以下场景来自DaoCloud官方文档场景化视频,这里以文字形式简单提取下要点,包括操作步骤和一些问题。
一共13个场景,本篇包含5个:9.快速定位异常与排障、10.基于CICD的应用发布、11.基于GitOps持续部署云原生应用、12.使用中间件与pgvector部署ChatGPT、13.Redis跨集群数据同步。
9. 快速定位异常与排障
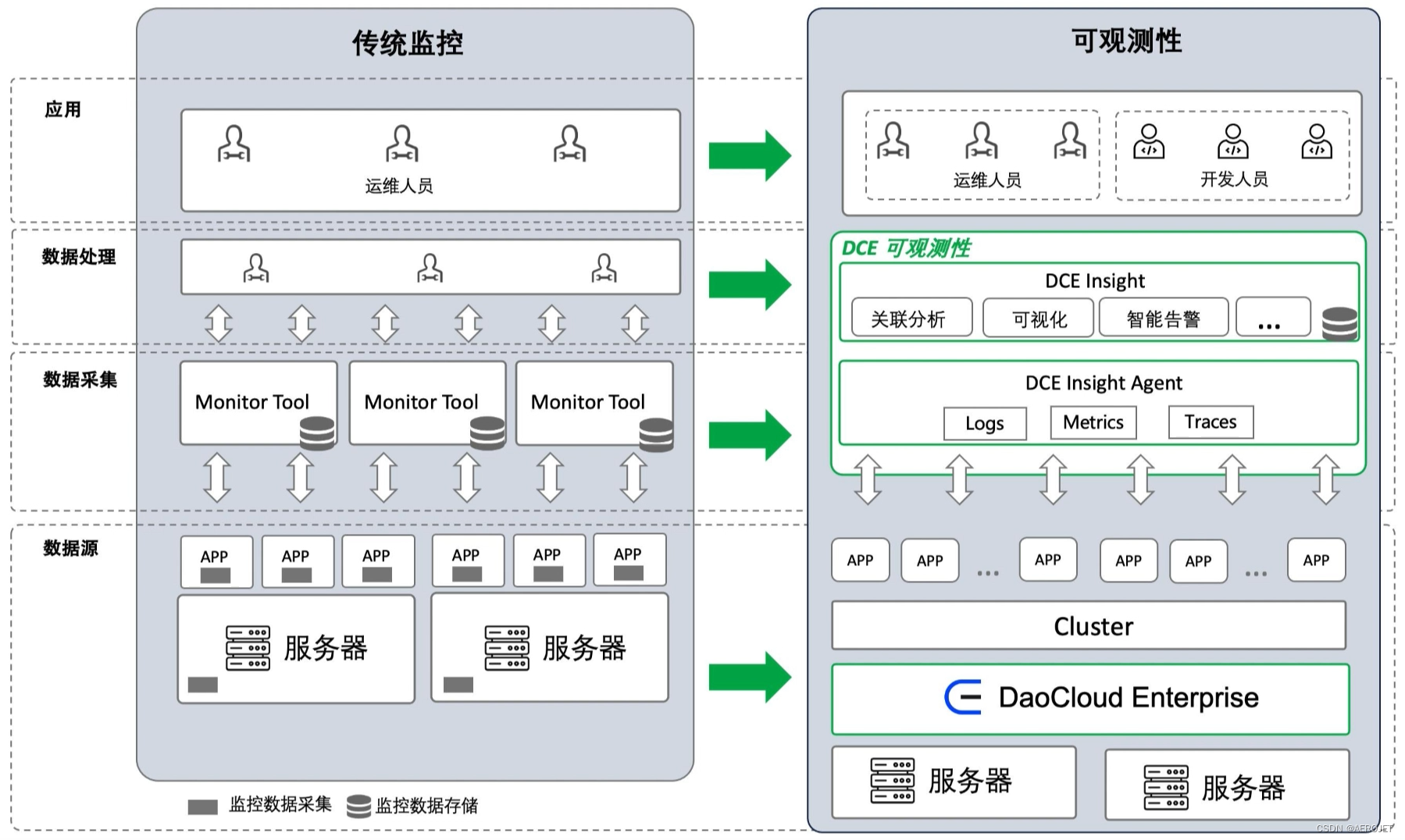
介绍云原生可观测性,微服务架构的流行促进了观测性方法的完善,一般来说是三大支柱(日志、追踪、指标)和理解什么是“可观测”,概括一下应该是使用非人工方法缩短从数据获得信息甚至智慧的时间。对于云原生来说,承载微服务应用是其技术特性之一,服务网格和自动化能力能够简化数据收集,尤其对于APM,可以在一些情况下使用非侵入的方式获得数据,同时云原生监控方案也会充分考虑弹性特质。一般的云原生平台至少会集成事件、指标和日志数据,但很难产生洞察,仍然是人工数据查询的方式产出信息,DCE增强了这方面的能力,能够根据规则产生告警信息,功能设计方面似乎仍然保持了简单,主流的监控厂商正在从基础设施、应用、流程等更大范围内集成数据并使用人工智能分析,云原生平台似乎没有动力构建这样庞大的系统,找到云原生监控的场景、关注点甚至适用的氛围是非常重要的,这可能需要深入稳定性保障体系构建的方法论,不做深入。
