import pandas as pd
data = {'Age': [20, 30, 40, 20, 20], 'Name': ['Lucy', 'Lily', 'Andy', 'Bob', 'Tony'],
'City': ['Bj', 'Sh', 'Gz', 'Bj', 'Bj']}
df = pd.DataFrame(data=data)
# 获取列
name_column = df['Name']
# 获取行
first_row = df.loc[0]
# 选择多列
subset = df[['Name', 'Age']]
# 过滤行
filtered_rows = df[df['Age'] > 30]
# 获取列名
columns = df.columns
# 获取形状(行数和列数)
shape = df.shape
# 获取索引
index = df.index
# 获取描述统计信息
stats = df.describe()
# 添加新列
df['Salary'] = [70000, 60000, 50000, 70000, 70000]
# 删除列
df.drop('City', axis=1, inplace=True)
# 排序
df.sort_values(by=["Age", "Salary", "Name"], ascending=[True, False, False], inplace=True)
# df = df.sort_index()
# 重命名列
df.rename(columns={'Name': 'Full Name'}, inplace=True)
print(df)
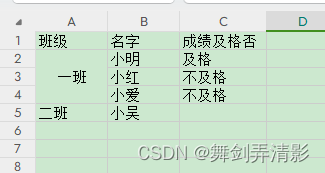
pandas处理excel问题(记录)
2024-04-24 01:52:02 34 阅读