private final LinkedHashMap<K, V> map;
//当前缓存的大小(带单位的)
private int size;
//缓存最大容量(带单位的)
private int maxSize;
…
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException(“maxSize <= 0”);
}
this.maxSize = maxSize;
//LinkedHashMap是按照 访问顺序 排序的,所以get、put操作都会把要存的k-v放在队尾
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
/**
- 获取缓存,同时会把此k-v放在链表的尾部
*/
public final V get(K key) {
if (key == null) {
throw new NullPointerException(“key == null”);
}
V mapValue;
//get是线程安全的操作
synchronized (this) {
//LinkedHashMap的get方法中调afterNodeAccess,会移到链表尾部
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
…
}
/**
缓存key-value,value会存在 队尾
@return 之前也是这个key存的value
*/
public final V put(K key, V value) {
if (key == null || value == null) {
//不允许 null key、null value
throw new NullPointerException(“key == null || value == null”);
}
V previous;
//可见put操作是线程安全的
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
//强引用存入map(不会被动地被系统回收),其因为是LinkedHashMap,会放在队尾
previous = map.put(key, value);
if (previous != null) {
//如果前面已这个key,那么替换后调整下当前缓存大小
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
//重新调整大小
trimToSize(maxSize);
return previous;
}
/**
- 比较 当前已缓存的大小 和最大容量,决定 是否删除
*/
private void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
- “.sizeOf() is reporting inconsistent results!”);
}
if (size <= maxSize) {
//大小还没超过最大值
break;
}
//已经达到最大容量
//因为是访问顺序,所以遍历的最后一个就是最近没有访问的,那么就可以删掉它了!
Map.Entry<K, V> toEvict = null;
for (Map.Entry<K, V> entry : map.entrySet()) {
toEvict = entry;
}
// END LAYOUTLIB CHANGE
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
//因为是为了腾出空间,所以这个回调第一个参数是true
entryRemoved(true, key, value, null);
}
}
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {}
…
}
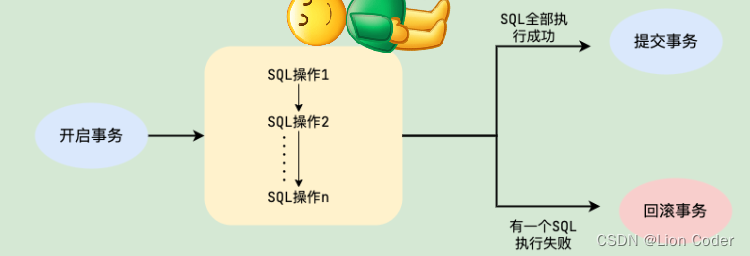
由以上代码及注释,可见LruCache的算法实现是依靠 设置了访问顺序的LinkedHashMap。因为是访问顺序模式,get、put操作都会调整k-v到链表尾部。在缓存将满时,遍历LinkedHashMap,因为是访问顺序模式,所以遍历的最后一个就是最近没有使用的,然后删除即可。
2.2 DiskLruCache
DiskLruCache是实现磁盘缓存,所以需要设备存储的读写权限;一般是从网络请求图片后缓存到磁盘中,所以还需要网络权限。
DiskLruCache,不是官方提供,所以需要引入依赖:
implementation ‘com.jakewharton:disklrucache:2.0.2’
DiskLruCache的创建,不是通过new,而是open方法,需要传入缓存目录、最大缓存容量。
缓存的添加,是通过Editor,缓存对象的编辑器。传入图片url的key 调用DiskLruCache的edit方法获取Editor(如果缓存正在被编辑就会返回null),可以从Editor得到文件输出流,这样就可以写入到文件系统了。
缓存的获取,传入图片url的key 调用DiskLruCache的get方法 得到SnapShot,可从SnapShoty获取文件输入流,这样就用BitmapFactory得到bitmap了。
缓存的删除,DiskLruCache的remove方法可以删除key对应的缓存。
通过查看源码,发现LinkedHashMap内部也是维护了访问顺序的LinkedHashMap,原理上和LruCache是一致的。只是使用上有点点复杂,毕竟涉及文件的读写。
具体使用及注意点如下代码:
private void testDiskLruCache(String urlString) {
long maxSize = 5010241024;
try {
//一、创建DiskLruCache
//第一个参数是要存放的目录,这里选择外部缓存目录(若app卸载此目录也会删除);
//第二个是版本一般设1;第三个是缓存节点的value数量一般也是1;
//第四个是最大缓存容量这里取50M
mDiskLruCache = DiskLruCache.open(getExternalCacheDir(), 1, 1, maxSize);
//二、缓存的添加:1、通过Editor,把图片的url转成key,通过edit方法得到editor,然后获取输出流,就可以写到文件系统了。
DiskLruCache.Editor editor = mDiskLruCache.edit(hashKeyFormUrl(urlString));
if (editor != null) {
//参数index取0(因为上面的valueCount取的1)
OutputStream outputStream = editor.newOutputStream(0);
boolean downSuccess = downloadPictureToStream(urlString, outputStream);
if (downSuccess) {
//2、编辑提交,释放编辑器
editor.commit();
}else {
editor.abort();
}
//3、写到文件系统,会检查当前缓存大小,然后写到文件
mDiskLruCache.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
//三、缓存的获取
try {
String key = hashKeyFormUrl(urlString);
DiskLruCache.Snapshot snapshot = mDiskLruCache.get(key);
