【Linux】认识文件(三):缓冲区
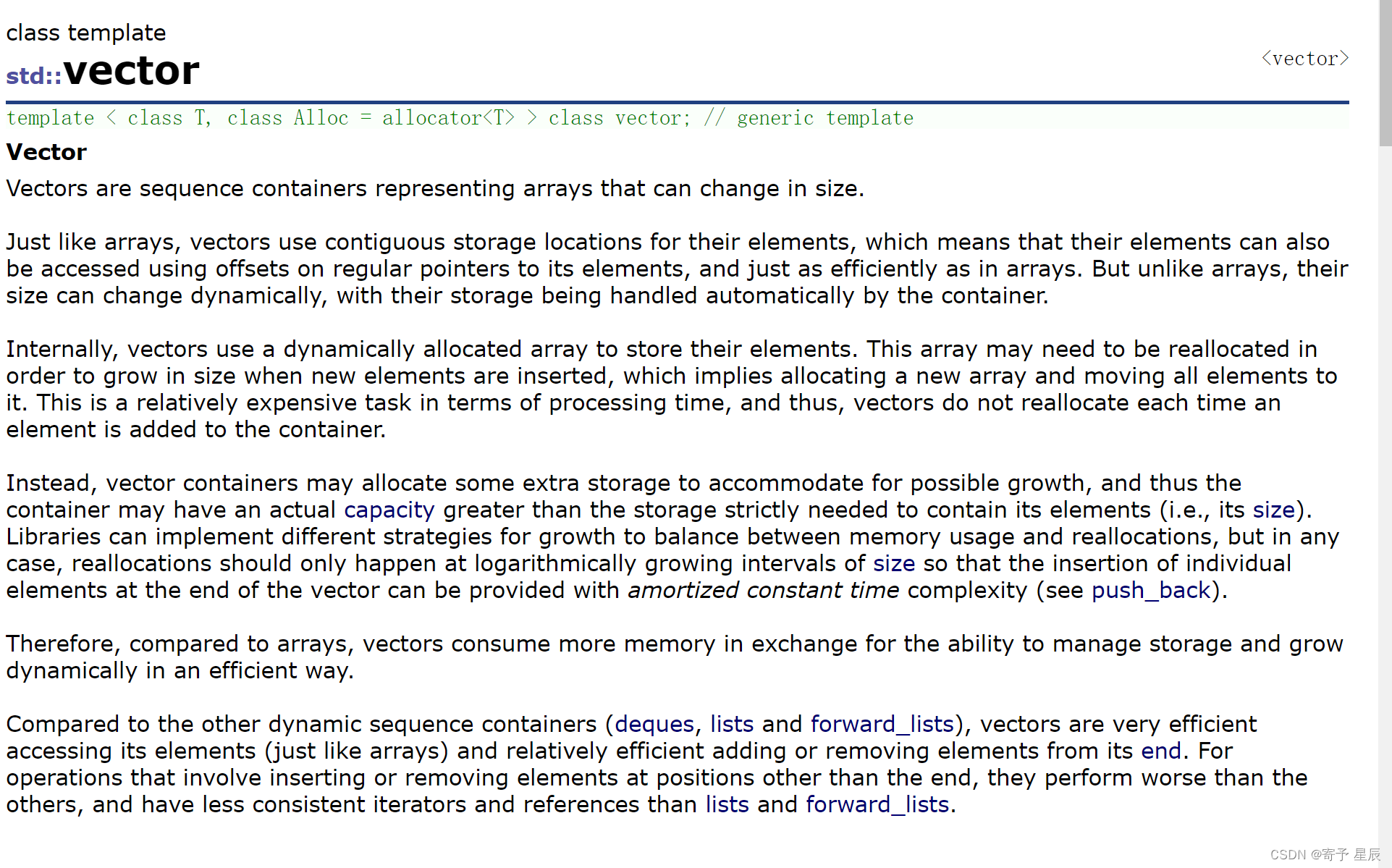
一.啥是缓冲区?
