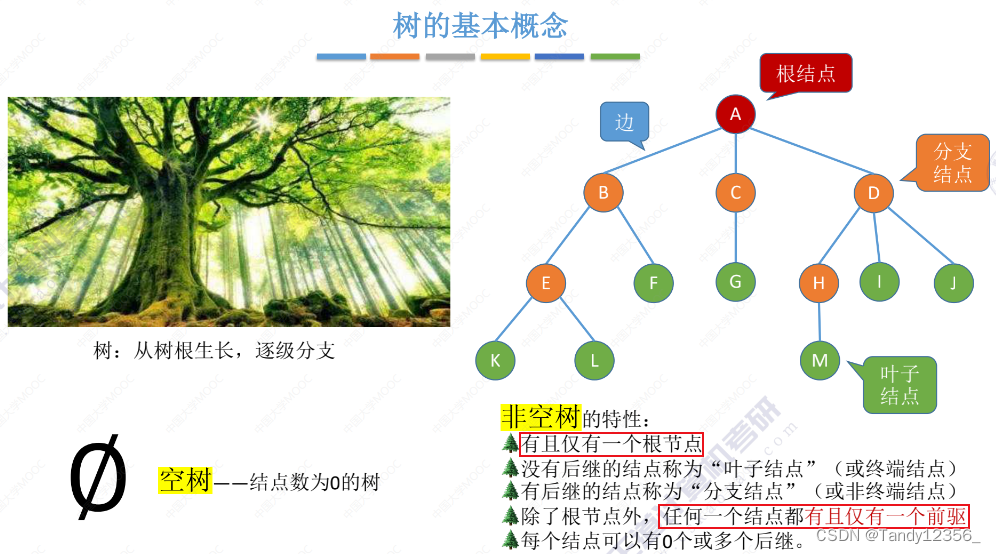
1.什么是树?树的基本概念术语:
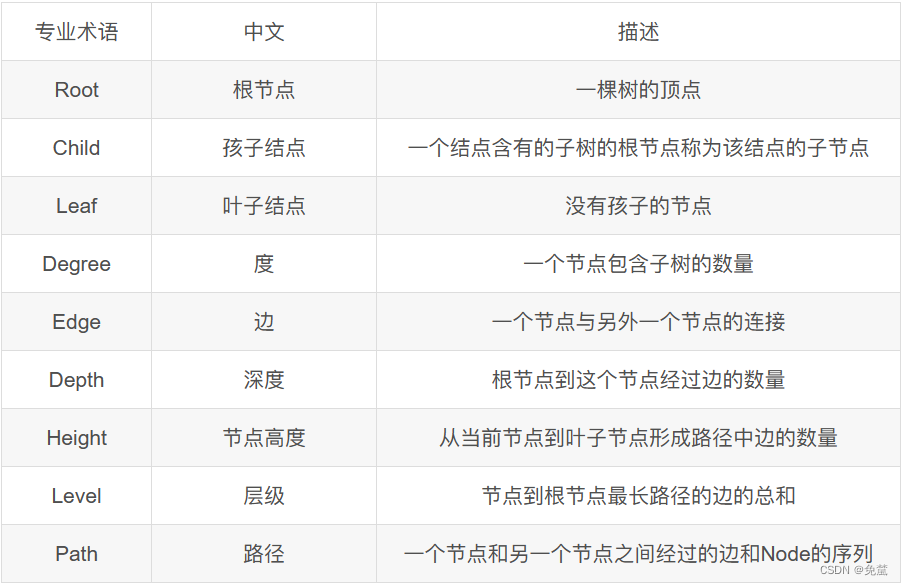
2.树有哪些属性?
(理解树的三种节点名称)
根节点:树的最顶层节点;
子节点:一个节点下连接的节点
叶子节点:(不是只有最后一层)如果一个节点下没有叶子节点,那么该节点被称为叶子节点
3.树大概怎么实现?
4.树的基本应用:
1)数据存储结构,比如系统磁盘中对文件的存储
2)提高数据查询的效率:二叉树
3)Tire树,用来存储字典,它可以被用来做动态的拼写检查
4)网络路由算法
......