FileInputStream inputStream = (FileInputStream)snapshot.getInputStream(0);
// Bitmap bitmap = BitmapFactory.decodeStream(inputStream);
// mIvBitamp.setImageBitmap(bitmap);
//注意,一般需要采样加载,但文件输入流是有序的文件流,采样时两次decodeStream影响文件流的文职属性,导致第二次decode是获取是null
//为解决此问题,可用文件描述符
FileDescriptor fd = inputStream.getFD();
//采样加载(就是前面讲的bitmap的高效加载)
BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds=true;
BitmapFactory.decodeFileDescriptor(fd,null,options);
ViewGroup.LayoutParams layoutParams = mIvBitamp.getLayoutParams();
options.inSampleSize = getInSampleSize(layoutParams.width, layoutParams.height, options.outWidth, options.outHeight);
options.inJustDecodeBounds = false;
Bitmap bitmap = BitmapFactory.decodeFileDescriptor(fd, null, options);
//存入内容缓存,绘制到view。(下次先从内存缓存获取,没有就从磁盘缓存获取,在没有就请求网络–“三级缓存”)
mBitmapLruCache.put(key,bitmap);
runOnUiThread(new Runnable() {
@Override
public void run() {
mIvBitamp.setImageBitmap(mBitmapLruCache.get(key));
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
/**
- 下载图片到文件输入流
*/
private boolean downloadPictureToStream(String urlString, OutputStream outputStream) {
URL url = null;
HttpURLConnection urlConnection = null;
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
url = new URL(urlString);
urlConnection = (HttpURLConnection) url.openConnection();
in = new BufferedInputStream(urlConnection.getInputStream());
out = new BufferedOutputStream(outputStream);
int b;
while ((b=in.read()) != -1) {
//写入文件输入流
out.write(b);
}
return true;
} catch (IOException e) {
e.printStackTrace();
}finally {
if (urlConnection != null) {
urlConnection.disconnect();
}
try {
if (in != null) {in.close();}
if (out != null) {out.close();}
} catch (IOException e) {
e.printStackTrace();
}
}
return false;
}
/**
- 图片的url转成key,使用MD5
*/
private String hashKeyFormUrl(String url) {
try {
MessageDigest digest = MessageDigest.getInstance(“MD5”);
return byteToHexString(digest.digest(url.getBytes()));
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return null;
}
private String byteToHexString(byte[] bytes) {
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < bytes.length; i++) {
String hex = Integer.toHexString(0XFF & bytes[i]);
if (hex.length()==1) {
stringBuffer.append(0);
}
stringBuffer.append(hex);
}
return stringBuffer.toString();
}
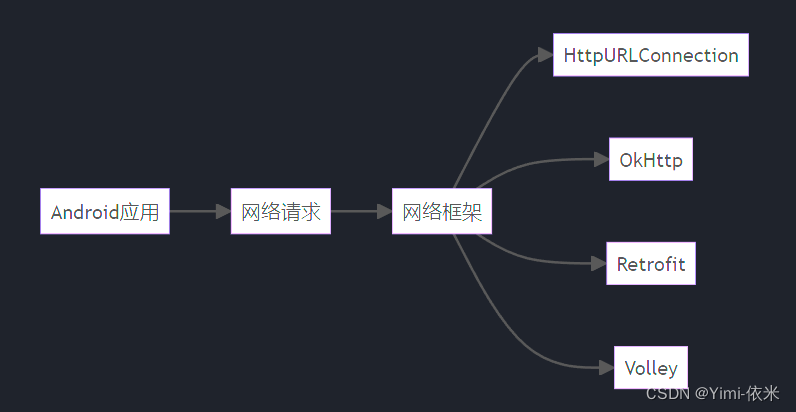
三、ImageLoader
=============
前面说的 Bitmap的高效加载、LruCache、DiskLruCache,是一个图片加载框架必备的功能点。下面就来封装一个ImageLoader。首先罗列 实现的要点:
- 图片压缩,就是采样加载
- 内存缓存,LruCache
- 磁盘缓存,DiskLruCache
- 网络获取,请求网络url
- 同步加载,外部子线程同步执行
- 异步加载,ImageLoader内部线程异步执行
说明,
”三级缓存“的逻辑:加载时 先从内存缓存获取,有就返回bitmap绘制图片到view,若没有就从磁盘缓存获取;磁盘缓存有就返回bitmap并缓存到内存缓存,没有就请求网络;网络请求回来,就缓存到磁盘缓存,然后从磁盘缓存获取返回。
同步加载,是在外部的子线程中执行,同步加载方法内部没有开线程,所以加载过程是耗时的 会阻塞 外部的子线程,加载完成后 需要自行切到主线程绘制到view。
异步加载,外部可在任意线程执行,因为内部实现是在子线程(线程池)加载,并且内部会通过Handler切到主线程,只需要传入view,内部就可直接绘制Bitmap到view。
详细如下
public class ImageLoader {
private static final String TAG = “ImageLoader”;
private static final long KEEP_ALIVE_TIME = 10L;
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
private static final int CORE_THREAD_SIZE = CPU_COUNT + 1;
private static final int THREAD_SIZE = CPU_COUNT * 2 + 1;
private static final int VIEW_TAG_URL = R.id.view_tag_url;
private static final Object object = new Object();
private ThreadPoolExecutor mExecutor;
private Handler mMainHandler;
