知识储备
链接: 【二叉检索树的实现——增删改查、读取命令文件、将结果写入新文件】
1、正则表达式的处理
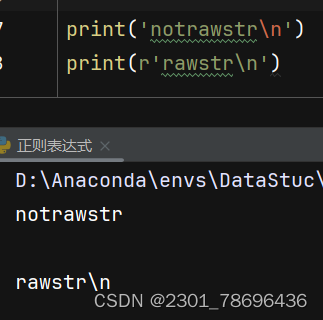
(1)r’'前缀的作用
r’'前缀的用于定义原始字符串,特点是不会处理反斜杠\作为转义字符
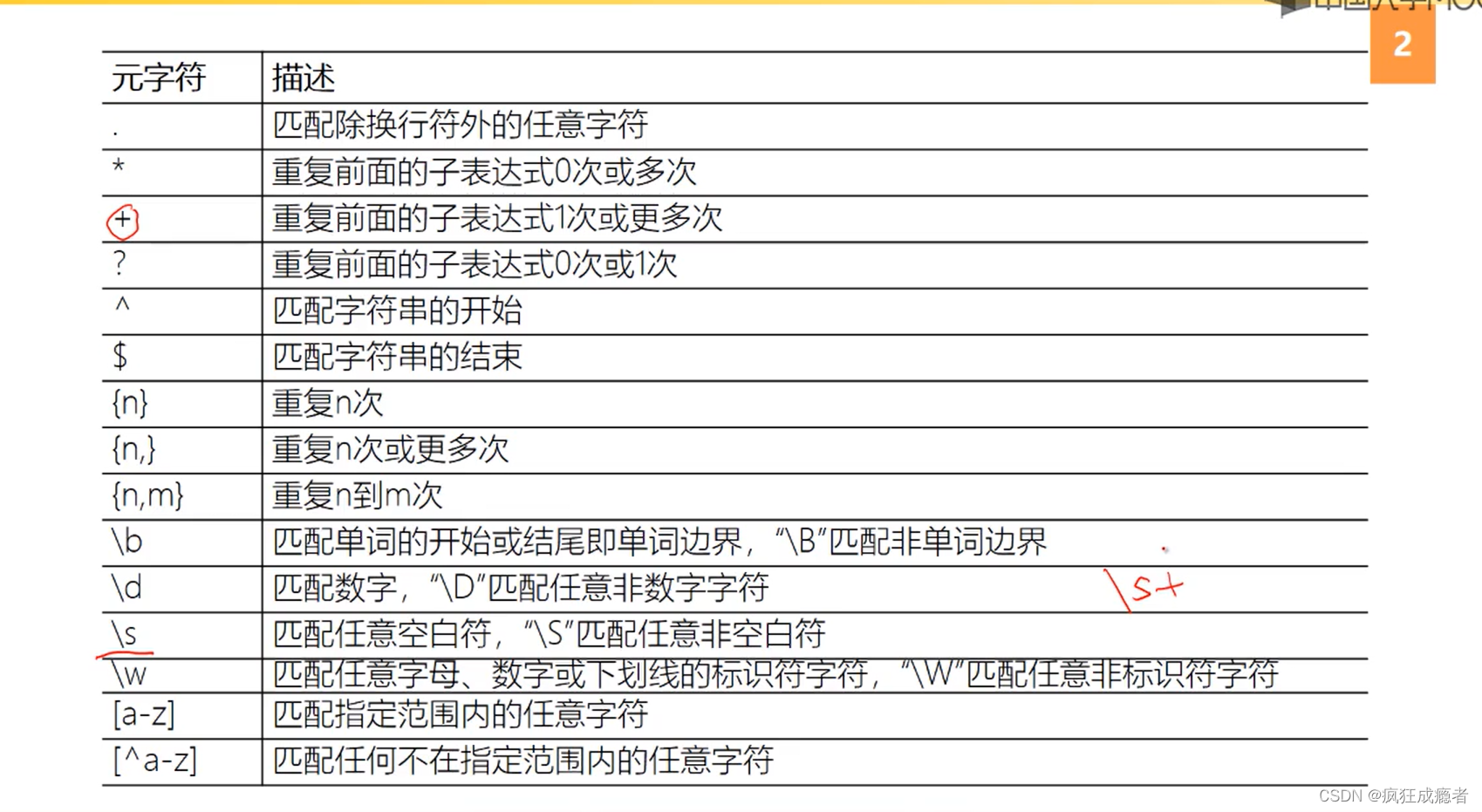
(2)正则表达式中元字符的用法总结
\d代表任意一个数字,+代表前面的任意数字可以出现多次
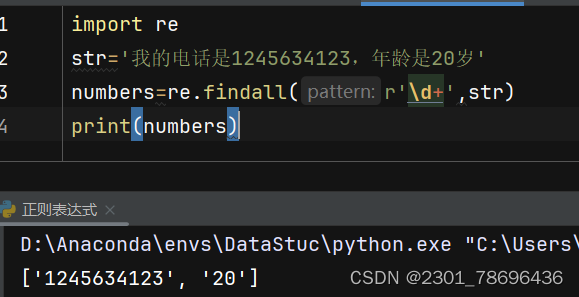
\w代表任意一个字母数字下划线字符,+代表前面的任意可以出现多次
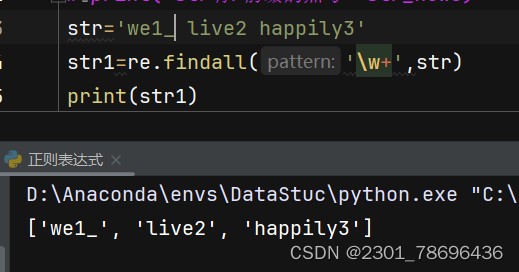
总结:
.:匹配除了换行符之外的任意单个字符。
例子:正则表达式 a.b 可以匹配到 “axb”、“a1b”、“a-b” 等,但不能匹配到 “aab” 或 “a\nb”(除非设置了多行模式)。
*:匹配前面的子表达式零次或多次。
例子:正则表达式 zo* 可以匹配到 “z” 以及 “zoo”。
+:匹配前面的子表达式一次或多次。
例子:正则表达式 zo+ 匹配 “zoo”,但不匹配 “z”。
?:匹配前面的子表达式零次或一次,也可以用在限定符后面表示非贪婪模式。
例子:正则表达式 do(es)? 可以匹配到 “do” 或 “does”。
^:匹配输入字符串的开始位置。
例子:正则表达式 ^Hello 匹配以 “Hello” 开始的字符串。
$:匹配输入字符串的结束位置。
例子:正则表达式 world$ 匹配以 “world” 结束的字符串。
{}:用大括号 {n} 表示恰好匹配 n 次,{n,} 表示至少匹配 n 次,{n,m} 表示匹配至少 n 次但不超过 m 次。
