目录
一、模块module
1.1 模块module
模块是 Python 程序架构的一个核心概念。Python中模块就是一个.py文件,模块中可以定义函数,变量,类。模块可以被其他模块引用
1.2 创建模块文件
创建文件:utils.py
# 定义变量
name = '张三'
# 定义函数
def sum(a,b):
return a+b
# 定义类
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return 'name:{},age:{}'.format(self.name,self.age)1.3 导入模块中的gongn
在Python中,你可以使用 import 语句来导入模块中的功能。具体如何导入取决于你想要从模块中获取什么。
1. 导入整个模块
import module_name
# 使用模块中的功能
module_name.function_name()2. 导入模块中的特定功能
from module_name import function_name
# 直接使用功能
function_name()3. 导入模块中的所有功能(不推荐,因为可能会导致命名冲突
from module_name import *
# 直接使用功能
function_name()1.4 模块导入冲突
1. 部分导入冲突
当从多个模块中导入功能时,如果两个模块都定义了相同名称的功能或变量,就可能会发生命名冲突。以下是一个简单的示例,展示了如何导致这种冲突:
假设我们有两个模块,module_a.py 和 module_b.py,它们都定义了一个名为 same_function 的函数:
module_a.py:
def same_function():
return "This is the function from module_a."module_b.py:
def same_function():
return "This is the function from module_b."现在,如果我们尝试在一个脚本中从这两个模块中导入 same_function,并且不使用别名(aliasing),就会导致命名冲突:
from module_a import same_function
from module_b import same_function
# 调用 same_function 会导致不明确,因为Python不知道要调用哪一个
result = same_function()
print(result) # 这里会抛出异常,因为same_function被定义了两次 运行上述代码时,Python解释器会抛出一个 NameError,因为它不知道在调用 same_function() 时应该使用哪个模块中的定义。
为了避免这种冲突,我们可以使用别名来导入功能:
from module_a import same_function as function_a
from module_b import same_function as function_b
# 现在我们可以明确调用每个模块中的函数
result_a = function_a()
result_b = function_b()
print(result_a) # 输出: This is the function from module_a.
print(result_b) # 输出: This is the function from module_b.使用别名可以确保我们清楚地知道我们正在调用哪个模块中的功能,从而避免命名冲突。
2. 全部导入冲突
当使用 from module import * 语句时,如果两个模块都定义了相同名称的变量或函数,那么全部导入这些模块将会导致命名冲突。以下是一个示例,展示了如何导致这种冲突:
假设我们有两个模块,module_a.py 和 module_b.py,它们都定义了一个名为 conflict_variable 的变量:
module_a.py:
conflict_variable = "This is the variable from module_a."module_b.py:
conflict_variable = "This is the variable from module_b."现在,如果我们尝试在一个脚本中全部导入这两个模块,将会导致命名冲突:
from module_a import *
from module_b import *
# 尝试访问 conflict_variable 会导致不明确,因为两个模块都定义了它
print(conflict_variable) # 这里的行为是不确定的,可能会抛出异常或者输出一个模块的值,取决于解释器的加载顺序和内部实现细节在这种情况下,print(conflict_variable) 的输出是不确定的,因为它取决于Python解释器加载模块的顺序。在某些情况下,它可能会输出 module_a 中的值,而在其他情况下可能会输出 module_b 中的值。更糟糕的是,有些解释器可能会抛出一个异常,因为两个模块都定义了 conflict_variable。
为了避免冲突,我们可以这样导入:
import module_a
import module_b
# 使用模块名作为前缀来访问变量,避免了命名冲突
print(module_a.conflict_variable) # 输出: This is the variable from module_a.
print(module_b.conflict_variable) # 输出: This is the variable from module_b.或者,如果我们需要频繁使用这些变量,并且不想在每次引用时都加上模块名前缀,我们可以给它们起别名:
import module_a as mod_a
import module_b as mod_b
# 使用别名来访问变量
print(mod_a.conflict_variable) # 输出: This is the variable from module_a.