private Context mApplicationContext;
private static volatile ImageLoader mImageLoader;
private LruCache<String, Bitmap> mLruCache;
private DiskLruCache mDiskLruCache;
/**
- 磁盘缓存最大容量,50M
*/
private static final long DISK_LRU_CACHE_MAX_SIZE = 50 * 1024 * 1024;
/**
- 当前进程的最大内存,取进程内存的1/8
*/
private static final long MEMORY_CACHE_MAX_SIZE = Runtime.getRuntime().maxMemory() / 8;
public ImageLoader(Context context) {
if (context == null) {
throw new RuntimeException(“context can not be null !”);
}
mApplicationContext = context.getApplicationContext();
initLruCache();
initDiskLruCache();
initAsyncLoad();
}
public static ImageLoader with(Context context){
if (mImageLoader == null) {
synchronized (object) {
if (mImageLoader == null) {
mImageLoader = new ImageLoader(context);
}
}
}
return mImageLoader;
}
private void initAsyncLoad() {
mExecutor = new ThreadPoolExecutor(CORE_THREAD_SIZE, THREAD_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS,
new LinkedBlockingQueue(), new ThreadFactory() {
private final AtomicInteger count = new AtomicInteger(1);
@Override
public Thread newThread(Runnable runnable) {
return new Thread(runnable, "load bitmap thread "+ count.getAndIncrement());
}
});
mMainHandler = new Handler(Looper.getMainLooper()){
@Override
public void handleMessage(@NonNull Message msg) {
LoadResult result = (LoadResult) msg.obj;
ImageView imageView = result.imageView;
Bitmap bitmap = result.bitmap;
String url = result.url;
if (imageView == null || bitmap == null) {
return;
}
//此判断是 避免 ImageView在列表中复用导致图片错位的问题
if (url.equals(imageView.getTag(VIEW_TAG_URL))) {
imageView.setImageBitmap(bitmap);
}else {
Log.w(TAG, “handleMessage: set image bitmap,but url has changed,ignore!”);
}
}
};
}
private void initLruCache() {
mLruCache = new LruCache<String, Bitmap>((int) MEMORY_CACHE_MAX_SIZE){
@Override
protected int sizeOf(String key, Bitmap value) {
//缓存对象bitmap的大小,单位要和MEMORY_CACHE_MAX_SIZE一致
return value.getByteCount();
}
@Override
protected void entryRemoved(boolean evicted, String key, Bitmap oldValue, Bitmap newValue) {
//移除旧缓存时会调用,可以在这里进行像资源回收的工作。
}
};
}
private void initDiskLruCache() {
File externalCacheDir = mApplicationContext.getExternalCacheDir();
if (externalCacheDir != null) {
long usableSpace = externalCacheDir.getUsableSpace();
if (usableSpace < DISK_LRU_CACHE_MAX_SIZE){
//剩余空间不够了
Log.e(TAG, “initDiskLruCache: “+“UsableSpace=”+usableSpace+” , not enough(target 50M),cannot creat diskLruCache!”);
return;
}
}
//一、创建DiskLruCache
//第一个参数是要存放的目录,这里选择外部缓存目录(若app卸载此目录也会删除);
//第二个是版本一般设1;第三个是缓存节点的value数量一般也是1;
//第四个是最大缓存容量这里取50M
try {
this.mDiskLruCache = DiskLruCache.open(mApplicationContext.getExternalCacheDir(), 1, 1, DISK_LRU_CACHE_MAX_SIZE);
} catch (IOException e) {
e.printStackTrace();
Log.e(TAG, "initDiskLruCache: "+e.getMessage());
}
}
/**
缓存bitmap到内存
@param url url
@param bitmap bitmap
*/
private void addBitmapMemoryCache(String url, Bitmap bitmap) {
String key = UrlKeyTransformer.transform(url);
if (mLruCache.get(key) == null && bitmap != null) {
mLruCache.put(key,bitmap);
}
}
/**
从内存缓存加载bitmap
@param url url
@return
*/
private Bitmap loadFromMemoryCache(String url) {
return mLruCache.get(UrlKeyTransformer.transform(url));
}
/**
从磁盘缓存加载bitmap(并添加到内存缓存)
@param url url
@param requestWidth 要求的宽
@param requestHeight 要求的高
@return bitmap
*/
