本文介绍相关运算及实现。
相关运算在相关检测及数字锁相放大中经常用到,其与卷积运算又有一定的联系,本文简要介绍其基本运算及与卷积运算的联系,并给出实现。
1.定义
这里以长度为N的离散时间序列x(n),y(n)为例,相关运算定义如下:
1)
x(n)保持不动,y(n)相对于x(n)向左移动
最后面的式子是等效情况下,y(n)不动,x(n)相对于y(n)向右移动
2)
y(n)保持不动,x(n)相对于y(n)向左移动
最后面的式子是等效情况下,x(n)不动,y(n)相对于x(n)向右移动
注意:
1),
的定义是不一样的,
2)n的取值范围为[-(N-1),N-1]
3)相关运算结果长度为2*N-1(2个序列长度和减1)
对比卷积公式:
注意:
1)n的取值范围为[0,2*N-2]
2)卷积运算结果长度为2*N-1(2个序列长度和减1)
3)后面2个等式成立使用的是卷积交换律
对比卷积公式和相关运算公式,可以知道,无论是还是
,它们与卷积运算差别仅在运算时x(n)或y(n)是否需要折叠(转换成x(-n)或y(-n))。因此,在做相关运算时可以将输入x(n)或y(n)先折叠,再经过卷积运算即可求出相关运算结果。
这里用Matlab作下验证,在Matlab命令行下输入:
x=[1,2,3];
y=[3,2,1];
z1=xcorr(x,y);
z2=conv(x, flip(y));其中flip(y)即对y进行折叠(反转序列),得到的结果是z1和z2是相等的。
2.实现
这里基于C语言来实现。参考代码如下:
static void correlate(float *pSrcA, uint32_t srcALen, float *pSrcB, uint32_t srcBLen, float *pDst);
static void correlate(float *pSrcA, uint32_t srcALen, float *pSrcB, uint32_t srcBLen, float *pDst)
{
float *pIn1 = pSrcA; /* inputA pointer */
float *pIn2 = pSrcB + (srcBLen - 1U); /* inputB pointer */
float sum = 0; /* Accumulator */
uint32_t i = 0U; /* loop counter */
uint32_t j = 0U; /* loop counter */
uint32_t inv = 0U; /* Reverse order flag */
uint32_t tot = 0U; /* Length */
if ((pSrcA == NULL) || (srcALen == 0) || (pSrcB == NULL) || (srcBLen == 0) || (pDst == NULL))
{
return ;
}
/* The algorithm implementation is based on the lengths of the inputs. */
/* srcB is always made to slide across srcA. */
/* So srcBLen is always considered as shorter or equal to srcALen */
/* But CORR(x, y) is reverse of CORR(y, x) */
/* So, when srcBLen > srcALen, output pointer is made to point to the end of the output buffer */
/* and a varaible, inv is set to 1 */
/* If lengths are not equal then zero pad has to be done to make the two
* inputs of same length. But to improve the performance, we assume zeroes
* in the output instead of zero padding either of the the inputs*/
/* If srcALen > srcBLen, (srcALen - srcBLen) zeroes has to included in the
* starting of the output buffer */
/* If srcALen < srcBLen, (srcALen - srcBLen) zeroes has to included in the
* ending of the output buffer */
/* Once the zero padding is done the remaining of the output is calcualted
* using convolution but with the shorter signal time shifted. */
/* Calculate the length of the remaining sequence */
tot = ((srcALen + srcBLen) - 2U);
if (srcALen > srcBLen)
{
