过量化量化常数来减少平均内存占用,并为每个参数额外节省0.4位)。
使用BitsAndBytesConfig对象进行量化,从预先训练的Llama-2语言模型创建AutoModelForCausalLM对象。
代码将预训练令牌概率设置为1。
加载token
- 代码加载Llama-2语言模型的标记器。
- 填充令牌设置为序列结束(EOS)令牌。
- 代码将填充侧设置为“右”,这意味着输入序列将在右侧进行填充。这对于正确的填充方向至关重要(Llama 2就是这样)。
#加载本地模型
model_name = r"G:\hugging_fase_model\Llama-2-7b-chat-hf"
#getattr() 是 Python 内置的一个函数,可以用来获取一个对象的属性值或方法
compute_dtype = getattr(torch, "float16")
#加载量化器
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
#加载模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map=device,
torch_dtype=compute_dtype,
quantization_config=bnb_config,
)
#控制模型是否使用缓存的一个配置选项。当设置为`False`时,表示禁用模型的缓存机制
model.config.use_cache = False
#预训练令牌概率设置为1
model.config.pretraining_tp = 1
#加载tokener
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True,
)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
##将聊天模板设置为OAI聊天ML
model, tokenizer = setup_chat_format(model, tokenizer)
测试 在没有inetruing 的情况下对模型的预测效果
包含要预测的新闻标题的Pandas DataFrame。model:预先训练的Llama-2语言模型。标记化器:Llama-2语言模型的标记化器。
该功能的工作原理如下:
对于测试DataFrame中的每个新闻标题:
为语言模型创建一个提示,要求它分析新闻标题的情绪并返回相应的情绪标签。
使用Hugging Face Transformers库中的pipeline()函数,使用提示从语言模型中生成文本。
从生成的文本中提取预测的情绪标签。
将预测的情绪标签附加到y_pred列表中。
返回y_pred列表
Hugging Face Transformers库中的pipeline()函数用于从语言模型中生成文本。
task参数指定任务是文本生成。模型和标记器参数指定预先训练的Llama-2语言模型和语言模型的标记器。
max_new_tokens参数指定要生成的新令牌的最大数量。温度参数控制生成的文本的随机性。
较低的温度将产生更可预测的文本,而较高的温度将生成更具创造性和意想不到的文本。
def predict(test, model, tokenizer):
y_pred = []
for i in tqdm(range(len(X_test))):
prompt = X_test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens = 1,
temperature = 0.0,
do_sample=False,
)
result = pipe(prompt)
answer = result[0]['generated_text'].split("=")[-1]
if "positive" in answer:
y_pred.append("positive")
elif "negative" in answer:
y_pred.append("negative")
elif "neutral" in answer:
y_pred.append("neutral")
else:
y_pred.append("none")
return y_pred
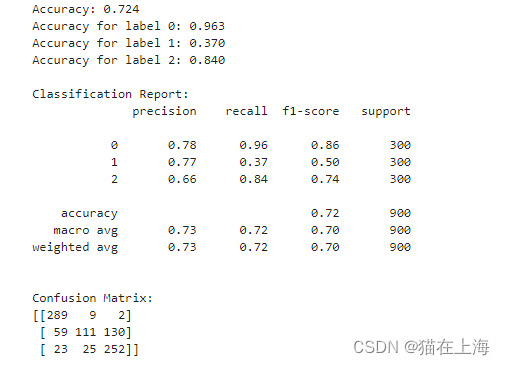
evaluate(y_true, y_pred)
返回:
Fine-tuning
我们为微调做好了一切准备。配置并初始化了一个简单微调训练器(SFTTrainer),用于使用参数高效微调(PEFT)方法训练大型语言模型,与模型的总体尺寸相比,该方法在减少参数数量的情况下运行,因此应能节省时间。PEFT方法侧重于细化一组有限的(额外的)模型参数,同时保持大多数预先训练的LLM参数不变。这大大减少了计算和存储开销。此外,这一策略还解决了灾难性遗忘的挑战,这通常发生在LLM的完全微调过程中。
使用的详细依赖说明:
PEFT 配置:
- peft_config对象指定peft的参数。以下是一些最重要的参数:
- lora_lfa:lora更新矩阵的学习率。
- lora_dropout:lora更新矩阵的丢失概率。
- r: LoRA更新矩阵的秩。
- bias:要使用的偏倚类型。可能的值是none、additive和learned。
- task_type:正在为其训练模型的任务类型。可能的值为CAUSAL_LM和MASKED_LM。
TrainingArguments
training_arguments对象指定用于训练模型的参数。以下是一些最重要的参数:
- output_dir:保存训练日志和检查点的目录。
- num_train_epochs:为其训练模型的历元数。
- per_device_train_batch_size:每个设备上每个批次的样本数。
- gradient_accumulation_steps:在更新模型参数之前累积梯度的批次数。
- optim:用于训练模型的优化器。
- save_steps:保存检查点的步骤数。
- logging_steps:记录训练指标的步骤数。
- learning_rate:优化器的学习率。
- weight_decay:优化器的权重衰减参数。
- fp16:是否使用16位浮点精度。
- bf16:是否使用BFloat16精度。
- max_grad_norm:最大梯度范数。
- max_steps:训练模型的最大步骤数。
- warmup_ratio:用于预热学习率的训练步骤的比例。
- group_by_length:是否按长度对训练样本进行分组。
- lr_scheduler_type:要使用的学习率调度程序的类型。
- report_to:用于向其报告培训指标的工具。
- evaluation_strategy:在训练过程中对模型进行评估的策略。
Trainer和SFTTrainer不同:
Trainer
通用培训:专为在监督学习任务(如文本分类、问答和摘要)上从头开始培训模型而设计。