private Bitmap loadFromDiskCache(String url, int requestWidth, int requestHeight) throws IOException {
if (Looper.myLooper()==Looper.getMainLooper()) {
Log.w(TAG, “loadFromDiskCache from Main Thread may cause block !”);
}
if (mDiskLruCache == null) {
return null;
}
DiskLruCache.Snapshot snapshot = null;
String key = UrlKeyTransformer.transform(url);
snapshot = mDiskLruCache.get(key);
if (snapshot != null) {
FileInputStream inputStream = (FileInputStream)snapshot.getInputStream(0);
//Bitmap bitmap = BitmapFactory.decodeStream(inputStream);
//一般需要采样加载,但文件输入流是有序的文件流,采样时两次decodeStream影响文件流的位置属性,
//导致第二次decode是获取是null,为解决此问题,可用文件描述符。
FileDescriptor fd = inputStream.getFD();
Bitmap bitmap = BitmapSampleDecodeUtil.decodeFileDescriptor(fd, requestWidth, requestHeight);
addBitmapMemoryCache(url,bitmap);
return bitmap;
}
return null;
}
/**
从网路加载图片 到磁盘缓存(然后再从磁盘中采样加载)
@param urlString urlString
@param requestWidth 要求的宽
@param requestHeight 要求的高
@return Bitmap
*/
private Bitmap loadFromHttp(String urlString, int requestWidth, int requestHeight) throws IOException {
//线程检查,不能是主线程
if (Looper.myLooper()==Looper.getMainLooper()) {
throw new RuntimeException(“Do not loadFromHttp from Main Thread!”);
}
if (mDiskLruCache == null) {
return null;
}
DiskLruCache.Editor editor = null;
editor = mDiskLruCache.edit(UrlKeyTransformer.transform(urlString));
if (editor != null) {
OutputStream outputStream = editor.newOutputStream(0);
if (downloadBitmapToStreamFromHttp(urlString, outputStream)) {
editor.commit();
}else {
editor.abort();
}
mDiskLruCache.flush();
}
return loadFromDiskCache(urlString, requestWidth, requestHeight);
}
/**
从网络下载图片到文件输入流
@param urlString
@param outputStream
@return
*/
private boolean downloadBitmapToStreamFromHttp(String urlString, OutputStream outputStream) {
URL url = null;
HttpURLConnection urlConnection = null;
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
url = new URL(urlString);
urlConnection = (HttpURLConnection) url.openConnection();
in = new BufferedInputStream(urlConnection.getInputStream());
out = new BufferedOutputStream(outputStream);
int b;
while ((b=in.read()) != -1) {
//写入文件输入流
out.write(b);
}
return true;
} catch (IOException e) {
e.printStackTrace();
Log.e(TAG, "downloadBitmapToStreamFromHttp,failed : "+e.getMessage());
}finally {
if (urlConnection != null) {
urlConnection.disconnect();
}
IoUtil.close(in);
IoUtil.close(out);
}
return false;
}
/**
从网络直接下载bitmap(无缓存、无采样)
@param urlString
@return
*/
private Bitmap downloadBitmapFromUrlDirectly(String urlString) {
URL url;
HttpURLConnection urlConnection = null;
BufferedInputStream bufferedInputStream = null;
try {
url = new URL(urlString);
urlConnection = (HttpURLConnection) url.openConnection();
bufferedInputStream = new BufferedInputStream(urlConnection.getInputStream());
return BitmapFactory.decodeStream(bufferedInputStream);
} catch (IOException e) {
e.printStackTrace();
Log.e(TAG, "downloadBitmapFromUrlDirectly,failed : "+e.getMessage());
}finally {
if (urlConnection != null) {
urlConnection.disconnect();
}
IoUtil.close(bufferedInputStream);
}
return null;
}
public Bitmap loadBitmap(String url){
return loadBitmap(url,0,0);
}
/**
- 同步 加载bitmap
作者2013年从java开发,转做Android开发,在小厂待过,也去过华为,OPPO等大厂待过,18年四月份进了阿里一直到现在。
参与过不少面试,也当面试官 面试过很多人。深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,不成体系的学习效果低效漫长,而且极易碰到天花板技术停滞不前!
