接下来我们来看看分布式锁
一、什么是分布式锁?
分布式锁,就是在分布式系统中使用的锁。
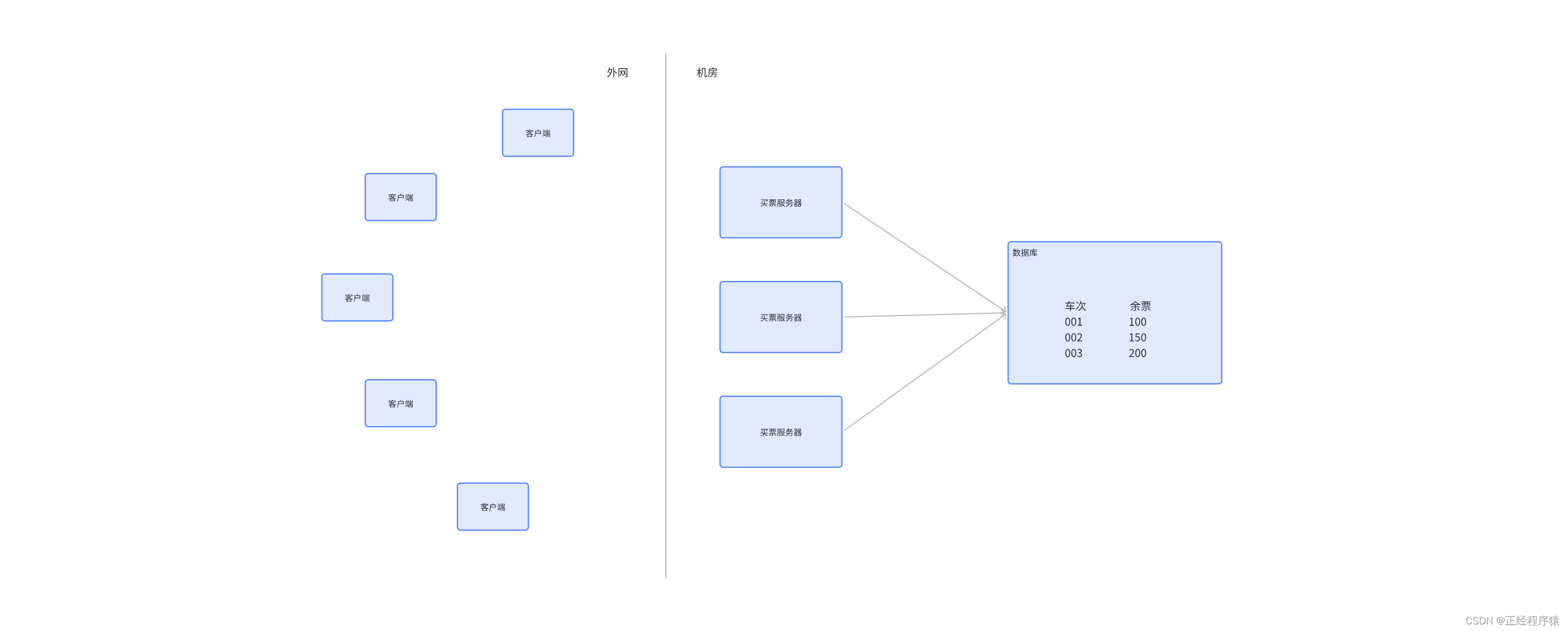
在单体应用中,我们通过锁解决的是控制共享资源访问的问题
分布式锁,就是解决了分布式系统中控制共享资源访问的问题
与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程
1.1、分布式锁应该具备哪些条件
- 分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性(可理解为重新进入,由多于一个任务并发使用,而不必担心数据错误)
- 具备锁失效机制,即自动解锁,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
1.2、分布式锁的实现方式
- 基于数据库实现分布式锁
- 基于Zookeeper实现分布式锁
- 基于redis实现分布式锁
1.2.1、基于数据库的分布式锁
基于数据库的锁实现有两种方式:
- 基于数据库表的增删
基于数据库表增删是最简单的方式,首先创建一张锁的表主要包含以下手段
- 类的全路径名+方法名
- 时间戳
具体的使用方式:
当需要锁住某个方法时,往该表中插入一条相关的记录。
类的全路径名+方法名时有唯一约束的,如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就会认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容,执行完毕之后,需要delete该记录
- 基于数据库排他锁
public void lock()){
connection.setAutoCommit(false);
int count = 0;
while(count < 4){
try{
select * from lock where lock_name=xxx for update;
if(结果不为空){
//代表获取到锁
return;
}
}catch(Exception e){
}
sleep(1000);
count++;
}
throw new LockException();
}- 基于数据库锁的优缺点
上面两种方式都是依赖数据库表,一种是通过表中的记录判断当前是否有锁的存在,另外一种是通过数据库的排他锁来实现分布式锁
- 优点是直接借助数据库,简单容易理解
- 缺点是操作数据库需要一定的开销,性能问题需要考虑
1.2.2、基于Zookeeper的分布式锁
基于zookeeper临时有序节点可以实现的分布式锁。每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是偶获取锁的方式很简单,只需要判断有序节点中需要最小的一个。当释放锁的时候,只需将这个顺势节点删除即可。同时也可以避免服务宕机导致的锁无法释放,而产生的死锁问题
- 性能上可能没有缓存服务那么高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所欲的Follower机器上
- zookeeper的并发安全问题:因为可能存在网络抖动,客户端和ZK集群的session连接断了,zk集群以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了
1.2.3、基于redis的分布式锁
redis命令说明:
setnx命令:set if not exists ,当且仅当key不存在时,将key的值设为value。若给定的key已经存在,则SETNX不做任何动作
返回1,所用该进程获得锁,将key值设为value
返回0,说明其他进程已经获得了锁,进程不能进入临界区
命令格式:setnx lock.key lock.value
get命令:获取key的值,如果存在,则返回;如果不存在,则返回null
命令格式:get lock.key
getset命令:该方法时原子的,对key设置new Value这个值,并且返回key原来的旧值
命令格式:getset lock.key new Value
del命令:删除redis中指定的key
命令格式:del lock.key
1.2.4、基于set命令的分布式锁
- 加锁:使用setnx进行加锁,当该指令返回1时,说明成功获得锁