5.二叉树:
特点:每个结点最多有两个孩子;
基于属性不同,我们还可以把二叉树分为以下几种类型:
1)完全二叉树: 若设二叉树的高度为h,那么除了最后一层,其他每层都达到了 最大个数,并且叶子节点都是从左到右依次排布
2)完美二叉树(满二叉树):叶子节点都处在最底层
3)严格二叉树:每个节点只有0/2个子节点
4)平衡二叉树:
1* 空树
2* 左右两个子树的高度差不超过1
3* 平衡二叉树的每一层子树都是一颗平衡二叉树
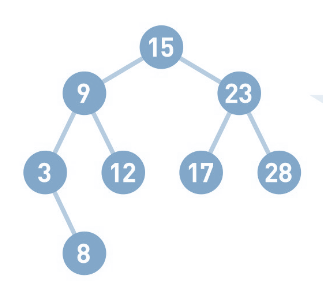
5)二叉搜索树:
特点:左子树上所有节点数据小于父节点数据,右子树上所有节点数据大于父节点数据。
实现:(主要依赖)
插入节点:
1)迭代性插入
2)递归性插入
综合来讲:如果对内存占用和性能要求比较严格,或者需要在较大规模的数据集上操作二叉树,可能更倾向于使用迭代性的插入节点。而如果注重代码的简洁和可读性,并且树的深度不会很大,递归性的插入节点可能是一个更好的选择。
//创建Tree,相当于插入Node;
//两种插入方法:
//1.迭代性插入;
//2.递归性插入;
//相对来说,递归性的代码更容易编写,在树的深度不是很大时是一种简洁的写法。
Node* createTree(Node* root,int data) {
//递归性的写法:那么函数一定有返回值,要有递归性(运动性)的参数。
if (root == NULL) {
root = createNode(data);
return root;
}
//如果根节点不是NULL,直接先考虑左子树,再考虑右子树。
if (data <= root->data) {
root->left = createTree(root->left,data);
}
else {
root->right = createTree(root->right,data);
}
return root;
}查找结点:(同样是递归性的实现)
//有递归意味,用了递归的想法,但是并不需要返回,只是找到或者都找不到,所以这个函数并不需要返回树的类型
bool searchData(Node* root, int data) {
if (root == NULL) {
return false;
}
if (data < root->data) {
return searchData(root->left, data);
}
else if (data > root->data) {
return searchData(root->right, data);
}
else if(data == root->data){
return true;
}
return false;
}6.二叉搜索树在内存中的栈与堆
(函数递归与二叉树的实现----root的变化)
简单理解,函数调用在栈中实现,动态创建的节点在堆上新建。至于root的变化 ,它是不断递归返回的,所以在最后返回的root就是我们需要的树顶节点的root。
7.功能实现:
1)FindMax()
int FindMax(Node* root) {
// 如果根节点为空,则返回一个特定值,表示未找到最大值
if (root == NULL) {
return -1; // -1表示不存在
}
// 如果右子树不为空,则递归地向右子树搜索
if (root->right != NULL) {
return FindMax(root->right);
}
// 如果右子树为空,则当前节点就是最大值节点
return root->data;
}2)FindMin()
int FindMin(Node* root) {
// 如果根节点为空,则返回一个特定值,表示未找到最小值
if (root == NULL) {
return -1; // -1表示不存在
}
// 如果左子树不为空,则递归地向左子树搜索
if (root->left != NULL) {
return FindMax(root->left);
}
// 如果左子树为空,则当前节点就是最小值节点
return root->data;
}3)FindHeight()(计算高度或者最大深度)
int FindHeight(Node* root) {
//根据二叉树的特点:向下找的时候要时刻比较左右子树的高度,并向下递归。
//可能会疑问:左右子树的高度我们也不知道啊?怎么比较?