缓冲区,官方说法就是:指的是一块用于临时存储数据的内存区域。
它通常用于数据的输入和输出操作之间,作为数据的中转站,用于平衡输入和输出设备之间的速度差异。
这么会说肯定不太好理解,所以接下来,就给大伙解开缓冲区的面纱。
二.缓冲区现象
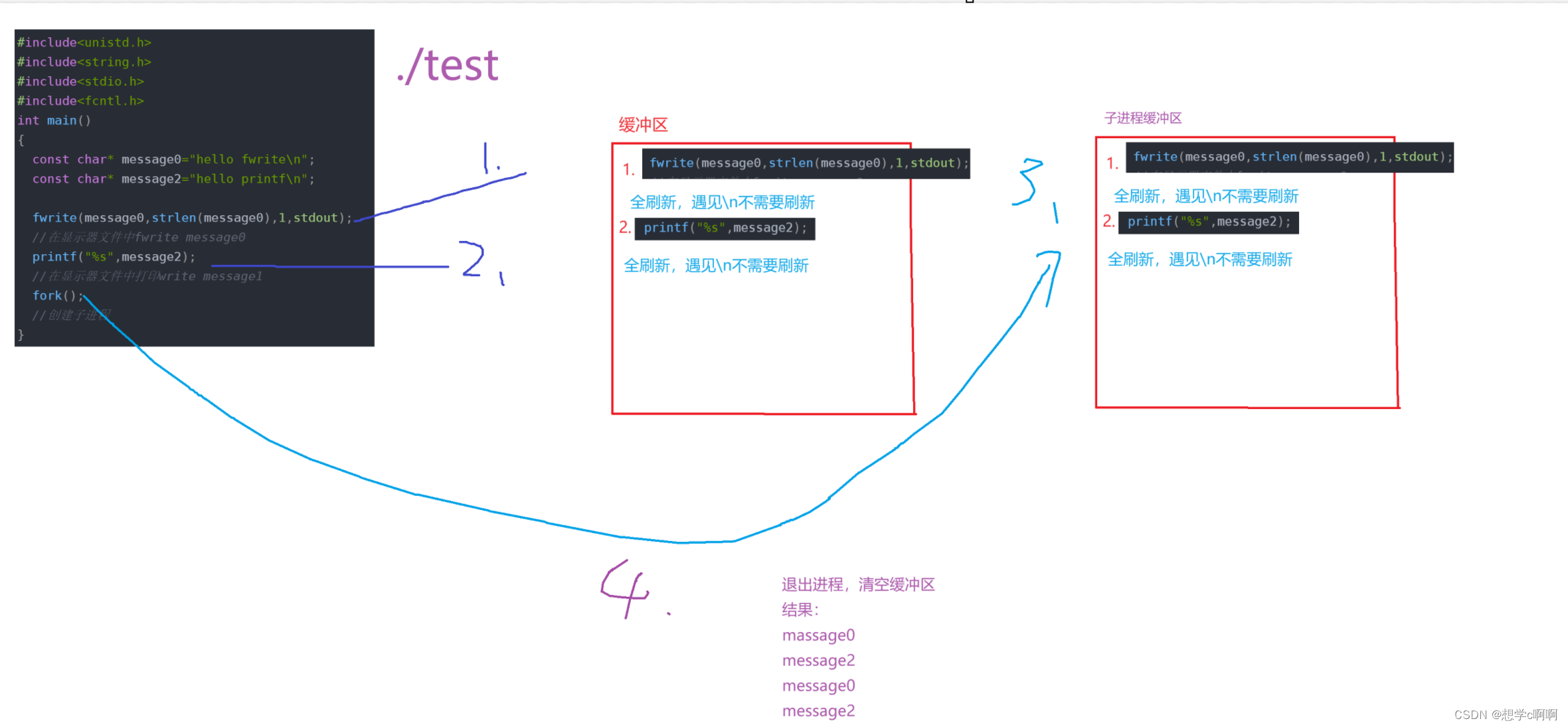
#include<unistd.h>
#include<string.h>
#include<stdio.h>
#include<fcntl.h>
int main()
{
const char* message0="hello fwrite\n";
const char* message2="hello printf\n";
fwrite(message0,strlen(message0),1,stdout);
//在显示器文件中fwrite message0
printf("%s",message2);
//在显示器文件中打印write message1
fork();
//创建子进程
}
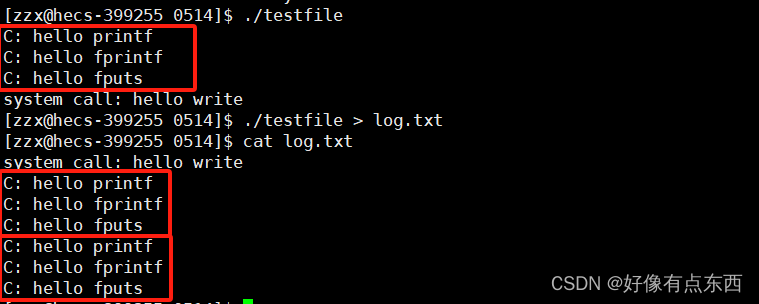
用./test
来运行这个程序