- 解锁:当得到锁的线程执行完任务之后,使用del命令释放锁,以便其他线程可以继续执行setnx命令来获得锁
- 存在的问题:假设线程获取了锁之后,在执行任务的过程中挂掉,来不及显示地执行del命令来释放锁,那么竞争该锁的线程都会执行不了,产生死锁的情况
- 解决方案:设置锁超时时间
- 设置锁超时时间:setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放,可以使用expire命令设置锁超时时间
- 存在问题:setnx和expire不是原子性操作,假设某个线程执行setnx命令,成功获得了锁,但是还没来得及执行expire命令,服务器就挂掉了,这样依赖,这把锁就没有设置过期时间,变成了死锁,别的线程再也没有办法获得锁了
- 解决方案:reids的set命令支持在获取锁的同时设置key的过期时间
- 使用set命令加锁并设置锁过期时间
- 命令格式:set nx ex
- 存在问题:
- 假设线程A成功得到了锁,并且设置的超时时间是30秒,如果某些原因导致线程A执行的很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁
- 随后,线程A执行完任务,接着执行del指令来释放锁,但这时候线程B还没执行完,线程A 实际上删除的是线程B加的锁
- 解决方案:
- 可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。在加锁的时候吧当前线程ID当作value,并在删除之前验证key对应的value是不是自己线程的ID。但是这样做其实隐含了一个新的问题,get操作,判断和释放锁是两个独立操作,不是原子性。对于非原子性的问题,我们可以使用Lua脚本来确保操作的原子性
- 锁续期:(机制类似与reidsson的看门狗机制)
- 虽然步骤4避免了线程A误删掉key的情况,但是同一时间有A、B两个线程在访问代码块,仍然是不完美的。
- 怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续期”。
- 假设线程A执行了29秒还没执行完,这时候守护线程会执行expire指令,为这把锁续期20秒,守护线程从第29秒开始执行,每20秒执行一次
- 情况一:当线程A执行完任务,会显示关掉守护线程
- 情况二:如果服务器同时断电,由于线程A和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了
1.2.5、基于setnx、get、getset的分布式锁
- 实现原理:
- setnx(lockkey,当前时间+过期超时实践)如果返回1,则获取锁成功;如果返回0则没有获取到锁,转向步骤b
- get(lockkey)获取值oldExpireTime,并将这个value值与当前系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取,转向步骤c
- 计算新的过期时间,newExipireTime=当前时间+锁超时时间,然后getset(lockkey,new ExpireTime)会返回当前lockkey的值currentExpireTime
- 判断currentExpireTime与oleExpireTime是否相等,如果相等,说明当前getset是指成功,获取到了锁,如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回重试,或者继续重试
- 获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行del命令释放锁(释放锁之前需要判断持有锁的线程是不是当前线程);如果大于锁设置的超时时间,则不需要再对锁进行处理
- 代码实现
- 获取锁的方式:
public boolean lock(long acquireTimeout, TimeUnit timeUnit) throws InterruptedException {
acquireTimeout = timeUnit.toMillis(acquireTimeout);
long acquireTime = acquireTimeout + System.currentTimeMillis();
//使用J.U.C的ReentrantLock
