欢迎大家收藏,点赞。本文章适合知识蒸馏入门新手。
首先以2020年的论文CRD为学习基础,再学习较新的论文。因此,本文先复现CRD论文。
目录
(KD) - Distilling the Knowledge in a Neural Network
思考:KD方法中,教师的温度和学生的温度一样,如果不一样呢?会有什么效果?
CRD(2020)代码复现(亲测能跑通!!!)
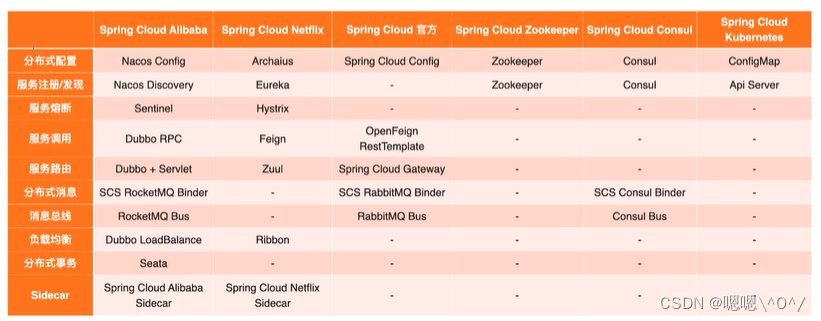
此链接是2020年的一篇经典论文,它实现了KD、FitNet、AT、SP、CC、VID、RKD、PKT、AB、FT、FSP、NST等知识蒸馏方法。本文在代码中对以上的方法进行详细介绍,以及如何实现。此外,还介绍了一些较新的知识蒸馏方法,例如CTKD,MGD,PEFD,SimKD。
首先需要将代码调试通,在windows环境下跑起来。
1. 先下载代码,然后解压到本地目录,链接在上面。
2. 打开pycahrm,打开项目。(我的python版本是3.9)
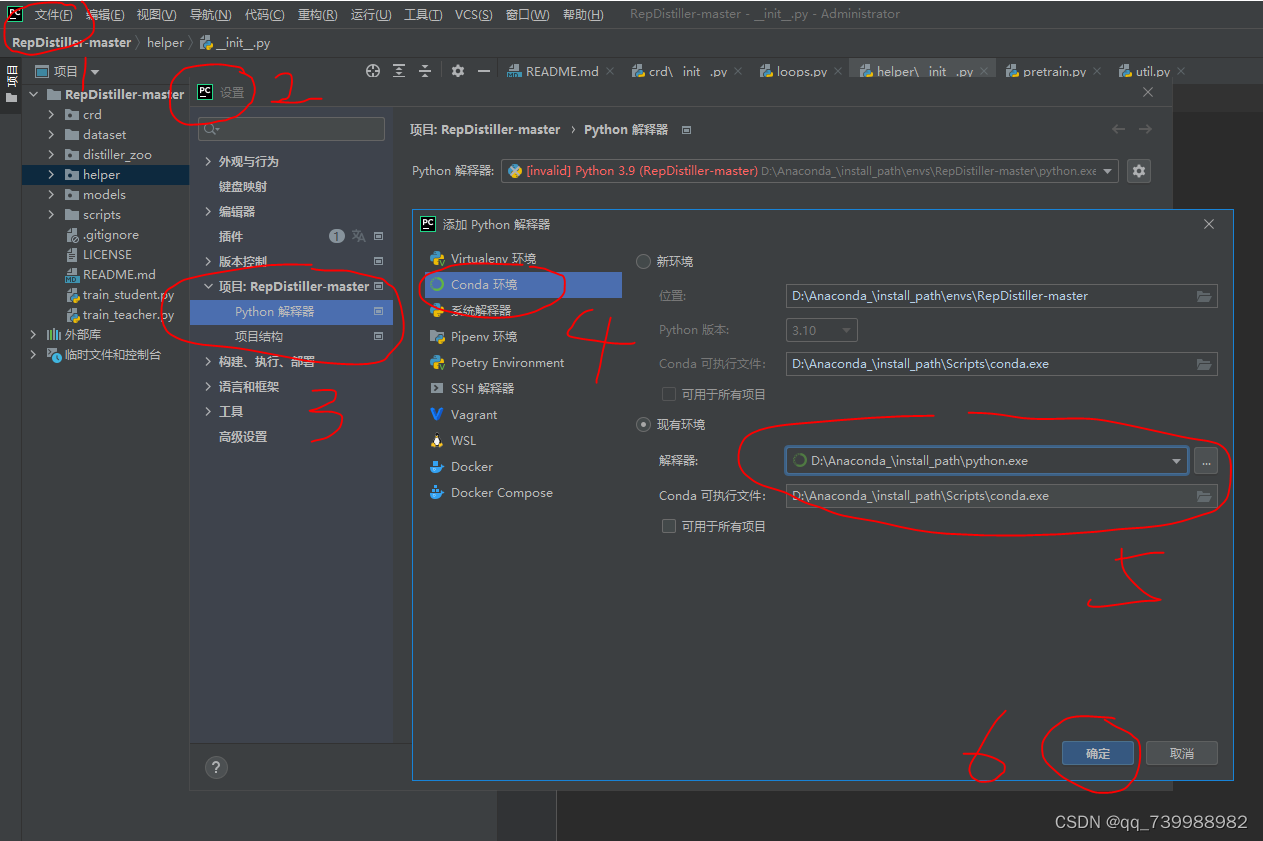
3. 配置conda环境。文件---设置---搜索python解释器---点击Python解释器最右方的六芒星,添加环境---Conda环境---确定。
4. 项目介绍:

CRD目录:本论文的核心思想模块。
dataset目录:数据集的加载设置。
distiller_zoo目录:各种蒸馏方法的模块,包括KD、FitNet、AT、SP、CC、VID、RKD、PKT、AB、FT、FSP、NST等知识蒸馏方法。
helper目录:训练网络需要的帮助性模块。
models目录:各种网络模型,包括教师模型和学生模型。
scripts目录:shell命令。
train_student和train_teacher。一个是训练学生所需(训练学生就需要用到知识蒸馏方法,不是单独训练一个小模型),一个是训练教师所需。
5. 直接运行train_student,遇到问题再见招拆招。
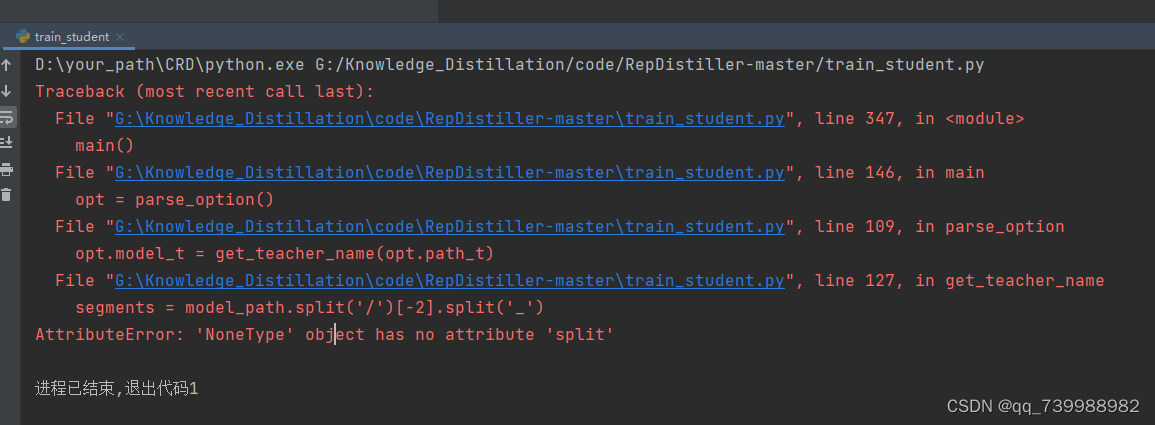
这里报错,原因是没有添加教师的路径。找不到教师模型。
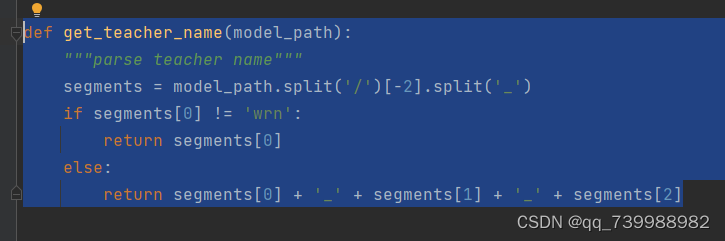
这里的参数,--path_t就是教师路径,这里默认为None。需要我们添加。

