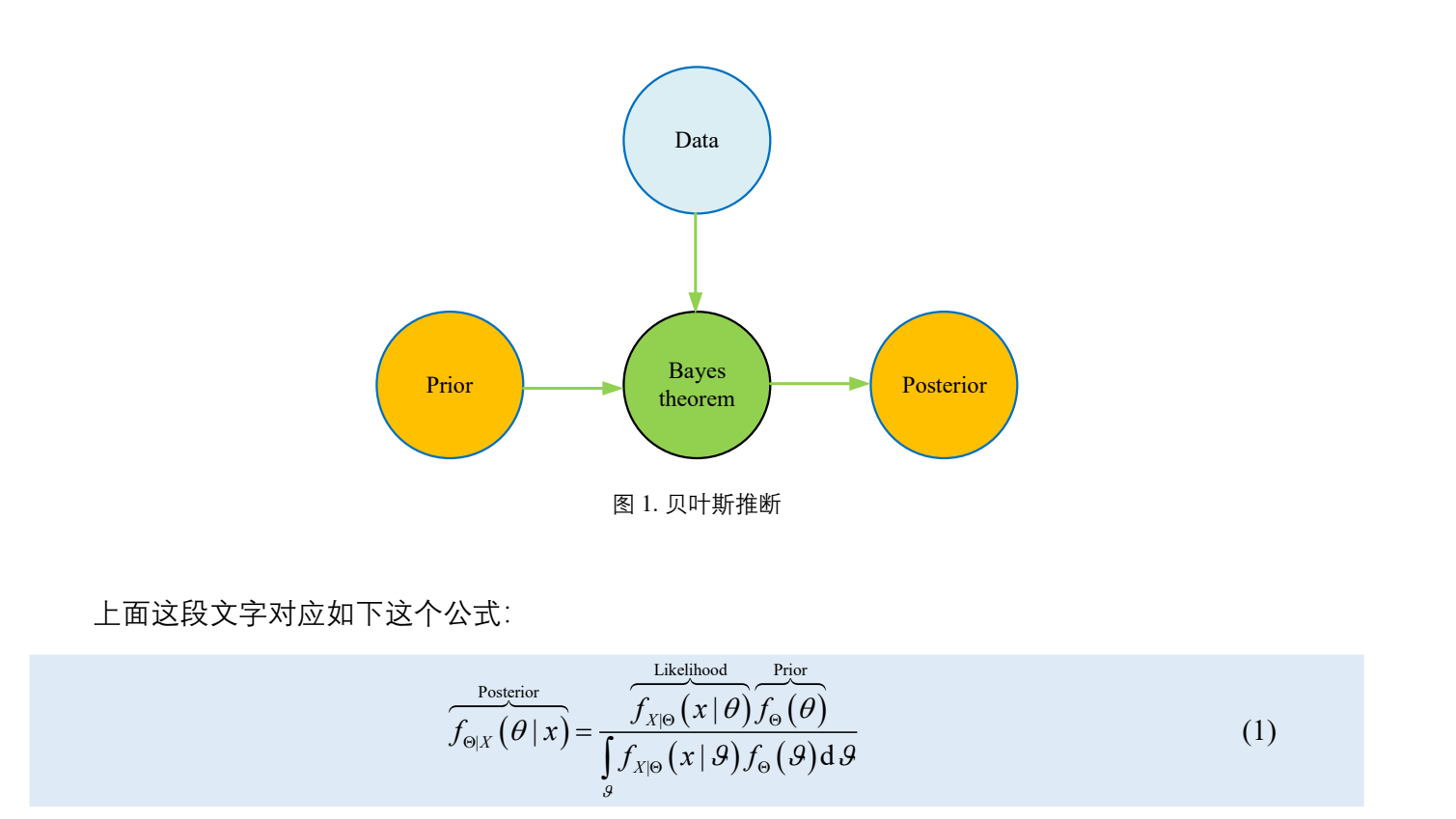
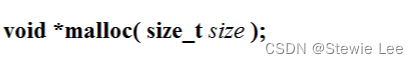贝叶斯后验之旅总结之旅
一、说明
这篇博文深入探讨了贝叶斯统计的核心概念,包括后验分布、点估计和损失函数。我们将探讨如何使用网格近似、百分位区间和最高后验密度区间 (HPDI) 来总结后验分布,并讨论选择正确的损失函数以做出最佳决策的重要性。
我们将继续探索理查德·麦克勒斯 (Richard McElreath) 的伟大著作《统计反思》。
在罕见情况下阳性结果的误导性:了解罕见病症的悖论:为什么大多数阳性检测结果可能具有误导性blog.stackademic.com
网格近似后验是贝叶斯推理中使用的一种方法,用于近似模型参数的后验分布。
二、网格化近似
将网格近似后验视为一种在看到一些数据后理解我们的参数可能是什么的方法,尤其是当数学变得太棘手时。想象一下,我们有一个网格或一组框,每个框代表对参数的不同猜测。然后,我们看到每个猜测基于我们拥有的数据和我们最初的信念的可能性有多大。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
def posterior_grid_approx(grid_points=5, success=6, tosses=9):
# define grid
p_grid = np.linspace(0, 1, grid_points)
# define prior
prior = np.repeat(5, grid_points) # uniform
# compute likelihood at each point in the grid
likelihood = stats.binom.pmf(success, tosses, p_grid)
# compute product of likelihood and prior
unstd_posterior = likelihood * prior
# standardize the posterior, so it sums to 1
posterior = unstd_posterior / unstd_posterior.sum()
return p_grid, posterior
该函数使用网格近似方法近似二项式似然的后验分布。posterior_grid_approx
我们可以生成 10,000 个样本,从这个后验中抽取二项式似然,使用 100 个网格点在 9 次抛掷中成功 6 次。
p_grid, posterior = posterior_grid_approx(grid_points=100, success=6, tosses=9)
p_grid
"""
array([0. , 0.01010101, 0.02020202, 0.03030303, 0.04040404,
0.05050505, 0.06060606, 0.07070707, 0.08080808, 0.09090909,
0.1010101 , 0.11111111, 0.12121212, 0.13131313, 0.14141414,
0.15151515, 0.16161616, 0.17171717, 0.18181818, 0.19191919,
0.2020202 , 0.21212121, 0.22222222, 0.23232323, 0.24242424,
0.25252525, 0.26262626, 0.27272727, 0.28282828, 0.29292929,
0.3030303 , 0.31313131, 0.32323232, 0.33333333, 0.34343434,
0.35353535, 0.36363636, 0.37373737, 0.38383838, 0.39393939,
0.4040404 , 0.41414141, 0.42424242, 0.43434343, 0.44444444,
