一、模型文件(Checkpoint)
首先它很大,这些文件是你从huggingface或者civitai下载而来的,
所以这些大文件如 .ckpt 或 .safetensors ,实际上包含了什么内容呢?
它包含了包含了三种不同模型的权重:CLIP、主模型和VAE。

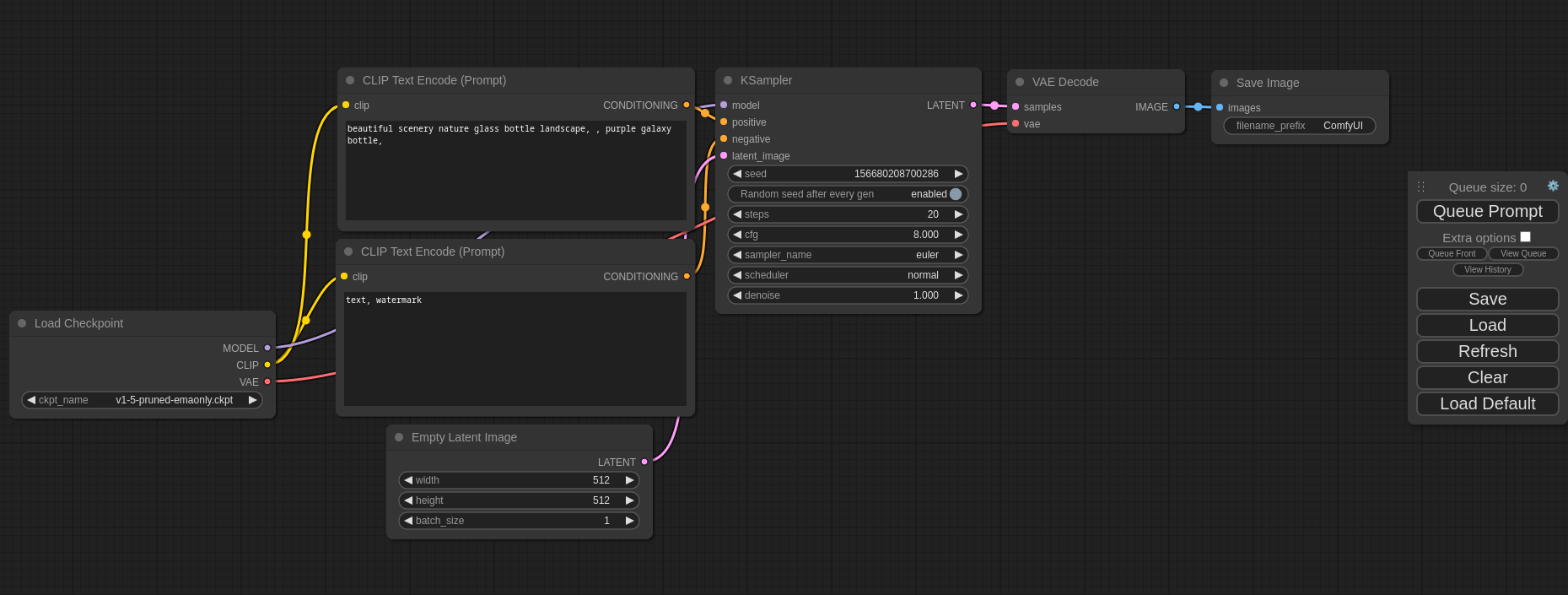
在默认的ComfyUI工作流中,由这里的CheckpointLoader加载模型到ComfyUI中。
你能看到它会有3种输出。
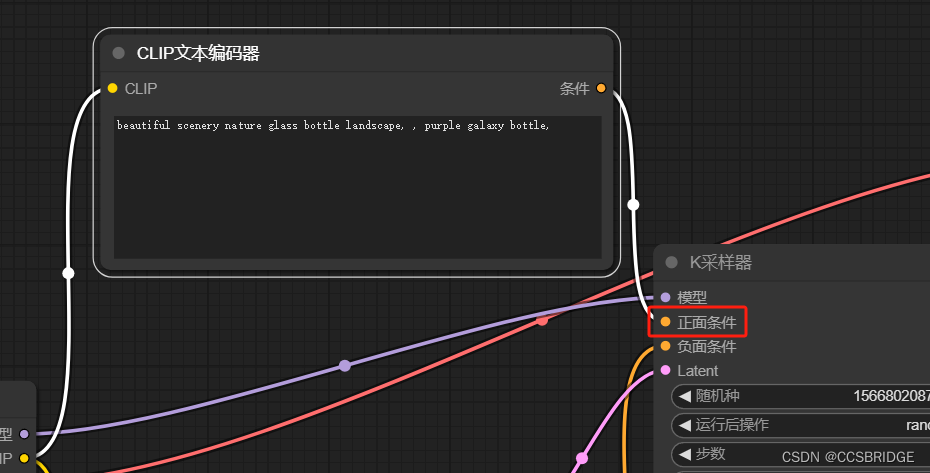
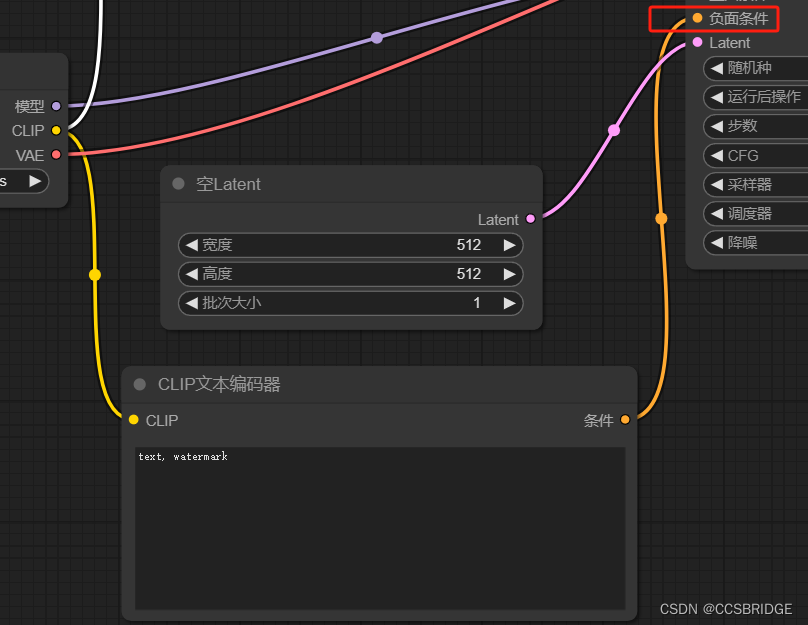
二、CLIP文本编码器(CLIP Text Encode)
让我们先看CLIP文本编码器这一条分流,注意CLIP又有两条分流,分别流向正面条件和负面条件。