//所以,才是递归性的,先用两个变量记住函数的返回值(左右子树的高度),再进行比较;
//用两个变量记住函数的返回值 这一步中就要调用自己,实现递归,直到左右子树为空树(高度为-1);
//return -1;
if (root == NULL) {
return -1;
}
int left = 0, right = 0;
left = FindHeight(root->left);
right = FindHeight(root->right);
return max(left, right) + 1;
}4)遍历打印
深度优先遍历:(D--data , L--left , R--right)
每一个D,L,R操作都是按照顺序全部做完后才进行下一步操作
1* 前序遍历<D,L,R>
//前序遍历:值-左-右
void Preorder(Node* root) {
if (root == NULL) {
return;
}
printf("%d", root->data);
Preorder(root->left);
Preorder(root->right);
}2* 中序遍历<L,D,R>
//中序遍历:左-值-右
void Inorder(Node* root) {
if (root == NULL) {
return;
}
Inorder(root->left);
printf("%d", root->data);
Inorder(root->right);
}3* 后序遍历 <L,R,D>
//后序遍历:左-右-值
void Postorder(Node* root) {
if (root == NULL) {
return;
}
Postorder(root->left);
Postorder(root->right);
printf("%d", root->data);
}广度优先遍历:(层序遍历)
// 层序遍历二叉树
//主要流程:root->root左孩->root右孩
//主要实现:前提是非空树,如果是返回就行了。借助队列这个容器,当队列中不为空时出队一个元素并访问(打印)
//紧接着先判断有没有左孩(有就入队),再判断有没有右孩(有就入队)。
//这样操作就保证了:对层间来说先遍历前层后遍历后层;对同层来说先遍历左孩后遍历右孩。
void levelOrderTraversal(Node* root) {
if (root == NULL) return;
Queue* q = createQueue();
enqueue(q, root);
while (!isEmpty(q)) {
Node* current = dequeue(q);
printf("%d ", current->data);
if (current->left != NULL) {
enqueue(q, current->left);
}
if (current->right != NULL) {
enqueue(q, current->right);
}
}
printf("\n");
}8.判断是否为二叉搜索树
伪代码: Function isBST(root): if root is NULL: return True // 检查左子树的最大值 maxLeft = getMaxValue(root->left) // 检查右子树的最小值 minRight = getMinValue(root->right) // 如果左子树的最大值大于等于根节点的值,或者右子树的最小值小于等于根节点的值,则不是二叉搜索树 if maxLeft >= root->data or minRight <= root->data: return False // 递归检查左右子树 return isBST(root->left) and isBST(root->right)
bool isBST(Node* root) {
//基本特点:保证左子树上所有元素都比父节点小,保证右子树上所有元素都比父节点大;
//基本实现:每个子树都是搜索二叉树,且每个左子树的最大值小于根节点,每个右子树小于根节点;
if (root == NULL) {
return true;//空树是二叉搜索树;
}
int left_max = FindMax(root->left);
int right_min = FindMin(root->right);
if (root->data<left_max || root->data>right_min) {