操作步骤:
- 前提条件,为集群安装Insight组件,部署使用OTel(OpenTelemetry,是业界主流的开源遥测框架,它指出了可观测性的三大支柱并提供了架构参考和实现) SDK的演示应用;
- 创建告警策略,策略适用于选定集群的指定资源类型(集群、节点、工作负载),策略内添加具体的规则,能够直接输入PromeQL语句,也支持更友好的界面配置方式,可能PromeQL具备更高的灵活性,不宜读也是事实,告警信息可以选定渠道发送,整体上是一些非常基本的功能;
- 制造错误率告警,登录DCE在拓扑中找到错误率告警的链路,从此进入可查看黄金指标(错误率、吞吐率、延时)趋势信息,确认告警详情,进入筛选后的链路追踪即可锁定到具体的交易,链路中聚合了进程、日志、事件数据,可以初步定位异常原因,进入日志服务可以根据链路ID还原日志上下文,进行更加深入的分析,整个工作流还是比较流畅的,但各个步骤的信息提取还是非常依赖人工分析,比如要得出告警指标的异常等级变化趋势只能去人工分析折线图,Istio原生的面板对可观测的理解比较深入;
问题:
- 从界面看,开始服务监控的步骤从为目标集群安装Insight组件开始,然后使用OTel SDK或者Operator采集链路数据,其中Operator支持部署哪些采集方式呢?