此时,项目中还没有训练好的教师网络,但还好作者提供了训练好的教师网络,可以去下载。
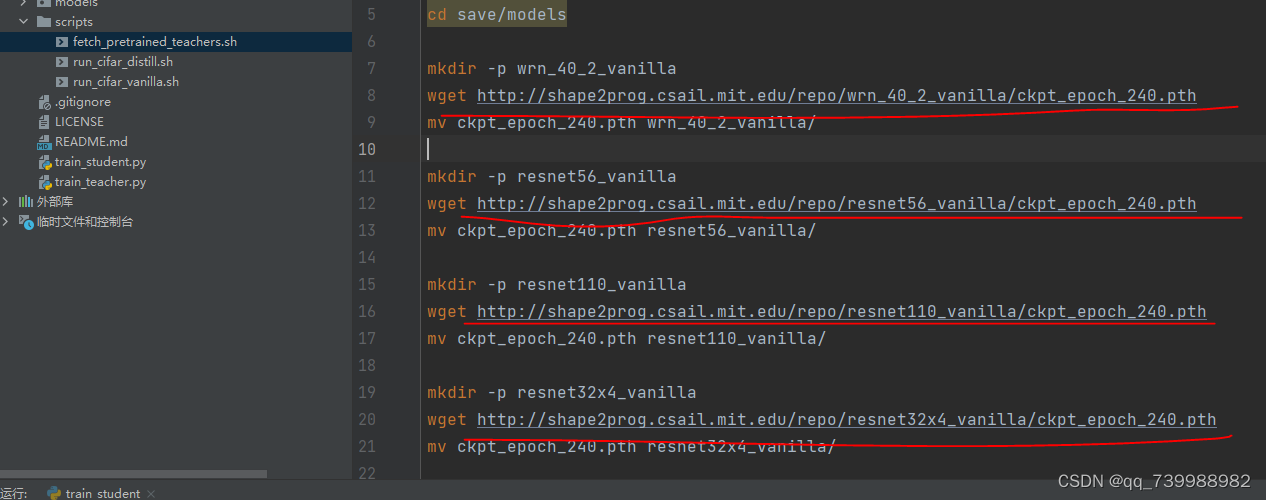
可以使用终端命令或者手动复制这个网址到浏览器上下载。下载完之后把文件放入到项目中。
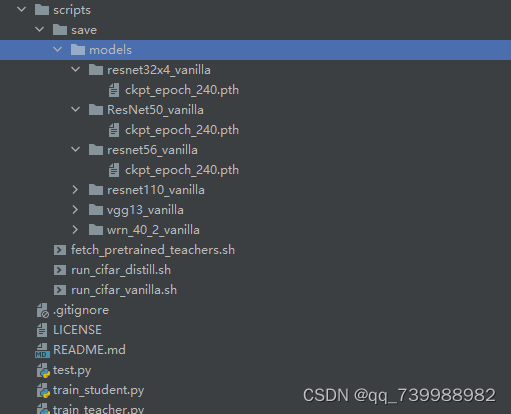
我将这些文件下载下来保存到了scripts/save/models里面,如下图所示。
以resnet32x4_vanilla作为教师,鼠标右键复制绝对路径,添加到train_student.py文件中的超参数
--path_t中,并将路径中的 / 替换为 \ 如下图所示。

运行train_student.py。此时又报错,
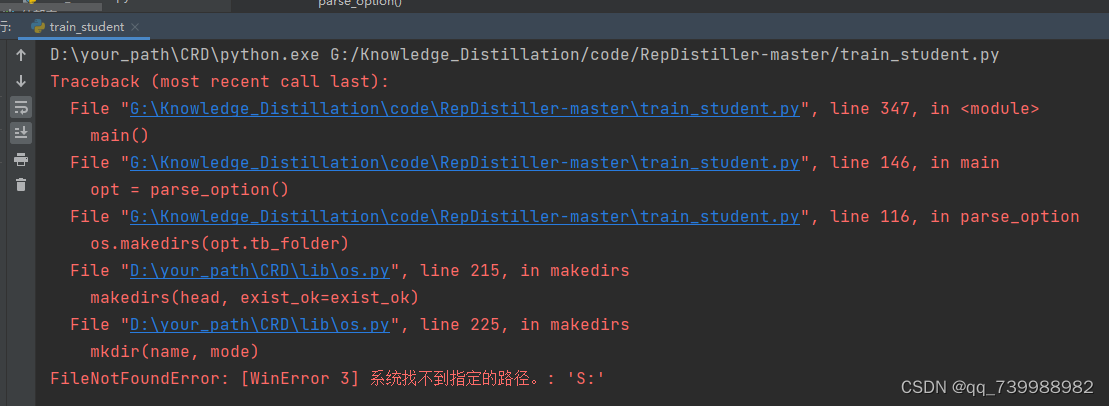
找到问题所在,如下图所示。原因是这个:符号,在windows系统下创建一个文件不能用冒号命名。

