0.概述
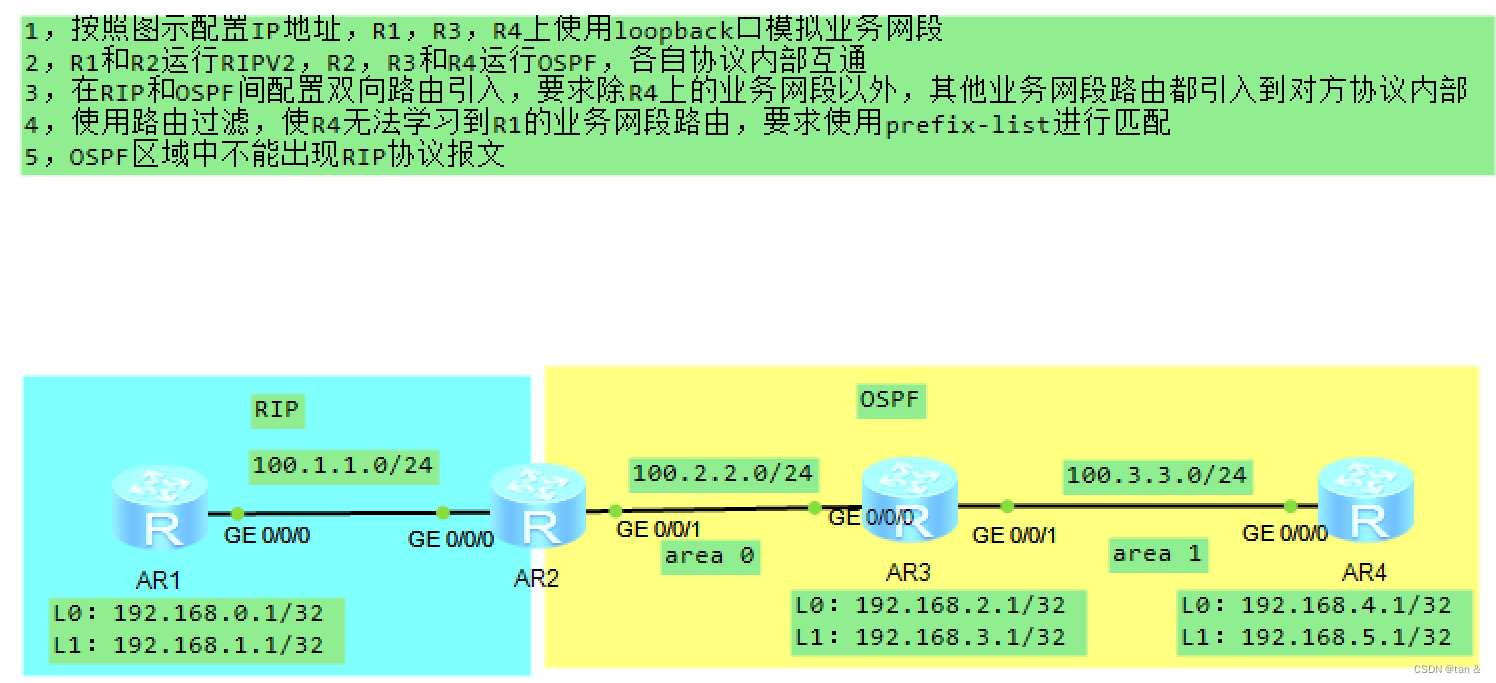
很多应用中,在进一步处理之前都要求数据元素互异。以网络搜索引擎为例,多个计算节点各自获得的局部搜索结果,需首先剔除其中重复的项目,方可合并为一份完整的报告。类似地,所谓向量的唯一化处理,就是剔除其中的重复元素。
1.错误版
template <typename T> int Vector<T>::dedup() { //删除无序向量中重复元素(错误版)
int oldSize = _size; //记录原规模
for ( Rank i = 1; i < _size; i++ ) { //逐一考查_elem[i]
Rank j = find ( _elem[i], 0, i ); //在_elem[i]的前驱中寻找与之雷同者(至多一个)
if ( 0 <= j ) remove ( j ); //若存在,则删除之(但在此种情况,下一迭代不必做i++)
}
return oldSize - _size; //向量规模变化量,即被删除元素总数
}
错误:删除重复元素情况下,下一迭代不必做i++。
2.繁琐版
算法思想:从前至后顺序唯一化,先剔除与第一个元素重复得元素,再剔除后面的。
template <typename T> int Vector<T>::dedup() { //删除无序向量中重复元素(繁琐版)
int oldSize = _size; //记录原规模
int i = -1; //从最前端开始
while ( ++i < _size - 1 ) { //从前向后,逐一
int j = i + 1; //assert: _elem[0, i]中不含重复元素
while ( j < _size )
if ( _elem[i] == _elem[j] ) remove ( j ); //若雷同,则删除后者
else j++; //并继描
}
return oldSize - _size; //向量规模变化量,即被删除元素总数
}
3.高效版
算法思想:从前至后查找,先使用无序向量的查找find()接口在前缀[0,i)中寻找与[i]雷同者,若存在再调用remove()接口删除,remove()函数根据情况进行向量空间的动态管理,调用shrink()接口,查看是否需要缩容。动态空间不清楚的可以看动态空间管理。
template <typename T> void Vector<T>::shrink() { //装填因子过小时压缩向量所占空间
if ( _capacity < DEFAULT_CAPACITY << 1 ) return; //不致收缩到DEFAULT_CAPACITY以下
if ( _size << 2 > _capacity ) return; //以25%为界
T* oldElem = _elem; _elem = new T[_capacity >>= 1]; //容量减半