- DCE的可观测场景为何种规模、何种文化的团队设计?
更详细的信息参考什么是可观测模块。
10. 基于CICD的应用发布
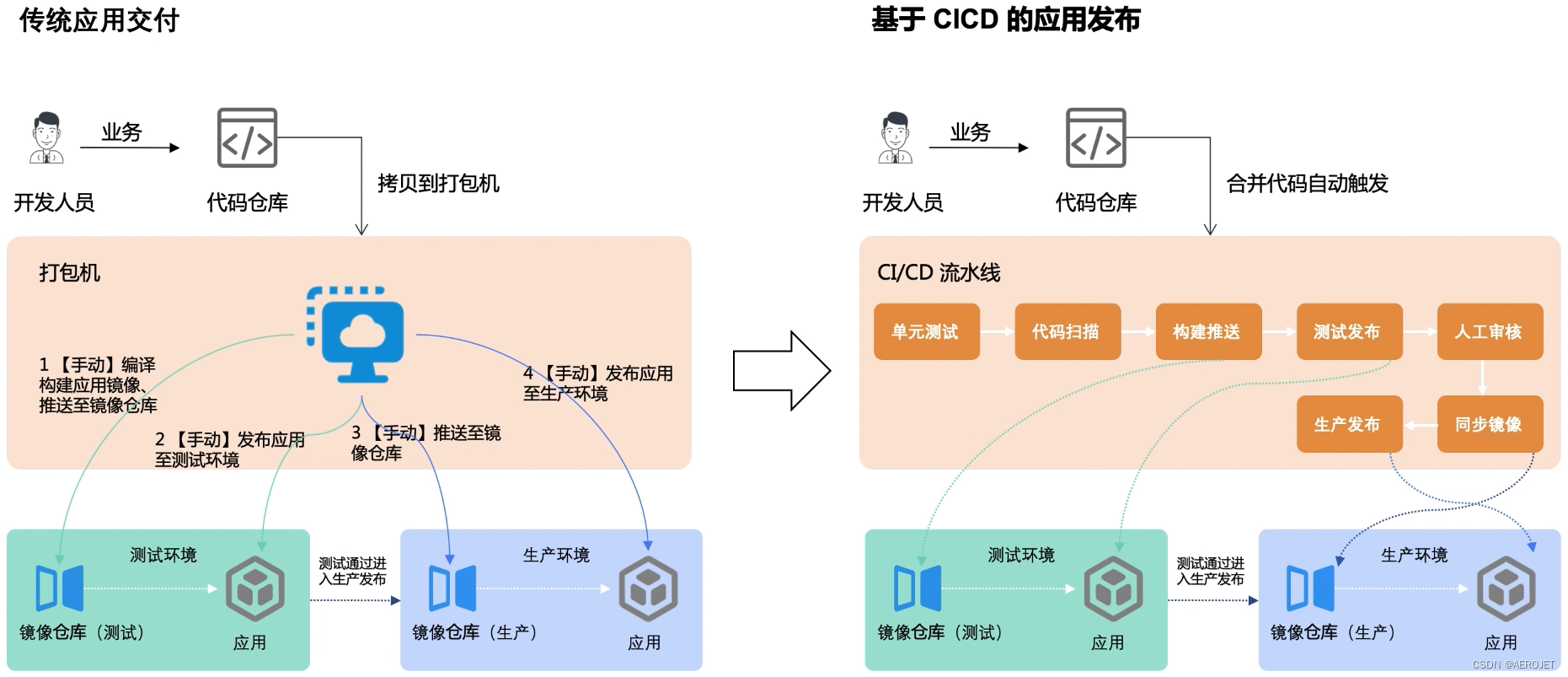
由应用工作台模块支持CICD,实际上是简单的Jenkins集成,流行的云原生平台似乎都是这样的集成方式,指标度量方面非常弱,在DevOps的理念中度量是改进的必选项,实际上度量适用于任何改进过程,这种弱度量设计似乎更适合于小规模的自治团队,比如微服务团队,功能设计简单的真实原因是什么呢?
操作步骤:
- 前提条件,在集群中部署Jenkins并通过NodePort暴露,进入Jenkins控制台配置Sonarqube,然后依次准备应用代码仓库、部署目标集群、应用Harbor仓库、流水线凭证(用于访问目标集群、Harbor仓库);
- 通过Jenkinsfile创建流水线:拉取代码、质量扫描、构建并推送至Harbor、使用Helm部署;
问题:
- 视频中使用手动触发流水线,支持Webhook驱动的自动化方式吗?
- 关于度量是否存在一些弥补方案?
- 部署过程中的其他步骤,例如环境配置、数据库变更、刷新外部缓存等如何自动化呢?似乎还有很长的路要走;