结果如下: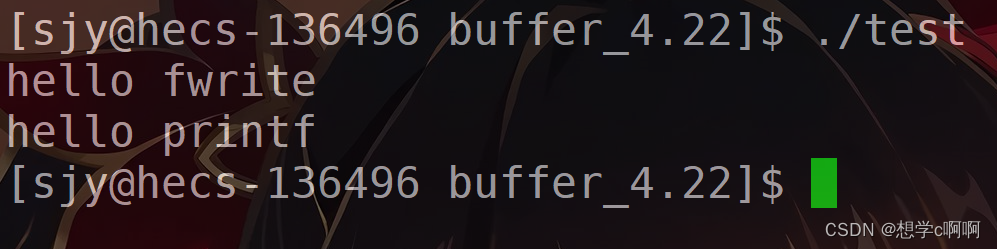
大伙可能觉得这也没啥
但是如果我们将结果重定向给文本文件:
./test > test.log
结果如下:
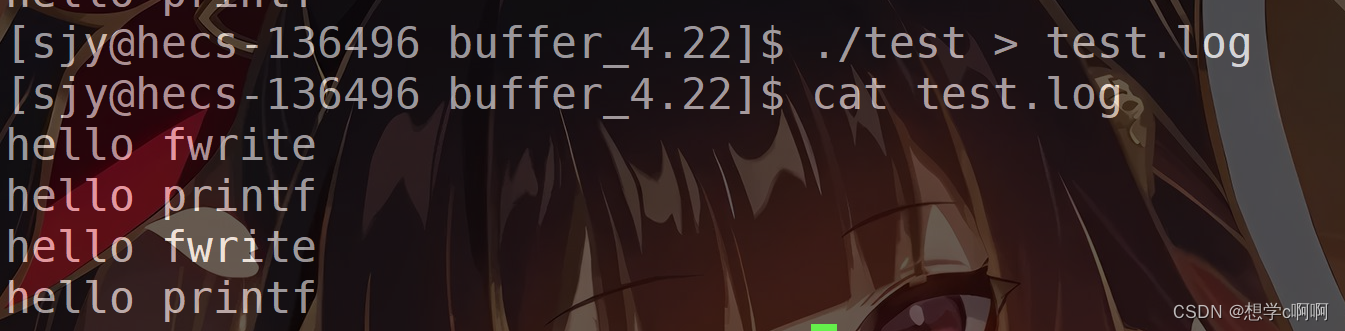
这里我们能发现这里面
fwrite和printf被打印了两次
这里其实就是缓冲区的展现了。
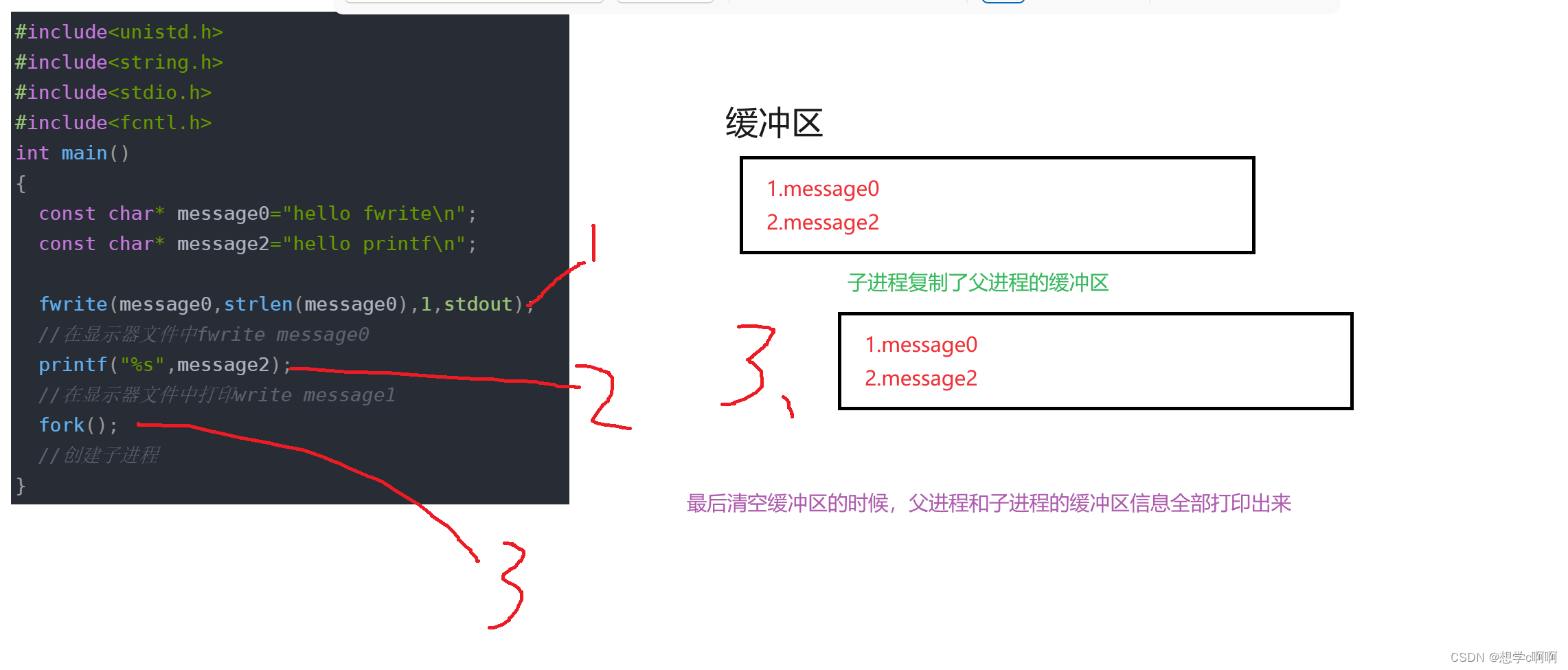
大致情况就是这样了。
三.缓冲区的刷新方法
但是这里细心的人可能会有别的疑惑了
为什么正常运行程序是两条
反而重定向到文件中的时候反而多了两条呢?
这里就要牵扯到缓冲区的刷新方式了:
缓冲区刷新问题:
- a:无缓冲 ----->直接刷新
- b:**行缓冲 ----->遇到\n进行刷新 **
- c:**全缓冲 ----->全部一次性进行刷新 **
- 进程退出时候会刷新
要注意:
一般显示器中的刷新方式是行缓冲
一般文件的刷新方式是全缓冲
所以我们这里可以来分析一下了
输出到显示器:
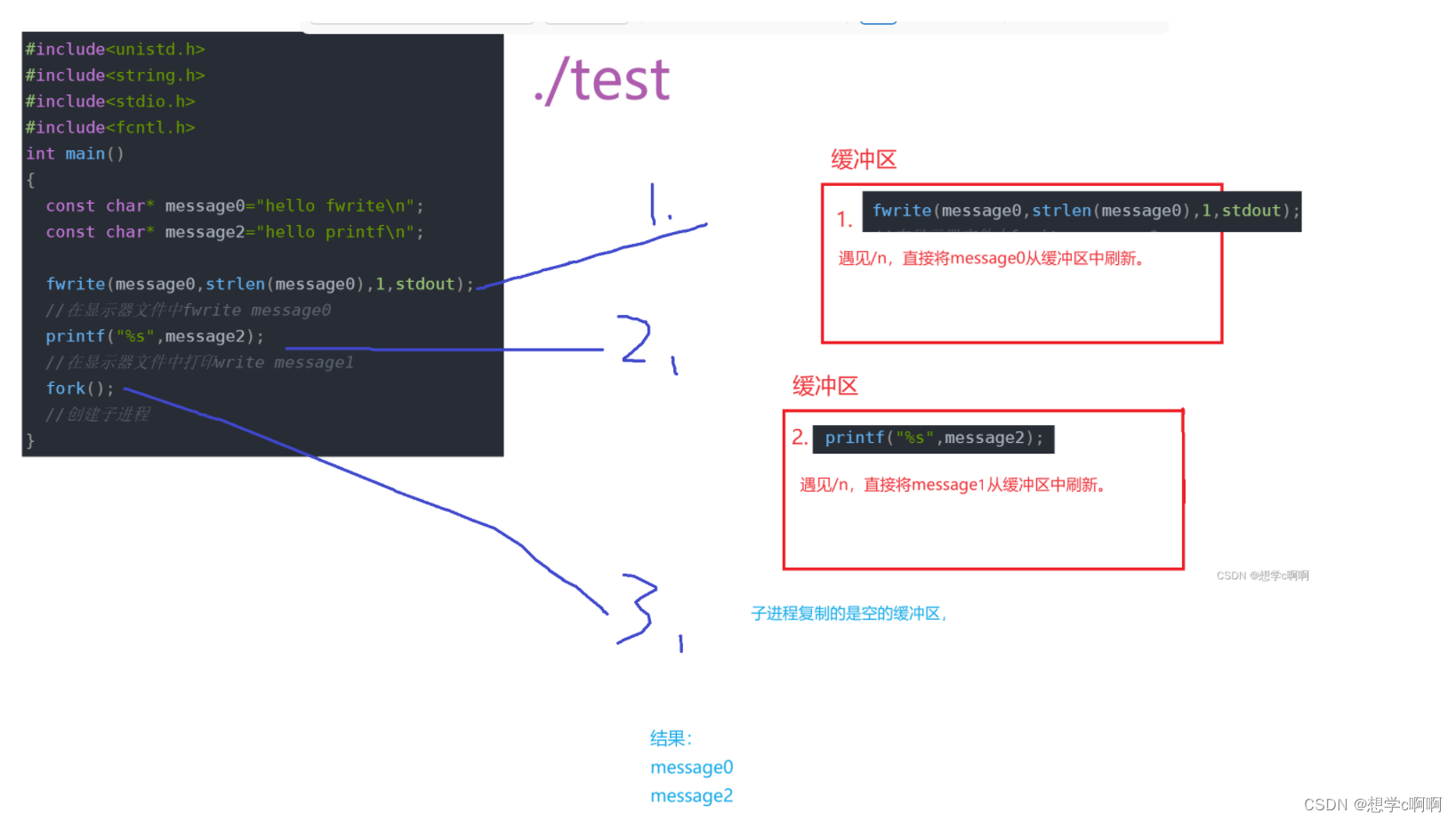
输出到文件:
这里大伙应该就能明白不同刷新方式的区别的。