CLIP文本编码器的作用就是把人类语言转换成模型能够理解的数据格式。
三、K 采样器 (KSampler)
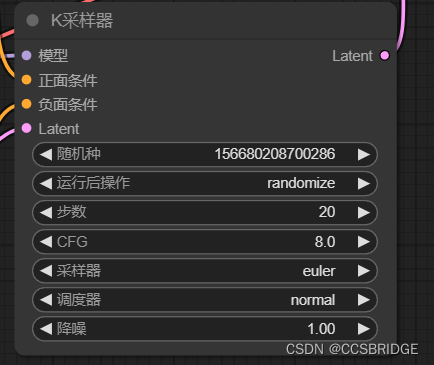
CLIP文本编码器会流动到K采样器,图片就是通过这个采样器生成的。
在K采样器中,主要输入是Stable Diffusion的模型。
同时,正向提示词和反向提示词也是作为K采样器的输入。
四、空的潜在图像

最后,需要再来一个空潜在图像作为输入。(Empty Latent Image)
这是因为我们当前的场景是文生图。
五、降噪
于是采样器会利用这个潜在空图像,向这个潜在空图像添加噪声,然后使用Stable Diffusion的模型进行降噪。
具体的降噪过程是:编码后的正面和负面提示被传递给模型,在每个采样步骤中被用来指导去噪。
