示例文档内容:
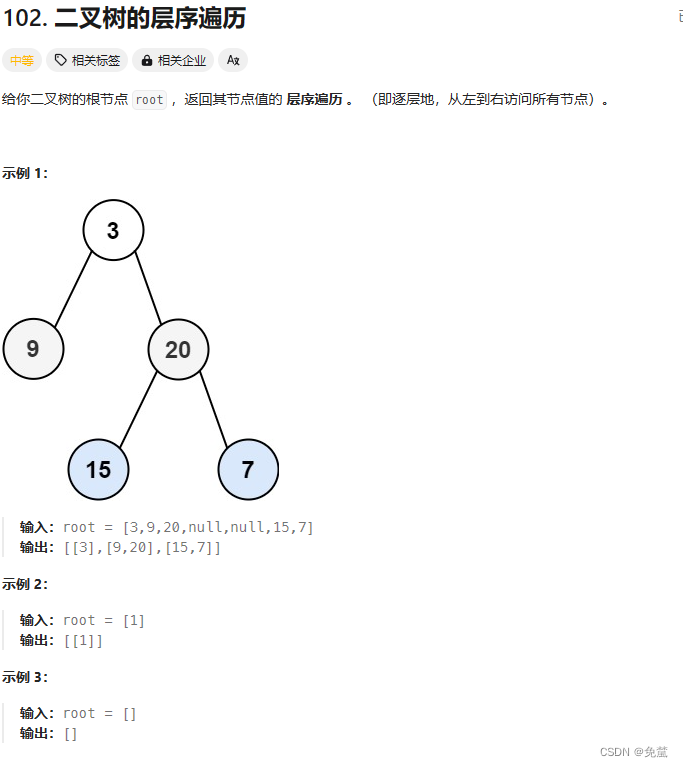
图片简介:第一张图
图片显示区域
图片简介:第二张图
图片显示区域
文档文件夹:
f:/doc/示例.docx
导出的文件夹:
f:/doc/png/示例/示例.docx
f:/doc/png/示例/示例.txt
f:/doc/png/示例/示例_000001_第一张图.png
f:/doc/png/示例/示例_000002_第二张图.png
示例.txt
第一张图
第二张图
相关问题:
如果指定关键字后是空的,这里用XXX代替,导出后可以查看TXT和Word文档对应的那行是不是格式有问题,TXT导出的每行和图片都是对应的,目前只支持示例文档这样的格式。
from docx import Document
import os
import re
import shutil
# pip install python-docx
# pip install lxml # 通常不必需,除非在安装 python-docx 后出现问题
def get_picture(document, paragraph):
"""
从段落中获取图片
"""
img = paragraph._element.xpath('.//pic:pic')
if not img:
return None
img = img[0]
embed = img.xpath('.//a:blip/@r:embed')[0]
related_part = document.part.related_parts[embed]
image = related_part.image
return image
def extract_content(docx_path, output_dir):
try:
doc = Document(docx_path)
base_filename = os.path.splitext(os.path.basename(docx_path))[0]
doc_output_dir = os.path.join(output_dir, base_filename)
os.makedirs(doc_output_dir, exist_ok=True)
shutil.copy(docx_path, doc_output_dir)
extracted_text = []
extracted_images = []
for para in doc.paragraphs:
match = re.search(r'图片简介:(.*)', para.text)
if match:
violation_text = match.group(1).strip() if match.group(1).strip() else "XXX"
extracted_text.append(violation_text)
image = get_picture(doc, para)
if image:
blob = image.blob
image_index = len(extracted_images) + 1
formatted_index = f"{image_index:06d}"
img_path = os.path.join(doc_output_dir, f"{base_filename}_{formatted_index}.png")
extracted_images.append(img_path)
with open(img_path, "wb") as f:
f.write(blob)
if extracted_text:
text_filename = f"{base_filename}.txt"
text_path = os.path.join(doc_output_dir, text_filename)
with open(text_path, 'w', encoding='utf-8') as text_file:
text_file.write('\n'.join(extracted_text))
rename_images_based_on_text(doc_output_dir, text_path, extracted_images)
except Exception as e:
print(f"Error processing {docx_path}: {e}")
def rename_images_based_on_text(output_dir, text_file_path, extracted_images):
with open(text_file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
if len(extracted_images) != len(lines):
print(f"Error: The number of images ({len(extracted_images)}) and text lines ({len(lines)}) do not match in {output_dir}.")
return
for image_path, line in zip(extracted_images, lines):
new_image_name = f"{os.path.splitext(image_path)[0]}_{line.strip()}{os.path.splitext(image_path)[1]}"
os.rename(image_path, new_image_name)
print(f"Renamed '{image_path}' to '{new_image_name}'")
def process_documents(folder_path, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for filename in os.listdir(folder_path):
if filename.endswith(".docx") or filename.endswith(".doc"):
docx_path = os.path.join(folder_path, filename)
extract_content(docx_path, output_folder)
# 示例用法
folder_path = "f:/doc"
output_folder = "f:/doc/png"
process_documents(folder_path, output_folder)