将这个名称修改一下即可,我将符号:修改为符号~ 如下图所示。

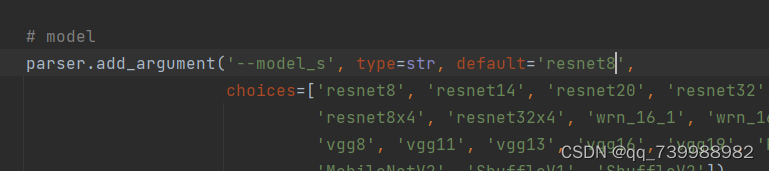
然后我们将学生模型resnet8修改为resnet8x4,choices里面有,直接复制过来。
因为resnet32x4和resnet8x4是一对。如下两张图所示。

此时开始自动下载数据集。等待下载完或者自行到网上下载。

项目文件里面多了一个data文件,里面装的就是数据集。
然后再次运行train_student,又报错。这个错误是因为我的电脑线程最大是6.

将超参数num_works,默认值8,改为6.如下如所示。

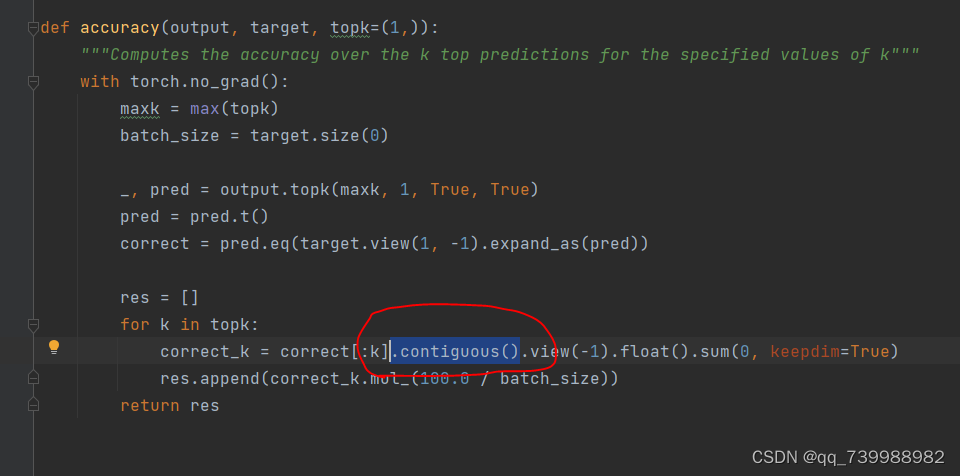
还有一个错误,如下图所示。

这是因为view()需要Tensor中的元素地址是连续的,但可能出现Tensor不连续的情况,所以先用 .contiguous()。将其在内存中变成连续分布即可。如下图所示。
再次运行train_student.py。又报错。这是因为pytorch版本的原因。导致读取数据没有读取到。
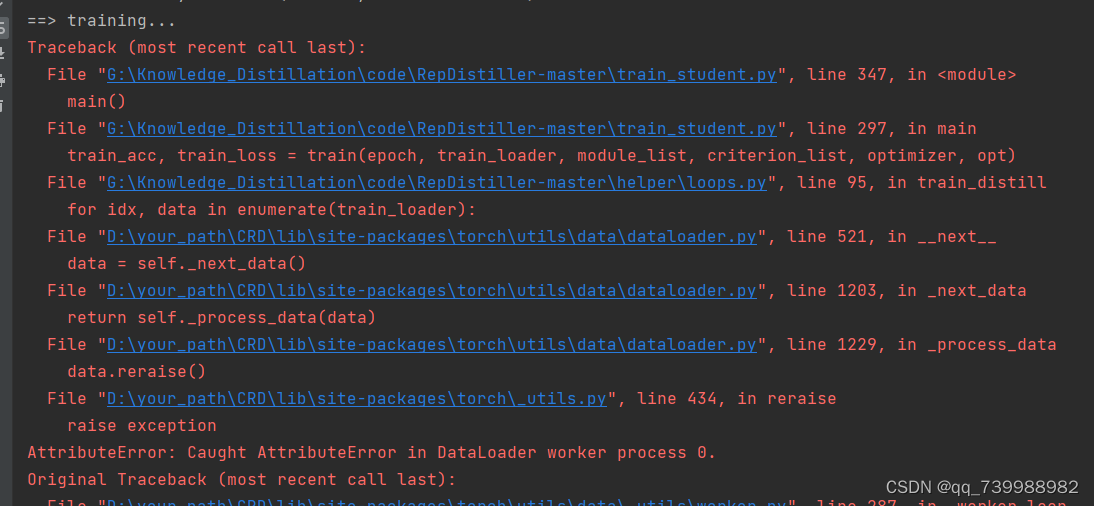
找到dataset里面的cifar100. 将括号括起来的注释掉,改为下图所示。