例子:正则表达式 o{2} 匹配 “oo”,o{2,} 匹配 “oo”、“ooo”、“oooo” 等,o{2,4} 匹配 “oo”、“ooo”、“oooo”。
[]:字符集,匹配方括号中列出的任意一个字符。
例子:正则表达式 [abc] 匹配 “a”、“b” 或 “c”。
^(在字符集中):在字符集中表示取非,匹配未列出的字符。
例子:正则表达式 [^abc] 匹配除了 “a”、“b” 和 “c” 以外的任意字符。
\:转义字符,用于匹配那些具有特殊意义的字符,如 . 匹配点字符本身。
例子:正则表达式 . 匹配点字符本身,而不是任意字符。
\d:匹配一个数字字符,等价于 [0-9]。
例子:正则表达式 \d\d\d 匹配三位数,如 “123”。
\D:匹配一个非数字字符,等价于 [^0-9]。
例子:正则表达式 \D\D\D 匹配三个非数字字符。
\w:匹配任意一个字母数字字符或下划线,等价于 [a-zA-Z0-9_]。
例子:正则表达式 \w+ 匹配一个或多个字母、数字或下划线组成的字符串,如 “hello”、“12345” 或 “hello_world”。
\W:匹配任意一个非字母数字字符或非下划线字符,等价于 [ ^a-zA-Z0-9_ ]。
例子:正则表达式 \W+ 匹配一个或多个非字母、非数字或非下划线的字符。
\s:匹配任何空白字符,包括空格、制表符、换页符等。
例子:正则表达式 \s+ 匹配一个或多个空白字符,如空格、制表符或换行符。
\S:匹配任何非空白字符。
例子:正则表达式 \S+ 匹配一个或多个非空白字符。
\b:匹配一个单词边界,即单词和空格之间的位置。
例子:正则表达式 \bcat\b 匹配独立的单词 “cat”,而不是 “concatenate” 中的 “cat”。