0.45454545, 0.46464646, 0.47474747, 0.48484848, 0.49494949,
0.50505051, 0.51515152, 0.52525253, 0.53535354, 0.54545455,
0.55555556, 0.56565657, 0.57575758, 0.58585859, 0.5959596 ,
0.60606061, 0.61616162, 0.62626263, 0.63636364, 0.64646465,
0.65656566, 0.66666667, 0.67676768, 0.68686869, 0.6969697 ,
0.70707071, 0.71717172, 0.72727273, 0.73737374, 0.74747475,
0.75757576, 0.76767677, 0.77777778, 0.78787879, 0.7979798 ,
0.80808081, 0.81818182, 0.82828283, 0.83838384, 0.84848485,
0.85858586, 0.86868687, 0.87878788, 0.88888889, 0.8989899 ,
0.90909091, 0.91919192, 0.92929293, 0.93939394, 0.94949495,
0.95959596, 0.96969697, 0.97979798, 0.98989899, 1. ])
"""
posterior
"""
array([0.00000000e+00, 8.74189399e-12, 5.42528410e-10, 5.99057536e-09,
3.26180559e-08, 1.20539919e-07, 3.48564903e-07, 8.50900993e-07,
1.83481131e-06, 3.59840377e-06, 6.54782899e-06, 1.12132482e-05,
1.82630178e-05, 2.85156172e-05, 4.29489252e-05, 6.27065231e-05,
8.91007750e-05, 1.23612501e-04, 1.67887126e-04, 2.23727245e-04,
2.93081602e-04, 3.78030539e-04, 4.80768017e-04, 6.03580362e-04,
7.48821920e-04, 9.18887872e-04, 1.11618447e-03, 1.34309701e-03,
1.60195585e-03, 1.89500088e-03, 2.22434480e-03, 2.59193562e-03,
2.99951879e-03, 3.44859945e-03, 3.94040517e-03, 4.47584972e-03,
5.05549822e-03, 5.67953423e-03, 6.34772923e-03, 7.05941481e-03,
7.81345817e-03, 8.60824124e-03, 9.44164393e-03, 1.03110317e-02,
1.12132482e-02, 1.21446127e-02, 1.31009234e-02, 1.40774660e-02,
1.50690287e-02, 1.60699232e-02, 1.70740117e-02, 1.80747408e-02,
1.90651815e-02, 2.00380761e-02, 2.09858908e-02, 2.19008754e-02,
2.27751286e-02, 2.36006690e-02, 2.43695124e-02, 2.50737535e-02,
2.57056525e-02, 2.62577258e-02, 2.67228404e-02, 2.70943107e-02,
2.73659977e-02, 2.75324082e-02, 2.75887956e-02, 2.75312582e-02,