return false;
}
if (isBST(root->left) && isBST(root->right)) {
return true;
}
return false;
}
//但其实还可以使用另外一种递归检查的方式
//另外,这里的最大值和最小值在获取后是不变的,所以在主调函数中可以先找到最大值,最小值再传入。
//或者直接设置最值的全局变量9.DeleteNode()
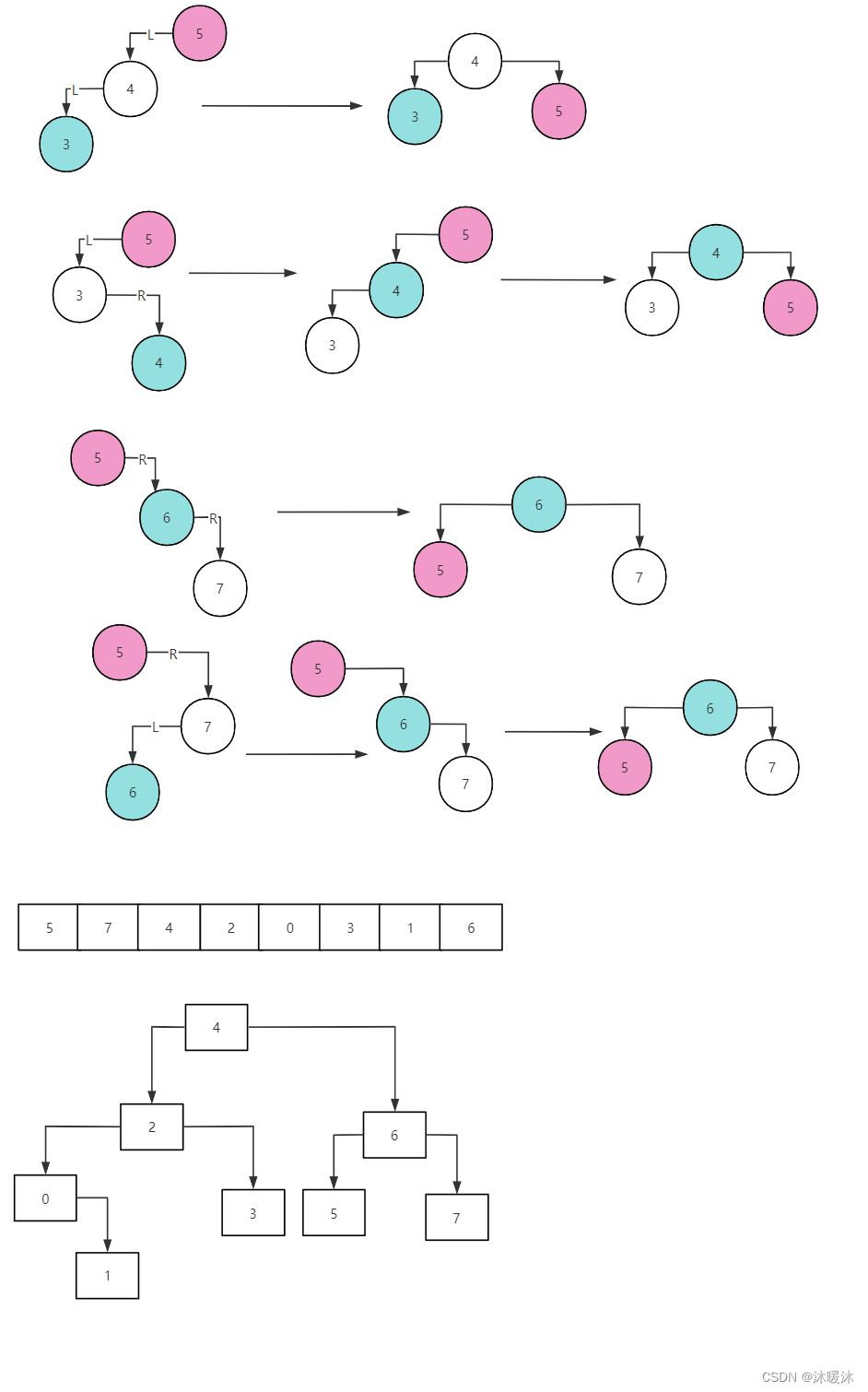
//删除指定数值的结点;
//对于删除有三种情景:1.删除叶子结点 2.删除单个孩子结点 3.删除两个孩子的结点
Node* DeleteNode(Node* root, int data) {
if (root == NULL) {
return root;
}
if (data < root->data) {
//再对左子树操作;
DeleteNode(root->left, data);
}
else if (data > root->data) {
//再对右子树操作;
DeleteNode(root->right, data);
}
else {
//对当前结点进行删除
Node* temp = root;
if (root->left == NULL && root->right == NULL) {
//1.删除叶子结点:
root = NULL;
free(temp);
}
else if (root->right == NULL) {
//2.删除有左孩子的结点;
root = root->left;
free(temp);
}
else if (root->left == NULL) {
//3.删除有右孩子的结点;
root = root->right;
free(temp);
}
else {
//4.删除有两个孩子的结点;主要思想:先拷贝子树的最值到删除处,再删除原本的。
//主要有两种写法:1.拷贝右子树的最小值,删除原来的;2.拷贝左子树的最大值,删除原来的。
//下面采用右子树最小值;
root->data = FindMin(root->right);
//递归删除:使得两个孩子的情况转换为1,2这两种情况。
//这里怎么递归?
//拷贝的是右子树的最小值,所以传入右子树,删除此时与root相同的值,相当于把那个最小值的结点拉到root的位置
root->right = DeleteNode(root->right, root->data);
}
}
return root;
}10.二叉搜索树的中序后继节点
//如果节点 node 有右子树,那么它的中序后继节点是其右子树中的最小节点。
//如果节点 node 没有右子树,那么它的中序后继节点是沿着父节点向根节点方向的第一个具有左孩子的祖先节点。
//也就是说,找到离节点 node 最近的一个祖先节点,且该节点的左孩子也是节点 node 的祖先节点。
Node* inorderSuccessor(Node* root, Node* current) {
if (root == NULL || current == NULL) {
return NULL;
}
// 如果当前节点有右子树,则后继节点是右子树中的最小值节点
if (current->right != NULL) {
return FindMin(current->right);
}
// 如果当前节点没有右子树,则向上遍历父节点,直到找到第一个具有左孩子的祖先节点
Node* successor = NULL;
Node* ancestor = root; // 从根节点开始向上遍历
while (ancestor != current) {
if (current->data < ancestor->data) {
// 如果当前节点在祖先节点的左子树中,则更新后继节点为当前祖先节点
successor = ancestor;
ancestor = ancestor->left;
}
else {
// 如果当前节点在祖先节点的右子树中,则继续向上搜索祖先节点
ancestor = ancestor->right;
}
}
return successor;
}

















![[蓝桥杯 | 暴搜] 学会暴搜之路](https://img-blog.csdnimg.cn/direct/3ffb2a8342f443b59400979335511b44.png)