Videos
Due to the memory constraints, we have to do some down-sampling
Raw video: long high fps
Training: short clips with low fps
testing: run model on different clips, averaging predictions
Single-frame CNN
train normal 2D CNN to classify frames independently!
easy but a very strong baseline!
Late fusion
take the time axis into account
(flatten / average pooling) concatenate the results of CNNs and feed to MLP to get a classification score
Problem: Hard to compare low-level motion between frames
Early Fusion
compare frames with very first conv layer after that normal 2D CNN
then pass a 2D CNN to get class score
Problem: only one layer of the temporal processing may be not enough
3D CNN (slow fusion network)
use 3D conv and 3D pooling operations
C3D: The VGG of 3D CNNs
Measuring Motion: Optical Flow
Optical Flow gives a displacement field F between image t and image t+1.
Two-Stream Networks
combine Spatial stream Convnet and Temporal stream Convnet to a large vector and get a class score
Train the two Convnets seperately and take averages in Test time
Modeling long-term temporal structure
we can extract features with CNN (2D / 3D) and use lstm in the time axis
trick: sometimes we don’t backprop to CNN to save memory (use them as a feature extractor)
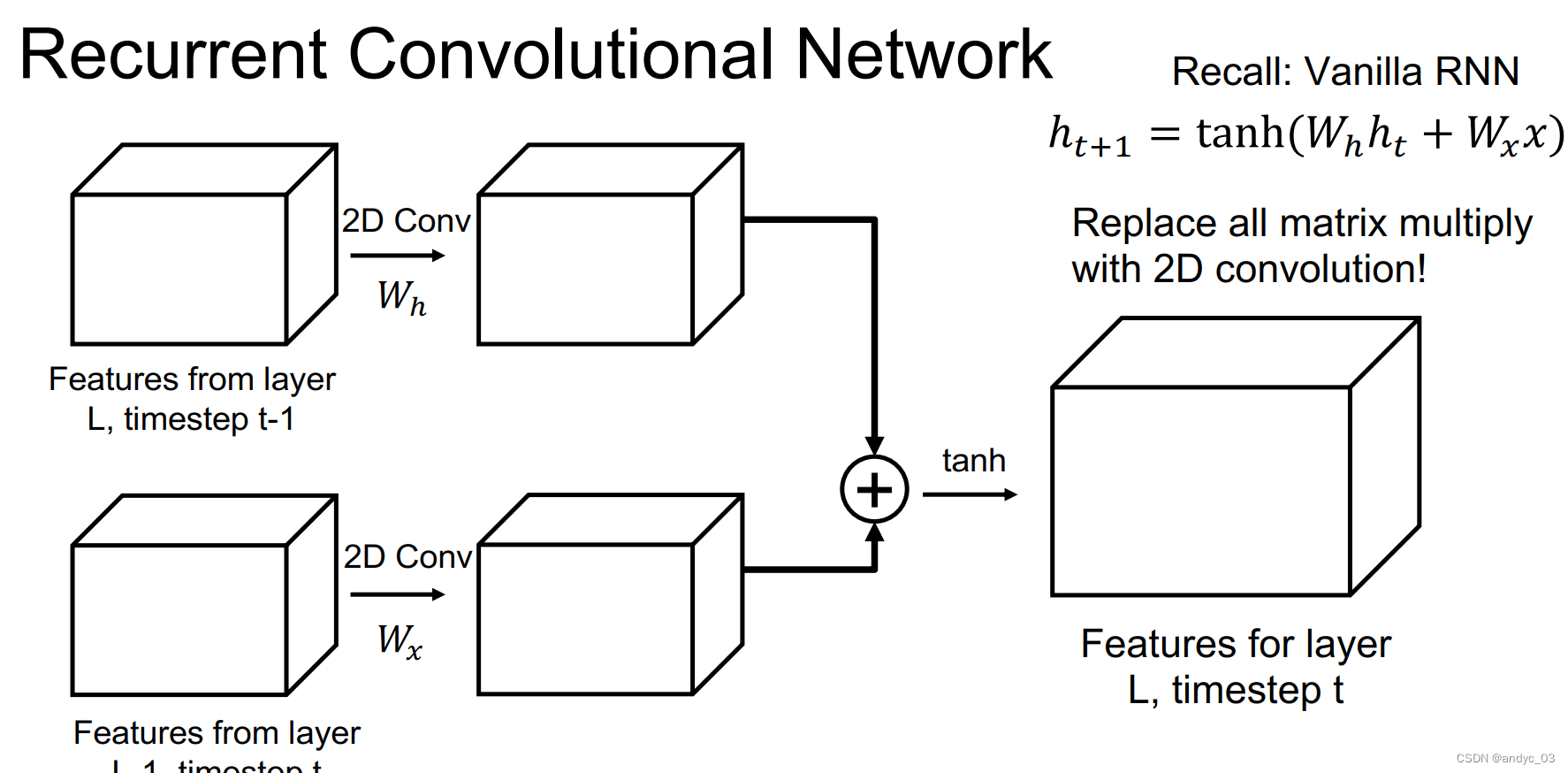
Recurrent Convolutional Network

Spatio-Temporal Self-Attention (Nonlocal Block)
Inflating 2D Networks to 3D (I3D)
take a 2D CNN architecture and replace each 2D conv/pool with a 3D version
we can inflate the trained weighted as well, duplicate them in time
pre-train model on images -> inflate them into videos -> fine-tuning
We can use the same visualizing tricks
SlowFast Networks
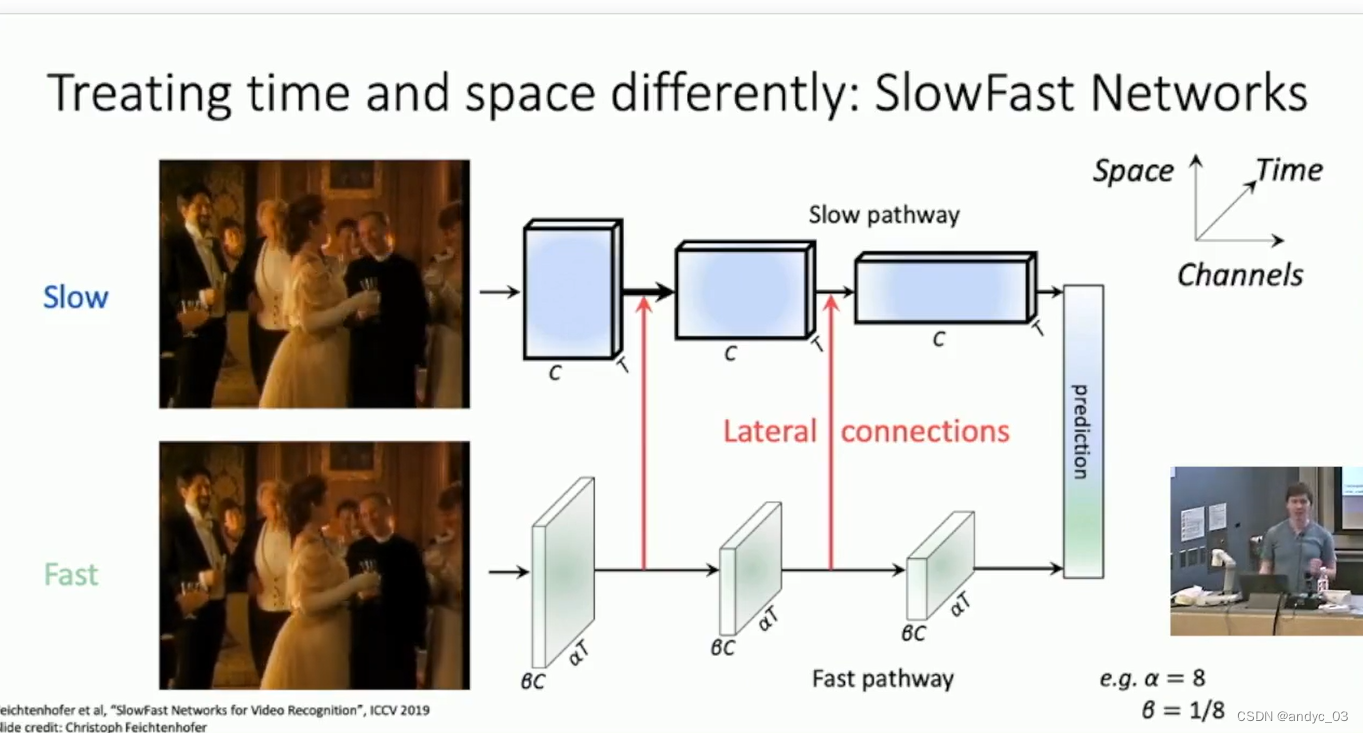
Other aspects: Temporal Action Localization, Spatio-Temporal Detection