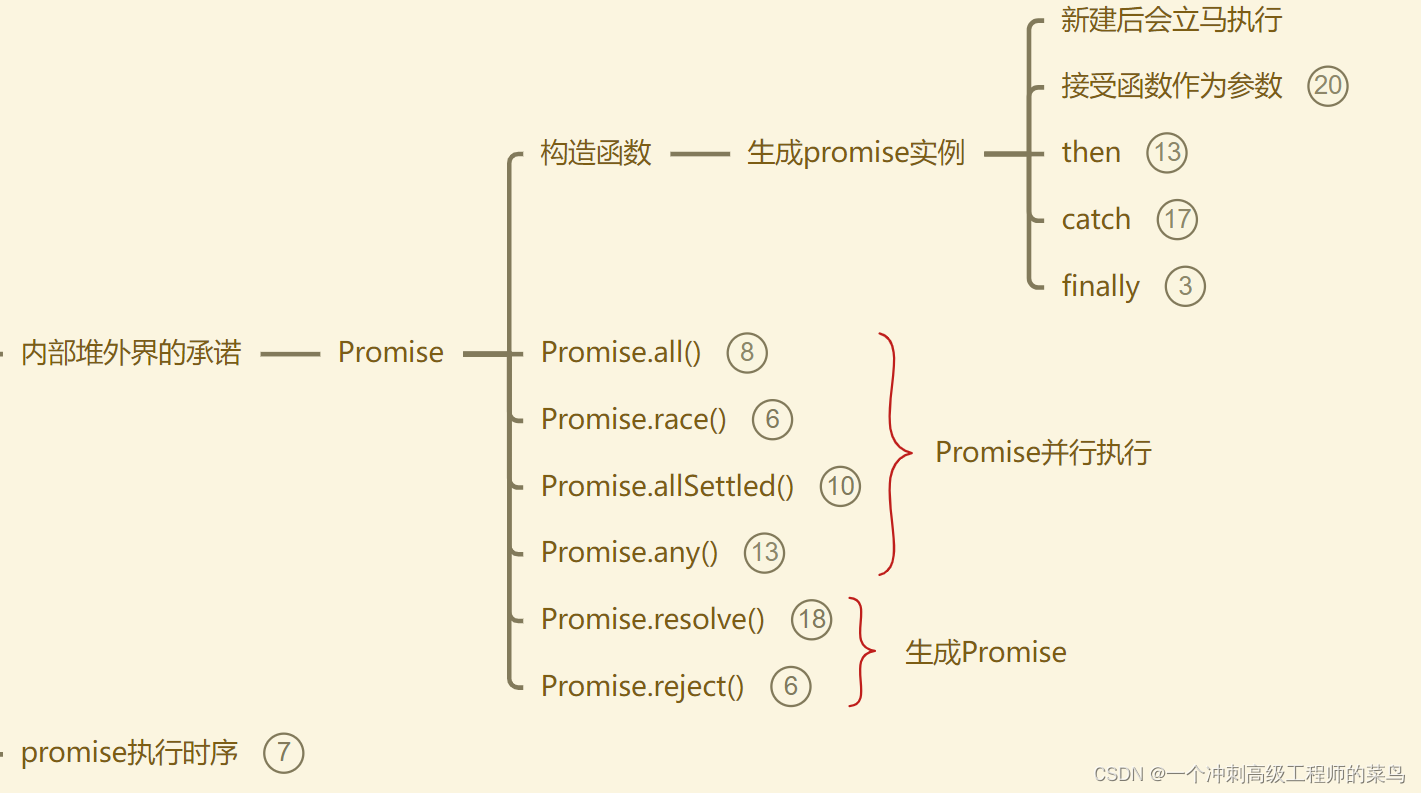
一直以为csv靠逗号(,)分割数据,那么只要用str.spilt(',',row)便可以将数据分割开。
事实证明想简单了,csv里还有这样的规定,如果数据内有双引号(")和逗号(,)那么,数据就要用双引号括起来,而双引号要替换两个双引号。
比如说数据是: hello,world,那么他在csv里应该表达为:"hello,world"
数据是: say "hello",那么他在csv里就应该是"say ""hello"""
这样就使得解析的时候没法直接用split函数。
根据规则解析应该符合以下状态图:
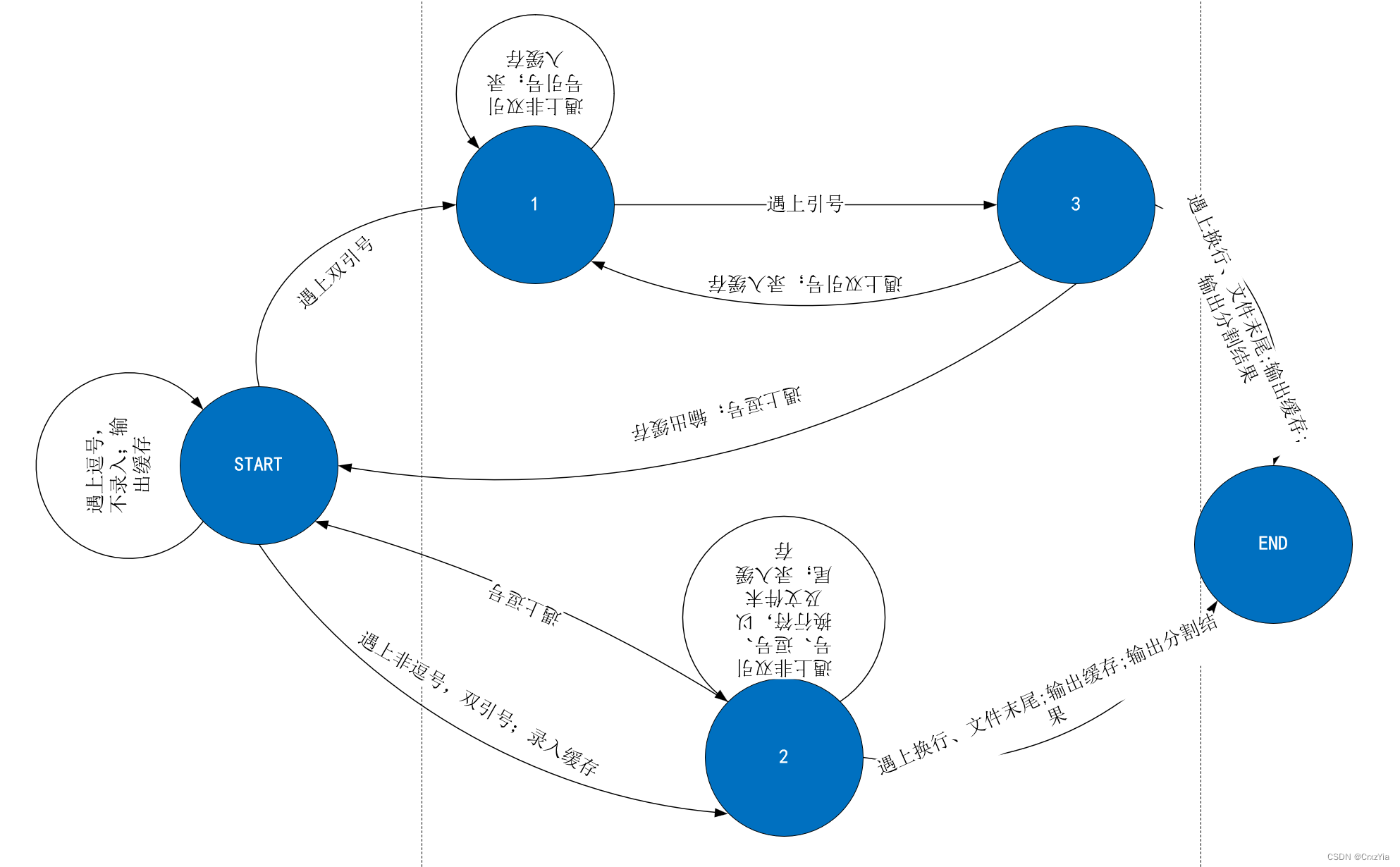
(有些字倒,将就看吧)
那么使用python实现便是:
class CsvInterpreter:
_lines = {"0": {"quot": ("1", False), "other": ("2", True)},
"1": {"other": ("1", True), "quot": ("3", False), "comma": ("1", True)},
"2": {"other": ("2", True), "comma": ("0", False), "enter": ("4", False)},
"3": {"quot": ("1", True), "comma": ("0", False), "enter": ("4", False)},
"5": {"comma": ("0", False), "enter": ("4", False)}}
def _init(self):
self._chars = ""
self._current_status = "0"
self._buffer = ""
self._container = []
def __init__(self):
self._buffer = None
self._chars = None
self._container = None
self._current_status = None
self._init()
def _next(self, char: str) -> None:
if char == '"':
cond = "quot"
elif char == ',':
cond = "comma"
elif char == '\n':
cond = "enter"
else:
cond = "other"
if cond not in self._lines[self._current_status]:
raise ValueError("格式不正确", self._chars, self._container, self._buffer, self._current_status, cond, char)
else:
next_status, if_input = self._lines[self._current_status][cond]
self._current_status = next_status
if if_input:
self._buffer += char
def split(self, line: str) -> list:
self._init()
self._chars = line
for char in line:
self._next(char)
if self._current_status in ["0", "4"]:
self._container.append(self._buffer)
self._buffer = ""
if self._current_status == "4":
return self._container
if self._current_status not in ["3", "4"]:
raise ValueError("格式不正确")
self._container.append(self._buffer)
return self._container运行:
csv_interpreter = CsvInterpreter()
with open('*.csv','r',encoding='utf-8') as f:
for line in f.readlines():
row = csv_interpreter.split(line)
print(row)