再次运行train_student.py。又报错。
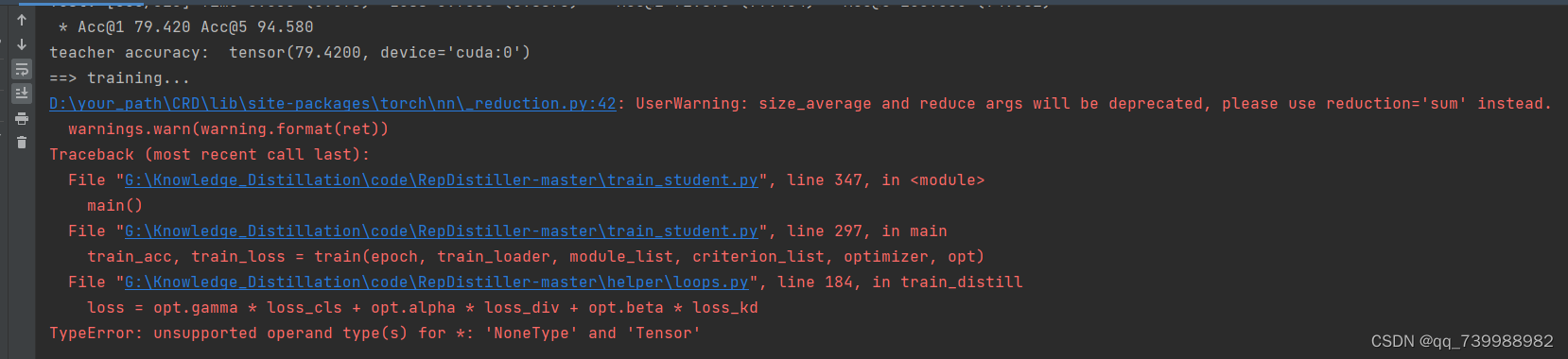
这是因为损失的权重默认为None,我们需要修改一下。如下图所示,将alpha设置为1,beta设置为0.


