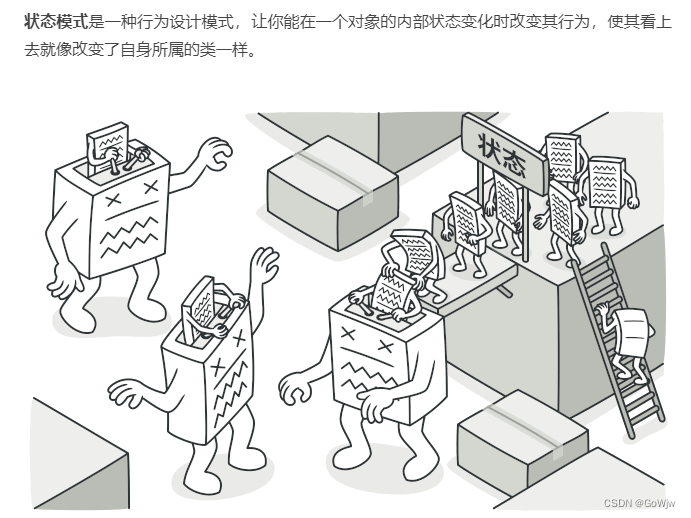
在使用 NumPy 进行数据处理时,np.where 方法是一个非常实用的工具,特别是当你需要根据某些条件从数组中查找元素的索引时。本案例展示了如何使用 np.where 在多维数组中查找满足特定条件的元素的位置。
详细解析
首先,我们始化一个 2x5 的二维数组 arr:
arr = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10]])
这个数组包含从 1 到 10 的整数,形状为两行五列。
接下来,使用 np.where 函数来找出数组中所有大于 2 的元素的索引:
indices = np.where(arr > 2)
这里,arr > 2 会首先生成一个布尔数组,其中的元素值为 True 或 False,具体取决于相应位置的元素是否满足大于 2 的条件。np.where 函数接着返回一个元组,每个元素是一个数组,分别表示满足条件的元素的行索引和列索引。
在本案例中,输出结果为:
(array([0, 0, 0, 1, 1, 1, 1, 1]), array([2, 3, 4, 0, 1, 2, 3, 4]))
这个结果中,第一个数组是行索引,第二个数组是列索引。例如,元素 3(大于2的第一个元素)在原数组中的位置是 (0, 2),即第0行第2列。通过这种方式,我们可以快速找到所有满足条件的元素的位置。
在本案例中,输出结果表示满足条件arr > 2的元素分别处在:
(0, 2)- 第一行第三列,元素3(0, 3)- 第一行第四列,元素4(0, 4)- 第一行第五列,元素5(1, 0)- 第二行第一列,元素6(1, 1)- 第二行第二列,元素7(1, 2)- 第二行第三列,元素8(1, 3)- 第二行第四列,元素9(1, 4)- 第二行第五列,元素10
应用场景
场景介绍
假设我们有一个人工智能模型的学习评分数据,其中包含了学生的姓名、分数和学习时长。我们的目标是识别出哪些学生在学习时长相对较短的情况下依然获得了高分,并给这些学生的成绩标记为“优秀”。
操作步骤
- 1.数据构建
首先,创建一个包含学生姓名、分数和学习时长的 NumPy 数组:
import numpy as np
# 学生姓名,分数,学习时长(小时)
data = np.array([
['Alice', 88, 12],
['Bob', 45, 15],
['Cindy', 72, 9],
['David', 62, 8],
['Ella', 90, 10]
])
# 分数和学习时长的数据类型是整数
scores = data[:, 1].astype(np.int)
hours = data[:, 2].astype(np.int)
- 2.应用 np.where
现在,我们想要找出分数高于 70 分且学习时长少于 11 小时的学生,并标记这些学生的分数为“优秀”。
# 设置条件
high_scores_good_efficiency = np.where((scores > 70) & (hours < 11))
# 标记为"优秀"
for index in high_scores_good_efficiency[0]:
data[index, 1] = "优秀"
print(data)
- 3.输出解析
执行上述代码后,我们可以看到数据中符合条件的学生分数已被标记为“优秀”:
[['Alice' '88' '12']
['Bob' '45' '15']
['Cindy' '优秀' '9']
['David' '62' '8']
['Ella' '优秀' '10']]
从输出中可以看到,Cindy 和 Ella 的分数被标记为“优秀”。他们都满足了分数超过 70 分且学习时长少于 11 小时的条件。
更多场景
这个简单的应用案例展示了如何在教育数据分析中使用 np.where 来进行条件筛选并作出相应的数据标记。这在实际应用中非常常见,比如:
- 学生表现分析:快速找出表现优异或需要帮助的学生,以便做进一步的辅导或奖励。
- 数据分段处理:对数据进行分段,高于或低于某些阈值的数据进行特别处理。
- 条件筛选:在数据集中快速找出满足特定条件的数据行,用于进一步分析或报告。





























![CodeForce[1500-2000]——1946C Tree Cutting](https://img-blog.csdnimg.cn/direct/e322dcd66f7543afb331de3f2e1e3372.png)