这种逐渐去噪的图像生成方式,正是Stable Diffusion生成图片的方式。
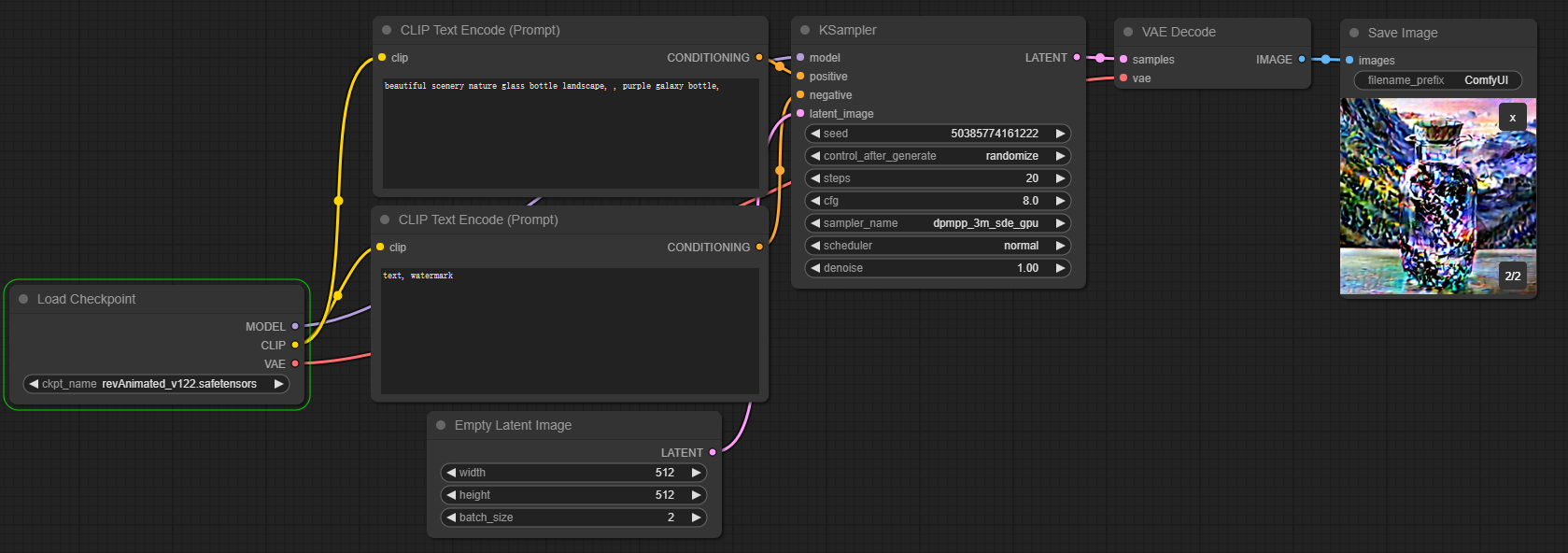
最终,采样器会输出一张降噪之后的图片。
六、VAE模型解码(VAE Decode)
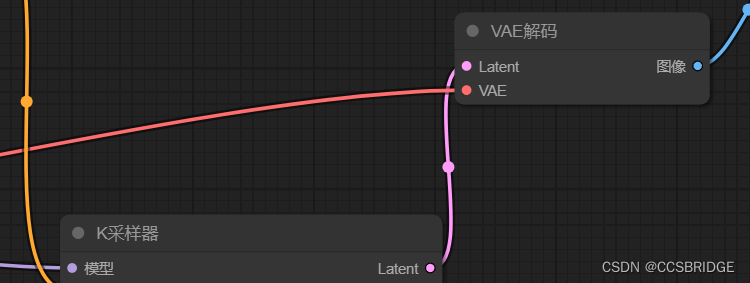
最后的最后,Stable Diffusion会用到VAE模型。
VAE模型被用于把处于潜在空间的图像,转换成肉眼可见的像素图像。
潜在空间的数据是Stable Diffusion模型能够理解的数据。
而像素空间的图像是图片浏览器和人类能够用肉眼观察到的图像。
这个步骤,你可以看到来自采样器的Latent潜在空间的图像作为VAE编码器的输入,通过VAE解码之后,输出常规图像。
这就是简易的工作流的基本流程