2.73568360e-02, 2.70636032e-02, 2.66507566e-02, 2.61186963e-02,
2.54690989e-02, 2.47049804e-02, 2.38307468e-02, 2.28522314e-02,
2.17767151e-02, 2.06129287e-02, 1.93710342e-02, 1.80625825e-02,
1.67004446e-02, 1.52987144e-02, 1.38725784e-02, 1.24381506e-02,
1.10122688e-02, 9.61224806e-03, 8.25558917e-03, 6.95963658e-03,
5.74118309e-03, 4.61601646e-03, 3.59840377e-03, 2.70050896e-03,
1.93173875e-03, 1.29801213e-03, 8.00948225e-04, 4.36967276e-04,
1.96299173e-04, 6.18938789e-05, 8.22780069e-06, 0.00000000e+00])
"""
samples = np.random.choice(p_grid, p=posterior, size=int(1e4), replace=True)
samples
"""
array([0.70707071, 0.63636364, 0.64646465, ..., 0.74747475, 0.62626263,
0.43434343])
"""
三、操作详细
以下是我们对代码所做的操作:
- 设置网格:我们创建了一个可能的值列表,用于在抛硬币中成功获得概率(如 0%、10%、…、100%)。
- 计算几率:我们根据在 9 次投掷中看到 6 个正面来计算出每个概率的可能性。
结合我们的初始猜测:我们将这些机会与最初的猜测(先前)相结合,即所有概率的可能性都相同。 - 归一化:我们调整了这些组合机会,使它们加起来达到 100%,为我们提供了关于获得头部概率的最新信念(后验)。
- 从我们的信念中抽取样本:然后,我们从更新的信念中随机挑选了 10,000 个值,这给了我们一堆样本,这些样本代表了我们对获得头部概率的不确定性。
- 简而言之,我们使用了一些数据(9 次投掷 6 个正面)来更新我们对抛硬币获得正面概率的信念,然后我们生成了一堆样本来代表我们更新的信念。
让我们绘制这些信念:
_, (ax0, ax1) = plt.subplots(1,2, figsize=(12,6))
ax0.plot(samples, 'o', alpha=0.2)
ax0.set_xlabel('sample number', fontsize=14)
ax0.set_ylabel('proportion toss (p)', fontsize=14)
sns.kdeplot(samples, ax=ax1)
ax1.set_xlabel('proportion toss (p)', fontsize=14)
ax1.set_ylabel('density', fontsize=14);
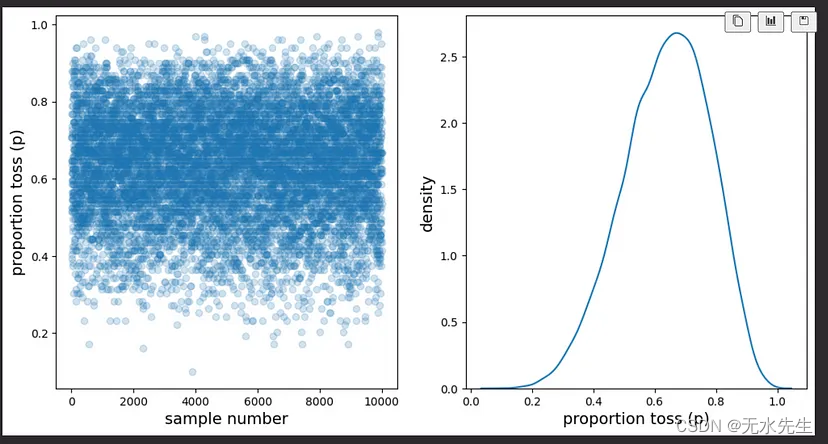
在此图中,您从上方查看后验分布,在 0.6 附近有更多的样本,而在 0.25 以下的样本更少。右侧显示了这些样本的密度估计值。
我们可以根据从网格近似或从该分布中抽取的样本获得的后验分布来计算某些事件的概率。
例如,我们可能想知道抛掷比例小于 0.5 的概率。
sum(posterior[ p_grid < 0.5 ])
"""
0.17183313110747472
"""
当我们的模型更复杂时,我们改用样本。我们计算有多少样本低于该数字,然后除以样本总数得到概率。
sum( samples < 0.5 ) / 1e4
"""
gives a similar result to the grid approximation.