print(mod_b.conflict_variable) # 输出: This is the variable from module_b.通过显式地导入并使用模块名或别名,我们可以确保代码中不会发生命名冲突,并且每个变量或函数都来自其定义的模块,这使得代码更加清晰和易于理解。
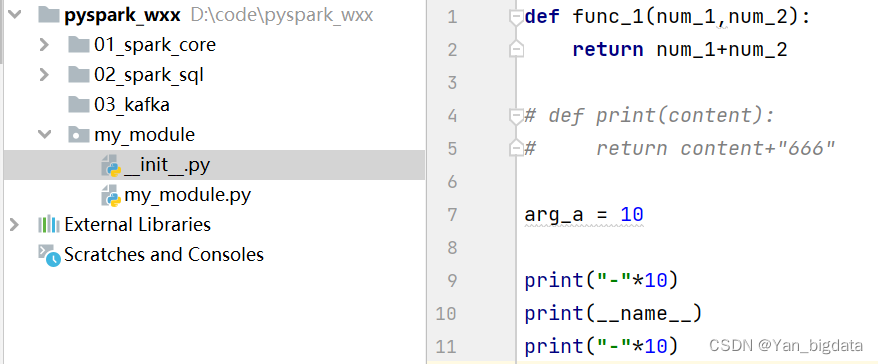
1.5 3. 模块的内置变量__name__
在Python中,每个模块都有一个内置变量 __name__,这个变量可以用来判断当前模块是被直接运行还是被其他模块导入。当模块被直接运行时,__name__ 的值会被设置为 '__main__';当模块被导入时,__name__ 的值则会被设置为该模块的名字。
以下是一个简单的模块示例,它展示了如何使用 __name__ 变量:
假设我们有一个名为 my_module.py 的模块:
# my_module.py
# 定义一些函数或变量
def my_function():
print("This is a function in my_module.")
my_variable = "This is a variable in my_module."
# 使用 __name__ 变量来判断模块是如何被使用的
if __name__ == '__main__':
print("my_module is being run directly")
my_function()
print(my_variable)
else:
print("my_module has been imported into another module")现在,我们来看看如何直接运行这个模块和从另一个模块中导入它:
直接运行 my_module.py:
python my_module.py输出:
my_module is being run directly
This is a function in my_module.
This is a variable in my_module.
从另一个模块导入 my_module:
首先,我们创建一个新的Python脚本 another_module.py:
# another_module.py
import my_module
# 使用 my_module 中定义的函数或变量
my_module.my_function()
print(my_module.my_variable)从另一个模块导入 my_module:
首先,我们创建一个新的Python脚本 another_module.py:
# another_module.py
import my_module
# 使用 my_module 中定义的函数或变量
my_module.my_function()
print(my_module.my_variable)然后运行 another_module.py:
python another_module.py输出:
my_module has been imported into another module
This is a function in my_module.
This is a variable in my_module.
通过使用 __name__ 变量,我们可以控制模块在被直接运行和被导入时的行为。这在编写可重用的库或模块时特别有用,因为它允许我们为模块的使用者提供清晰的接口,同时仍然能够测试模块自身的功能。
1. __name__的特点
- 如果将当前模块作为启动项,
__name__值为__main__ - 如果当前模块当作依赖引入,
__name__值不为__main__,为依赖的模块名称
2.__name__的作用
python没有入口函数的概念,可以通过__name__的功能
def sum(m,n):
return m+n
if __name__ == '__main__':
a = 10
b =20
result = sum(a,b)
print(result)主程序的代码放在if __name__ == '__main__':里。这样当前模块即可以独立测试运行,也可以被其他文件导入使用。如果不添加此if判断,别的地方导入当前文件模块时,会运行一些不需要的代码。
二、包 package
包就是个文件夹,用来放模块的,限定了模块的命名空间
1.1 包的作用
- 用来管理模块的
- 让业务更清晰化
- 解决一些命名的问题
network包:可以用来管理网络访问
cart模块中,可以提供购物车的增删改查功能
product中,可以提供商品的查看功能
user模块中,可以提供登录,注册等功能storage包:可以用来管理本地存储
cart模块中,可以提供购物车存储功能
product中,可以提供商品存储功能
user模块中,可以提供用户信息存储功能
通过包把类似功能的模块进行分类,让业务更加清晰
1.2 引入包中模块的功能方法一
import 包名.模块名
import pkg.hello
#访问模块中的属性
print(pkg.hello.name)
#访问模块中的函数
pkg.hello.say()
#访问模块中的类
nice = pkg.hello.Nice()1.3 引入包中模块的功能方法二(推荐)
from 包名 import 模块名
from pkg import hello
#访问模块中的属性
print(hello.name)
#访问模块中的函数
hello.say()
#访问模块中的类
nice = hello.Nice()1.4 引入包中模块的功能方法三(推荐)
from 包名.模块名 import 变量,函数,类
from pkg.hello import name
from pkg.hello import say
from pkg.hello import Nice
#访问模块中的属性
print(name)
#访问模块中的函数
say()
#访问模块中的类
nice = Nice()1.5. 引入包中模块的功能方法四
from 包名.模块名 import *
from pkg.hello import *
#访问模块中的属性
print(name)
#访问模块中的函数
say()
#访问模块中的类
nice = Nice()三、异常
1. 什么是异常?
当Python检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常"
2. 捕获异常 try...except...