threadLock.tryLock(acquireTimeout, timeUnit);
try {
//循环尝试
while (true) {
//调用tryLock
boolean hasLock = tryLock();
if (hasLock) {
//获取锁成功
return true;
} else if (acquireTime < System.currentTimeMillis()) {
break;
}
Thread.sleep(sleepTime);
}
} finally {
if (threadLock.isHeldByCurrentThread()) {
threadLock.unlock();
}
}
return false;
}
public boolean tryLock() {
long currentTime = System.currentTimeMillis();
String expires = String.valueOf(timeout + currentTime);
//设置互斥量
if (redisHelper.setNx(mutex, expires) > 0) {
//获取锁,设置超时时间
setLockStatus(expires);
return true;
} else {
String currentLockTime = redisUtil.get(mutex);
//检查锁是否超时
if (Objects.nonNull(currentLockTime) && Long.parseLong(currentLockTime) < currentTime) {
//获取旧的锁时间并设置互斥量
String oldLockTime = redisHelper.getSet(mutex, expires);
//旧值与当前时间比较
if (Objects.nonNull(oldLockTime) && Objects.equals(oldLockTime, currentLockTime)) {
//获取锁,设置超时时间
setLockStatus(expires);
return true;
}
}
return false;
}
}tryLock方法中,主要逻辑如下:lock调用tryLock方法,参数为获取的超时时间与单位,线程再超时时间内,获取锁操作将自旋再那里,知道该自旋锁的保持着释放了锁
3.释放锁的实现方式
public boolean unlock() {
//只有锁的持有线程才能解锁
if (lockHolder == Thread.currentThread()) {
//判断锁是否超时,没有超时才将互斥量删除
if (lockExpiresTime > System.currentTimeMillis()) {
redisHelper.del(mutex);
logger.info("删除互斥量[{}]", mutex);
}
lockHolder = null;
logger.info("释放[{}]锁成功", mutex);
return true;
} else {
throw new IllegalMonitorStateException("没有获取到锁的线程无法执行解锁操作");
}
}存在的问题:
这个锁的核心是基于System.currentMillis() , 如果多台服务器时间不一致, 那么问题就出现了, 但是这个bug完全可以从服务器运维层面规避的, 而且如果服务器的时间不一致的话,只要和时间相关的逻辑都是会出现问题的
如果前一个锁超时的时候, 刚好有多台服务器去请求获取锁,南无就会出现同时执行redis.getset()而导致出现过期时间覆盖问题,不过,这种情况并不会对正确结果造成影响
存在多个线程同时持有锁的情况,如果线程A执行任务的时间超过锁的过期时间,这是另一个线程就快获得这个锁,造成多个线程同时持有锁的情况。类似方案一,可以使用“锁续期” 的方式来解决
这两种redis分布式锁存在的问题
前面两种redis分布式锁的实现方式,如果从“高可用”的层面来看,仍然有所欠缺,也就是说当redis是单点的情况下,当发生故障时,则整个业务的分布式锁都将无法使用