我整理了一份阿里P7级别的最系统的Android开发主流技术,特别适合有3-5年以上经验的小伙伴深入学习提升。
主要包括阿里,以及字节跳动,腾讯,华为,小米,等一线互联网公司主流架构技术。如果你想深入系统学习Android开发,成为一名合格的高级工程师,可以收藏一下这些Android进阶技术选型
我搜集整理过这几年阿里,以及腾讯,字节跳动,华为,小米等公司的面试题,把面试的要求和技术点梳理成一份大而全的“ Android架构师”面试 Xmind(实际上比预期多花了不少精力),包含知识脉络 + 分支细节。

Java语言与原理;
大厂,小厂。Android面试先看你熟不熟悉Java语言

高级UI与自定义view;
自定义view,Android开发的基本功。

性能调优;
数据结构算法,设计模式。都是这里面的关键基础和重点需要熟练的。

NDK开发;
未来的方向,高薪必会。

前沿技术;
组件化,热升级,热修复,框架设计

网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。希望这份系统化的技术体系对大家有一个方向参考。
我在搭建这些技术框架的时候,还整理了系统的高级进阶教程,会比自己碎片化学习效果强太多,CodeChina上可见;
当然,想要深入学习并掌握这些能力,并不简单。关于如何学习,做程序员这一行什么工作强度大家都懂,但是不管工作多忙,每周也要雷打不动的抽出 2 小时用来学习。
不出半年,你就能看出变化!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
id开发主流技术,特别适合有3-5年以上经验的小伙伴深入学习提升。
主要包括阿里,以及字节跳动,腾讯,华为,小米,等一线互联网公司主流架构技术。如果你想深入系统学习Android开发,成为一名合格的高级工程师,可以收藏一下这些Android进阶技术选型
我搜集整理过这几年阿里,以及腾讯,字节跳动,华为,小米等公司的面试题,把面试的要求和技术点梳理成一份大而全的“ Android架构师”面试 Xmind(实际上比预期多花了不少精力),包含知识脉络 + 分支细节。
[外链图片转存中…(img-bOodJqkt-1714214786697)]
Java语言与原理;
大厂,小厂。Android面试先看你熟不熟悉Java语言
[外链图片转存中…(img-GxTNGRSR-1714214786697)]
高级UI与自定义view;
自定义view,Android开发的基本功。
[外链图片转存中…(img-Tr2i9l7D-1714214786698)]
性能调优;
数据结构算法,设计模式。都是这里面的关键基础和重点需要熟练的。
[外链图片转存中…(img-pahZyeOx-1714214786698)]
NDK开发;
未来的方向,高薪必会。
[外链图片转存中…(img-KnIBTPN5-1714214786698)]
前沿技术;
组件化,热升级,热修复,框架设计
[外链图片转存中…(img-5yY6ROos-1714214786699)]
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。希望这份系统化的技术体系对大家有一个方向参考。
我在搭建这些技术框架的时候,还整理了系统的高级进阶教程,会比自己碎片化学习效果强太多,CodeChina上可见;
当然,想要深入学习并掌握这些能力,并不简单。关于如何学习,做程序员这一行什么工作强度大家都懂,但是不管工作多忙,每周也要雷打不动的抽出 2 小时用来学习。
不出半年,你就能看出变化!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!