0.1702
"""
# We can use the same approach to calculate the probability
# that the parameter falls within other intervals.
sum((samples > 0.5) & (samples < 0.75)) / 1e4
"""
0.608
"""
兼容性区间是与我们的数据和模型一致的值范围。它包含总概率的一定百分比,向我们显示真实参数值可能下降的位置。与使用网格近似相比,使用后验分布的样本更容易找到这些区间。
# Calculate the 95% compatibility interval
lower_bound = np.percentile(samples, 2.5)
upper_bound = np.percentile(samples, 97.5)
# Plotting
plt.hist(samples, bins=50, density=True, alpha=0.7, label='Posterior samples')
plt.axvline(lower_bound, color='red', linestyle='--', label=f'Lower bound ({lower_bound:.3f})')
plt.axvline(upper_bound, color='green', linestyle='--', label=f'Upper bound ({upper_bound:.3f})')
plt.title('Posterior Distribution with 95% Compatibility Interval')
plt.xlabel('Proportion of Toss')
plt.ylabel('Density')
plt.legend()
plt.show()
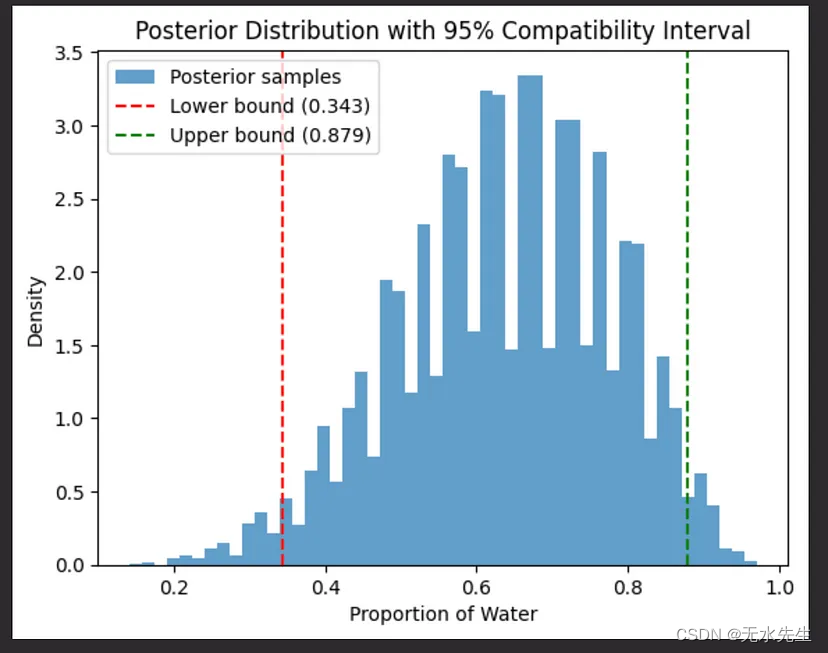
这是具有 95% 兼容区间的后验分布图。直方图表示样本从后部分布,虚线表示区间的下限和上限。在本例中,我们有 95% 的置信度,即抛掷的真实比例介于红线和绿线之间。
百分位区间 (PI) 是汇总分布的常用方法,将其分成相等的部分。例如,50% 的 PI 将 25% 的数据放在每侧,显示中间的 50%。如果分布不太倾斜,它们有利于显示分布的形状。然而,它们并不完美;在偏态分布中,它们可能会错过最可能的值。因此,虽然 PI 很有帮助,但它们也有局限性,尤其是在数据偏斜的情况下。