为了提高可用性,我们可以使用主从模式或哨兵模式,但是这种情况下仍然存在问题,在主从模式或哨兵模式下,正常情况下,如果加锁成功了,那么nsater节点会异步复制给对应的slave节点。如果在这个过程中发生master节点宕机,主备切换,slave节点变成master节点,er锁还没从master节点同步过来,这就发生锁丢失,会导致多个客户端可以同时持有同一把锁的问题
那么,如何避免这种情况呢?redis官方给出了基于redis集群部署的高可用分布式锁解决方案:RedLock;
1.2.6、基于RedLock的分布式锁
RedLock算法是Redis的作者Antirez在单Redis节点基础上引入的高可用模式。 Redlock的加锁要结合单节点分布式锁算法共同实现,因为它是RedLock的基础
1、加锁原理实现
现在假设有5个reids主节点(大于3的奇数个),这样基本保证他们不会同时宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
- 获取当前Unix时间,以毫秒为单位,并设置超时时间TTL
TTL要大于 正常业务执行时间+获取所有redis服务消耗时间+时钟漂移
- 依次尝试从5个实例,使用相同的key和具有唯一性的value获取锁,当向redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间TTL,这样可以避免客户端死等。比如:TTL为5s。这是获取锁最多用1s,所以如果一秒内无法获取锁,就放弃这个锁,从而尝试获取下个锁
- 客户端获取所有能获取的锁后的时间,减去第(a)步的时间,就得到锁的获取时间。锁的获取时间要小于锁的失效时间TTL,并且至少从半数以上的Redis节点获取到锁,才算获取成功锁
- 如果成功获得锁,key的真正有效时间=TTL-锁的获取时间-时钟漂移。比如:TTL是5s,获取所有锁用了2s,则真正锁有效时间为3s
- 如果因为某些原因,获取锁失败(没有在半数以上实例取得到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失但是实际上成功了
TTL要大于 正常业务执行时间+获取所有redis服务消耗时间+时钟漂移
设想这样一种情况:客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了,这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此释放锁的时候,客户端也应该对当时获取锁失败的那些redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却有问题
失败重试:当client不能获取锁时,应该在随机时间后重新获取锁;同时重试获取锁要有一定的次数限制;
在随机时间后进行重试,主要是防止过多的客户端同时尝试去获取锁,导致彼此都获取锁失败的问题
2、RedLock性能及崩溃恢复的相关解决方案:
由于N个Redis节点中的大多数能正常工作就能保证RedLocj正常工作,因此理论上它的可用性更高。前面我们说的主从架构下存在的安全性问题,在RedLock中已经不存在了,如果有节点发生崩溃重启,还是会对锁的安全性有影响,具体的影响程度跟Redis持久化配置有关:
- 如果Redis 没有持久化功能,在clientA获取锁成功后,所有redis重启,clientB能够再次获取到锁,这样就违反了锁的排他互斥性;
- 如果启动AOF永久化存储,事情会好些,举例:当我们重启redis后,由于redis过期机制是按照unix时间戳走,所以在重启后,然后会按照规定时间过期,不影响业务;但是由于AOF同步到磁盘的方式默认是每秒一次,如果在1秒内断电,会导致数据丢失,立即重启会造成锁的互斥性失效;但如果同步磁盘方式使用Always(每一个写命令都同步到硬盘)造成性能急剧下降,所以在锁完全有效性和性能方面要有所取舍
- 为了有效解决既保证锁完全有效性和性能高效问题:antirez由提出了“延迟重启”的概念,redis同步到磁盘方式保持默认的每秒1次,在redis崩溃单机后(无论一个还是所有),先不立即重启它,而是等待TTL时间后重启,这样的话,这个节点在重启前所参与的锁都会过期,他在重启后就不会对现有的锁造成影响,缺点是在TTL时间内服务相当于暂停状态;
3、Redisson中RedLock的实现
在JAVA的reidsson包已经实现类对RedLock的封装,主要是通过redisClient与lua脚本实现的,之所以使用lua脚本,是为了实现加解锁校验和执行的事务性