\B:匹配非单词边界的位置。
|:或运算符,匹配 | 符号前后的任意一个表达式。
():捕获括号,用于定义一个子表达式,并获取匹配的文本。
例子:正则表达式 (ab)+ 匹配一个或多个 “ab”,并且可以通过捕获括号提取匹配的内容。
(?..):非捕获括号,用于对匹配进行一些额外的操作,如前向和后向查找。
[…]:字符集内可以使用连字符 - 来表示字符范围,例如 [a-z] 表示小写字母范围。
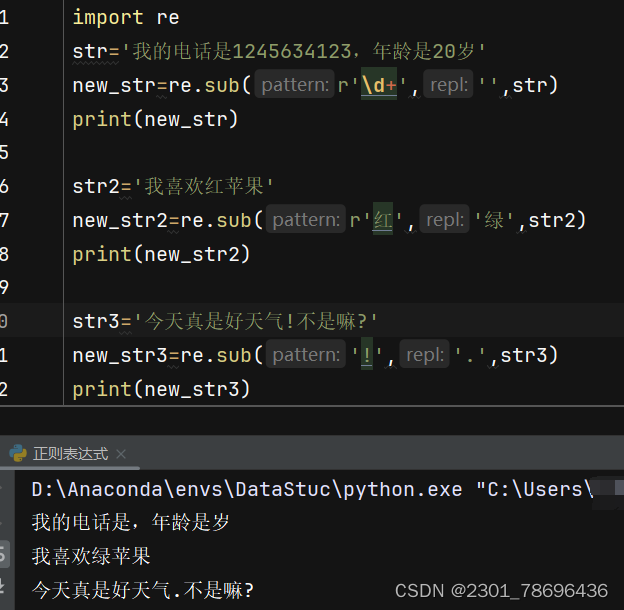
(3)替换字符串中的模式
(4)注意:正则表达式中,点号 “.” 代表除了换行符外的任意单个字符,因此要转义,只能通过反斜杠\转义,r’'前缀达不到目的
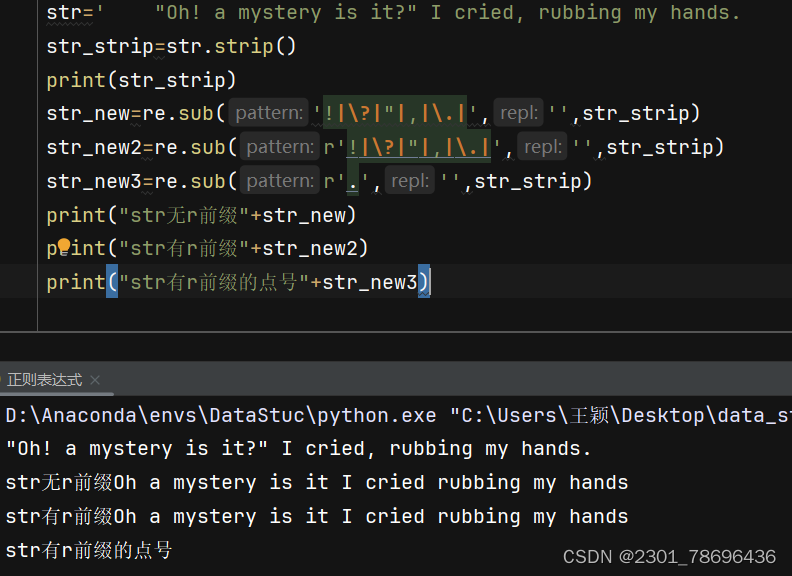
同理,?也一样

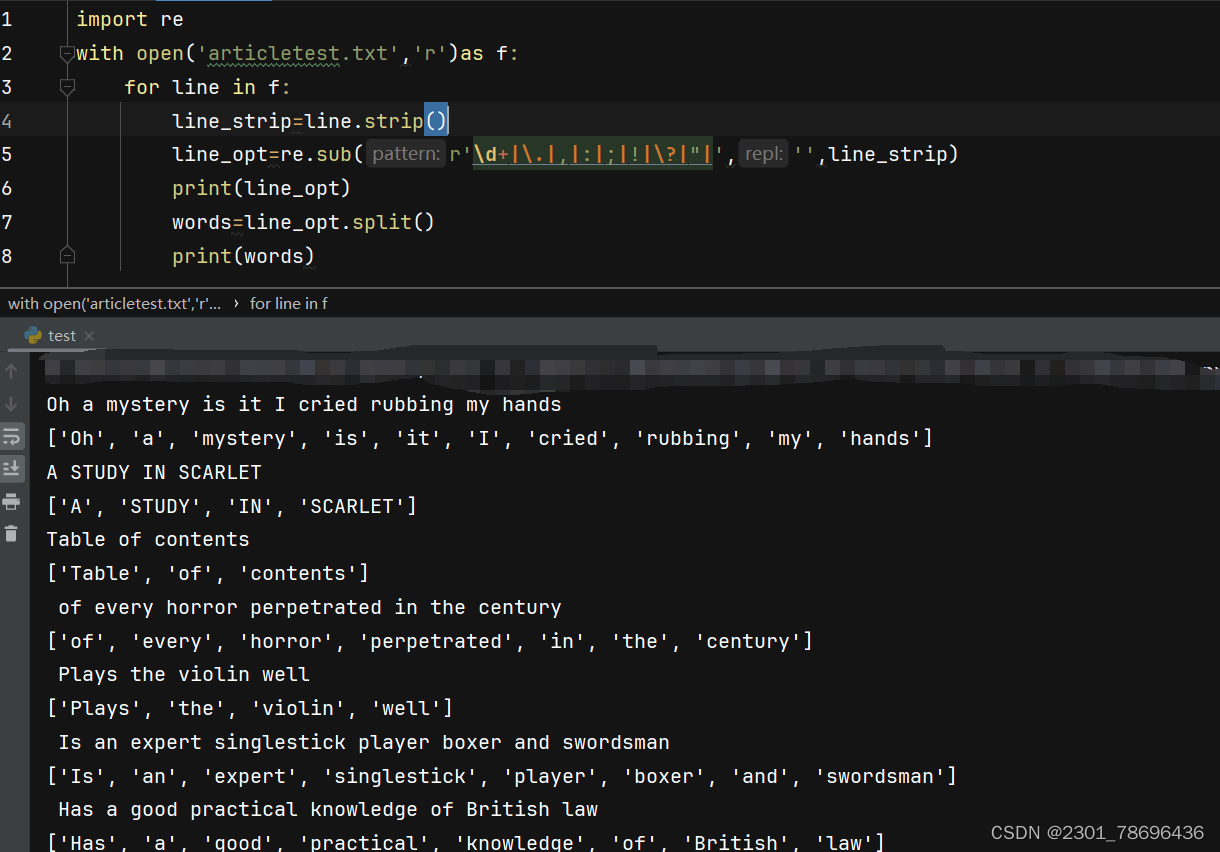
2、利用正则表达式分离文本中的单词
利用正则表达式去掉符号、数字等
(1)文本文件

(2)处理结果
3、利用二叉树将文章中的所有单词建立索引
(1)具体描述
当一本书的文字量很大时,为其创建索引表是一个繁琐的事情。利用任务 2 中构建的 BST 数据结构,
可以很轻松的创建书稿的索引表。方法如下:将文稿中出现的每个单词都插入到用 BST 构建的搜索表中,
记录每个单词在文章中出现的行号。对于如下的文本段 (左侧列表为行号),构建一个 BST,当调用了该
BST 的 printInOrder 方法之后,输出的内容如图 3 所示,一个按字典排序的索引表就创建好了。
1 Dudley’s birthday – how could he have forgotten? Harry got slowly
2 out of bed and started looking for socks. He found a pair under
3 his bed and, after pulling a spider off one of them, put them on.
4 Harry was used to spiders, because the cupboard under the stairs
5 was full of them, and that was where he slept.
6 When he was dressed he went down the hall into the kitchen. The
7 table was almost hidden beneath all Dudley’s birthday presents. It
8 looked as though Dudley had gotten the new computer he wanted, not
9 to mention the second television and the racing bike. Exactly why
10 Dudley wanted a racing bike was a mystery to Harry, as Dudley was
11 very fat and hated exercise – unless of course it involved
12 punching somebody. Dudley’s favorite punching bag was Harry, but
13 he couldn’t often catch him.