代码又报错。

超参数distill默认值是kd,如下图所示。因此去distiller_zoo/KD.py中去找原因。

将size_average=False替换为reduction='sum',如下面两张图所示。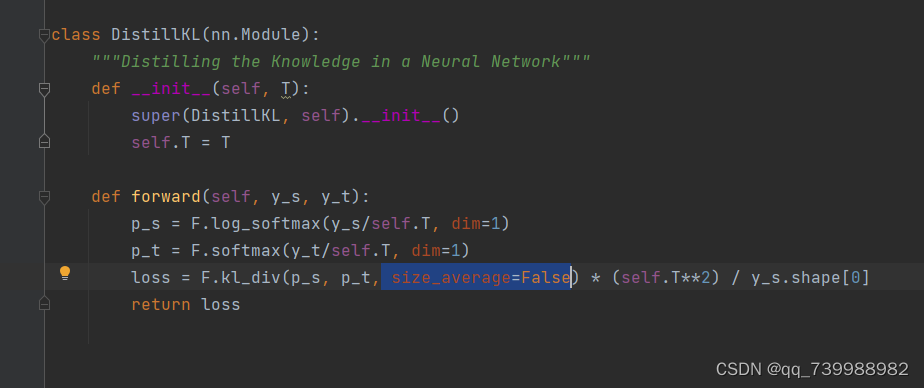
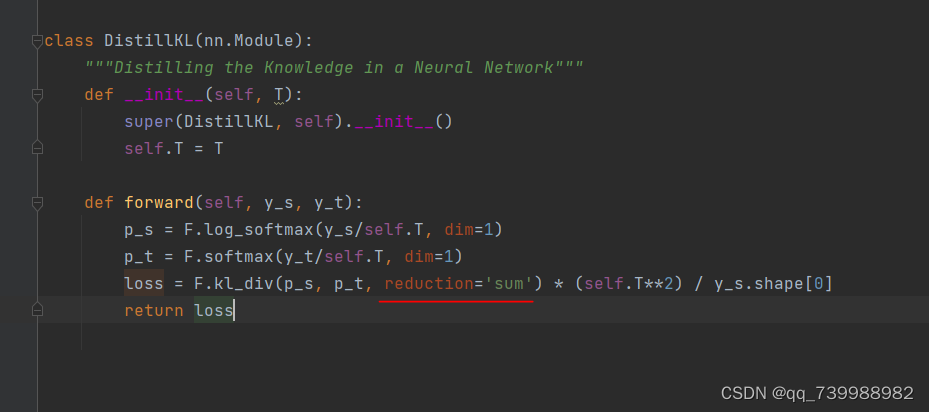
如下图所示,到这里,代码就跑通啦!!!
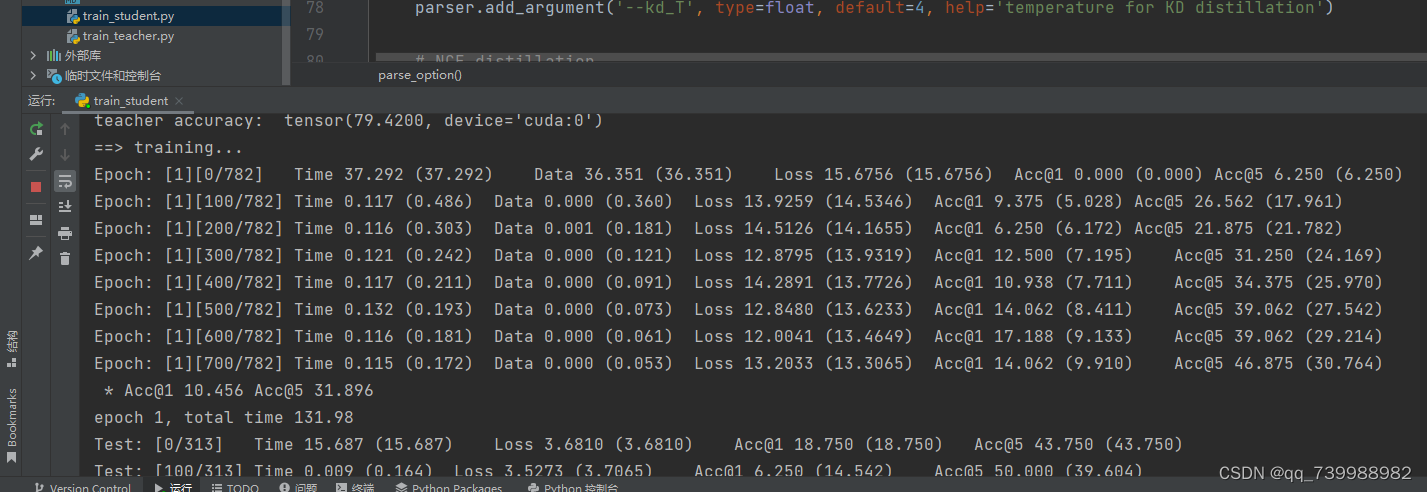
下面我们开始进一步学习。
(KD) - Distilling the Knowledge in a Neural Network
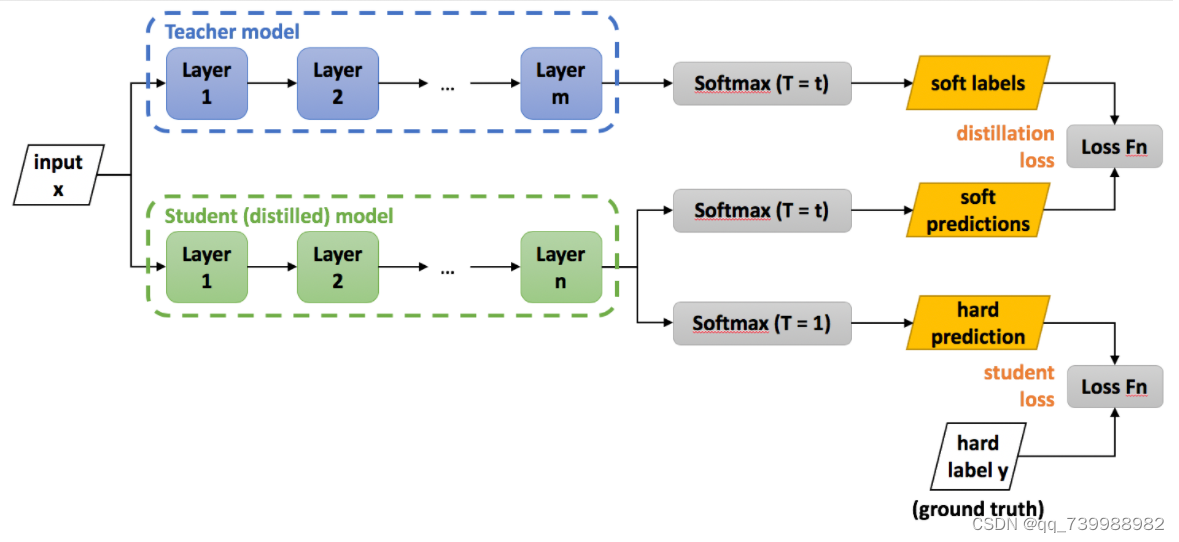
这篇论文是知识蒸馏的开山之作。意思就是大模型和小模型的输出logit(logit是input x通过layer层之后的输出)通过温度T(超参数)柔滑输出来计算损失。此外,小网络还向真实标签学习。
将大网络比作教师,小网络比作学生,真实标签比作课本。
学生向教师学习,同时也向课本学习。
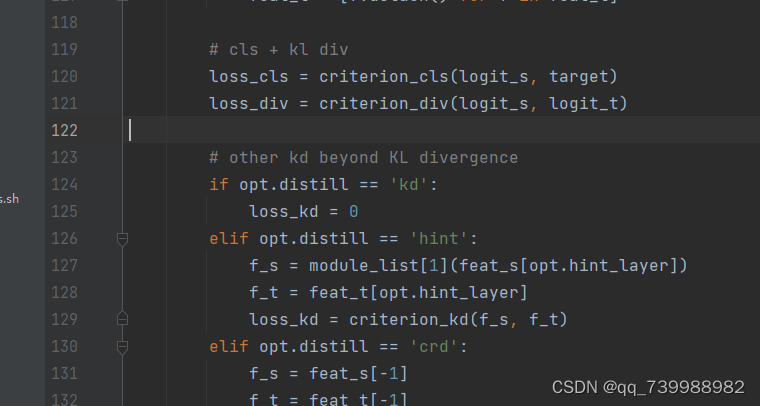
在CRD的代码中有3种损失,在helper/loops.py里,如下图所示。其中,loss_cls是学生模型的输出和目标标签的损失(向课本学习),loss_div是教师输出和学生输出的损失(学生向教师学习)。还有其他的一些蒸馏方法由loss_kd来表示。
训练学生模型的总损失就由3部分组成,如下所示。gamma、alpha、beta分别是损失的权重(超参数)。
gamma、alpha、beta的超参数设置在train_student.py文件里,如下图所示。

