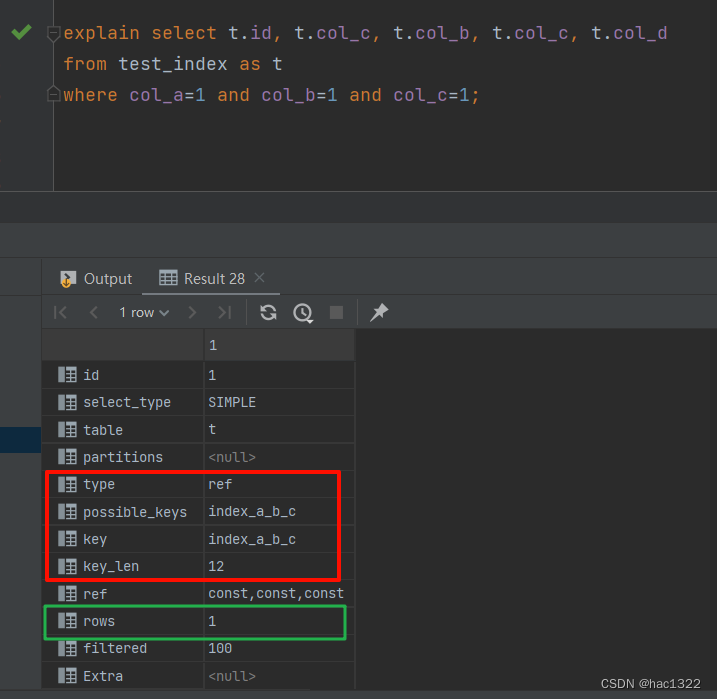
目录
前言
在网络爬虫和数据抓取领域,Python提供了多种强大的库来辅助开发者从网站上有效地抓取所需数据。这些库各有其特点和适用场景,下面将详细介绍六个常用的Python爬虫库:Requests, Beautiful Soup, Scrapy, Lxml, Selenium, 和 PyQuery。
1. Requests
特点:
- 简洁易用:Requests库以其简洁的API而闻名,使得发送网络请求变得异常简单。
- 功能丰富:支持从基本的GET和POST请求到复杂的功能如会话、Cookie处理、超时设置、SSL验证等。
应用场景: 适用于所有需要发送HTTP请求的场合。虽然它不直接用于解析网页,但通常作为获取网页内容的第一步,之后可以配合其他解析工具进行内容抓取。
示例代码:
import requests
response = requests.get('https://example.com')
print(response.text)2. Beautiful Soup
特点:
- 易于解析:可以快速地从HTML或XML中提取所需数据。
- 容错能力:即使面对格式不完美的标记,也能解析。
- 多种解析器支持:支持Python标准库的HTML解析器,还可以选择性能更优的lxml作为解析器。
应用场景: 适合于解析HTML页面,提取信息,特别是当页面结构比较规整,没有大量异步加载内容时。
示例代码:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello, World!</p>', 'html.parser')
print(soup.p.text)
3. Scrapy
特点:
- 框架全面:Scrapy是一个完整的爬虫框架,提供了项目结构、命令行工具等。
- 高性能:基于Twisted异步网络库,适合抓取大量数据。
- 可扩展性:支持自定义中间件、插件等,适合复杂的爬虫应用。
应用场景: 适用于需要高性能、大规模、复杂数据抓取的场景。常用于商业和研究中的数据挖掘项目。
示例代码:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com']
def parse(self, response):
yield {'text': response.css('p::text').get()}
4. Lxml
特点:
- 高性能:基于C语言库libxml2和libxslt,执行速度极快。
- 强大的XML支持:除HTML外,对XML的支持也非常强大。
- XPath和XSLT支持:支持复杂的XPath查询和XSLT转换。
应用场景: 适合需要进行复杂的XML处理或要求高性能解析的应用。
示例代码:
from lxml import etree
tree = etree.HTML('<p>Hello, World!</p>')
result = tree.xpath('//p/text()')
print(result[0])
5. Selenium
特点:
- 浏览器自动化:可以驱动真实的浏览器环境,模拟用户的真实操作。
- 支持JavaScript渲染页面:可以处理动态加载的内容,获取JavaScript生成的数据。
应用场景: 适用于需要与网页进行交互,或处理大量由JavaScript动态生成的内容的场景。
示例代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://example.com')
print(driver.page_source)
driver.quit()
6. PyQuery
特点:
- 类jQuery语法:使用与jQuery类似的语法,使得从HTML文档中提取信息变得非常直观。
- 快速方便:执行速度快,使用简便。
应用场景: 适合快速抓取和处理HTML文档,尤其是对于熟悉jQuery的开发者。
示例代码:
from pyquery import PyQuery as pq
d = pq('<p>Hello, World!</p>')
print(d('p').text())