这里没有最好的刷新方式,只有最合适的刷新方式。
四.缓冲区在哪?
为什么要问这个问题呢?
先带大伙来对上面的代码进行小小的改动:
#include<unistd.h>
#include<string.h>
#include<stdio.h>
#include<fcntl.h>
int main()
{
const char* message0="hello fwrite\n";
const char* message1="hello write\n";
const char* message2="hello printf\n";
fwrite(message0,strlen(message0),1,stdout);
//在显示器文件中fwrite message0
write(1,message1,strlen(message1));
//在显示器文件中write message1
printf("%s",message2);
//在显示器文件中打印write message1
fork();
//创建子进程
}
正常输入到显示器中

结果还是如我们所料
但是如果输出到文件中呢?

这里我们能发现这里write的官方接口没有被打印两次
所以我们能猜到:
write直接就打印了出来,没有进入缓冲区中
因为子进程会复制缓冲区,如果write进入缓冲区的话
就会被子进程给复制,从而出现两条write
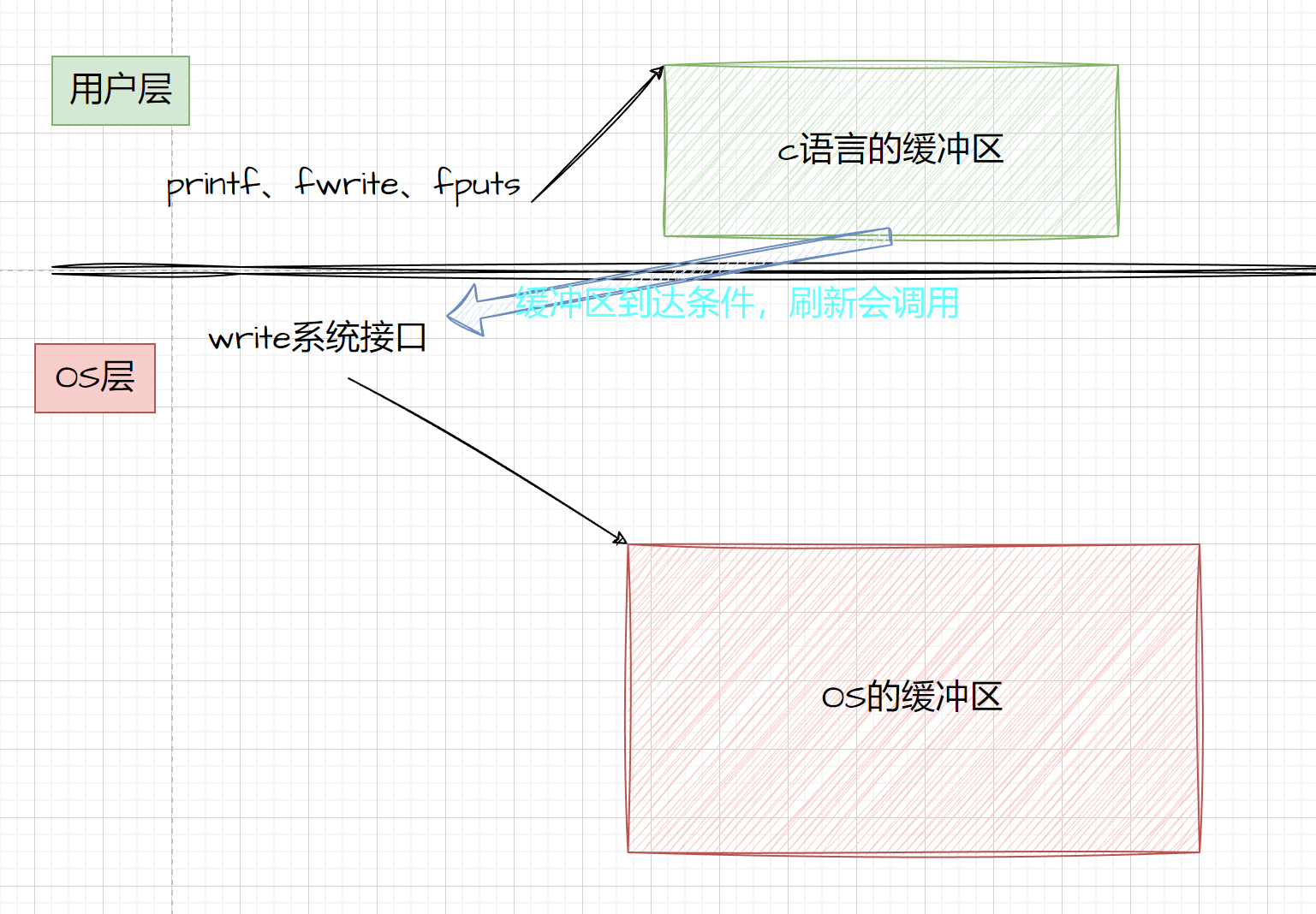
这里我们其实就能给出猜想了:
这个缓冲区只是在C库中,和系统没关系
其实答案真的如我们所想
操作系统中其实也会有缓冲区,但是不是我们用户能够管制的
但是C库中的缓冲区是用户级的,我们能够感受到
一般语言都会有自己的用户级缓冲区,不光是C语言
这里再来带大伙来验证一下:
众所周知:
_exit是系统接口 exit是C库中接口
所以讲道理,C缓冲区的话,_exit是不会处理的
但是exit是C接口,所以exit会进行处理。
这里我们来对比一下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
printf("test");
_exit(1);
}
结果:

#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
printf("test");
exit(1);
}
结果: 结果和我们想的一样
结果和我们想的一样
五.为什么要有缓冲区
为什么要有这个缓冲区:
- 提高程序员的效率
通过将数据传给系统和硬件的工作交给语言 - 缓冲区的解决输入和输出设备之间的速度不匹配问题
原理:当数据从一个设备传输到另一个设备时,数据的传输速度可能会有所不同。
例如,当从硬盘读取大量数据时,硬盘的读取速度相对较慢,而将数据发送到网络或显示器等设备时,速度可能要求更快。为了使这些设备之间的数据传输更加高效,可以使用缓冲区来调节数据的流动。



![<span style='color:red;'>Linux</span> 基础IO [<span style='color:red;'>缓冲区</span>&&<span style='color:red;'>文件</span>系统]](https://img-blog.csdnimg.cn/direct/a9c29f402df04e188d9ffca279c1d012.png)


















![《让云落地 云计算服务模式》第五章 [选择合适的云服务模式]学习](https://img-blog.csdnimg.cn/direct/edcc41102c684bcf848566a4f644ce8e.png)