(KD) - Distilling the Knowledge in a Neural Network这篇论文是只用到了教师和学生的损失与学生与真实标签的损失。因此,实现此方法,不需要beta,因此把beta设置成0。
KD代码实现
在distiller_zoo/KD.py中,如下图所示。
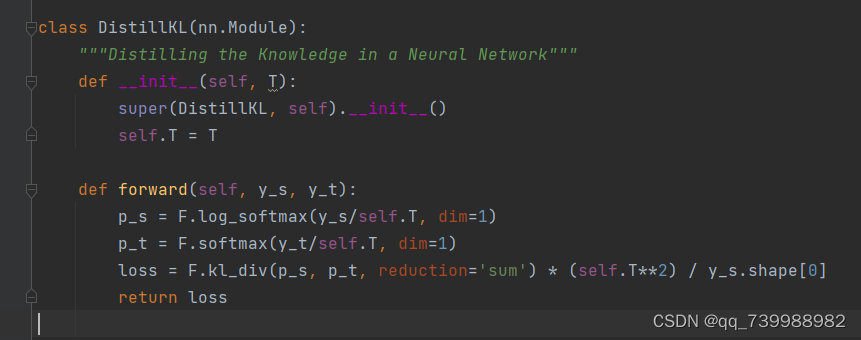
这里的温度设置在train_student.py文件中。kd_T表示温度的大小,作者默认设置为4。