for ( Rank i = 0; i < _size; i++ ) _elem[i] = oldElem[i]; //复制原向量内容
delete[] oldElem; //释放原空间
}
template <typename T> Rank Vector<T>::remove( Rank lo, Rank hi ) { //0 <= lo <= hi <= n
if ( lo == hi ) return 0; //出于效率考虑,单独处理退化情况
while ( hi < _size ) _elem[lo++] = _elem[hi++]; //后缀[hi, _size)顺次前移hi-lo位
_size = lo; shrink(); //更新规模,lo=_size之后的内容无需清零;如必要,则缩容
//若有必要,则缩容
return hi - lo; //返回被删除元素的数目
}
template <typename T> T Vector<T>::remove( Rank r ) { //删除向量中秩为r的元素,0 <= r < size
T e = _elem[r]; //备份被删除元素
remove( r, r + 1 ); //调用区间删除算法,等效于对区间[r, r + 1)的删除
return e; //返回被删除元素
}
template <typename T> //在无序向量中顺序查找e:成功则返回最靠后的出现位置,否则返回lo-1
Rank Vector<T>::find ( T const& e, Rank lo, Rank hi ) const { //0 <= lo < hi <= _size
while ( ( lo < hi-- ) && ( e != _elem[hi] ) ); //从后向前,顺序查找
return hi; //若hi < lo,则意味着失败;否则hi即命中元素的秩
}
template <typename T> Rank Vector<T>::dedup() { //删除无序向量中重复元素(高效版)
Rank oldSize = _size; //记录原规模
for ( Rank i = 1; i < _size; ) //自前向后逐个考查_elem[1,_size)
if ( -1 == find(_elem[i], 0, i) ) //在前缀[0,i)中寻找与[i]雷同者(至多一个),O(i)
i++; //若无雷同,则继续考查其后继
else
remove(i); //否则删除[i],O(_size-i)
return oldSize - _size; //被删除元素总数
}
3.1 复杂度
随着循环的不断进行,当前元素的后继持续地严格减少
这里所需的时间,主要消耗于find()和remove()两个接口。
remove() find() 接口不熟悉可以看常规向量。
find()时间线性正比于查找区间的宽度,即前驱的总数;remove()时间应线性正比于后继的总数。因此,每步迭代所需时间为O(n),总体复杂度应为O( n 2 n^2 n2)。