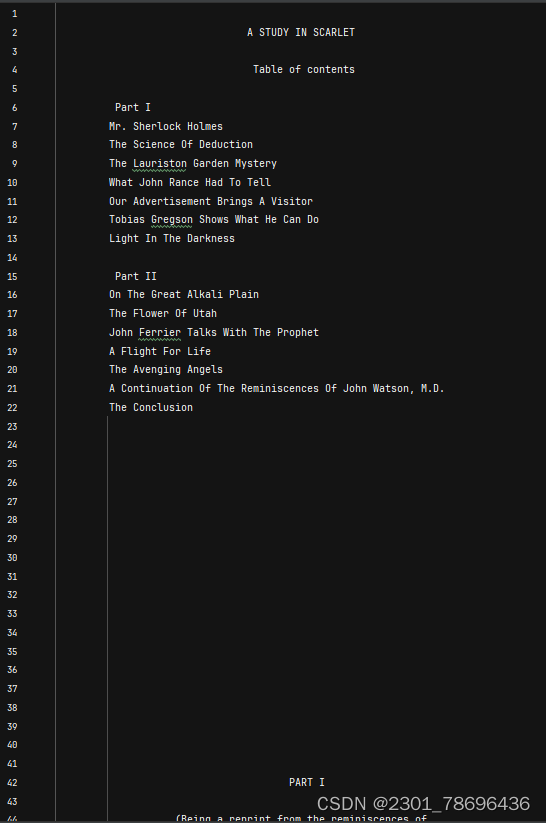
实验材料中准备了一篇英文文稿,文件名为 article.txt1,请按照上面的样例根据该 article.txt 中的内
容构建索引表,并将索引表的内容按照单词的字典序列输出到 indexResult.txt 文件中。构建 BST 中的结点数据时,请认真思考记录行号的数据类型,如果可能,尽量使用之前实验中已构建的数据结构,也是对
已创建的数据结构的一种验证

(2)article(进展示部分全文共有三万多行)

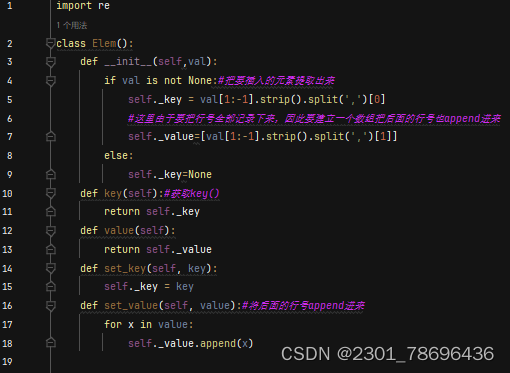
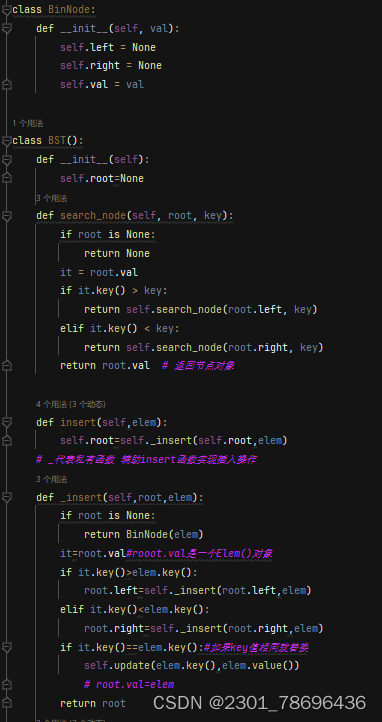
(3)代码实现
对Elem()类、BST()中序遍历方法做了修改
增加了添加索引的函数
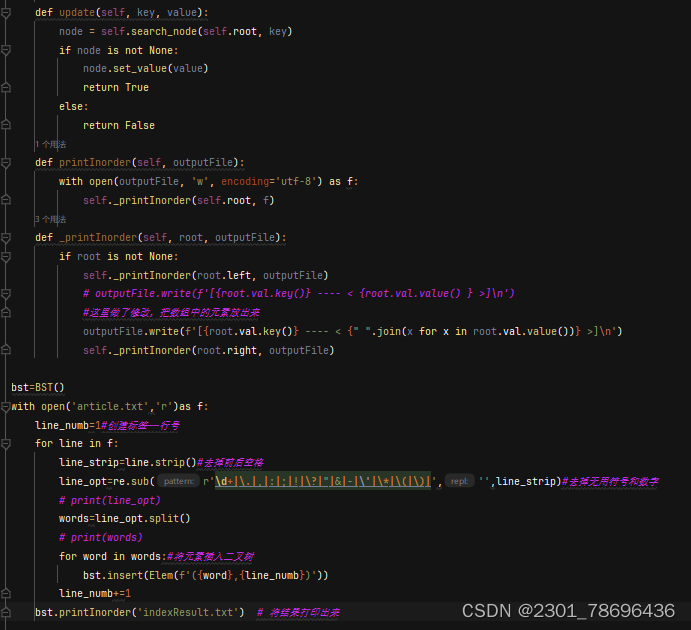
(4)代码注意点
(1)
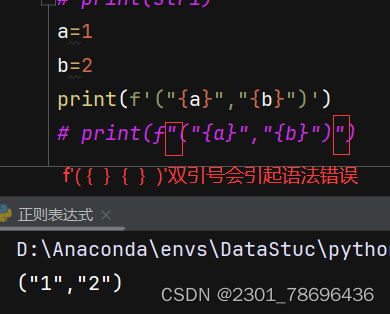
(2)
- lambda x: int(x.strip(‘"’))
这是一个匿名函数,它接受一个参数 x,并返回 int(x.strip(‘"’)) 的结果。在 lambda 函数内部,x.strip(‘"’) 用于去除字符串 x 两端的双引号,然后 int() 函数将其转换为整数。 - map(lambda x: int(x.strip(‘"’)), arr)
这里使用了 map 函数,它将 lambda 函数应用于列表 arr 中的每个元素。即对于列表 arr 中的每个字符串元素,都会执行 lambda 函数,将其转换为整数。 - list(…)
最后,list 函数用于将 map 函数的结果转换为列表,这样我们就得到了包含转换后整数的列表。
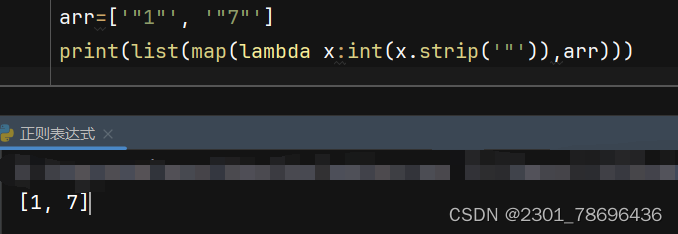
对比:

全部代码
import re
class Elem():
def __init__(self,val):
if val is not None:#把要插入的元素提取出来
self._key = val[1:-1].strip().split(',')[0]
#这里由于要把行号全部记录下来,因此要建立一个数组把后面的行号也append进来
self._value=[val[1:-1].strip().split(',')[1]]
else:
self._key=None
def key(self):#获取key()
return self._key
def value(self):
return self._value
def set_key(self, key):
self._key = key
def set_value(self, value):#将后面的行号append进来
for x in value:
self._value.append(x)
class BinNode:
def __init__(self, val):
self.left = None
self.right = None
self.val = val
class BST():
def __init__(self):
self.root=None
def search_node(self, root, key):
if root is None:
return None
it = root.val
if it.key() > key:
return self.search_node(root.left, key)
elif it.key() < key:
return self.search_node(root.right, key)
return root.val # 返回节点对象
def insert(self,elem):
self.root=self._insert(self.root,elem)
# _代表私有函数 辅助insert函数实现插入操作
def _insert(self,root,elem):
if root is None:
return BinNode(elem)
it=root.val#rooot.val是一个Elem()对象
if it.key()>elem.key():
root.left=self._insert(root.left,elem)
elif it.key()<elem.key():
root.right=self._insert(root.right,elem)
if it.key()==elem.key():#如果key值相同就替换
self.update(elem.key(),elem.value())
# root.val=elem
return root
def update(self, key, value):
node = self.search_node(self.root, key)
if node is not None:
node.set_value(value)
return True
else:
return False
def printInorder(self, outputFile):
with open(outputFile, 'w', encoding='utf-8') as f:
self._printInorder(self.root, f)
def _printInorder(self, root, outputFile):
if root is not None:
self._printInorder(root.left, outputFile)
# outputFile.write(f'[{root.val.key()} ---- < {root.val.value() } >]\n')
#这里做了修改,把数组中的元素放出来
outputFile.write(f'[{root.val.key()} ---- < {" ".join(x for x in root.val.value())} >]\n')
self._printInorder(root.right, outputFile)
bst=BST()
with open('article.txt','r')as f:
line_numb=1#创建标签——行号
for line in f:
line_strip=line.strip()#去掉前后空格
line_opt=re.sub(r'\d+|\.|,|:|;|!|\?|"|&|-|\'|\*|\(|\)|','',line_strip)#去掉无用符号和数字
# print(line_opt)
words=line_opt.split()
# print(words)
for word in words:#将元素插入二叉树
bst.insert(Elem(f'({word},{line_numb})'))
line_numb+=1
bst.printInorder('indexResult.txt') # 将结果打印出来