- 唯一ID的生成:
分布式事务锁中,为了能够让作为中心节点的存储节点获取锁的持有者,从而避免锁被非持有者误解锁,每个发起请求的client节点都必须具有全局唯一的id。通话吃那个我们是使用UUID来作为这个唯一id,redisson也是这样实现的,在此基础上,redisson还加入了threadid避免了多个线程反复获取UUID的性能损耗
procted final UUID id = UUID.randomUUID();
String getLockName(long threadId){
return id+":"+threadId;
}2. 加锁逻辑:
redisson加锁的核心代码非常容易理解,通过传入TTL与唯一id,实现一段时间的加锁请求。下面是可重入锁的实现逻辑:
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command)
{
internalLockLeaseTime = unit.toMillis(leaseTime);
// 获取锁时向5个redis实例发送的命令
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
// 校验分布式锁的KEY是否已存在,如果不存在,那么执行hset命令(hset REDLOCK_KEY uuid+threadId 1),
//并通过pexpire设置失效时间(也是锁的租约时间)
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 如果分布式锁的KEY已存在,则校验唯一 id,如果唯一 id 匹配,表示是当前线程持有的锁,那么重入次数加1,并且设置失效时间
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 获取分布式锁的KEY的失效时间毫秒数
"return redis.call('pttl', KEYS[1]);",
// KEYS[1] 对应分布式锁的 key;ARGV[1] 对应 TTL;ARGV[2] 对应唯一 id
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}3、释放锁逻辑
protected RFuture<Boolean> unlockInnerAsync(long threadId)
{
// 向5个redis实例都执行如下命令
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 如果分布式锁 KEY 不存在,那么向 channel 发布一条消息
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
// 如果分布式锁存在,但是唯一 id 不匹配,表示锁已经被占用
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
// 如果就是当前线程占有分布式锁,那么将重入次数减 1
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
// 重入次数减1后的值如果大于0,表示分布式锁有重入过,那么只设置失效时间,不删除
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
// 重入次数减1后的值如果为0,则删除锁,并发布解锁消息
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
// KEYS[1] 表示锁的 key,KEYS[2] 表示 channel name,ARGV[1] 表示解锁消息,ARGV[2] 表示 TTL,ARGV[3] 表示唯一 id
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage,
internalLockLeaseTime, getLockName(threadId));
}4、redisson中RedLock的使用
Config config = new Config();
config.useSentinelServers()
.addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389")