在Python中,你可以使用try...except...语句来捕获和处理异常。
格式:
try:
代码
except:
出现异常的代码try:
# 代码:这里写可能会抛出异常的代码
x = 10 / 0 # 这行代码会引发一个 ZeroDivisionError 异常
print("计算成功,结果是:", x)
except:
# 出现异常的代码:这里写处理异常的代码
print("发生了一个异常,无法完成计算")在这个例子中:
try块包含可能会抛出异常的代码。在这个例子中,我们尝试执行一个除以零的操作,这会导致ZeroDivisionError异常。except块用于捕获try块中抛出的任何异常。这里我们使用了不带异常类型的except,它会捕获所有类型的异常。在实际应用中,最好指定具体的异常类型,以便更精确地处理异常。- 如果
try块中的代码成功执行,那么将打印出计算的结果。如果发生异常,那么控制流将跳转到except块,执行处理异常的代码。
3. finally
try语句中使用finally,finally中代码不论有没有出现异常都会执行
格式:
try:
逻辑代码
finally:
无论是否出现异常,都会执行示例:
try:
# 逻辑代码:这里写可能会抛出异常的代码
result = some_function_that_might_fail()
print("逻辑代码执行成功,结果是:", result)
# 其他逻辑代码...
finally:
# 无论是否出现异常,都会执行这个代码块
print("finally 块总是会被执行")
# 清理资源或执行其他必要的操作在这个例子中:
try块包含可能会抛出异常的逻辑代码。some_function_that_might_fail()是一个假设的函数,它可能由于各种原因而失败并抛出异常。finally块包含的代码无论try块中的代码是否成功执行,或者是否抛出异常,都会执行。这是执行清理任务或确保某些操作总是发生的好地方。
请注意,如果没有 except 块来捕获异常,那么如果在 try 块中发生异常,它将会“冒泡”到更高级别的异常处理代码(如果有的话),或者如果没有进一步的处理,程序将会终止并打印出未处理的异常信息。
4. try except finally语法
格式:
try:
逻辑代码
except Exception as error:
print(error)
finally:
无论是否出现异常,都会执行示例:
try:
# 逻辑代码:这里写可能会抛出异常的代码
result = some_function_that_might_fail()
# 其他逻辑代码...
print("逻辑代码执行成功")
except Exception as error:
# 出现异常时执行的代码
print(f"捕获到异常: {error}")
# 异常处理逻辑,比如记录日志、回滚事务等...
finally:
# 无论是否出现异常,都会执行的代码
print("finally 块总是会被执行")
# 清理资源或执行其他必要的操作,比如关闭文件、释放网络连接等...在这个示例中:
try块包含了可能会抛出异常的逻辑代码。some_function_that_might_fail()是一个假设的函数,它可能由于各种原因(如输入错误、资源不足等)而失败并抛出异常。except块捕获了在try块中抛出的任何异常,并打印出异常信息。这里使用Exception作为异常类型,意味着它会捕获所有从Exception类派生的异常。根据实际需要,您可以捕获更具体的异常类型。finally块包含的代码无论try块是否成功执行,或者except块是否捕获了异常,都会执行。这是执行清理任务或确保某些操作总是发生的好地方。
请注意,无论是否发生异常,finally 块中的代码都会被执行。
5. try except else finally语法
格式:
try:
逻辑代码
except Exception as error:
print(error)
else:
没有出现异常的逻辑
finally:
无论是否出现异常,都会执行示例:
try:
# 逻辑代码:这里写可能会抛出异常的代码
x = 1 / 0 # 这行代码会抛出 ZeroDivisionError 异常
except Exception as error:
# 出现异常时执行的代码
print(f"捕获到异常: {error}")
else:
# 没有出现异常时执行的代码
print("没有出现异常,执行 else 块的代码")
finally:
# 无论是否出现异常,都会执行的代码
print("finally 块总是会被执行")在这个示例中:
try块尝试执行x = 1 / 0,这会导致ZeroDivisionError异常。except块捕获了这个异常,并打印出异常信息。- 因为
try块中出现了异常,所以else块中的代码不会被执行。 - 无论是否出现异常,
finally块中的代码都会被执行。
输出:
捕获到异常: division by zero
finally 块总是会被执行
注意,else 块在 try 块成功执行后才会执行,即没有抛出任何异常。而 finally 块无论 try 或 except 块执行与否,都会执行。


























![[极客大挑战 2019]Upload、[ACTF2020 新生赛]Upload、[MRCTF2020]你传你呢](https://img-blog.csdnimg.cn/direct/cd6d22f8ba094f1f9ce988651c93e034.png)
![[C++/STL]模板进阶](https://img-blog.csdnimg.cn/direct/275222cca3ed4689b26959c8b0405ea9.png)