细节可以参考基于流水线和 GitOps 实现 CI/CD。
11. 基于GitOps持续部署云原生应用
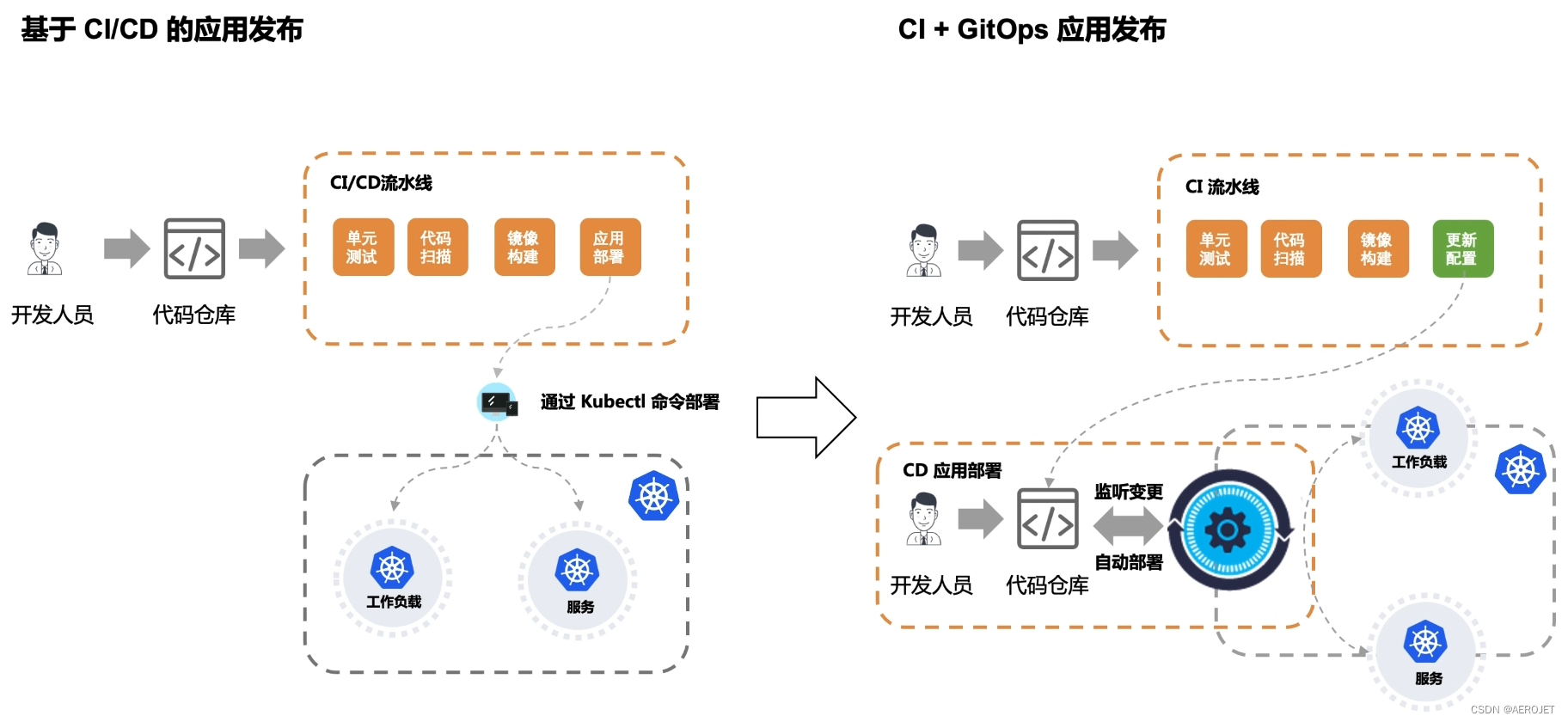
GitOps替换了前面CICD场景中的CD部分,GitOps中两个关键的概念是应用配置和配置同步,这里的配置是指存放于独立仓库的K8s的manifest文件,K8s支撑了底层的自动化,而配置同步的精妙在于避免通过K8s私自修改配置,它能发现仓库中的配置与实际环境中的不同,从而使配置管理不至于沦为口号,例如应用能够基于仓库做可靠的回滚。DCE基于开源项目ArgoCD实现GitOps。了解GitOps可以阅读下面两篇文章:
操作步骤:
- 前提条件,基本与CICD部分一致,差异在于增加了配置仓库的访问凭证(流水线要访问配置仓库),以及在GitOps模块下增加配置仓库的地址;
- 在GitOps模块中创建应用,完成部署位置、配置仓库、同步策略的配置;
- 初次部署应用,此时因为还未部署应用,因此配置属于未同步状态,执行同步即可将应用部署到集群中,注意此时配置仓库中是存在可用配置的,即可用的manifest文件,包含可用的镜像;
- 更改应用配置,在应用工作台创建Jenkins自定义流水线,分为三个阶段:拉取代码、构建镜像并推送、同步应用配置,最后一步的细节是,首先拉取配置然后使用