p_grid, posterior = posterior_grid_approx(success=4, tosses=4)
plt.plot(p_grid, posterior)
plt.xlabel('proportion toss (p)', fontsize=14)
plt.ylabel('Density', fontsize=14);
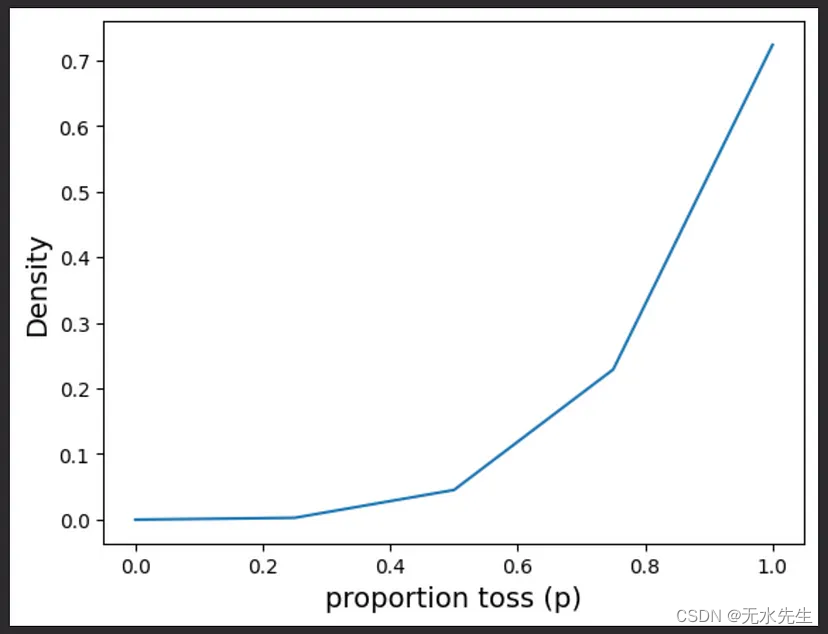
让我们近似一个特定场景的后验分布,其中我们在 4 次投掷中有 4 次成功。这是高度偏斜的,其最大值位于边界 (p = 1)。
在这种情况下,50% PI 可能会排除 p = 1 附近最可能的参数值,这在描述后验分布的形状方面可能会产生误导。
最高后验密度区间 (HPDI) 是一个范围,其中包含来自后验分布的最可能值。它是覆盖指定概率量的最窄区间,专注于分布的最密集部分。例如,50% HPDI 表示最可能的 50% 参数值。
import arviz as az
samples = np.random.choice(p_grid, p=posterior, size=int(1e4), replace=True)
# Calculate the 50% HPDI
hpdi_interval = az.hdi(samples, hdi_prob=0.5)
点估计值是用于汇总后验分布的单个值。最大后验 (MAP) 估计值是一种常见类型,表示最可能的参数值。但是,使用点估计可能会过度简化结果,因为它们无法捕获后验分布的完整信息。
p_grid[posterior == max(posterior)]
# array([1.])
四、结论
要从后验分布中选择点估计值(如众数、均值或中位数),可以使用损失函数,该函数衡量出错的代价。例如,如果您的损失是基于您的估计值与真实值的相差程度,则后验分布的中位数通常是最小化预期损失的最佳选择。不同的损失函数可能导致不同的首选点估计值。
选择后验分布的点估计值取决于您选择的损失函数,不同的损失函数会导致不同的估计值(例如,中位数或平均值)。损失函数的选择应以您正在做出的决策的特定背景为指导。在某些情况下,甚至可能不需要点估计。重要的是要传达完整的后验分布、数据和模型,以支持明智的决策,而不是仅仅依赖单点估计。