KD用到的公式

思考:为什么KD方法有效?
答:因为超参数温度T可以柔化教师和学生的输出,让学生不仅仅知道正确类别的信息,也知道错误类别的信息。
实验:温度T的消融实验
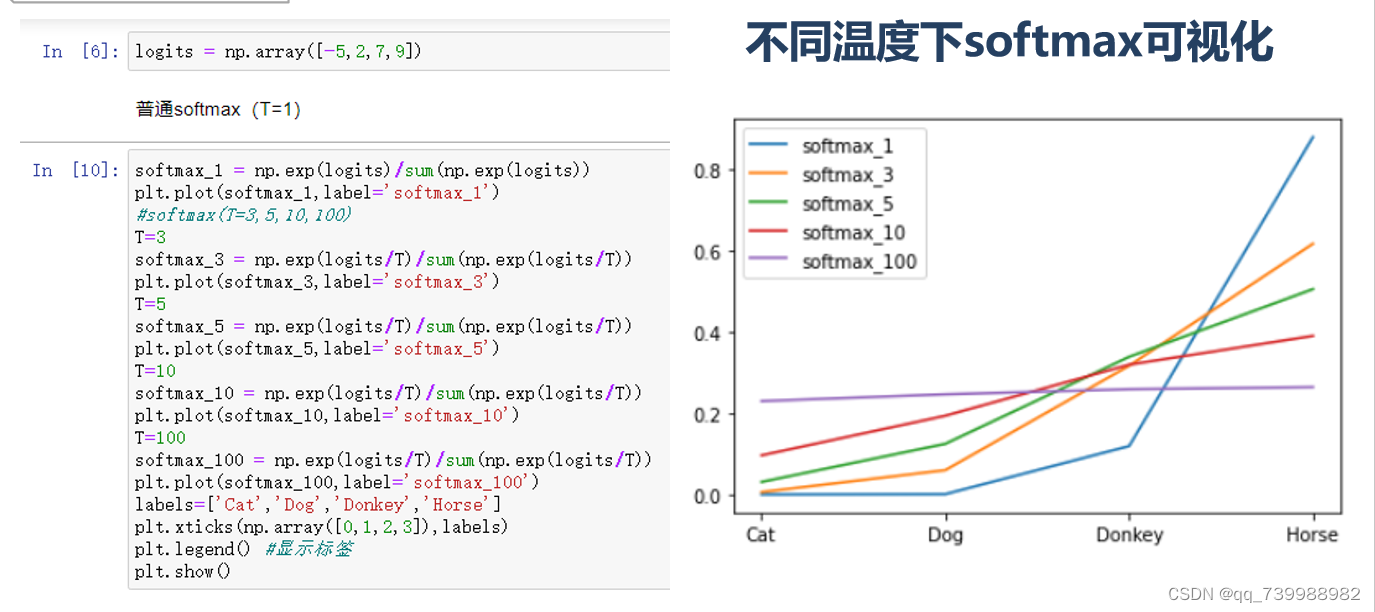
实验结果分析:使用np.array()来模拟网络的输出。如右图所示,温度越高,越能拉拢类与类之间的区别,当温度为100的时候,Cat、Dog、Donkey、Horse之间的区别就很难以区分了。相反,如果温度越低,类别之间的区别就越大。特别地,当温度为1的时候,相当于没有温度。实验结果证明,温度T可以对网络模型的输出起到柔化的作用。
思考:KD方法中,教师的温度和学生的温度一样,如果不一样呢?会有什么效果?
对于知识蒸馏中的温度T问题,推荐阅读《Curriculum Temperature for Knowledge Distillation》:链接: Curriculum Temperature for Knowledge Distillation | Papers With Code
--这篇论文(CTKD)将超参数温度动态化,网络会自动学习温度,无需手动设置。2023
还推荐阅读《Logit Standardization in Knowledge Distillation》
链接: Logit Standardization in Knowledge Distillation | Papers With Code
--这篇论文探讨了师生温度弊端问题,并提出了Logit标准化来解决。 CVPR 2024
(后面的内容待更新!!!!欢迎收藏、点赞)
(FitNet) - Fitnets: hints for thin deep nets
(AT) - Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
(SP) - Similarity-Preserving Knowledge Distillation
(CC) - Correlation Congruence for Knowledge Distillation
(VID) - Variational Information Distillation for Knowledge Transfer
(RKD) - Relational Knowledge Distillation
(PKT) - Probabilistic Knowledge Transfer for deep representation learning
(AB) - Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
(FT) - Paraphrasing Complex Network: Network Compression via Factor Transfer
(FSP) - A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
(NST) - Like what you like: knowledge distill via neuron selectivity transfer
CRD:
AB:
AT
CC
DKD
FitNet
FSP
FT
RKD
SP
VID
SimKD
PEFD
MGD
CTKD
多出口网络
NKD
SSD
Logits标准化KD