.setMasterName("masterName")
.setPassword("password").setDatabase(0);
RedissonClient redissonClient = Redisson.create(config);
RLock redLock = redissonClient.getLock("REDLOCK_KEY");
try {
// 尝试加锁,最多等待500ms,上锁以后10s自动解锁
boolean isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
if (isLock) {
//获取锁成功,执行对应的业务逻辑
}
} catch (Exception e) {
e.printStackTrace();
} finally {
redLock.unlock();
}可以看到,redisson包的实现中,通过lua脚本校验了解锁时的client身份,所以我们无需再在finally中去判断是否加锁成功,也无需做额外的身份校验,可以说已经达到开箱即 用的程度了。
同样,基于RedLock释放的分布式锁也存在client获取锁之后,子啊TTL时间内没有完成业务逻辑的处理,而此时锁会被自动释放,造成多个线程同时持有锁的问题。而Redisson在实现的过程中,自行延长锁key的生存时间
1.2.7、基于Redisson看门狗的分布式锁
前面说了,如果某些原因导致持有锁的线程在锁过期时间内,还没执行任务,而锁因为还没超时被自动释放了,那么就会导致多个线程同时持有锁的现象出现,而为了解决这个问题,可以进行“锁续期”。其实,在JAVA的Redisson包中有一个“看门狗”机制,已经帮助我们实现了这个功能。
- redisson原理:
redisson在获取锁之后,会维护一个看门狗线程,当锁即将过期还没有释放时,不断的延长锁key的生存时间
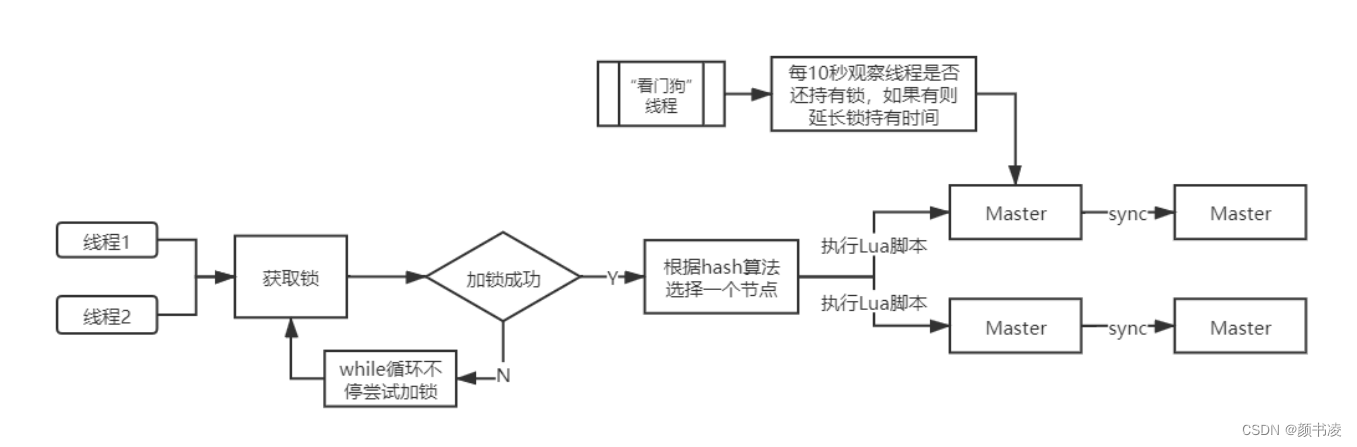
2.加锁机制
1、线程去获取锁,获取成功;执行lua脚本,保存数据到redis数据库
2、线程去获取锁,获取失败;一直通过while循环尝试获取锁,获取成功后,执行lua脚本,保存数据到redis数据库
3. watvh dog自动延期机制:
看门狗启动后,对整体性能也会有一定影响,默认情况下看门狗线程是不启动。如果redisson进行加锁的同时设置了锁的过期时间,也会导致看门狗机制
redisson在获取锁之后,会维护一个看门狗线程,在每一个锁设置的过期时间的1/3处,如果线程还没执行完任务,则不断延长锁的有效期。看门狗的检查锁超时时间默认是30s,可以通过lockWactchdogTimeout参数来改变
加锁的时间默认是30s,如果加锁的业务没有执行完,那么每隔30/3=10s,就会进行一次续期,把锁重置成30s,保证解锁前锁不会失效
万一业务的机器宕机呢?如果宕机了,那看门狗线程就执行不了了,就续不了期,那自然30s之后锁就解开了
4. redission分布式锁的关键点
对key不设置过期时间,由Redisson在加锁成功后给维护一个watchdog看门狗,watchdog负责定时监听并处理,在锁没有被释放且快要过期的时候自动对锁进行续期,保证解锁前锁不会自动失效
通过Lua脚本实现加锁和解锁的原子操作
通过记录获取锁的客户端id,每次加锁时判断是否是当前客户端已经获得锁,实现了可重入锁
5. Redisson的使用
在方案三中,我们已经演示基于Redisson的RedLock的使用案例,其中Redisson也封装可重入锁(Reentrant Lock)、公平锁(Fair Lock)、联锁(MultiLock)、红锁(RedLock)、读写锁(ReadWriteLock)、信号量(Semaphore)、可过期性信号量(PermitExpirableSemaphore)、闭锁(CountDownLatch)
![]()

![[<span style='color:red;'>Redis</span>实战]<span style='color:red;'>分布式</span><span style='color:red;'>锁</span>](https://img-blog.csdnimg.cn/direct/71216cd0c3a64570b293af6bfe2a6c18.png)