sed命令替换镜像版本最后push新配置到镜像仓库; - 同步配置,此时GitOps已经检测到仓库中的配置与实际环境存在差异,手动更新即可部署新的版本,值得注意的是配置同步替换了前面使用Helm部署的过程,GitOps通过自动感知变化防止配置漂移;
更多细节参考创建ArgoCD应用。
12. 使用中间件与pgvector部署ChatGPT
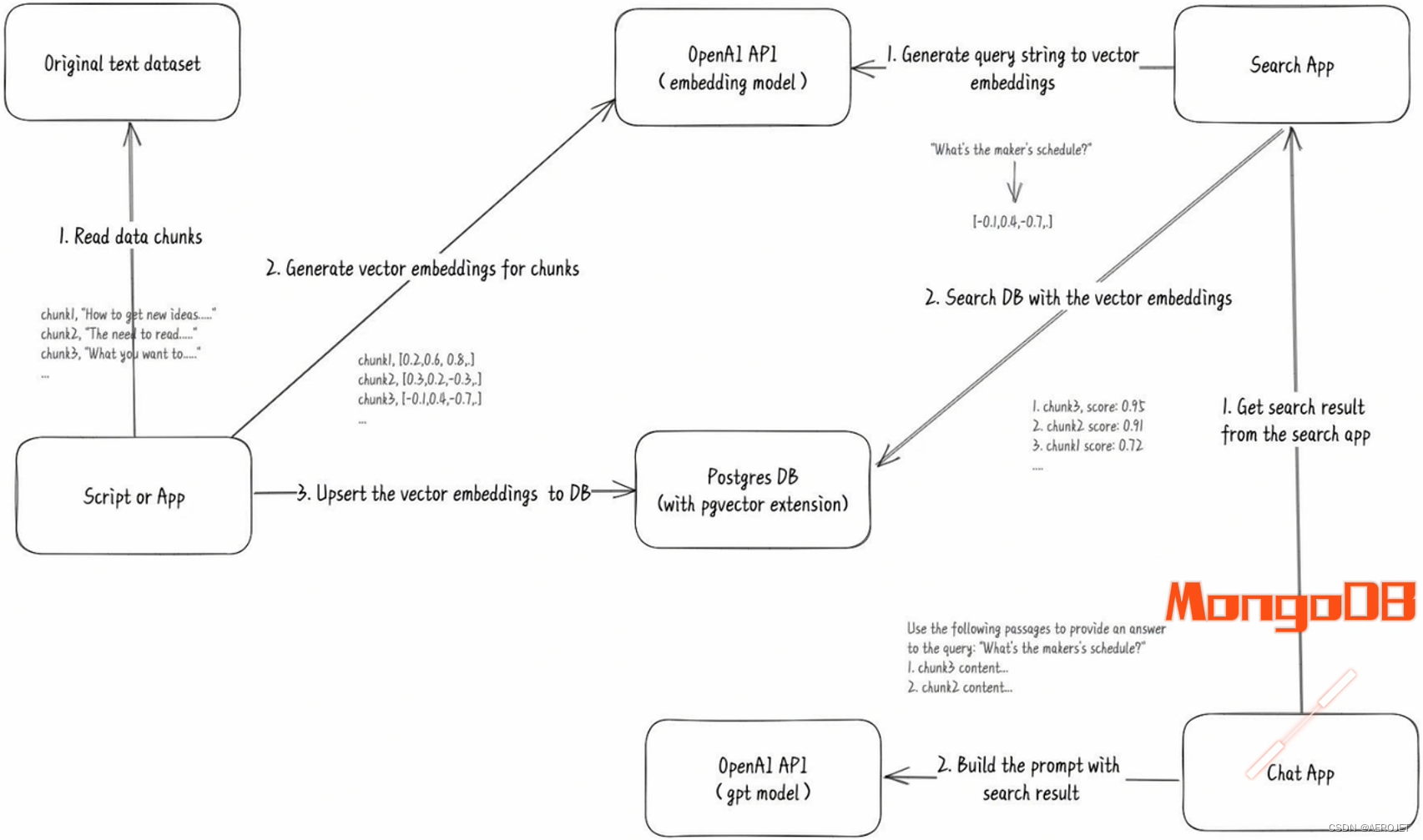
通过FastGPT整合DCE的各类文档,创建智能问答应用,这里需要理解FastGPT的工作流,简单来说它使用了OpenAI的接口,向量化之后的知识库存储于本地PostgreSQL(需要pgvector插件支持),同时使用中间件MongoDB存储历史对话,DCE需要支持这两类有状态应用的部署,这个示例主要展示了适用于AI的数据库的管理能力,另外向我们展示了构建一个AI应用是多么简单。
操作步骤:
- 在DCE中间件模块下创建MongoDB实例,然后创建PostgreSQL数据库实例,在pgAdmin控制台中添加vector插件;
- 部署FastGPT;
- 使用FastGPT;
- 通过pgAdmin查看原始的向量数据;
13. Redis跨集群数据同步
