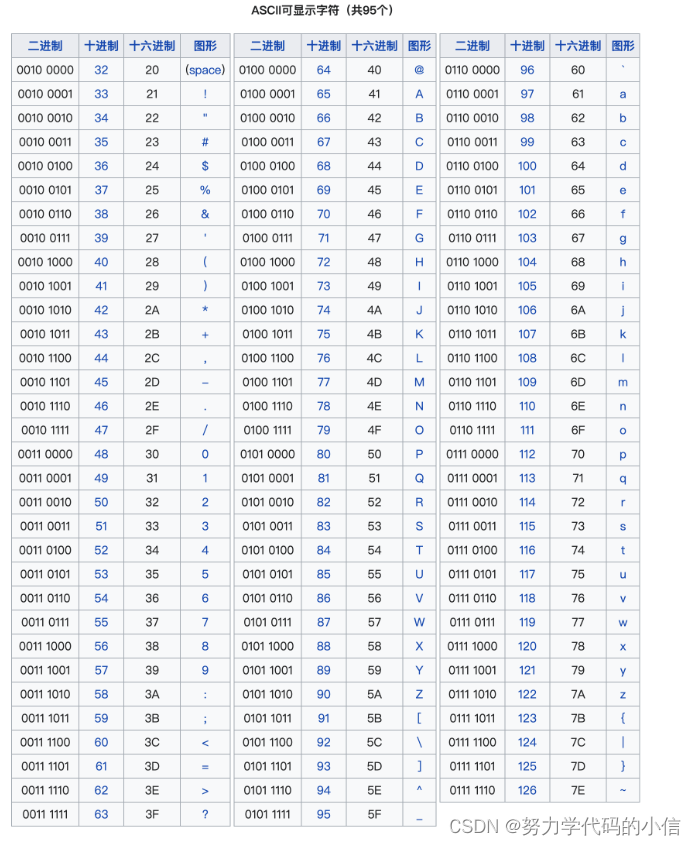
我们求字符串长度的时候一般使用len(s),但如果对含中文的字符串使用,长度会不符合我们的预期。
package main
import (
"fmt"
)
func main() {
const s = "你好,中文!"
fmt.Println(len(s))
}
结果如下:
18
但是字符串中只有6个字符。
这是因为在Go语言中,字符串是不可变的字节序列,而在UTF-8编码中,一个中文字符通常由多个字节表示。
实验代码:
package main
import (
"fmt"
)
func main() {
const s = "你好,中文!"
fmt.Println(s)
for i := 0; i < len(s); i++ {
fmt.Print(s[i], " ")
}
fmt.Println()
}
结果如下:
你好,中文!
228 189 160 229 165 189 239 188 140 228 184 173 230 150 135 239 188 129
如果我们想正确求出含中文的字符串的长度,那么我们需要使用unicode/utf8库的RuneCountInString(s)。
示例如下:
package main
import (
"fmt"
// 导入unicode/utf8
"unicode/utf8"
)
func main() {
const s = "你好,中文!"
// 计算字符长度
fmt.Println("Rune Count:", utf8.RuneCountInString(s))
}
结果:
Rune Count: 6
这里的Rune是Go中字符的概念,可以查看Strings, bytes, runes and characters in Go进一步了解。
如果想提取字符,可以将字符串string类型的变量转为rune类型的切片。
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
const s = "你好,中文!"
firstRune := []rune(s)
fmt.Printf("%c\n", firstRune[:2])
fmt.Printf("%c\n", firstRune[2])
}
结果:
[你 好]
好