高度可定制:提供广泛的配置选项,用于微调超参数、优化器、调度器、日志记录和评估指标。
处理复杂的训练工作流程:支持梯度积累、早期停止、检查点和分布式训练等功能。
需要更多的数据:通常需要更大的数据集才能从头开始进行有效的训练。
SFTTrainer:
监督微调(SFT):优化用于在监督学习任务中用较小的数据集微调预训练模型。
界面更简单:提供精简的工作流程,配置选项更少,更容易上手。
高效内存使用:使用参数高效(PEFT)和封装优化等技术来减少训练期间的内存消耗。
更快的训练:与Trainer相比,使用更小的数据集和更短的训练时间,可以实现相当或更好的准确性。
SFTTrainer 参数
- model:要训练的模型。
- train_dataset:训练数据集。
- eval_dataset:评估数据集。
- peft_config:peft配置。
- dataset_text_field:数据集中文本字段的名称。
- tokenizer:要使用的tokenizer。
- args:训练参数。
- packing:是否包装培训样品。
- max_seq_length:最大序列长度。
#训练过程以及模型的保存路径
output_dir="../output_finetruning_v2"
#加载lora 的参数
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
#target_modules="all-linear",
task_type="CAUSAL_LM",
#inplace=Fals
)
training_arguments = TrainingArguments(
output_dir=output_dir, # 模型保存地址
num_train_epochs=3, # 训练论数
per_device_train_batch_size=1, # 每个设备的批量大小
gradient_accumulation_steps=8, # 执行向后/更新过程之前的步骤数
gradient_checkpointing=True, # 使用渐变检查点保存内存
optim="paged_adamw_32bit",
save_steps=0,
logging_steps=25, # 每10步记录一次
learning_rate=2e-4, # 学习率,基于QLoRA
weight_decay=0.001,
fp16=True,
bf16=False,
max_grad_norm=0.3, # 基于QLoRA的最大梯度范数
max_steps=-1,
warmup_ratio=0.03, # 基于QLoRA的预热率
group_by_length=True,
lr_scheduler_type="cosine", # 使用余弦学习速率调度器
report_to="tensorboard", # 向tensorboard报告指标
evaluation_strategy="epoch" # 保存每个检查点
)
#加载SFTT 训练器
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=1024,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)
# 模型训练
trainer.train()
返回大概会训练1小时
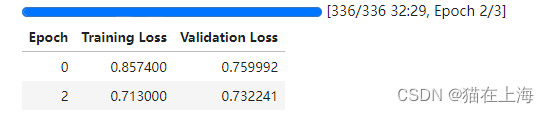
#模型保存
trainer.save_model()
#保存token
tokenizer.save_pretrained(output_dir)
可以看到具体的保存内容
(‘…/output_finetruning_v2\tokenizer_config.json’,
‘…/output_finetruning_v2\special_tokens_map.json’,
‘…/output_finetruning_v2\tokenizer.model’,
‘…/output_finetruning_v2\added_tokens.json’,
‘…/output_finetruning_v2\tokenizer.json’)
清除数据后从新预测
import gc
del [model, tokenizer, peft_config, trainer, train_data, eval_data, bnb_config, training_arguments]
del [df, X_train, X_eval]
del [TrainingArguments, SFTTrainer, LoraConfig, BitsAndBytesConfig]
for _ in range(100):
torch.cuda.empty_cache()
gc.collect()
from peft import AutoPeftModelForCausalLM
#路径是输出的模型路径
finetuned_model = "../output_finetruning_v2/"
compute_dtype = getattr(torch, "float16")
tokenizer = AutoTokenizer.from_pretrained(r"G:\hugging_fase_model\Llama-2-7b-chat-hf")
model = AutoPeftModelForCausalLM.from_pretrained(
finetuned_model,
torch_dtype=compute_dtype,
return_dict=False,
low_cpu_mem_usage=True,
device_map=device,
)
merged_model = model.merge_and_unload()
模型的合并保存
这里保存好后可以最直接作为最后的使用
merged_model.save_pretrained("../merged_model",safe_serialization=True, max_shard_size="2GB")
tokenizer.save_pretrained("../merged_model")
查看预测结果
y_pred = predict(test, merged_model, tokenizer)
evaluate(y_true, y_pred)
结果返回
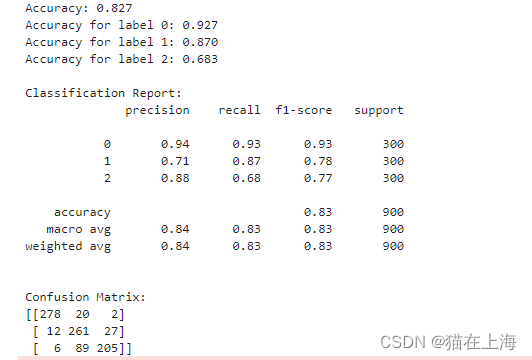
从这里看整个结果在F1分数上有明显提升
数据保存
evaluation = pd.DataFrame({'text': X_test["text"],
'y_true':y_true,
'y_pred': y_pred},
)
evaluation.to_csv("test_predictions.csv", index=False)
以上是本次案例的全部内容,感谢阅读。