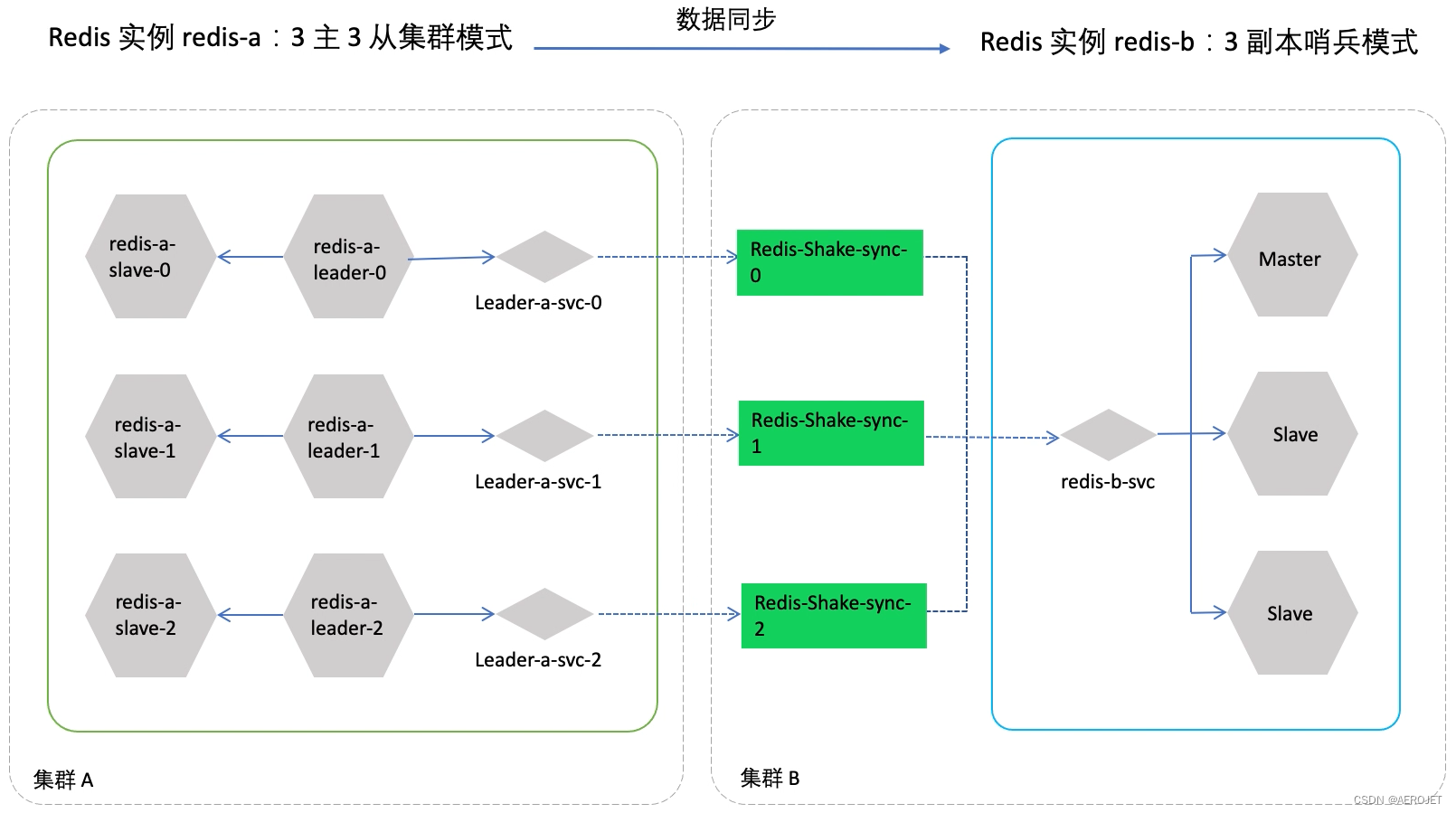
以Redis为例演示了有状态服务的数据实时同步能力,DCE在数据同步和恢复方面是否有定制化的实现需要了解更多细节,表面看仅仅是基于开源方案操作。
操作步骤:
- 前提条件,准备两个集群,在中间件模块中为两个集群分别部署Redis实例,采用不同的部署架构,源集群为三副本集群,目标集群为三副本哨兵,注意正确暴露有状态应用;
- 在目标集群部署redis-shake,它是阿里开源的redis同步工具,同步时如果源端是集群部署,可以从不同的节点拉取,所以需要先创建对应源集群每个节点的同步配置,然后使用这些配置创建三个redis-shake工作负载,此时已经实现数据从源端到目标端的实时同步,做数据恢复时需要停止原有的redis-shake负载,并在反方向部署;
更多细节参考跨集群数据同步,从文档中可以看到,DCE支持的中间件覆盖关系数据库、非关系数据库、搜索引擎、对象存储、队列这些分布式应用的架构组件,能够支持分布式应用的运行。























![[蓝桥杯 2018 国 C] 迷宫与陷阱](https://img-blog.csdnimg.cn/direct/12dda1332a4d445a954a4fa601feece1.png)