/* Calculating the number of zeros to be padded to the output */
j = srcALen - srcBLen;
/* Initialise the pointer after zero padding */
pDst += j;
}
else if (srcALen < srcBLen)
{
/* Initialization to inputB pointer */
pIn1 = pSrcB;
/* Initialization to the end of inputA pointer */
pIn2 = pSrcA + (srcALen - 1U);
/* Initialisation of the pointer after zero padding */
pDst = pDst + tot;
/* Swapping the lengths */
j = srcALen;
srcALen = srcBLen;
srcBLen = j;
/* Setting the reverse flag */
inv = 1;
}
/* Loop to calculate convolution for output length number of times */
for (i = 0U; i <= tot; i++)
{
/* Initialize sum with zero to carry on MAC operations */
sum = 0.0f;
/* Loop to perform MAC operations according to convolution equation */
for (j = 0U; j <= i; j++)
{
/* Check the array limitations */
if ((((i - j) < srcBLen) && (j < srcALen)))
{
/* z[i] += x[i-j] * y[j] */
sum += pIn1[j] * pIn2[-((int32_t)i - (int32_t)j)];
}
}
/* Store the output in the destination buffer */
if (inv == 1)
{
*pDst-- = sum;
}
else
{
*pDst++ = sum;
}
}
}
main函数:
int main()
{
float x[] = {1, 2, 3, 4};
float y[] = {4, 3, 2, 1};
float z[7] = {0};
uint32_t i = 0;
correlate(x, 4, y, 4, z);
for (i = 0; i < sizeof(z) / sizeof(z[0]); i++)
{
printf("%f ", z[i]);
}
printf("\r\n");
return 0;
}
输出结果:
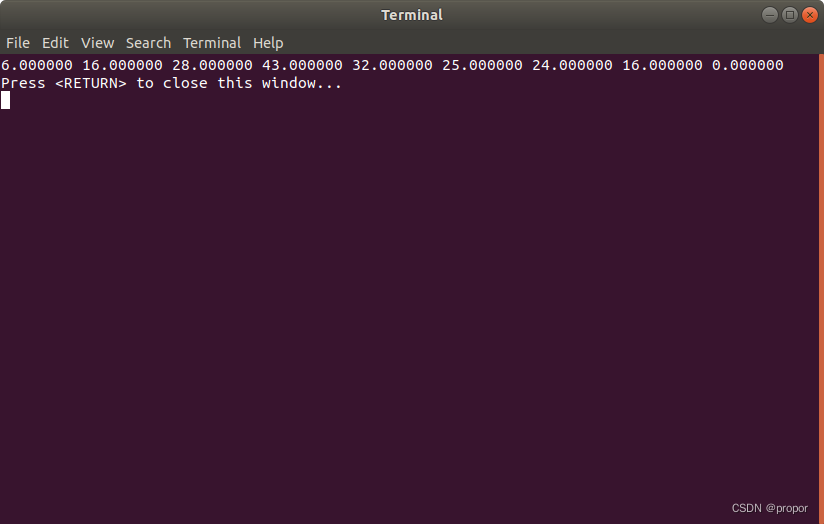
作为对比,在Matlab命令行下输入:
x=[1,2,3,4];
y=[4,3,2,1];
z=xcorr(x,y);查看结果和用C语言实现的是一致的。
3.应用
通过相关运算,我们得到了相关序列,为了方便后续数据处理,需要对得到的相关序列进行归一化处理,对于2个互相关序列,有如下2种归一化方法:
1)有偏估计
2)无偏估计
为了查看这2者之间差异,在Matlab命令行下,输入如下命令:
fm=1000;
fs=100000;
N=fs/fm;
k=0:1:1000;
theta=pi/8;
x=sin(2*k*pi/N + theta);%原始信号
xn=awgn(x,20,0);%原始信号加噪声
subplot(5,1,1);
plot(k,x);
title('x');
subplot(5,1,2);
plot(k,xn);
title('xn');
[r,lags]=xcorr(xn,x,500);%未缩放的互相关
subplot(5,1,3);
plot(k,r);
title('corr none');
[rb,lags]=xcorr(xn,x,500,'biased');%互相关的有偏估计
subplot(5,1,4);
plot(k,rb);
title('corr biased');
[rub,lags]=xcorr(xn,x,500,'unbiased');%互相关的无偏估计
subplot(5,1,5);
plot(k,rub);
title('corr unbiased');输出结果:

由图可知:
1)“未缩放的互相关运算”仅是相关运算计算出的序列,在2个互相关信号重叠(相位差为0)时值最大
2)“互相关的有偏估计”在2个互相关信号重叠(相位差为0)时值最大,且为原始信号幅值的一半
3)“互相关的无偏估计”则有如下特点:
a)与原始信号频率相同
b)输出为cos信号,且起始相位为2个互相关信号相位之差(0)
c)信号幅值为原信号幅值的一半
这其实和相敏检波(PSD)运算效果是一致的(未加LPF)。
总结,本文介绍了相关运算及实现。





















![代码随想录算法训练营第五天:哈希表的初步认识[1]](https://img-blog.csdnimg.cn/img_convert/5ef59ee727c11507da78c5fb19fdc2a4.gif)